本文主要介绍总体及样本的主成分的概念,如何可视化,以及一些最基本的性质。
1 总体的主成分
考虑x∼(μ,Σ),其中Σ可分解为Σ=ΓΛΓ′,Γ=(η1,…,ηd),各列为单位特征向量,Λ为特征值降序排列的对角矩阵,协方差矩阵的秩rank(Σ)=r,对于k=1,…,r,定义如下概念:
- 第k个principal component score(主成分得分)为wk=ηk′(x−μ);
- 第k个principal component vector(主成分向量)为w(k)=(w1,…,wk)′=Γk′(x−μ);
- 第k个principal component projection (vector)(主成分映射(向量))为pk=ηkηk′(x−μ)=wkηk。
我们来仔细看以上几个概念。ηk也叫载荷(loading),score xk其实就是x在方向ηk上的贡献,也就是将x投影到ηk,而将前k个score放到一起,就组成了x(k)。pk是一个d维向量,它的方向就是ηk的方向,长度/欧式范数为∣xk∣。
2 样本的主成分
假设我们有n个样本,将它们排成d×n的矩阵X=(x1,…,xn),记样本均值xˉ=n1Xℓn,样本协方差矩阵S=n−11(X−xˉℓn′)(X−xˉℓn′)′,并且rank(S)=r≤d。
我们可以对样本协方差矩阵进行谱分解S=Γ^Λ^Γ^′。与在总体中的定义一样,可以在样本中定义如下概念:
- 第k个principal component score为wk=η^k′(X−xˉℓn′),这是一个1×n的行向量;
- principal component data为W(k)=(w1′,…,wk′)′=Γ^k′(X−xˉℓn′),它是k×n的矩阵;
- 第k个principal component projection为Pk=η^kη^k′(X−xˉℓn′)=η^kwk,它是d×n的矩阵。
3 主成分的可视化
本节考察如何将PC的贡献、PC scores W(k)、PC projection Pk进行可视化。
3.1 Scree plot
