mapreduce-1.概览
MapReduce过程
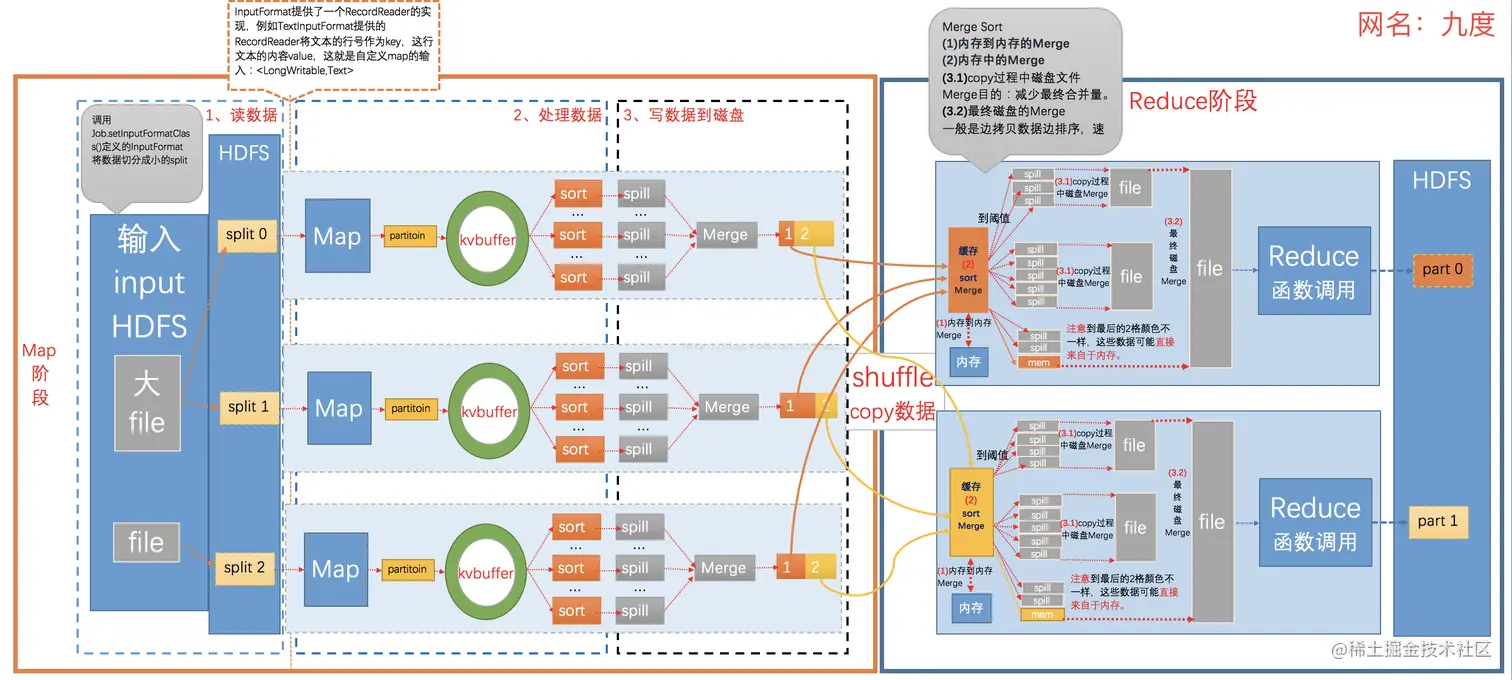
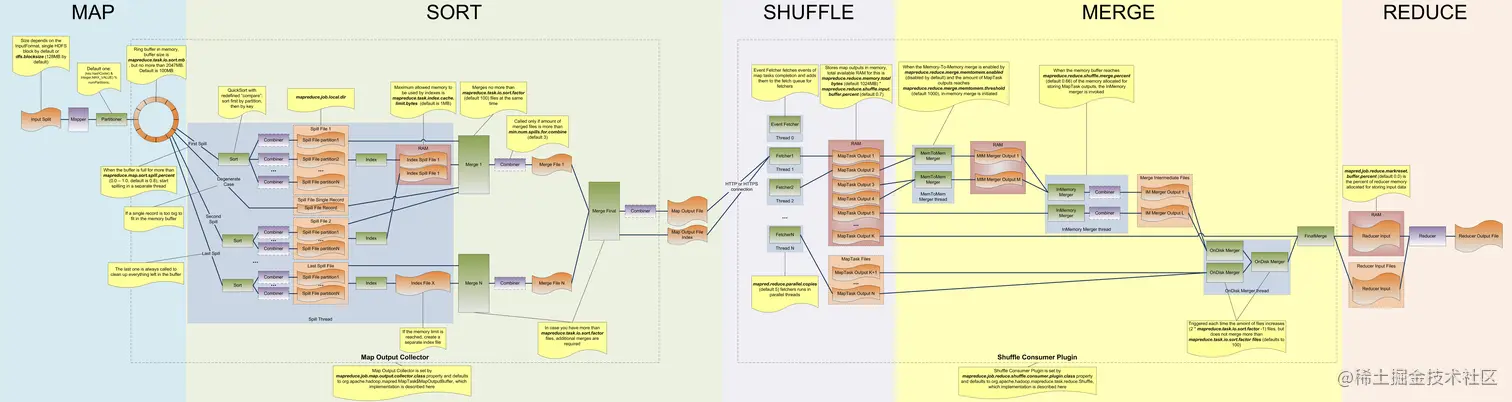
- Map 在MapTask执行时,其输入数据来源于HDFS的Block。例如一个目录下有三个文件大小分别为:5M 10M 150M 这个时候其实会产生四个Mapper处理的数据分别是5M,10M,128M,22M。
- Partition 在经过Mapper运行后,MapReduce提供了Partitioner接口,其作用是根据Key或Value及Reduce的数量来决定当前这对输出数据最终应该交由哪个ReduceTask处理。默认是对key哈希后再以reduce task数量取模,默认的取模方式只是为了避免数据倾斜。接下来需要将数据写入内存缓冲区中。缓冲区的作用就是批量收集Map结果,减少磁盘I/O影响。
- Splil: Spill这个重要的过程是由Spill线程承担,Spill线程从Map任务接到“命令”之后就开始正式干活,干的活叫SortAndSpill。Map的输出结果是由collector处理的,每个Map任务不断地将键值对输出到在内存中构造的一个环形数据结构Kvbuffer中,大小默认100M。内存缓冲区的大小是有限的,默认是100MB。可以通过mapreduce.task.io.sort.mb(default:100)参数来调整。可以根据不同的硬件尤其是内存的大小来调整,调大的话,会减少磁盘spill的次数此时如果内存足够的话,一般都会显著提升性能。spill一般会在Buffer空间大小的80%开始进行spill(因为spill的时候还有可能别的线程在往里写数据,因为还预留空间,有可能有正在写到Buffer中的数据),可以通过mapreduce.map.sort.spill.percent(default:0.80)进行调整。
- Combine(可选): Combiner存在的时候,此时会根据Combiner定义的函数对map的结果进行合并,什么时候进行Combiner操作呢???和Map在一个JVM中,是由min.num.spill.for.combine的参数决定的,默认是3,也就是说spill的文件数在默认情况下有三个的时候就要进行combine操作,最终减少磁盘数据
