

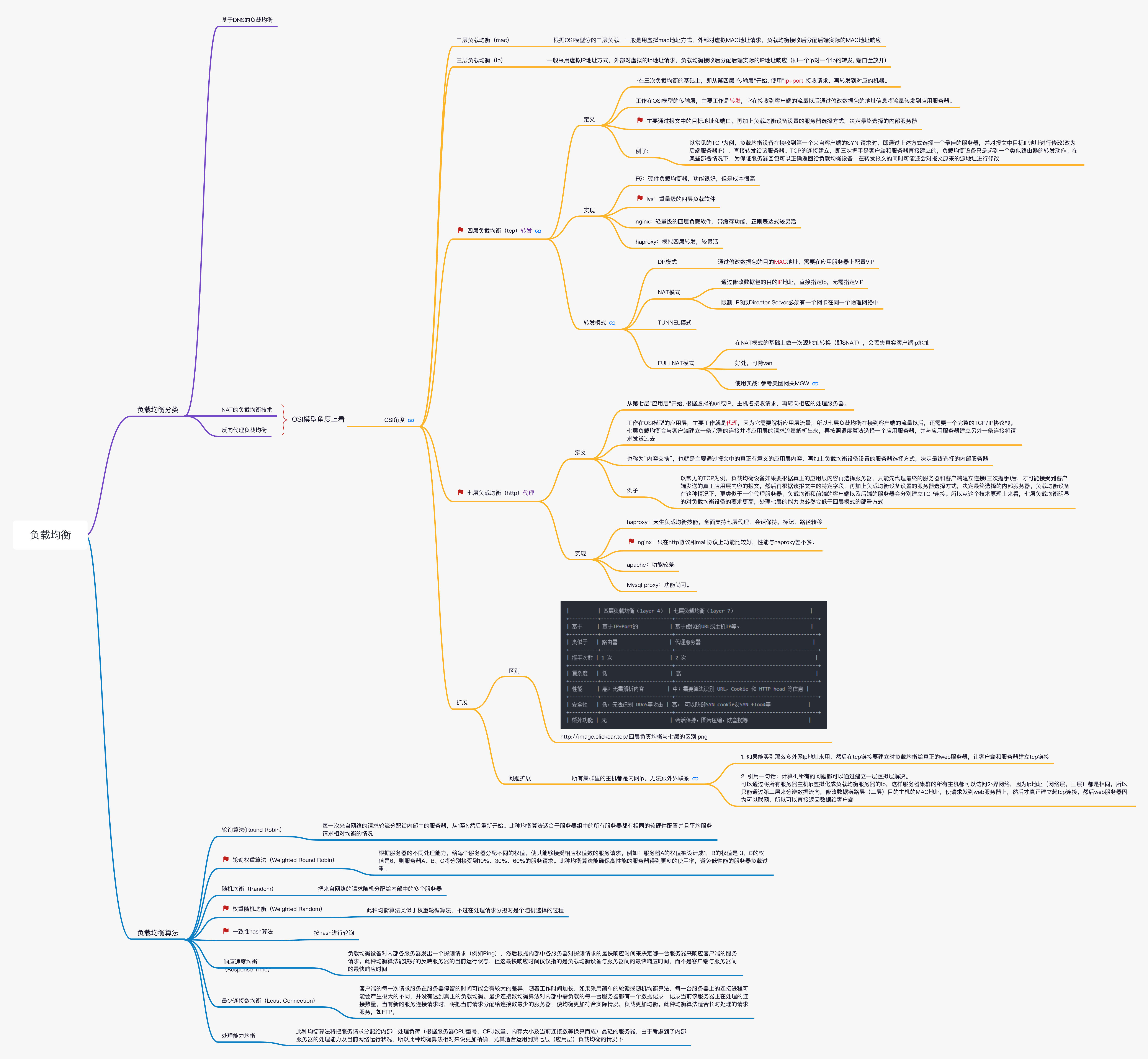
负载均衡,就是将负载(工作任务)进行平衡。简单理解,就是需要根据负载均衡算法,来选择服务器资源。比如,我们知道,单机已经满足现有的并发,经常会部署多台服务器,那么在处理链中,负载系统怎么发现这些服务器(如在nginx中配置服务器地址)?怎么确定一个客户端,访问的是哪台服务器呢(依据负载均衡算法)?
www.processon.com/mindmap/606…
负载均衡的维度(系统如何发现服务器地址)
首先,要理解负载均衡的维度,我们来看看,负载均衡系统的怎么发现或者是配置多台服务器地址的呢?
