数据准备
#建表
create table department(
id int,
name varchar(20)
);
create table staff(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
#插入数据
insert into department values
(200,'挖矿小分队'),
(201,'人力资源'),
(202,'销售'),
(203,'运营');
insert into staff(name,sex,age,dep_id) values
('程咬金','male',38,200),
('露娜','female',26,201),
('李白','male',38,201),
('王昭君','female',28,202),
('典韦','male',118,200),
('小乔','female',16,204)
;
#查看表结构和数据
mysql> desc department;
+
| Field | Type | Null | Key | Default | Extra |
+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+
2 rows in set (0.06 sec)
mysql> desc staff;
+
| Field | Type | Null | Key | Default | Extra |
+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
| sex | enum('male','female') | NO | | male | |
| age | int(11) | YES | | NULL | |
| dep_id | int(11) | YES | | NULL | |
+
5 rows in set (0.04 sec)
#表department与staff
mysql> select * from department;
+
| id | name |
+
| 200 | 挖矿小分队 |
| 201 | 人力资源 |
| 202 | 销售 |
| 203 | 运营 |
+
4 rows in set (0.00 sec)
mysql> select * from staff;
+
| id | name | sex | age | dep_id |
+
| 1 | 程咬金 | male | 38 | 200 |
| 2 | 露娜 | female | 26 | 201 |
| 3 | 李白 | male | 38 | 201 |
| 4 | 王昭君 | female | 28 | 202 |
| 5 | 典韦 | male | 118 | 200 |
| 6 | 小乔 | female | 16 | 204 |
+
6 rows in set (0.00 sec)
连表查
-
交叉连接 不适用任何匹配条件,生成笛卡尔积
- select * from 表1,表2;
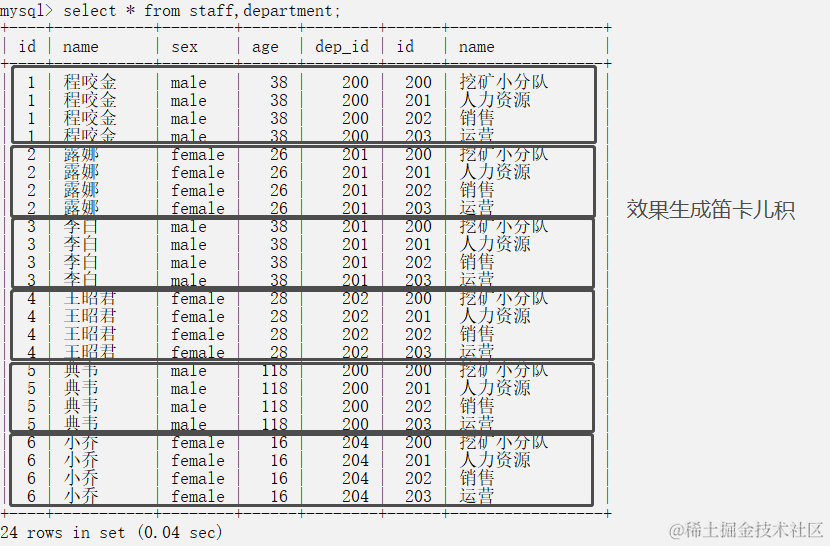
-
内链接 (常用) 只连接匹配的行
- select * from staff inner join department on 条件(表1.字段=表2.字段)
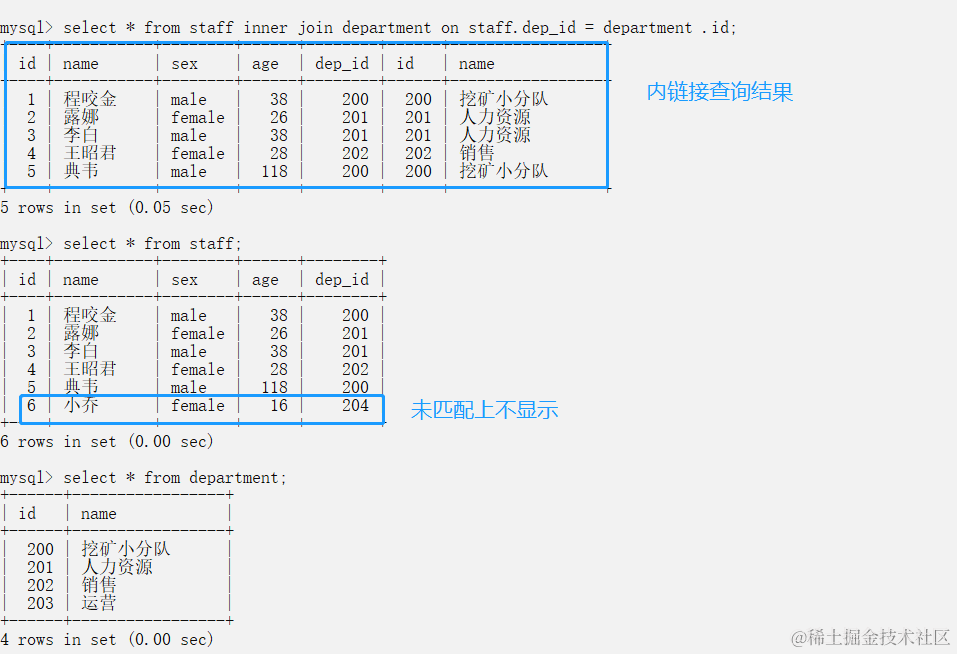
- 小结: 找两张表共有的部分,利用条件从笛卡尔积结果中筛选出了正确的结果
