


前言
ArrayList 我们几乎每天都会使用到,平时非常熟悉,但真正面试的时候,发现还是有不少人对源码细节说不清楚,给面试官留下基础比较差的印象,从而面试凉凉了。本小节就和大家一起看看 ArrayList 相关的源码。
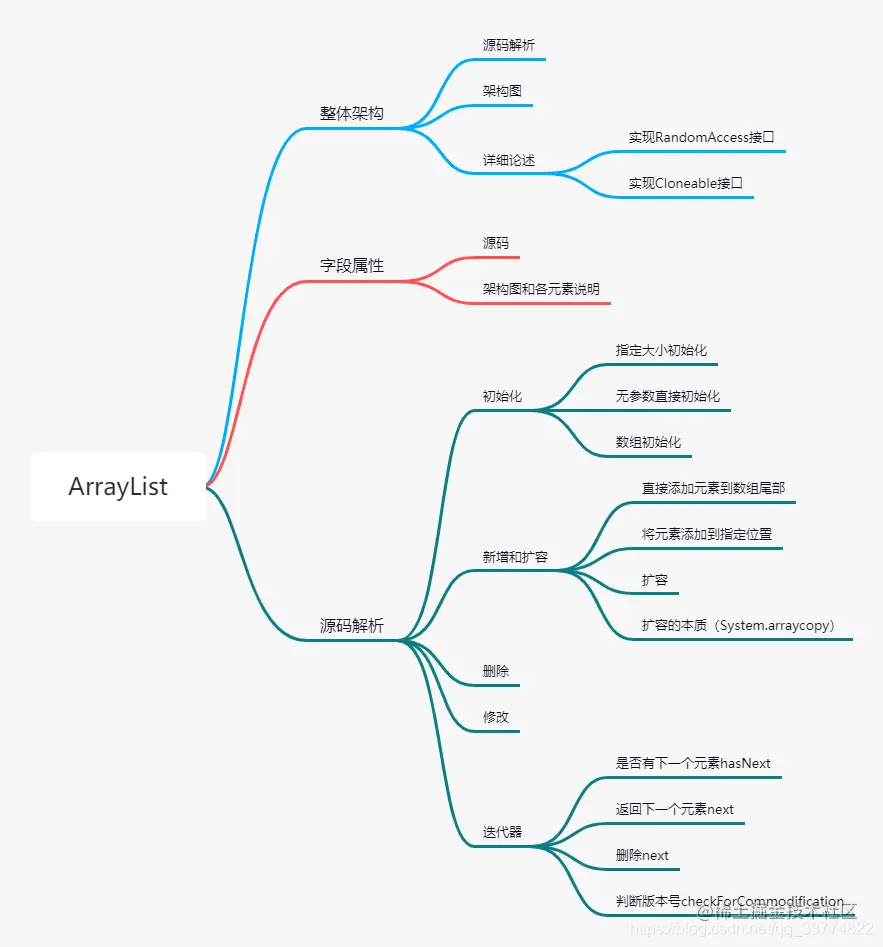
1.整体架构
1.1源码解析
ArrayList 是一个用数组实现的集合,支持随机访问,元素有序且可以重复,继承了AbstractList,实现了List,RandomAccess,Clone,Serializable接口等,具体代码如下:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
1.2架构图
1.3详细论述
1.3.1实现 RandomAccess 接口
这是一个标记接口,我们可以看到接口中为空,public interface RandomAccess {},一般此标记接口用于 List 实现,主要目的是允许通用算法改变其行为,以便在应用于随机或顺序访问列表时提供良好的性能。
然而又有人问,快速随机访问是什么东西?有什么作用?
