支持向量机(Support Vector Machine)
线性可分(Linear Separable):存在一条直线(2D)/平面(3D)/超平面(>=4dim),可以将两类分开
线性不可分(Nonlinear Separable):不存在一条直线/平面/超平面,可以将两类分开
1. 数学表达
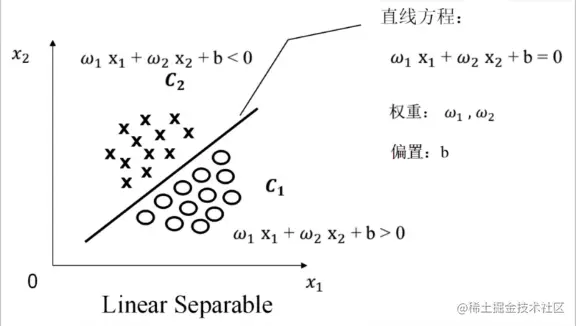
用数学严格定义训练样本以及他们的标签
假设 我们有N个训练样本和他们的标签{(X1,y1),(X2,y2),...,(XN,yN)}
其中Xi=[xi1,xi2]T, yi={+1,−1}
yi 是标签,如果Xi属于C1,则yi=+1; 如果Xi属于C2,则yi=−1.
用向量形式来定义线性可分
假设 Xi=[xi1xi2] w=[w1w2]
(1) 若yi=+1,则wTXi+b>0
(2) 若yi=−1,则wTXi+b<0
如果yi=+1或 −1,则一个训练样本集{(Xi,yi)},在i=1∼N线性可分,是指存在(w,b),使得对i=1∼N,有:yi(wTXi+b)>0
2. 如何解决线性可分问题
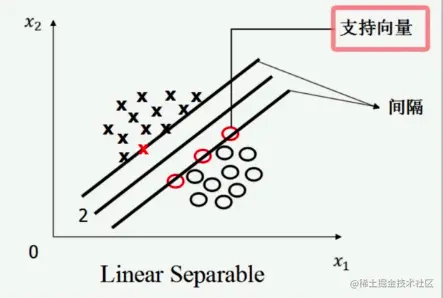
支持向量机寻找的最优分类直线应满足:
- 该直线分开了两类;
- 该直线最大化间隔(margin);
- 该直线处于间隔的中间,到所有支持向量距离相等。
扩展到多维环境,支持向量机要找一个超平面,使它的间隔最大,并且离两边所有支持向量的距离相等。为了推出最优问题,我们要注意以下事实。
事实一
wTx+b=0与 (awT)x+(ab)=0 是同一个超平面。 (a=0)
事实二
一个点X0到超平面wx+b=0的距离 d=∣∣w∣∣∣wTx0+b∣
基于事实一,我们用a去缩放w b,使得(w,b)→(aw,ab),最终在支持向量x0上有∣wTx0+b∣=1,而在非支持向量上 ∣wTx0+b∣>1.
基于事实二,支持向量x0到超平面的距离将会变为 d=∣∣w∣∣∣wTx0+b∣=∣∣w∣∣1. 由此可见,如果我们要最大化支持向量到超平面的距离,那么等价于最小化 ∣∣w∣∣. 因此我们把优化问题定为最小化 21∣∣w∣∣2,便于求导。
可证 ∂w∂21∣∣w∣∣2=w
其中w是一个n×1的向量,w=⎣⎡w1w2...wn⎦⎤.
综合上述事实,限制条件为:yi(wTxi+b)≥1,i=1∼N
其中1可以改为任意的正数。yi的作用是协调超平面的左右,使得一边wTxi+b>1,另一边wTxi+b<1.
综上所述,线性可分情况下,支持向量机寻找最佳超平面的优化问题可以表示为
上述问题是二次规划问题,目标函数是二次项,限制条件是一次项。
3. 如何解决线性不可分问题
我们需要放松限制条件,即对每个训练样本和标签,引入松弛变量(slack variable) δi.
