内容进度按照UNSW COMP9315课程来进行
个人课堂笔记,如有错误欢迎指正
Indexing 索引
indexing的作用
和图书馆中书的索引原理差不多。例如,为了确定一个学生id对应的学生记录,首先dbms会查找索引然后确定record所在的磁盘块,然后扫描该磁盘块来取得所需要的student记录
索引,意义上应该是一种组织文件的方式或者数据结构
(百度百科定义)在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
索引的类型
一般有两个大类
1.顺序索引
2.散列索引
按照磁盘上文件的顺序,有以下几种分类,其中,search key
(搜索码)可以认为是用来查找文件的一个属性或者属性集合
1. primary index, search key是unique的,文件的记录可能按照key来排序
2. clustering index, search key是non-unique field, 而且文件的记录一定按照key来排序
3. 相反如果顺序不遵从search key则称为non-clustering index, 或者secondary index (而且search key不是unique??)
如下图所示,就是一个non-clustring index (磁盘文件记录组织方式和search key的顺序不一样)
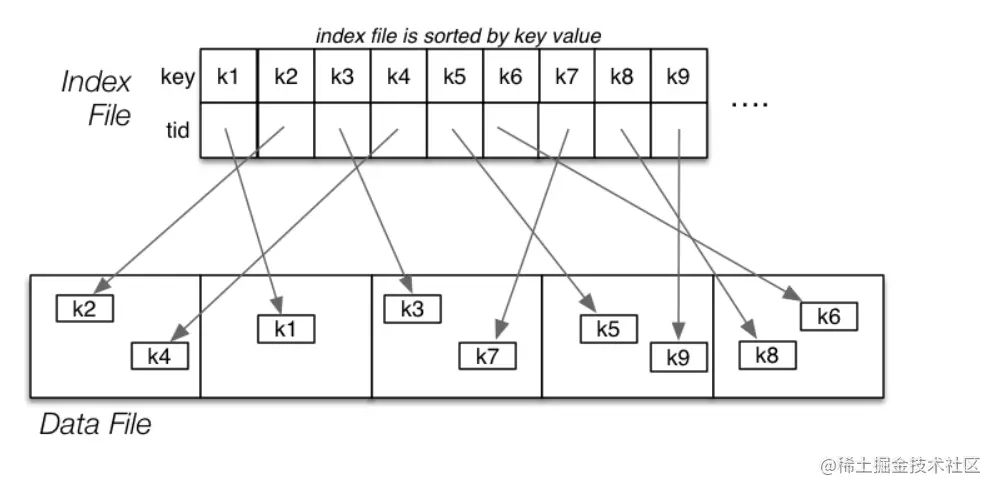
index-entry(索引项)定义,search key和pointer的结合,类似上图中的key+箭头的组合共同构成entry
根据search key的疏密程度,index还可以被分类为
1. dense index (稠密),每一个search key都有一个entry,上图就是一个稠密索引的例子
2. sparse index(稀疏),只有部分search key才有entry
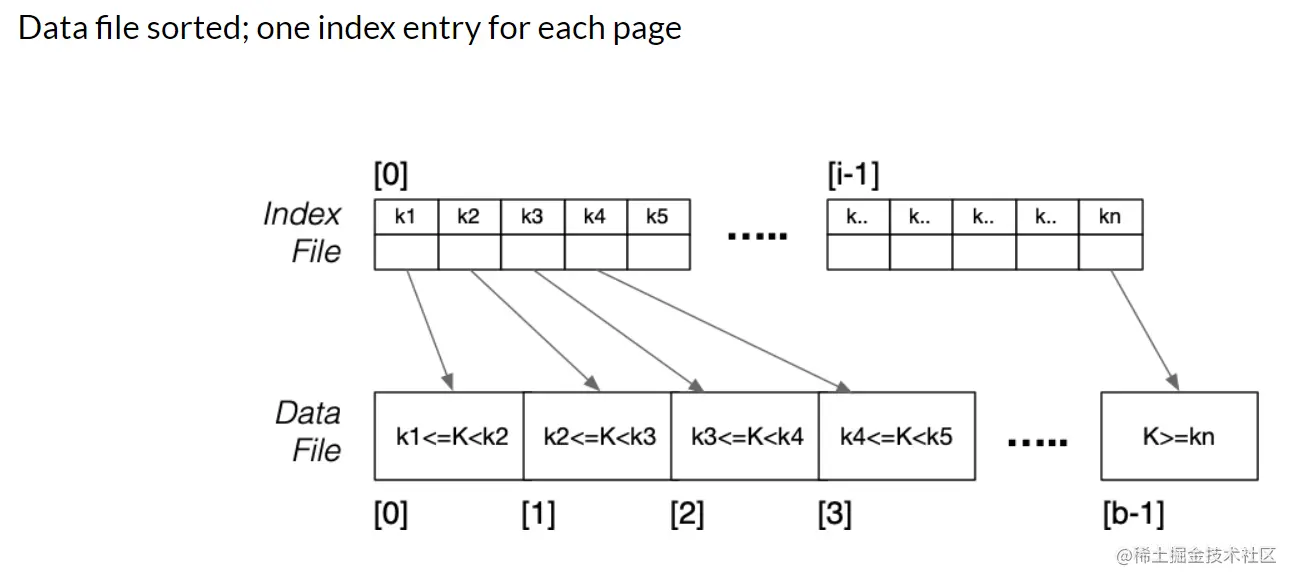
下图为定义

sparse indexing的例子,可见,在一定范围的key之内只有一个search key具有entry。如k1,当查找文件的时候,先定位到k1指向的文件块的位置,然后顺着这个指针搜索,直到查找到相应的文件为止
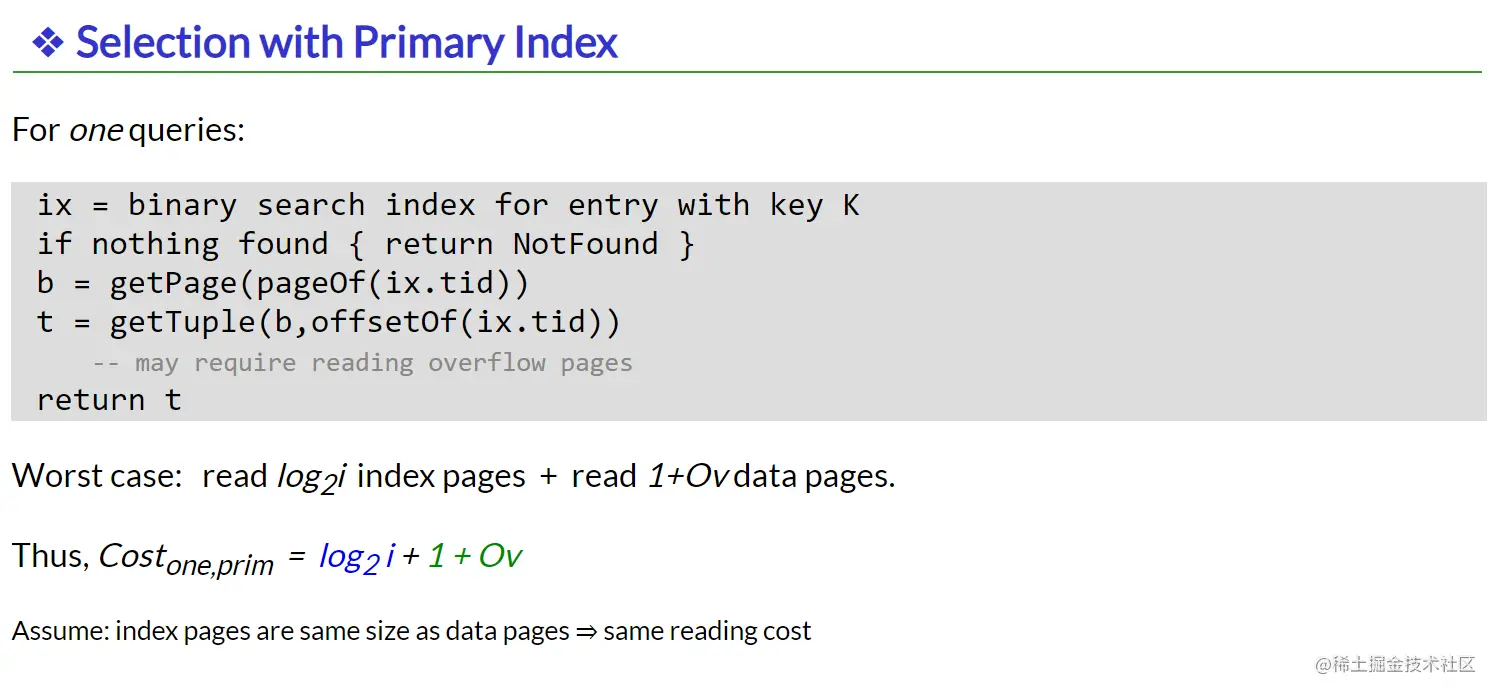
Selection
primary index下的selection查找效率,entry用二进制搜索来定位。找到entry之后可以直接定位在文件中的位置(因为是dense index)