通过查看Collections类中的binarySearch()方法,源码如下:
public static <T>
int binarySearch(List<? extends Comparable<? super T>> list, T key) {
if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
return Collections.indexedBinarySearch(list, key);
else
return Collections.iteratorBinarySearch(list, key);
}
由此可以看出,判断list是否实现RandomAccess接口来实行**indexedBinarySerach(list,key)或iteratorBinarySerach(list,key)**方法。
(instanceof其作用是用来判断某对象是否为某个类或接口类型)
1.3.2实现 Cloneable 接口
这个类是 java.lang.Cloneable,Cloneable 和 RandomAccess 接口一样也是一个标记接口,接口内无任何方法体和常量的声明,也就是说如果想克隆对象,必须要实现 Cloneable 接口,表明该类是可以被克隆的。
我们可以看下ArrayList中如何重写clone方法的,具体代码如下。
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
从上面的代码我们可以知道两点:
1.底层采用的是Arrays的copyOf方法,也就是System.arraycopy,此为native方法。
2.如果当前类没有继承clone接口,是会抛出异常的,也就是CloneNotSupportedException异常。
2.字段属性
2.1源码
ArrayList 整体架构比较简单,就是一个数组结构,比较简单,如下图长度为 10 的数组:
2.2架构图和各元素说明
DEFAULT_CAPACITY :表示数组的初始大小,默认是 10,这个数字要记住;
EMPTY_ELEMENTDATA:表示空的数组。elementData:表示Object类型的数组。
size: 表示当前数组的大小,类型 int,没有使用 volatile 修饰,非线程安全的;
3.源码解析
3.1 初始化
我们有三种初始化办法:无参数直接初始化、指定大小初始化、指定初始数据初始化,源码如下:
3.1.1指定大小初始化
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
需要注意的是:初始化集合大小创建 ArrayList 集合。当大于0时,给定多少那就创建多大的数组;当等于0时,创建一个空数组;当小于0时,抛出异常。
3.1.2无参数直接初始化
public ArrayList() {
//无参数直接初始化,数组大小为空
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
需要注意的是:此无参构造函数将创建一个 DEFAULTCAPACITY_EMPTY_ELEMENTDATA 声明的数组,注意此时初始容量是0,而不是大家以为的 10。
3.1.3数组初始化
public ArrayList(Collection<? extends E> c) {
//elementData 是保存数组的容器,默认为 null
elementData = c.toArray();
//如果给定的集合(c)数据有值
if ((size = elementData.length) != 0) {
//如果集合元素类型不是 Object 类型,我们会转成 Object
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// 给定集合(c)无值,则默认空数组
this.elementData = EMPTY_ELEMENTDATA;
}
}
3.2 新增和扩容实现
3.2.1直接添加元素到数组尾部
如果直接把元素添加到数组的尾部,需要先判断当前的数组长度是否可用,是否需要扩容,然后再进行赋值操作。
注意:这边赋值操作只有一行,并且线程不安全,没有考虑并发的场景。
//把元素添加到数组尾部
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
3.2.2将元素添加到指定位置
如果把元素添加到指定位置,第一步先判断当前的下标index是否有效,第二步和上面的一样,判断当前的数组长度是否可用,是否需要扩容,第三步采用native方法System.arraycopy来进行数组的复制操作,最后完成元素的赋值。
注意:赋值操作同样是线程不安全的,没有考虑并发的场景。
//把元素添加到指定位置
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
3.2.3扩容
我们先看下扩容(ensureCapacityInternal)的源码:
private void ensureCapacityInternal(int minCapacity) {
//如果当前数组为空,则取给定数组大小和默认数组大小的最大值
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
//确保容积足够
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
//记录数组被修改
modCount++;
// 如果我们期望的最小容量大于目前数组的长度,那么就扩容
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
//扩容,并把现有数据拷贝到新的数组里面去
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
// oldCapacity >> 1 是把 oldCapacity 除以 2 的意思
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 如果扩容后的值 < 我们的期望值,扩容后的值就等于我们的期望值