限制条件改写为 yi(wTxi+b)≥1−δi (i=1∼N)
3.1 改造后的Opt SVM
- 最小化: 21∣∣w∣∣2+C∑i=1Nδi 或 21∣∣w∣∣2+C∑i=1Nδi2
- 限制条件:
- δi≥0 (i=1∼N)
- yi(wTxi+b)≥1−δi (i=1∼N)
其中比例因子C是人为事先设定的(算法的超参数),比如10000,在实际应用中不断变化C的值,同时测试算法的识别率,再选取最佳的超参数。
4. 低维到高维的映射
支持向量机的优点在于,它可以通过将特征空间由低维映射到高维来扩大可选函数范围,值得注意的是,SVM在高维空间中,仍然用线性超平面对数据进行分类。
这与其他类型的算法不同,例如人工神经网络、决策树,采用的是直接产生更多可选函数。比如在人工神经网络中,采用多层非线性函数的组合。
例子一
人为指定一个二维到五维的映射φ(x),线性不可分数据集变成了一个线性可分的数据集。

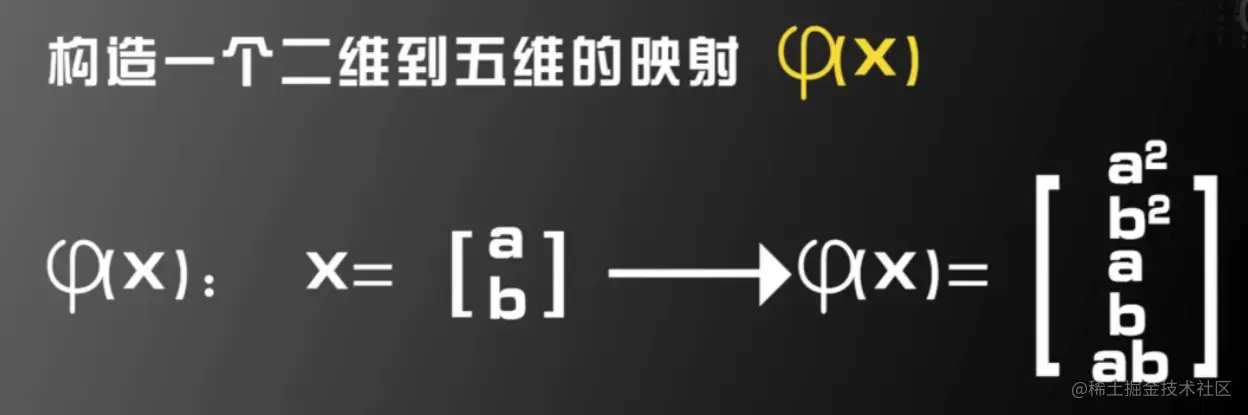
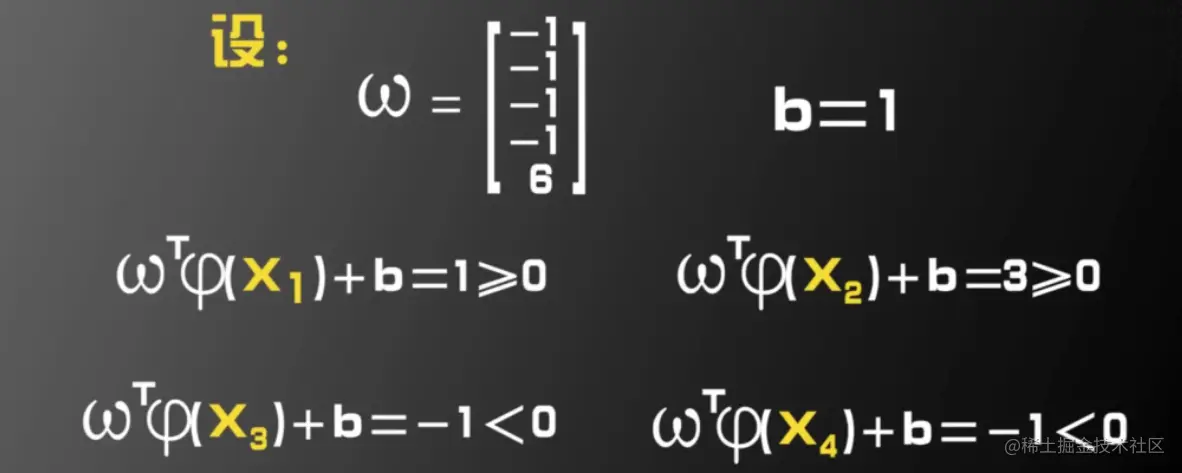
定理
假设: 在一个M维空间上随机取N个训练样本,随机地对每个训练样本赋予标签 +1或 -1。这些训练样本线性可分的概率为P(M)。那么,当M趋于无穷大时,P(M)=1。
理解: 当我们增加特征空间的维度M的时候,超平面待估计的的参数 (w,b) 会增加,整个算法模型的自由度也会增加,就更有可能分开低维时候无法分开的数据集。
结论: 将训练样本由低维映射到高维,能够增加线性可分的概率。
支持向量机优化问题
假设φ(x)已经确定,只需修改SVM中优化问题x为φ(x)即可。
- 最小化: 21∣∣w∣∣2+C∑i=1Nδi 或 21∣∣w∣∣2+C∑i=1Nδi2
- 限制条件:
- δi≥0 (i=1∼N)
- yi[wTφ(xi)+b]≥1−δi (i=1∼N)
-
所有的xi 被φ(xi)替代。
-
隐含的前提条件:在低维中,wi维度与xi维度相同,在高维中,w维度与φ(xi) 相同。
5. 核函数的定义