针对range queries的算法,如select * from R where a between lo and hi
首先这是一个primary index的例子,说明search key,也就是a?是唯一的,不存在一个对应多个tuple的情况(tuple就是记录)
1. 首先根据lower bound找到一个初始的page
2. 然后在getnextpage上进行循环,每次都取page中的第一个tuple出来判断其中的key是否 >hi,如果为true,退出循环。将循环的page加入{}中
3. 在pages={}进行循环,找到其中满足a大于lo而小于hi的tuple,返回结果
(R.ixf是啥??这一块不知道理解的有没有问题)

Insertion (忽略)
Delete (忽略)‘
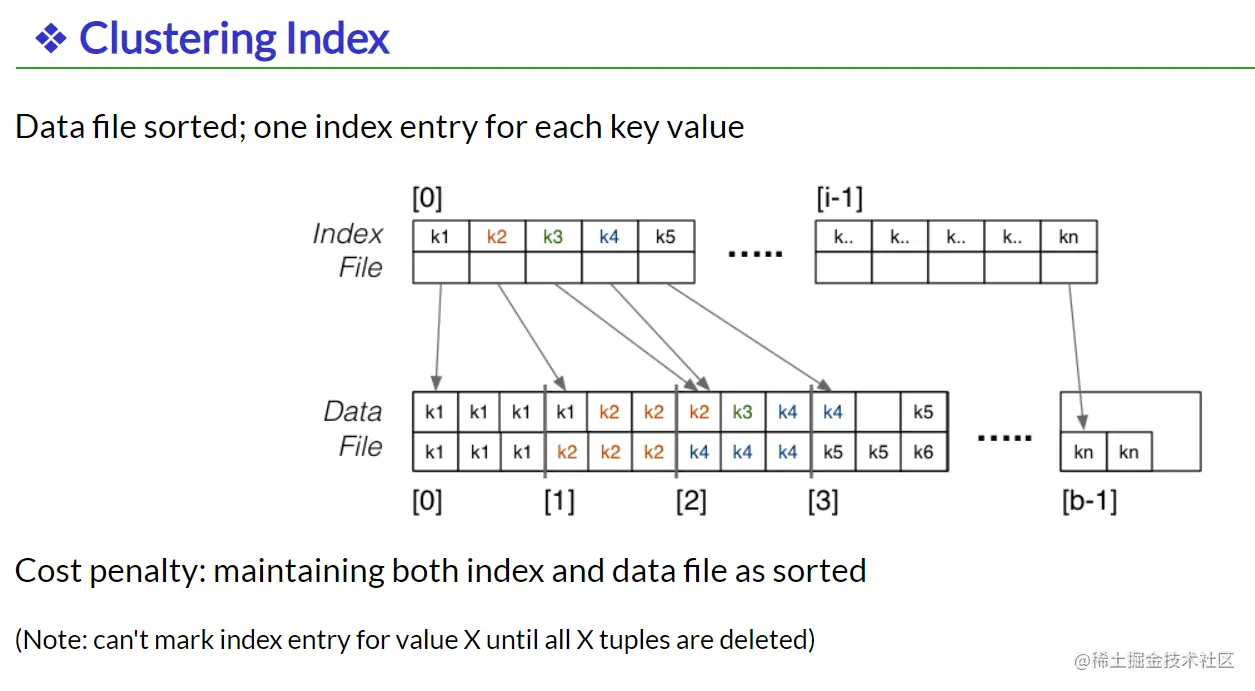
Clustering index
Clustering 中,key不是唯一的(如k1,就有多个),但是文件是根据index排序好了,所以也可以索引到相应位置
multi-level indexing
多重的索引,可以应对更大的数据量


