

- DOM 很难用 (网页其实是一棵树,树就是底下有多个子节点,每个子节点下面又有很多个子节点)
- JS 如何操作这棵树呢? 浏览器window上加一个document即可(因为JS只能操作JS不能操作网页)
输入window.document你就得到一个文档,这个document包含了整个文档。只是拿到了一个节点,但是它底下有所有节点,只是拿到了最根的那个节点。
window.document可以获得整个网页的所有元素。
- JS就是使用document来操纵整个网页,这就是Document Object Model文档对象模型。(DOM)
获取元素,也叫作标签
①获取任意元素
- 有很多API
window.idXXX 或者直接 idXXX
document.getElementById('idXXX') //这个方法不如上面的方法容易,有的时候有用
document.getElementsByTagName('div')[0] //尽量不用
document.getElementsByClassName('red')[0] //尽量不用
document.querySelector('#idxxx')
document.querySelectorAll('red')[0]
用哪一个?
- 工作中用querySelector和querySelectorAll
- 做demo直接用idxxx (不要被人发现~)
- 如果要兼容ie可能要用getElement(s)ByXXX
这个是最简单的方式(常用的方式)window.id名字或者id名字

如果是修改了 id 的名字的话就需要使用document.getElementById('idXXX')
譬如是我把 id 名字 user_email_control 改成了 blank
那么我运行 window.user_email_control 运行出了 undefined
那么我就需要使用document.getElementById('blank(被我修改后的id名字)')这样进行获取元素。
所以大部分情况下,只要你的名字不和全局的属性冲突,你就可以直接用这个id名字来获取元素。如果不小心冲突了那么就使用document.getElementById('idXXX')这样来进行获取
document.getElementsByTagName('div')[0] 这个的意思是找到所有标签名为div的元素。注意这个找到的是数组这里的 element 是带了 s 的!!!所以后面要记得带 [0] 或者 [1] [2] [3] 等等类似的下标才能操作对应的div 当然可以遍历
这个数组标签前面是个伪数组啊!!!
说明一个问题就是 document.getElementsByTagName('div')这个输入进去你获取到的是一个整体啊,但是你却不能够操作任何一个,因为这个是一个整体。
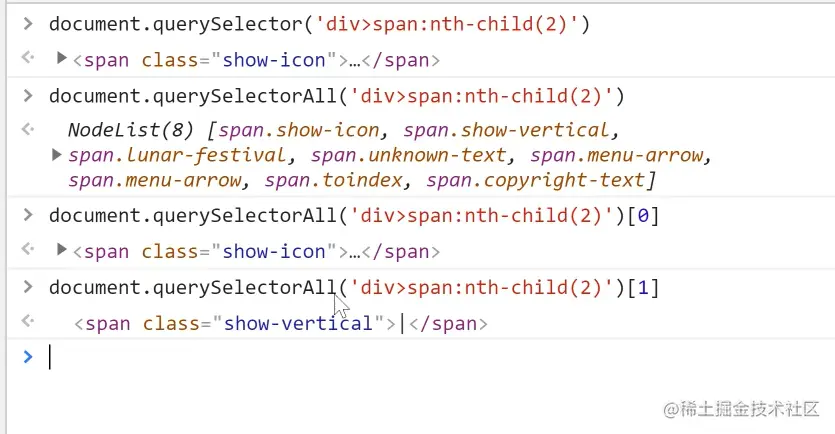
document.querySelector('')括号‘’里面的内容可以非常的复杂,css能写的基本都可以写在里面
②获取特定元素
- 获取html元素 document.documentElement
小写标签名字打出来就是大写(dom反人类的地方)
- 获取head元素 document.head
- 获取body元素 document.body
- 获取窗口(窗口不是元素)window 获取的是一个对象,但是有时候要进行对window全局的事件其的监听,那么就会使用到。 例如
window.onclick => (){
console.log('hi');}
- 获取所有元素 document.all 这个document.all比较奇怪,第6个falsy值
if(document.all){console.log(3)}else{console.log(4)}
说明了一个问题,document.all这个对象是假的,因为打印出了4
是因为document.all是否存在用来检测当前页面是不是ie浏览器
document.all[下标] 如果直接用的确可以直接进行查找元素