支持向量机创始人Vapnik在此问题上继续前进,他指出,我们可以不用知道φ(x)的具体形式,取而代之,如果对空间任意向量,我们知道K(X1,X2)=φ(X1)Tφ(X2),则仍然能通过SVM,计算wTφ(x)+b的值,进而得出x所属的类别。
定义核函数K 和映射 φ,它们是一一对应的关系。在说明如何通过核函数计算wTφ(x)+b之前,我们先研究核函数满足什么性质,才能存在φ(x),使得K(X1,X2)=φ(X1)Tφ(X2)。

上述充要条件即为Mercer's Theorem。可以举例高斯核函数K(X1,X2)=e−2σ2∣∣X1−X2∣∣2,满足Mercer's Theorem。但是在该例子中,φ(x) 不能写成显式表达式。尽管如此,我们依然能够通过一些方法知道wTφ(x)+b的值,从而知道一个测试样本x所属的类别。
6. 原问题(Prime Problem)和对偶问题(Dual Problem)
深入研究之前需要补充优化问题中的原问题与对偶问题的基础知识。
定义 复习凸优化:)嘿嘿
原问题(Prime Problem)
最小化(Minimize):f(w)
限制条件(Subject to):
gi(w)≤0 ,i=1∼K
hi(w)=0 ,i=1∼M
对偶问题(Dual Problem)
定义 L(w,α,β)=f(w)+∑i=1Kαigi(w)+∑i=1Mβihi(w)=f(w)+αTg(w)+βTh(w)
其中
α=[α1,α2,...,αK]T
β=[β1,β2,...,βM]T
g(w)=[g1(w),g2(w),...,gK(w)]T
h(w)=[h1(w),h2(w),...,hM(w)]T
对偶问题为
最大化(Maximize): θ(α,β)=infwL(w,α,β)
限制条件(Subject to):
αi≥0 ,i=1∼K
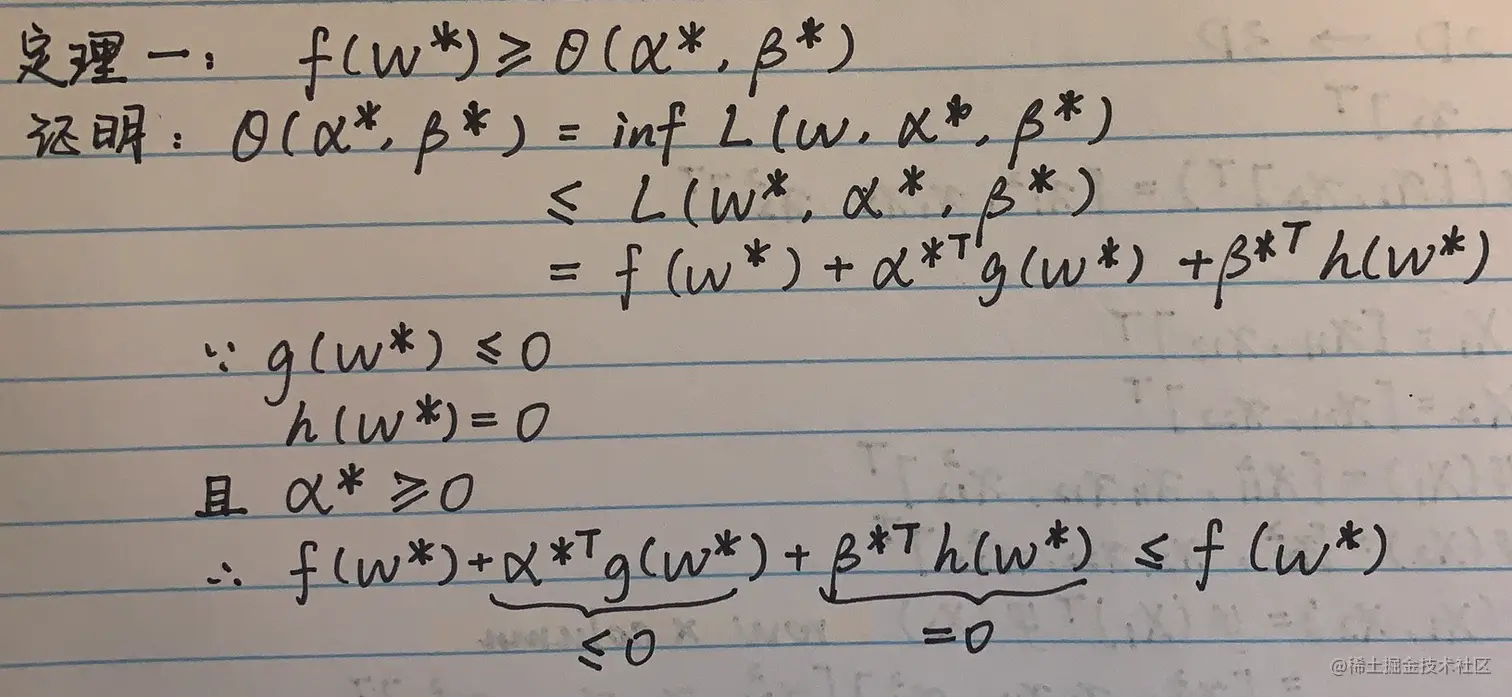
6.1 强对偶定理
如果原问题的目标函数是凸函数,限制条件是线性函数,则 f(w∗)=θ(α∗,β∗),此时的对偶差距f(w∗)−θ(α∗,β∗)等于0。