-
外连接
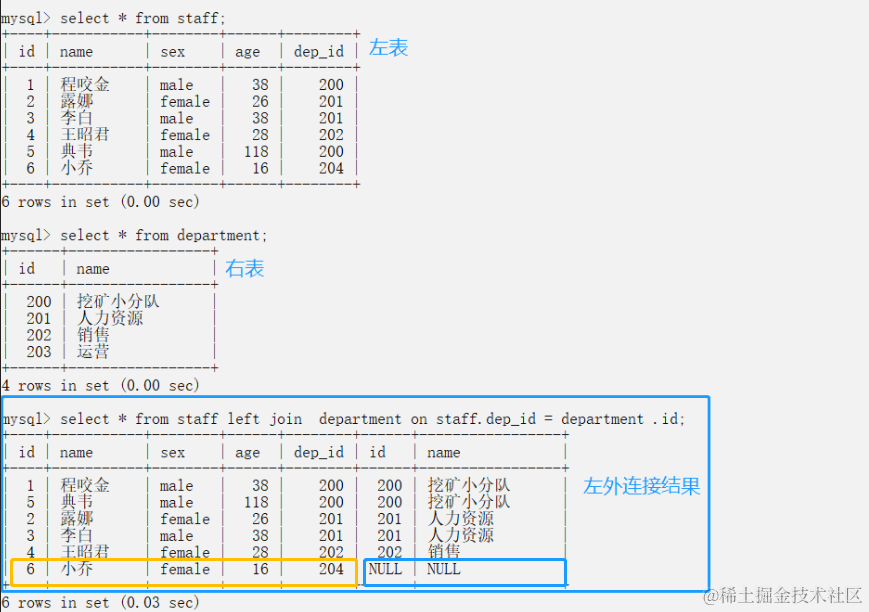
- 左外连接(常用) 优先显示左表全部记录 left join
- select * from staff left join department on 条件(表1.字段=表2.字段)
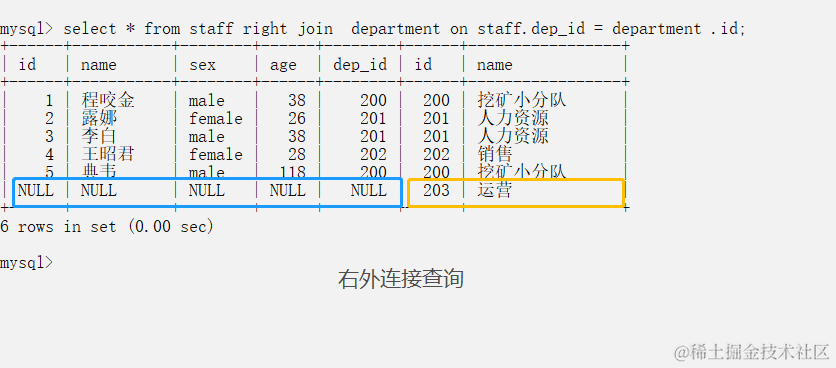
- 右外链接 优先显示右表全部记录 right join
- select * from staff right join department on 条件(表1.字段=表2.字段)
- 全外连接 显示左右两个表全部记录
- 查询语句 (mysql没有full join,可以有左外连接+右外连接来实现全外连接)
select * from 表1 left join 表2 on 条件((表1.字段=表2.字段))
union
select * from 表1 right join 表2 on 条件((表1.字段=表2.字段));
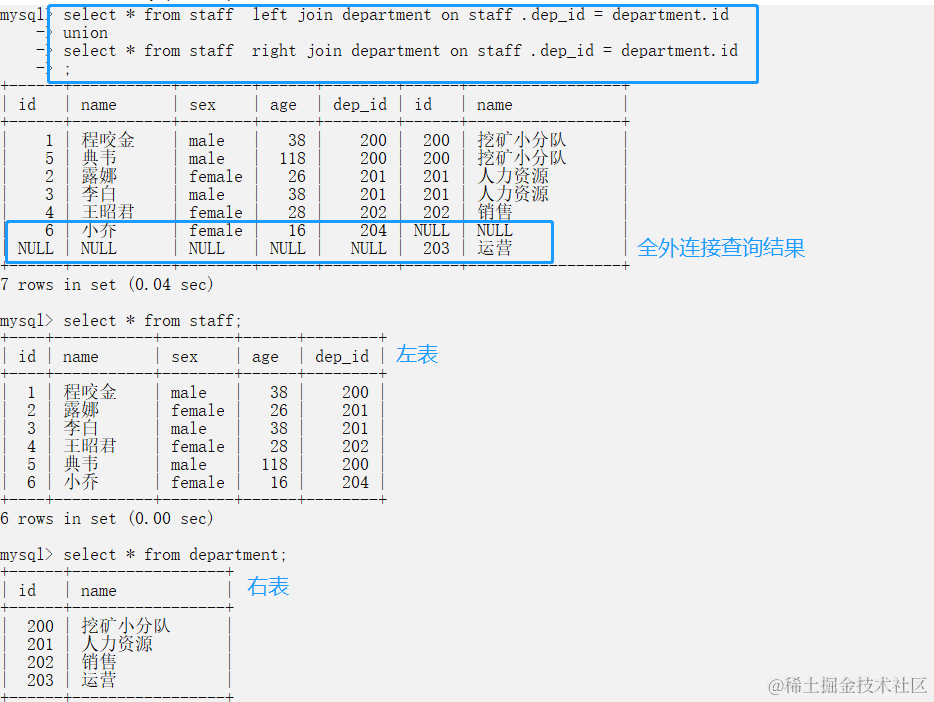
#全外连接:在内连接的基础上增加左边有右边没有的和右边有左边没有的结果
#注意:mysql不支持全外连接 full join
#强调:mysql可以使用此种方式间接实现全外连接
#注意 union与union all的区别:union会去掉相同的纪录
1.找挖矿小分队的所有员工的信息
#答:
mysql> select * from staff inner join department on department.id=staff.dep_id where department.name='挖矿小分队';
+
| id | name | sex | age | dep_id | id | name |
+
| 1 | 程咬金 | male | 38 | 200 | 200 | 挖矿小分队 |
| 5 | 典韦 | male | 118 | 200 | 200 | 挖矿小分队 |
+
2 rows in set (0.00 sec)
2.查找人力资源所有的员工名字
#答: (名字太长可以起别名)
mysql> select staff.name from staff inner join department as dep on dep.id=staff.dep_id where dep.name='人力资源';
+
| name |
+
| 露娜 |
| 李白 |
+
2 rows in set (0.00 sec)
3.找出年龄大于38的员工的姓名,及其所在的部门名称
#答:
mysql> select staff.name,dep.name from staff inner join department as dep on dep.id=staff.dep_id where age>38;
+
| name | name |
+
| 典韦 | 挖矿小分队 |
+
1 row in set (0.00 sec)
4.以内连接的方式查询 staff 和 department表,并且以age字段的升序方式显示
答:
mysql> select * from staff inner join department as dep on dep.id=staff.dep_id order by age;
+
| id | name | sex | age | dep_id | id | name |
+