- Merge: Map Task在计算的时候会不断产生很多spill文件,在Map Task结束前会对这些spill文件进行合并,这个过程就是merge的过程。mapreduce.task.io.sort.factor(default:10),代表进行merge的时候最多能同时merge多少spill,如果有100个spill个文件,此时就无法一次完成整个merge的过程,这个时候需要调大mapreduce.task.io.sort.factor(default:10)来减少merge的次数,从而减少磁盘的操作。
- Compress(可选): 减少磁盘IO和网络IO还可以进行:压缩,对spill,merge文件都可以进行压缩。中间结果非常的大,IO成为瓶颈的时候压缩就非常有用,可以通过mapreduce.map.output.compress(default:false)设置为true进行压缩,数据会被压缩写入磁盘,读数据读的是压缩数据需要解压,在实际经验中Hive在Hadoop的运行的瓶颈一般都是IO而不是CPU,压缩一般可以10倍的减少IO操作,压缩的方式Gzip,Lzo,BZip2,Lzma等,其中Lzo是一种比较平衡选择,mapreduce.map.output.compress.codec(default:org.apache.hadoop.io.compress.DefaultCodec)参数设置。但这个过程会消耗CPU,适合IO瓶颈比较大。
- Copy过程。即简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求MapTask所在的NodeManager获取MapTask的输出文件。因为MapTask早已结束,所以这些文件就由NodeManager管理。
- Merge阶段。同Map端的Merge动作,只是数组中存放的是不同Map端复制过来的数据。复制过来 数据会先放到内存缓冲区中,当内存中的数据达到一定阈值时,就会启动内存到磁盘的Merge。与Map端类似,这也是溢写过程,会在磁盘中形成众多的溢写文件,然后将这些溢写文件进行归并。
- Reducer的输出文件。不断地进行Merge后,最后会生成一个“最终文件"。这个文件可能存放在磁盘,也可能存放在内存中,默认存放在磁盘上。当Reducer的输入文件已定时,整个Shuffle过程才最终结束。