6.2 KKT条件
假如 f(w∗)=θ(α∗,β∗),则定理一中必然能够推出,对于所有的i=1∼K,αigi(w∗)=0,即要么 αi=0,要么 gi(w∗)=0。
7. SVM转化为对偶问题
7.1 原问题
- 最小化: 21∣∣w∣∣2+C∑i=1Nδi 或 21∣∣w∣∣2+C∑i=1Nδi2
- 限制条件:
- δi≥0 (i=1∼N)
- yi(wTφ(xi)+b)≥1−δi (i=1∼N)
首先将δi≥0 (i=1∼N)转换成δi≤0 (i=1∼N),得到
- 最小化: 21∣∣w∣∣2−C∑i=1Nδi或 21∣∣w∣∣2+C∑i=1Nδi2
- 限制条件:
- δi≤0 (i=1∼N)
- 1+δi−yi(wTφ(xi)+b)≤0 (i=1∼N)
容易发现,此时的限制条件都是线性的,而目标函数是凸的,满足强对偶定理。
接下来我们需要求解该对偶问题,值得注意的是,自变量w变成了(w,b,δi)。gi(w)包括两个不等式,并且该问题中不包括hi(w)。
7.2 对偶问题
针对21∣∣w∣∣2−C∑i=1Nδi来说:
- 最大化: θ(α,β)=infw,δ,b{21∣∣w∣∣2−C∑i=1Nδi+∑i=1Nβiδi+∑i=1Nαi[1+δi−yi(wTφ(xi)+b)]}
- 限制条件:
- αi≥0 (i=1∼N)
- βi≥0 (i=1∼N)
对(w,b,δi) 求导并令导数为0,
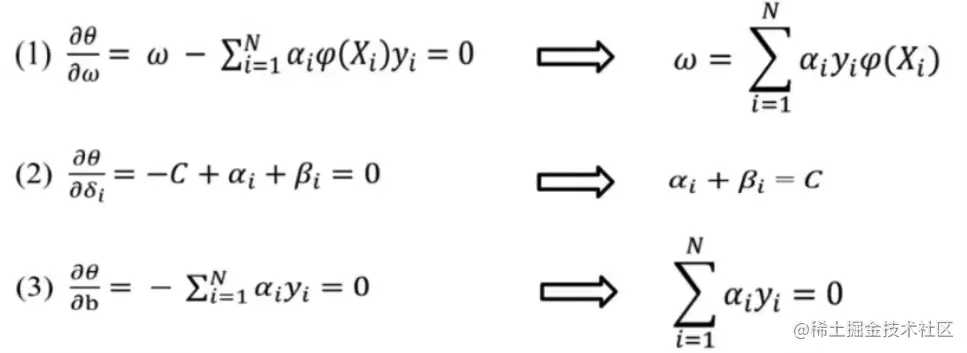
把(1)(2)(3)式代入目标函数,得到
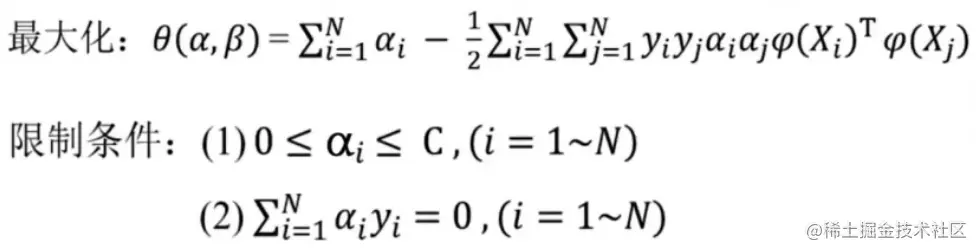
其中限制条件的第一条是基于αi≥0,βi≥0 且 αi+βi=C得到的。
8. 求解算法流程
上述问题也是一个二次规划问题,解此问题时,由于φ(Xi)Tφ(Xj)=K(Xi,Xj)核函数,所以我们只需要知道核函数,无需知道φ(X)的显式表达,就能求解这个对偶问题,得到αi,i=1∼N。解出α之后,可以根据w=∑i=1Nαiyiφ(Xi),得到w。