客户端如何访问服务器
经典面试题:
大致流程是:
- URL 解析
- DNS 查询
- TCP 连接
- 处理请求
- 接受响应
- 渲染页面
那毫无疑问,负载均衡其可以在2,3步骤进行负载。比如dns 映射到多个服务器的ip。
DNS查询步骤
从上可知,我们可以在 DNS查询、TCP连接这2个链路来进行负载均衡。
基于DNS的负载均衡(DNS步骤)
这个,其实比较简单,就是DNS服务器配置多个服务器地址,这样就可以获取到多个服务器地址了。
TCP连接步骤
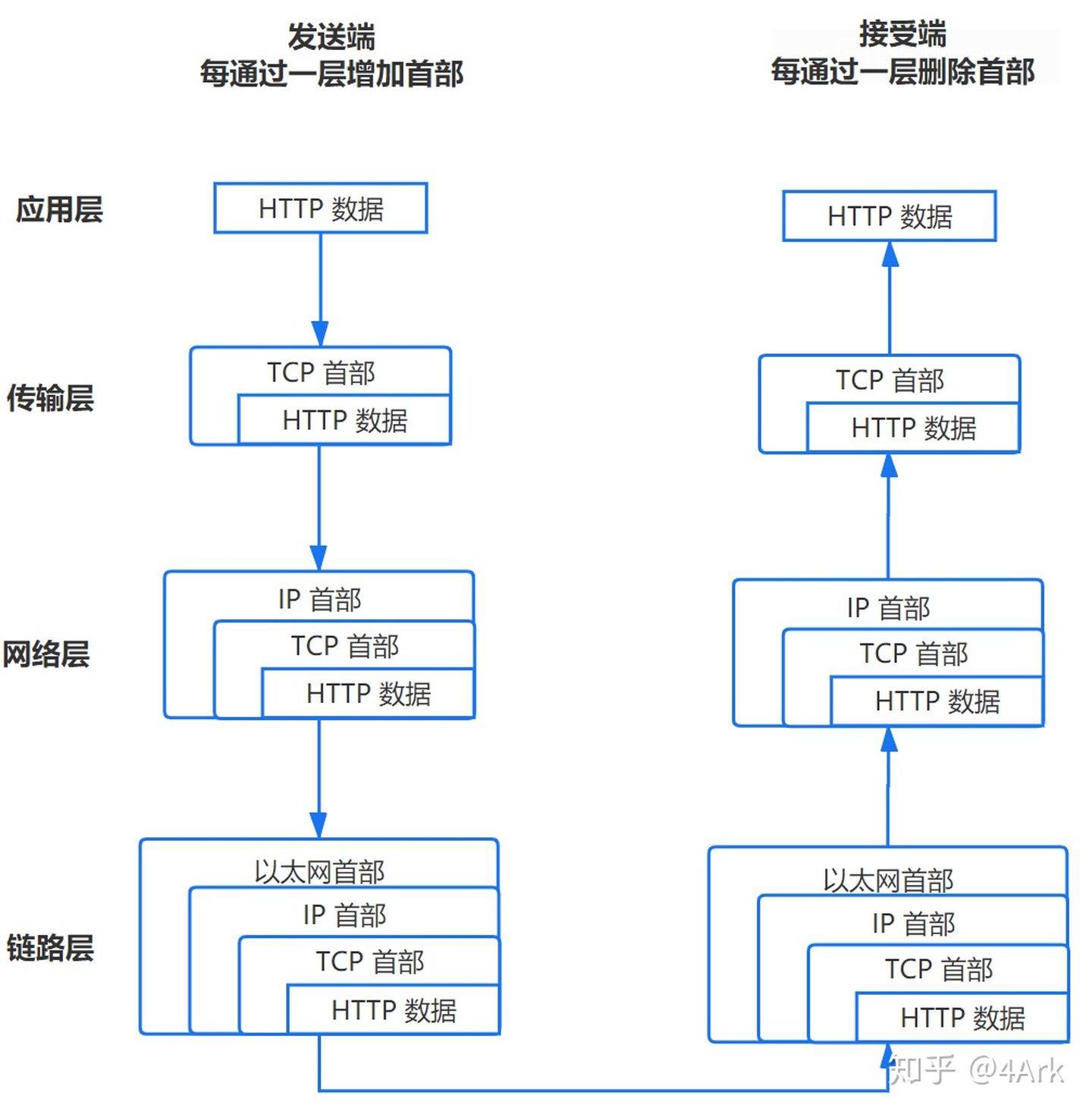
tcp/ip四层模型
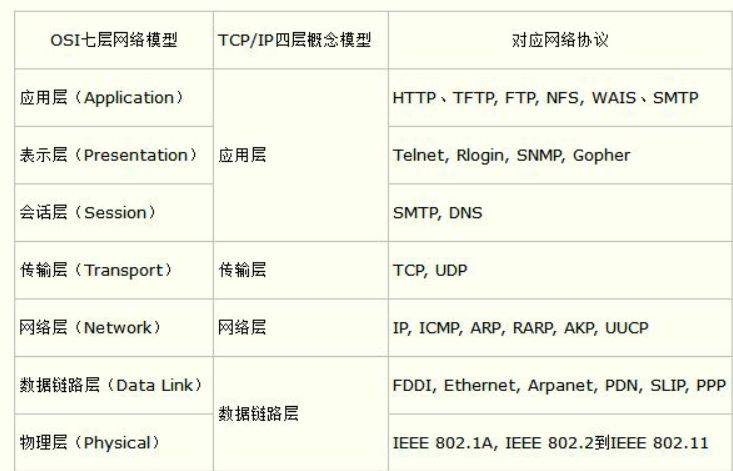
osi七层模型
我们知道,TCP/IP 分为四层(简化版),标准的是七层模型,在发送数据时,每层都要对数据进行封装。
基于NAT的负载均衡技术
1. 二层负载均衡(mac)
根据OSI模型分的二层负载,一般是用虚拟mac地址方式,外部对虚拟MAC地址请求,负载均衡接收后分配后端实际的MAC地址响应
2. 三层负载均衡(ip)
一般采用虚拟IP地址方式,外部对虚拟的ip地址请求,负载均衡接收后分配后端实际的IP地址响应. (即一个ip对一个ip的转发, 端口全放开)
🚩3. 四层负载均衡(tcp)转发
在三层负载均衡的基础上,即从第四层"传输层"开始, 使用"ip+port"接收请求,再转发到对应的机器。
工作在OSI模型的传输层,主要工作是转发,它在接收到客户端的流量以后通过修改数据包的地址信息将流量转发到应用服务器。
主要通过报文中的目标地址和端口,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器
🚩七层负载均衡(http)代理 又名 基于反向代理负载均衡
从第七层"应用层"开始, 根据虚拟的url或IP,主机名接收请求,再转向相应的处理服务器。