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 如果扩容后的值 > jvm 所能分配的数组的最大值,那么就用 Integer 的最大值
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 通过复制进行扩容
elementData = Arrays.copyOf(elementData, newCapacity);
}
注解应该比较详细,我们需要注意的四点是:(注意注意😝)
• 扩容的规则并不是翻倍,是原来容量大小 + 容量大小的一半,也就是扩容后的大小是原来容量的 1.5 倍;
• ArrayList 中的数组的最大值是 Integer.MAX_VALUE,超过这个值,抛出 OutOfMemoryError 异常。
• 新增时,并没有对值进行严格的校验,所以能向集合中添加 null 的,因为数组可以有 null 值存在。
• 赋值是非常简单的,直接往数组上添加元素即可:elementData [size++] = e。也正是通过这种赋值方式,线程是不安全的。
3.2.4 扩容的本质
扩容是通过这行代码来实现的:Arrays.copyOf(elementData, newCapacity);,这行代码描述的本质是数组之间的拷贝,扩容是会先新建一个符合我们预期容量的新数组,然后把老数组的数据拷贝过去,我们通过 System.arraycopy 方法进行拷贝,此方法是 native 的方法,源码如下:
/**
* @param src 被拷贝的数组
* @param srcPos 从数组那里开始
* @param dest 目标数组
* @param destPos 从目标数组那个索引位置开始拷贝
* @param length 拷贝的长度
* 此方法是没有返回值的,通过 dest 的引用进行传值
*/
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
通过查看源代码可以发现该方法声明为native,也就是说是本地方法,不是用Java写的。Java可以通过JNI来调用其他语言(主要还是C/C++语言)编写的方法。本文中就通过查看OpenJDK中的源码,简单分析一下System.arraycopy()方法的实现。
简而言之,System.arraycopy是通过c/c++的指针来实现赋值操作。
1、打开openjdk\hotspot\src\share\vm\prims\jvm.cpp可以看到一个方法JVM_ArrayCopy,但是该方法没有真正实现复制的代码,而是简单的检测源数组和目的数组不为空,排除一些异常情况
/*
java.lang.System中的arraycopy方法
*/
JVM_ENTRY(void, JVM_ArrayCopy(JNIEnv *env, jclass ignored, jobject src, jint src_pos,
jobject dst, jint dst_pos, jint length))
JVMWrapper("JVM_ArrayCopy");
// Check if we have null pointers
//检查源数组和目的数组不为空
if (src == NULL || dst == NULL) {
THROW(vmSymbols::java_lang_NullPointerException());
}
arrayOop s = arrayOop(JNIHandles::resolve_non_null(src));
arrayOop d = arrayOop(JNIHandles::resolve_non_null(dst));
assert(s->is_oop(), "JVM_ArrayCopy: src not an oop");
assert(d->is_oop(), "JVM_ArrayCopy: dst not an oop");
// Do copy
//真正调用复制的方法
s->klass()->copy_array(s, src_pos, d, dst_pos, length, thread);
JVM_END
2、openjdk\hotspot\src\share\vm\oops\objArrayKlass.cpp文件中copy_array方法
/*
java.lang.System中的arraycopy方法具体实现
*/
void ObjArrayKlass::copy_array(arrayOop s, int src_pos, arrayOop d,
int dst_pos, int length, TRAPS) {
//检测s是数组
assert(s->is_objArray(), "must be obj array");
//目的数组不是数组对象的话,则抛出ArrayStoreException异常
if (!d->is_objArray()) {
THROW(vmSymbols::java_lang_ArrayStoreException());
}
// Check is all offsets and lengths are non negative
//检测下标参数非负
if (src_pos < 0 || dst_pos < 0 || length < 0) {
THROW(vmSymbols::java_lang_ArrayIndexOutOfBoundsException());
}
// Check if the ranges are valid
//检测下标参数是否越界
if ( (((unsigned int) length + (unsigned int) src_pos) > (unsigned int) s->length())
|| (((unsigned int) length + (unsigned int) dst_pos) > (unsigned int) d->length()) ) {
THROW(vmSymbols::java_lang_ArrayIndexOutOfBoundsException());
}
// Special case. Boundary cases must be checked first
// This allows the following call: copy_array(s, s.length(), d.length(), 0).