对于总体数据,rank(Σ)=r,我们定义第k个PC,对总体协方差的贡献为
∑j=1rλjλk=tr(Σ)λk
再定义前κ个PC对总体协方差的累积贡献为
∑j=1rλj∑k=1κλk=tr(Σ)∑k=1κλk
对于不同k画出前k个PC的贡献和累积贡献,就得到了scree plot,如下图:
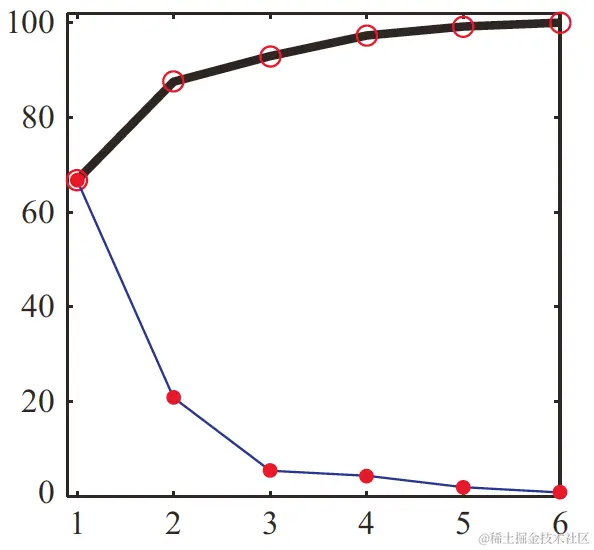
Scree plot中,有时可以找到elbow,传统方法是找出能比较好地代表数据的κ个点,就是elbow在的地方。有些文献中也叫knee或kink。在上图的例子中,elbow就是在第3个特征值处出现。当然,在很多情况下,也可能没有elbow。
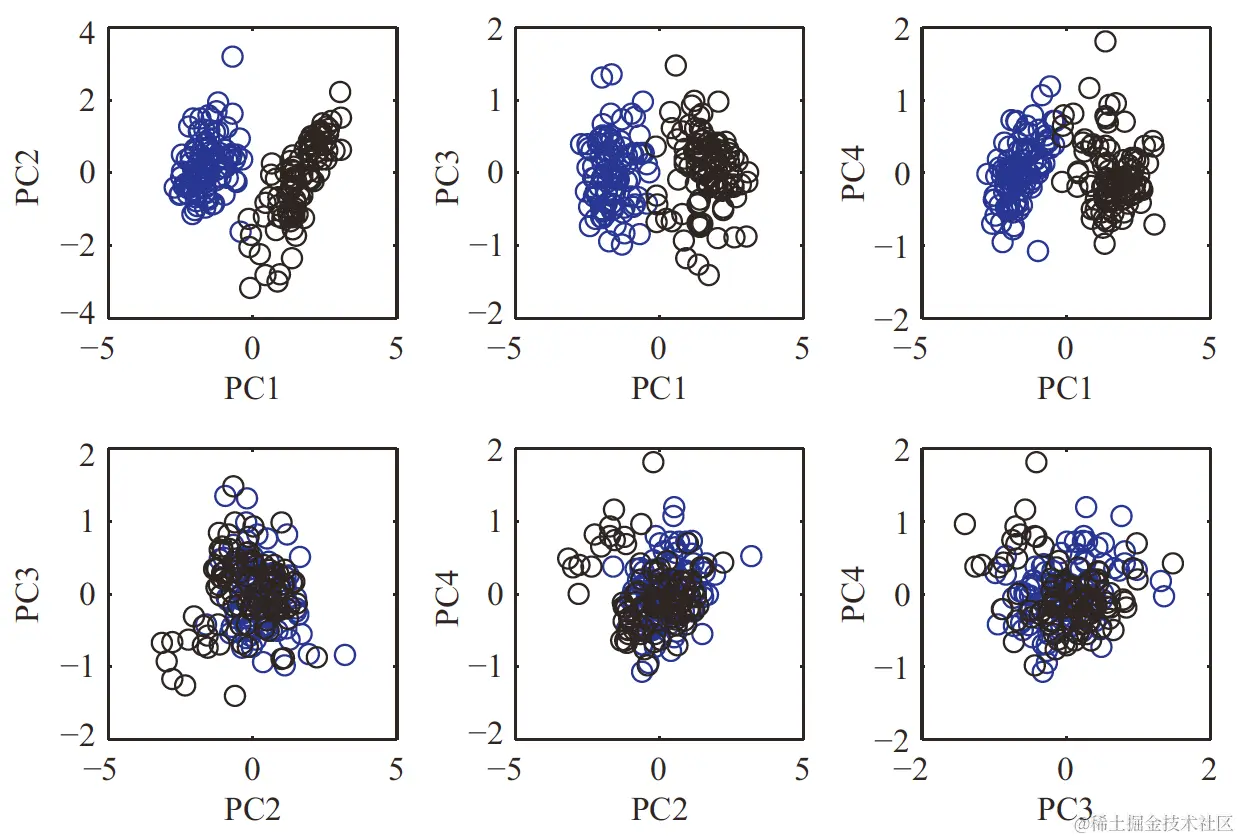
3.2 PC score plot
如果我们画出各PC的score,就叫PC score plot,但由于我们的视觉只能接受到三维的事物,因此对于超过三维,需要进行处理。比如对于W(4),我们可以成对地在二维平面上画出各PC的score,如下图:
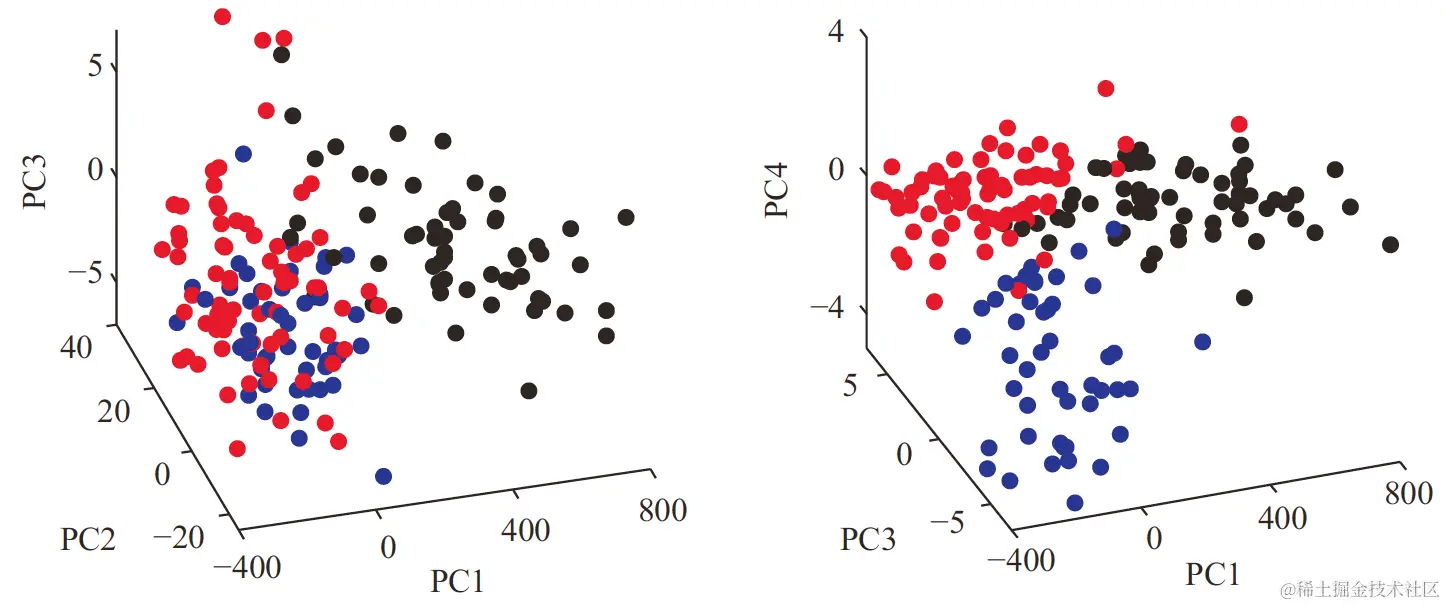
也可以直接画出三维图,如下图:
3.3 Projection plot
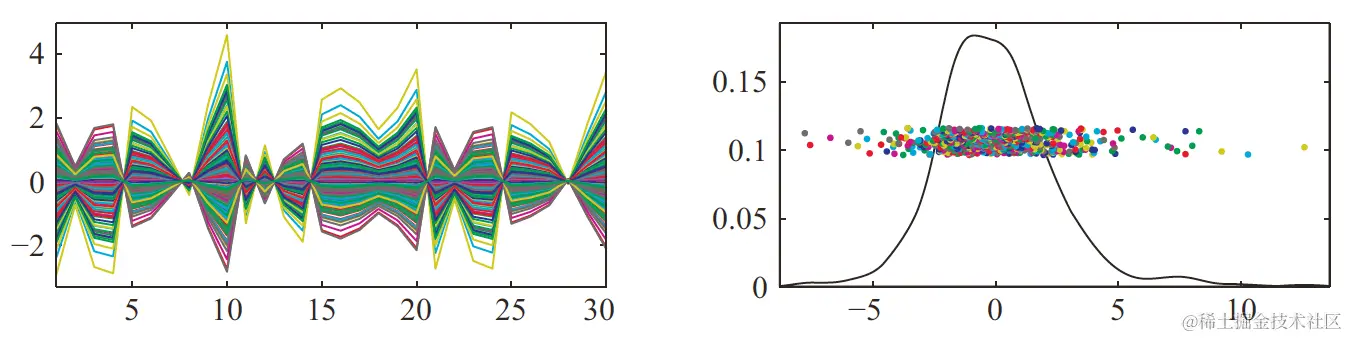
接下来看如何将Pk可视化。Pk为d×n的矩阵,它的第i列就是第i个样本在η^k方向的贡献。对于每个k,都可以用Pk画出平行坐标图,这样就很方便地将Pk可视化了。
第k个PC projection表示的其实就是用第k个score wk对向量η^k进行伸缩变换,因此也可以看一下这些score的分布,这就是密度估计(density estimates)。
下图是一个d=30的示例,左图为某个PC的projection plot,右图为非参数密度估计(可用Matlab工具curvdatSM):
4 PC的性质
4.1 结构性质
本节考虑PC的一些性质,先看X和它的PC的相关结构。这里采用第1节的设定。
