在sklear中如何调用dbscan进行聚类
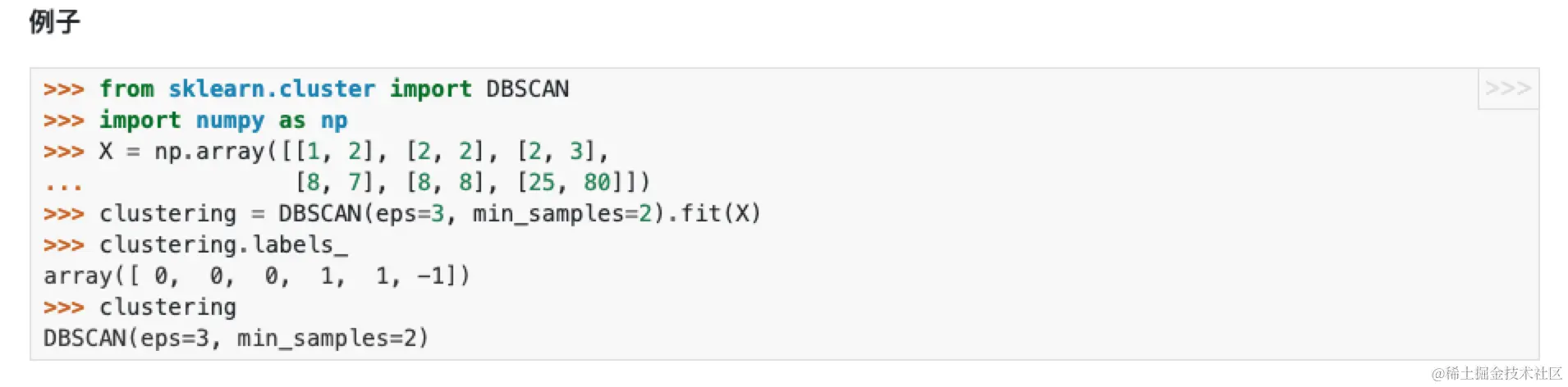
clustering = DBSCAN(xxx).fit()
# 如果想知道聚类的结果,需要clustering.labels_
clustering = DBSCAN(xxx).fit_predict()
# 该函数可以直接知道聚类的结果
clustering.get_params()是得到所有的参数
DBSCAN()算法有很多的参数:
class sklearn.cluster.DBSCAN(eps=0.5, *, min_samples=5, metric=
参数详述:
eps: 浮点型,邻域,可选,默认值是0.5
min_samples:整数,如果一个数据点的eps范围内有至少min_samples个数据点,则该数据点就是核心数据点
metrics: 字符串,默认是"euclidean",用于计算数据点之间的距离。有很多计算距离的衡量指标,比如欧式距离,余弦距离等。
metric_params: 字典,默认是None
algorithm: 算法,有{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}几个选项, 默认是’auto’
leaf_size: 整数,默认值是30,传递给球树,影响速度,内存,根据情况自己选择
p: 浮点型,默认是None,明氏距离的幂次,用于计算距离。
n_jobs: 整数,默认是None,cpu并行数。