工作在OSI模型的应用层,主要工作就是代理,因为它需要解析应用层流量,所以七层负载均衡在接到客户端的流量以后,还需要一个完整的TCP/IP协议栈。七层负载均衡会与客户端建立一条完整的连接并将应用层的请求流量解析出来,再按照调度算法选择一个应用服务器,并与应用服务器建立另外一条连接将请求发送过去。
也称为“内容交换”,也就是主要通过报文中的真正有意义的应用层内容,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器
比如nginx:只在http协议和mail协议上功能比较好,性能与haproxy差不多;
四层负载均衡与七层负债均衡的区别

负载均衡算法,(如何选的问题)
轮循均衡(Round Robin)
每一次来自网络的请求轮流分配给内部中的服务器,从1至N然后重新开始。此种均衡算法适合于服务器组中的所有服务器都有相同的软硬件配置并且平均服务请求相对均衡的情
🚩权重轮循均衡(Weighted Round Robin)
根据服务器的不同处理能力,给每个服务器分配不同的权值,使其能够接受相应权值数的服务请求。例如:服务器A的权值被设计成1,B的权值是 3,C的权值是6,则服务器A、B、C将分别接受到10%、30%、60%的服务请求。此种均衡算法能确保高性能的服务器得到更多的使用率,避免低性能的服务器负载过重
原理:待分析
代码实现
package org.dromara.soul.plugin.divide.balance.spi;
import org.dromara.soul.common.dto.convert.DivideUpstream;
import org.dromara.soul.spi.Join;
import java.util.List;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.atomic.AtomicBoolean;
import java.util.concurrent.atomic.AtomicLong;
/**
* Round robin load balance impl.