首先来看w(k)=Γk′(x−μ),它的期望必满足E(w(k))=0,这说明PC vectors都是中心化了的。而它的方差
Var(w(k))====Γk′ΣΓkΓk′ΓΛΓ′ΓkIk×dΛId×kΛk
即PC scores互不相关。当然,如果x是正态分布,那么PC scores也相互独立,否则需要用其他方法做出相互独立。
而w(k)是由wk=ηk′(x−μ)作为元素组成的列向量,因此Var(wk)=λk,Cov(wk,wl)=ηk′Σηl=λkδkl,这里δkl是Kronecker delta function(δkk=1,对于k=l有δkl=0)。由于Λ为按特征值降序排列的对角矩阵,因此必有
Var(w1)≥Var(w2)≥⋯≥Var(wk)
对于Σ的特征值,有
∑j=1dλj=∑j=1dσj2
其中σj2为Σ的第j个对角线元素。这是因为Σ与Λ为相似矩阵,所以它们的迹一定相同。
如果用第2节中有关样本的设定,同样由于S=Γ^Λ^Γ^′,S与Λ^为相似矩阵,因此必有
j=1∑dλ^j=j=1∑dsj2
4.2 最优化性质
我们从另一个角度出发,来看主成分分析。
对于第1节中设定的总体x,假设Σ满秩,我们能不能找到一个d维的单位向量u,使得u′x的方差最大?
由于Σ满秩,那么它的d个特征向量可构成正交基,不妨设u=c1η1+⋯+cdηd,而u′u=1就等价于∑ici2=1,则方差
Var(u′x)====≤=u′Σuj,k∑cjckηj′Σηkj,k∑cjckλkηj′ηkj∑cj2λjλ1j∑cj2λ1
假设各特征值互不相同,那么上式只有当c12=1且cj=0(j=1)时等号成立,此时u=±η1。
接下来,我们寻找下一个u2,要求u2′x与η1′x不相关,并能使u′x的方差最大。同样可设u2=c1η1+⋯+cdηd,u2′x与η1′x不相关等价于u2′η1=0,此时又等价于c1=0,重复上述过程,可以解出u2′x的最大方差为λ2,此时u2=±η2。
不断重复上述过程,可以找出d个u。
如果rank(Σ)=r≤d,那么可找出r个特征值。如果特征值有重复,那么找出的u可能有多个解。