因为φ(x)不一定具有显式表达式,所以w也不一定具有显式表达式。下面将要说明,在不知道w的显式表达的情况下,我们也能计算wTx+b的值。
首先我们要求解b。
根据KKT条件,对于所有i=1∼N,有αi[1+δi−yi(wTφ(Xi)+b)]=0,且βiδi=0→(c−αi)δi=0。由于w=∑j=1Nαjyjφ(Xj),则wTφ(Xi)=∑j=1NαjyjφT(Xj)φ(Xi)=∑j=1NαjyjK(Xj,Xi)
另一方面,如果对某个i,αi=0且αi=c,则根据KKT条件,必有δi=0
1+δi−yi(wTφ(Xi)+b)=0
其中yiwTφ(Xi)=∑j=1NαjyiyjK(Xj,Xi)
所以只需要找一个 0<αi<c,则b能够被计算得到。
b=yi1−∑j=1NαiyiyjK(Xj,Xi)
下面考虑对于一个测试样本X,我们需要判断其所属的类别,我们计算
wTφ(X)+b=∑i=1Nαiyiφ(Xi)Tφ(X)+b=∑i=1NαiyiK(Xi,X)+b
由此可见,即使φ(x)未知,依然可以通过核函数来算出wTφ(X)+b。 【Kernal Trick】
8.1 结论
判决标准为:
如果∑i=1NαiyiK(Xi,X)+b≥0,那么X∈C1
如果∑i=1NαiyiK(Xi,X)+b<0,那么X∈C2
最终,我们只通过核函数,也能完成对X的类别判决。
8.2 一些常用核函数介绍
- (Linear)线性内核 K(X1,X2)=X1TX2 → 没有实用价值
- (Ploy)多项式核 K(X1,X2)=(X1TX2+1)d
- (Rbf)高斯径向基函数核 K(X1,X2)=e−2σ2∣∣X1−X2∣∣2→ 最常用的核函数
- (tanh)sigmoid核 K(X1,X2)=tanh(βX1TX2+b), tanh(x)=ex+e−xex−e−x
9. 国际象棋的兵王问题
图中是数据集样本,字母与数字对代表黑方王、白方王和白方兵在棋盘上的位置,"draw"表示和棋,"six"表示白方最多用六步将死黑方。


