对齐
- 现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定变量的时候经常在特定的内存地址访问,这就需要各类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。
- 如果不按照适合其平台要求对数据存放进行对齐,会在存取效率上带来损失。比如有些平台每次读都是从偶地址开始,如果一个int型(假设为32位系统)如果存放在偶地址开始的地方,那么一个读周期就可以读出,而如果存放在奇地址开始的地方,就可能会需要2个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该int数据。显然在读取效率上下降很多
结构体对齐的规则
- 数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员的对齐按照#pragma pack指定的数值(默认为8)和这个数据成员自身长度中,比较小的那个进行
- 结构(或联合)的整体对齐规则:在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将按照#pragma pack指定的数值和结构(或联合)最大数据成员长度中,比较小的那个进行
- 结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储
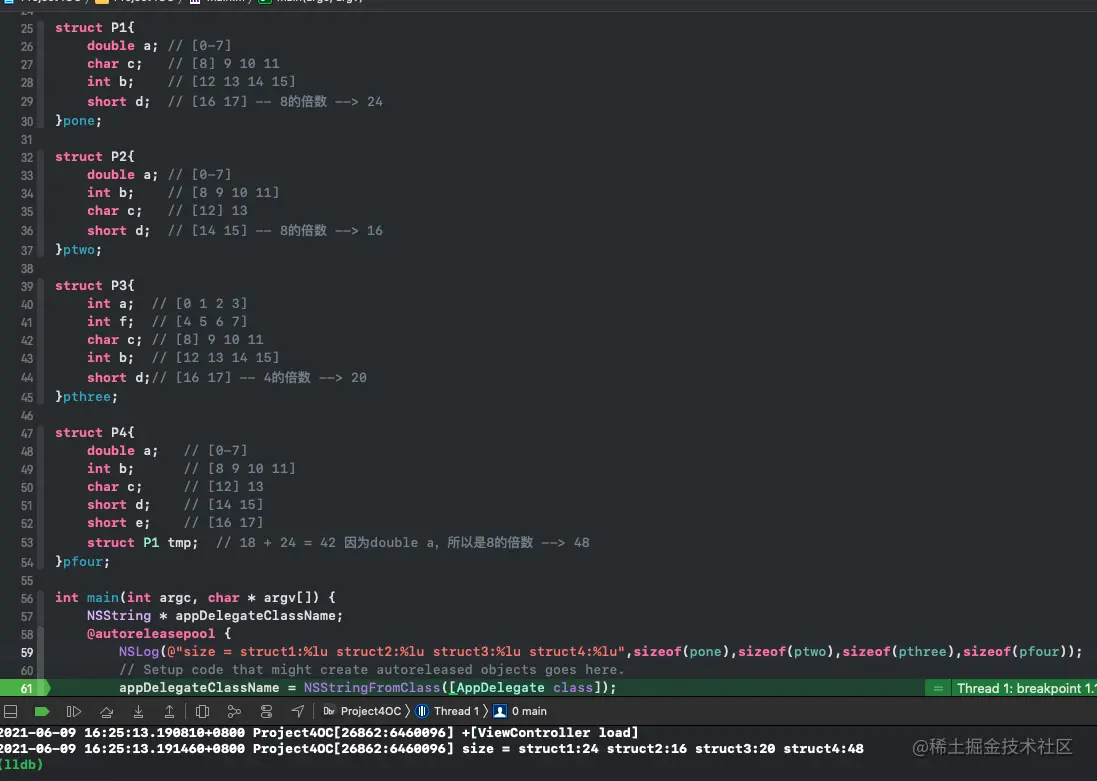
代码验证
struct P1{
double a;
char c;
int b;
short d;
}pone;
struct P2{
double a;
int b;
char c;
short d;
}ptwo;
struct P3{
int a;
int f;
char c;
int b;
short d;
}pthree;
struct P4{
double a;
int b;
char c;
short d;
short e;
struct P1 tmp;
}pfour;
最后
- 结构体的对齐显示成员对齐,然后是结构体的整体对齐,根据内存对齐原则,来对齐内存。
- 根据数据成员对齐:根据#pragma pack(x) 将x(默认是8)和需要排列的数据成员的自身长度比较,使用较小的,这样就排出了每一个数据所占的地址及位置。然后依次排列,但并不一定是连续排列,要排列的数据 根据数据成员自身长度和x哪个更小,假设自身数据长度为4,x = 8,再看要排列的地址是不是4的倍数,如果不是,则延长地址到4的倍数处再排列
- 数据结构对齐:当上面那个对齐了每一个数据成员后现在需要对数据结构整体长度对齐。找出数据结构成员中最大的长度z,跟x做对比,找到最小的那个,假设x为8,z为4,则整体数据结构长度应该是4的整数倍,不够自动补齐
- 结构体作为成员:如果成员内有结构体,需要看结构体中最大的成员的长度h来做比较,是h的倍数