| 2 | 露娜 | female | 26 | 201 | 201 | 人力资源 |
| 4 | 王昭君 | female | 28 | 202 | 202 | 销售 |
| 1 | 程咬金 | male | 38 | 200 | 200 | 挖矿小分队 |
| 3 | 李白 | male | 38 | 201 | 201 | 人力资源 |
| 5 | 典韦 | male | 118 | 200 | 200 | 挖矿小分队 |
+
5 rows in set (0.05 sec)
5.找到部门为 挖矿小分队 和 人力资源 的所有员工的名字
#答:
mysql> select staff.name from staff inner join department as dep on dep.id = staff.dep_id where dep.name in ('挖矿小分队','人力资源');
+
| name |
+
| 程咬金 |
| 露娜 |
| 李白 |
| 典韦 |
+
4 rows in set (0.00 sec)
子查询
#1:子查询是将一个查询语句嵌套在另一个查询语句中。
#2:内层查询语句的查询结果,可以为外层查询语句提供查询条件。
#3:子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字
#4:还可以包含比较运算符:= 、 !=、> 、<等
#5: 多用连表查,因为连表查询比子查询效率高
1.用子查询 找到部门是销售的所有员工的姓名
#解题思路
①先找department表部门为销售的部门的id
mysql> select id from department where name = '销售';
+
| id |
+
| 202 |
+
1 row in set (0.00 sec)
②再找staff表中部门dep_id = 202
mysql> select name from staff where dep_id = 202;
+
| name |
+
| 王昭君 |
+
1 row in set (0.00 sec)
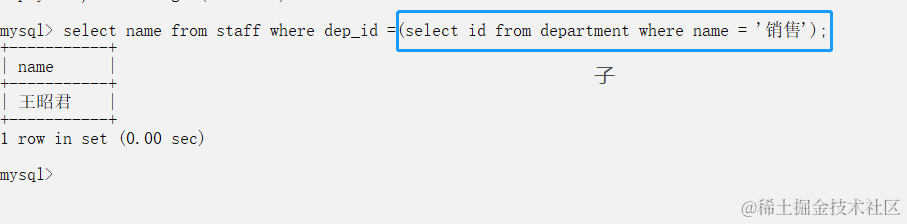
③字表查
mysql> select name from staff where dep_id =(select id from department where name = '销售');
+
| name |
+
| 王昭君 |
+
1 row in set (0.00 sec)
2.用子查询 找到部门为 销售 和 人力资源 的所有员工的名字
①先找department表部门为销售和人力资源的部门的id
mysql> select id from department where name = '销售' or name = '人力资源';
+
| id |
+
| 201 |
| 202 |
+
2 rows in set (0.00 sec)
②子查询
mysql> select name from staff where dep_id in (select id from department where name = '销售' or name = '人力资源');
+
| name |
+
| 露娜 |
| 李白 |
| 王昭君 |
+
3 rows in set (0.00 sec)
1. 带IN关键字的子查询
①查询平均年龄在28岁以上的部门名
select id,name from department
where id in