// This is correct, since the position is supposed to be an 'in between point', i.e., s.length(),
// points to the right of the last element.
//length==0则不需要复制
if (length==0) {
return;
}
//UseCompressedOops只是用来区分narrowOop和oop,具体2者有啥区别需要再研究
//调用do_copy函数来复制
if (UseCompressedOops) {
narrowOop* const src = objArrayOop(s)->obj_at_addr<narrowOop>(src_pos);
narrowOop* const dst = objArrayOop(d)->obj_at_addr<narrowOop>(dst_pos);
do_copy<narrowOop>(s, src, d, dst, length, CHECK);
} else {
oop* const src = objArrayOop(s)->obj_at_addr<oop>(src_pos);
oop* const dst = objArrayOop(d)->obj_at_addr<oop>(dst_pos);
do_copy<oop> (s, src, d, dst, length, CHECK);
}
}
do_copy方法
// Either oop or narrowOop depending on UseCompressedOops.
template <class T> void ObjArrayKlass::do_copy(arrayOop s, T* src,
arrayOop d, T* dst, int length, TRAPS) {
BarrierSet* bs = Universe::heap()->barrier_set();
// For performance reasons, we assume we are that the write barrier we
// are using has optimized modes for arrays of references. At least one
// of the asserts below will fail if this is not the case.
assert(bs->has_write_ref_array_opt(), "Barrier set must have ref array opt");
assert(bs->has_write_ref_array_pre_opt(), "For pre-barrier as well.");
if (s == d) {
// since source and destination are equal we do not need conversion checks.
assert(length > 0, "sanity check");
bs->write_ref_array_pre(dst, length);
//复制的函数
Copy::conjoint_oops_atomic(src, dst, length);
} else {
// We have to make sure all elements conform to the destination array
Klass* bound = ObjArrayKlass::cast(d->klass())->element_klass();
Klass* stype = ObjArrayKlass::cast(s->klass())->element_klass();
if (stype == bound || stype->is_subtype_of(bound)) {
// elements are guaranteed to be subtypes, so no check necessary
//stype对象是bound,或者stype是bound的子类抑或stype实现bound接口
bs->write_ref_array_pre(dst, length);
Copy::conjoint_oops_atomic(src, dst, length);
} else {
// slow case: need individual subtype checks
// note: don't use obj_at_put below because it includes a redundant store check
T* from = src;
T* end = from + length;
for (T* p = dst; from < end; from++, p++) {
// XXX this is going to be slow.
T element = *from;
// even slower now
bool element_is_null = oopDesc::is_null(element);
oop new_val = element_is_null ? oop(NULL)
: oopDesc::decode_heap_oop_not_null(element);
if (element_is_null ||
(new_val->klass())->is_subtype_of(bound)) {
bs->write_ref_field_pre(p, new_val);
*p = element;
} else {
// We must do a barrier to cover the partial copy.
const size_t pd = pointer_delta(p, dst, (size_t)heapOopSize);
// pointer delta is scaled to number of elements (length field in
// objArrayOop) which we assume is 32 bit.