*
* @author xiaoyu
*/
@Join
public class RoundRobinLoadBalance extends AbstractLoadBalance {
private final int recyclePeriod = 60000;
private final ConcurrentMap<String, ConcurrentMap<String, WeightedRoundRobin>> methodWeightMap = new ConcurrentHashMap<>(16);
private final AtomicBoolean updateLock = new AtomicBoolean();
@Override
public DivideUpstream doSelect(final List<DivideUpstream> upstreamList, final String ip) {
String key = upstreamList.get(0).getUpstreamUrl();
ConcurrentMap<String, WeightedRoundRobin> map = methodWeightMap.get(key);
if (map == null) {
methodWeightMap.putIfAbsent(key, new ConcurrentHashMap<>(16));
map = methodWeightMap.get(key);
}
int totalWeight = 0;
long maxCurrent = Long.MIN_VALUE;
long now = System.currentTimeMillis();
DivideUpstream selectedInvoker = null;
WeightedRoundRobin selectedWRR = null;
for (DivideUpstream upstream : upstreamList) {
String rKey = upstream.getUpstreamUrl();
WeightedRoundRobin weightedRoundRobin = map.get(rKey);
int weight = getWeight(upstream);
if (weightedRoundRobin == null) {
weightedRoundRobin = new WeightedRoundRobin();
weightedRoundRobin.setWeight(weight);
map.putIfAbsent(rKey, weightedRoundRobin);
}
if (weight != weightedRoundRobin.getWeight()) {
//weight changed
weightedRoundRobin.setWeight(weight);
}
long cur = weightedRoundRobin.increaseCurrent();
weightedRoundRobin.setLastUpdate(now);
if (cur > maxCurrent) {
maxCurrent = cur;
selectedInvoker = upstream;
selectedWRR = weightedRoundRobin;
}
totalWeight += weight;
}
if (!updateLock.get() && upstreamList.size() != map.size() && updateLock.compareAndSet(false, true)) {
try {
// copy -> modify -> update reference
ConcurrentMap<String, WeightedRoundRobin> newMap = new ConcurrentHashMap<>(map);
newMap.entrySet().removeIf(item -> now - item.getValue().getLastUpdate() > recyclePeriod);
methodWeightMap.put(key, newMap);
} finally {
updateLock.set(false);
}
}
if (selectedInvoker != null) {
selectedWRR.sel(totalWeight);
return selectedInvoker;
}
// should not happen here
return upstreamList.get(0);
}
/**
* The type Weighted round robin.
*/
protected static class WeightedRoundRobin {
private int weight;
private final AtomicLong current = new AtomicLong(0);
private long lastUpdate;
/**
* Gets weight.
*
* @return the weight
*/
int getWeight() {
return weight;
}
/**
* Sets weight.
*
* @param weight the weight
*/
void setWeight(final int weight) {
this.weight = weight;
current.set(0);
}
/**
* Increase current long.
*
* @return the long
*/
long increaseCurrent() {
return current.addAndGet(weight);
}
/**
* Sel.
*
* @param total the total
*/
void sel(final int total) {
current.addAndGet(-1 * total);
}
/**
* Gets last update.
*
* @return the last update
*/
long getLastUpdate() {
return lastUpdate;
}
/**
* Sets last update.
*
* @param lastUpdate the last update
*/
void setLastUpdate(final long lastUpdate) {
this.lastUpdate = lastUpdate;
}
}
}
🚩一致性hash算法
算法实现原理:
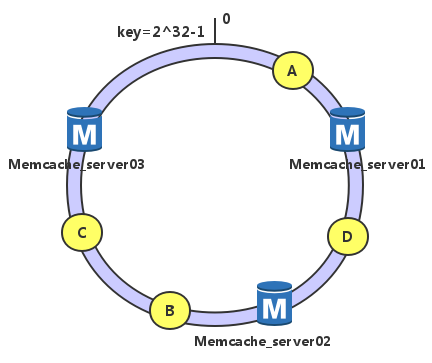
hash一致性算法原理,按顺时针取服务器
简单理解: 服务器 01,02,03取hash后按图中位置所示 。当客户端ABCD、按hash获取到的值如图。 这样时候为A,则返回的服务器为01。如为D 则返回的是服务器02。按顺时针取最近的服务器
为了取数尽量均衡,引入虚拟节点,相当于是虚拟节点A1,A2,A3 其实都是指向服务器A.