(select dep_id from staff group by dep_id having avg(age) > 28);
#结果
+
| id | name |
+
| 200 | 挖矿小分队 |
| 201 | 人力资源 |
+
2 rows in set (0.00 sec)
②查看部门是挖矿小分队员工姓名
select name from staff
where dep_id in
(select id from department where name='挖矿小分队');
#结果
+
| name |
+
| 程咬金 |
| 典韦 |
+
2 rows in set (0.00 sec)
③查看不足1人的部门名(子查询得到的是有人的部门id)
select name from department where id not in (select distinct dep_id from staff);
#结果
+
| name |
+
| 运营 |
+
1 row in set (0.02 sec)
2. 带比较运算符的子查询
#比较运算符:=、!=、>、>=、<、<=、<>
①查询大于所有人平均年龄的员工名与年龄
mysql> select name,age from staff where age > (select avg(age) from staff);
+
| name | age |
+
| 典韦 | 118 |
+
1 row in set (0.00 sec)
②查询大于部门内平均年龄的员工名、年龄
select t1.name,t1.age from staff t1
inner join
(select dep_id,avg(age) avg_age from staff group by dep_id) t2
on t1.dep_id = t2.dep_id
where t1.age > t2.avg_age;
#结果
+
| name | age |
+
| 李白 | 38 |
| 典韦 | 118 |
+
2 rows in set (0.04 sec)
3. 带EXISTS关键字的子查询
EXISTS关字键字表示存在。在使用EXISTS关键字时,内层查询语句不返回查询的记录。
而是返回一个真假值。True或False
当返回True时,外层查询语句将进行查询;当返回值为False时,外层查询语句不进行查询
#department表中存在dept_id=203,Ture
select * from staff
where exists
(select id from department where id=200);
#结果
+
| id | name | sex | age | dep_id |
+
| 1 | 程咬金 | male | 38 | 200 |
| 2 | 露娜 | female | 26 | 201 |
| 3 | 李白 | male | 38 | 201 |
| 4 | 王昭君 | female | 28 | 202 |
| 5 | 典韦 | male | 118 | 200 |
| 6 | 小乔 | female | 16 | 204 |
+
6 rows in set (0.00 sec)
#department表中存在dept_id=205,False
mysql> select * from staff
where exists
(select id from department where id=204);
Empty set (0.00 sec)