assert(pd == (size_t)(int)pd, "length field overflow");
bs->write_ref_array((HeapWord*)dst, pd);
THROW(vmSymbols::java_lang_ArrayStoreException());
return;
}
}
}
}
bs->write_ref_array((HeapWord*)dst, length);
}
3、在openjdk\hotspot\src\share\vm\utilities\copy.hpp文件中找到该conjoint_oops_atomic函数,还有针对narrowOop的重载函数,这里不写出
// oops, conjoint, atomic on each oop
static void conjoint_oops_atomic(oop* from, oop* to, size_t count) {
assert_params_ok(from, to, LogBytesPerHeapOop);
pd_conjoint_oops_atomic(from, to, count);
}
4、openjdk\hotspot\src\share\vm\oops\klass.hpp中的is_subtype_of函数
//检测是否是k的子类,或者是实现k接口
bool is_subtype_of(Klass* k) const {
juint off = k->super_check_offset();
Klass* sup = *(Klass**)( (address)this + off );
const juint secondary_offset = in_bytes(secondary_super_cache_offset());
if (sup == k) {
return true;
} else if (off != secondary_offset) {
return false;
} else {
return search_secondary_supers(k);
}
}
5、openjdk\hotspot\src\os_cpu\windows_x86\vm\copy_windows_x86.inline.hpp,最主要就是pd_conjoint_oops_atomic函数
static void pd_conjoint_oops_atomic(oop* from, oop* to, size_t count) {
// Do better than this: inline memmove body NEEDS CLEANUP
if (from > to) {
while (count-- > 0) {
// Copy forwards
*to++ = *from++;
}
} else {
from += count - 1;
to += count - 1;
while (count-- > 0) {
// Copy backwards
*to-- = *from--;
}
}
}
3.3 删除
ArrayList 删除元素有很多种方式,比如根据数组下标删除、根据值删除或批量删除等等,原理和思路都差不多,我们选取根据值下标方式来进行源码说明:
public E remove(int index) {
//判断下标是否合法
rangeCheck(index);
modCount++;
//获取旧值
E oldValue = elementData(index);
// numMoved 表示删除 index 位置的元素后,需要从 index 后移动多少个元素到前面去
// 减 1 的原因,是因为 size 从 1 开始算起,index 从 0 开始算起
int numMoved = size - index - 1;
//赋值
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
//赋值为nll,方便gc回收
elementData[--size] = null;
//返回旧值
return oldValue;
}
我们需要注意的是:某一个元素被删除后,为了维护数组结构,我们都会把数组后面的元素往前移动.
3.4 修改
通过调用 set(int index, E element) 方法在指定索引 index 处的元素替换为 element。并返回原数组的元素。
public E set(int index, E element) {
//判断索引合法性,是否索引越界
rangeCheck(index);
//获得原数组指定索引的元素
E oldValue = elementData(index);
//将指定所引处的元素替换为 element
elementData[index] = element;
//返回原数据
return oldValue;
}
3.5 迭代器
ArrayList实现了java.util.Iterator接口,主要包括是否有下一个元素hasNext,返回下一个元素next,删除remove,判断版本号checkForComodification方法。
3.5.1 是否有下一个元素hasNext
public boolean hasNext() {
//cursor 表示下一个元素的位置,size 表示实际大小,如果两者相等,
//说明已经没有元素可以迭代了,如果不等,说明还可以迭代
return cursor != size();
}
3.5.2 返回下一个元素next
从源码中可以看到,next 方法就干了两件事情,第一是检验能不能继续迭代,第二是找到迭代的值,并为下一次迭代做准备(cursor+1)。
public E next() {
//迭代过程中,判断版本号有无被修改,有被修改,抛 ConcurrentModificationException 异常
checkForComodification();
//本次迭代过程中,元素的索引位置
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
// 下一次迭代时,元素的位置,为下一次迭代做准备
cursor = i + 1;
// 返回元素值
return (E) elementData[lastRet = i];
}
3.5.3 删除remove
public void remove() {
// 如果上一次操作时,数组的位置已经小于 0 了,说明数组已经被删除完了
if (lastRet < 0)
throw new IllegalStateException();
//迭代过程中,判断版本号有无被修改,有被修改,抛 ConcurrentModificationException 异常
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
// -1 表示元素已经被删除,这里也防止重复删除
lastRet = -1;
// 删除元素时 modCount 的值已经发生变化,在此赋值给 expectedModCount
// 这样下次迭代时,两者的值是一致的了
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
3.5.4判断版本号checkForComodification
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
总结
本文从 ArrayList 整体架构出发,从初始化、新增、扩容、删除、迭代,修改等核心源码实现,我们发现 ArrayList 其实就是围绕底层数组结构进行封装的,如果jdk对底层代码进行修改,我们也不需要进行任何修改,做到对用户无感知。