具体实例matlab见支持向量机(兵王问题MATLAB程序),注意其中svmtrain函数不适用于matlab2019之后的版本,需自行调整参数。
10. 识别系统的性能度量
不能简单地使用识别率来评价性能。
Confusion Matrix
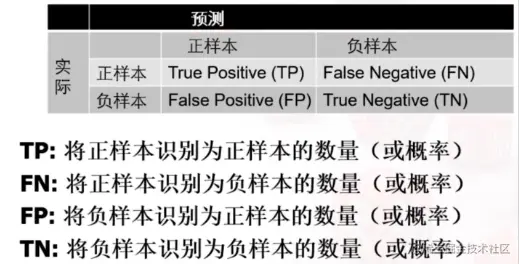
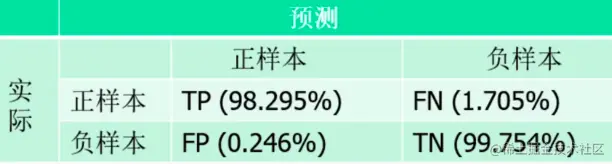
例如兵王问题中的混淆矩阵,总共有TP+FN个正样本,FP+TN个负样本,识别率为TP+FN+FP+TNTP+TN
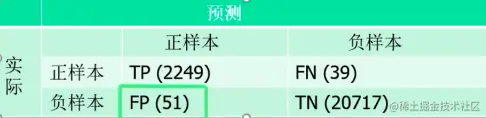
混淆矩阵的概率关系 TP+FN=1,FP+TN=1。
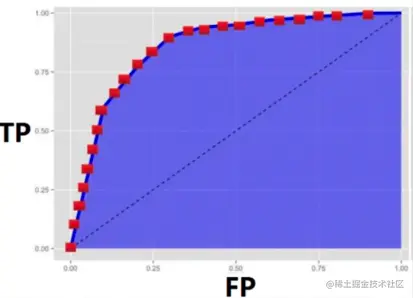
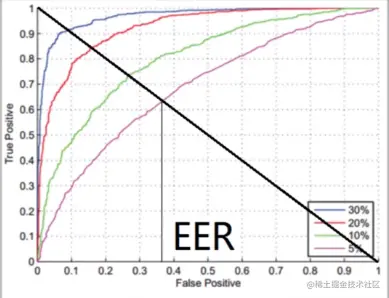
越贴近左上角的曲线,系统性能就越好。AUC越大,系统性能越好。EER越低,系统性能越好。
AUC
EER FP=FN
11. 处理多分类问题
SVM有三种方式处理多类问题,即类别大于2的问题:
- 改造优化的目标函数和限制条件 (不常用)
- 一类 VS 其他类
- 一类 VS 另一类
11.1 一类 VS 其他类
构造N个
设有C1,C2,C3三类
SVM1: (C1C2) VS (C3)
SVM2: (C1C3) VS (C2)
SVM3: (C2C3) VS (C1)
假设y=+1指向第一列的类,y=−1指向第二列的类。则可以通过hard decision来判断新样本X属于哪一类。
例如y=+1,y=+1,y=−1,则X∈C1。 如果y=+1,y=−1,y=−1,则落在C1或C2,需要根据αiyiK(Xi,X)+b的值进行soft decision,哪一个值越小(负得越多)就是在哪一个类里。
11.2 一类 VS 另一类
构造2N∗(N−1)个
设有C1,C2,C3三类
SVM1: (C1) VS (C2)
SVM2: (C1) VS (C3)
SVM3: (C2) VS (C3)