代码实现
package org.dromara.soul.plugin.divide.balance.spi;
import org.dromara.soul.common.dto.convert.DivideUpstream;
import org.dromara.soul.common.exception.SoulException;
import org.dromara.soul.spi.Join;
import java.nio.charset.StandardCharsets;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.List;
import java.util.SortedMap;
import java.util.concurrent.ConcurrentSkipListMap;
/**
* hash algorithm impl.
*
* @author xiaoyu(Myth)
*/
@Join
public class HashLoadBalance extends AbstractLoadBalance {
private static final int VIRTUAL_NODE_NUM = 5;
@Override
public DivideUpstream doSelect(final List<DivideUpstream> upstreamList, final String ip) {
// 使用跳跃表
final ConcurrentSkipListMap<Long, DivideUpstream> treeMap = new ConcurrentSkipListMap<>();
for (DivideUpstream address : upstreamList) {
// 虚拟节点,使得分布尽量均匀
for (int i = 0; i < VIRTUAL_NODE_NUM; i++) {
long addressHash = hash("SOUL-" + address.getUpstreamUrl() + "-HASH-" + i);
treeMap.put(addressHash, address);
}
}
long hash = hash(String.valueOf(ip));
// 大于某个值,才会返回
SortedMap<Long, DivideUpstream> lastRing = treeMap.tailMap(hash);
if (!lastRing.isEmpty()) {
// 取剩余环中的最大值
return lastRing.get(lastRing.firstKey());
}
return treeMap.firstEntry().getValue();
}
private static long hash(final String key) {
// md5 byte
MessageDigest md5;
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new SoulException("MD5 not supported", e);
}
md5.reset();
byte[] keyBytes;
keyBytes = key.getBytes(StandardCharsets.UTF_8);
md5.update(keyBytes);
byte[] digest = md5.digest();
// hash code, Truncate to 32-bits
long hashCode = (long) (digest[3] & 0xFF) << 24
| ((long) (digest[2] & 0xFF) << 16)
| ((long) (digest[1] & 0xFF) << 8)
| (digest[0] & 0xFF);
return hashCode & 0xffffffffL;
}
}
随机均衡(Random)
把来自网络的请求随机分配给内部中的多个服务器
🚩权重随机均衡(Weighted Random)
此种均衡算法类似于权重轮循算法,不过在处理请求分担时是个随机选择的过程。
算法原理
较为简单,其实就是 服务器A(20 权重) B(权重40) C 权重(30)
- 计算中的总权重值 70
- 生成随机总权重值内的一个随机数。比如25
- 按照顺序,去扣减权重。比如25在服务器B时,扣减为0,说明位于服务器B处。
代码实现
package org.dromara.soul.plugin.divide.balance.spi;
import org.dromara.soul.common.dto.convert.DivideUpstream;
import org.dromara.soul.spi.Join;
import java.util.List;
import java.util.Random;
/**
* random algorithm impl.
*
* @author xiaoyu(Myth)
*/
@Join
public class RandomLoadBalance extends AbstractLoadBalance {
private static final Random RANDOM = new Random();
@Override
public DivideUpstream doSelect(final List<DivideUpstream> upstreamList, final String ip) {
int totalWeight = calculateTotalWeight(upstreamList);
boolean sameWeight = isAllUpStreamSameWeight(upstreamList);
if (totalWeight > 0 && !sameWeight) {
return random(totalWeight, upstreamList);
}
// If the weights are the same or the weights are 0 then random
return random(upstreamList);
}
private boolean isAllUpStreamSameWeight(final List<DivideUpstream> upstreamList) {
boolean sameWeight = true;
int length = upstreamList.size();
for (int i = 0; i < length; i++) {
int weight = getWeight(upstreamList.get(i));
if (i > 0 && weight != getWeight(upstreamList.get(i - 1))) {
// Calculate whether the weight of ownership is the same
sameWeight = false;
break;
}
}
return sameWeight;
}
private int calculateTotalWeight(final List<DivideUpstream> upstreamList) {
// total weight
int totalWeight = 0;
for (DivideUpstream divideUpstream : upstreamList) {
int weight = getWeight(divideUpstream);
// Cumulative total weight
totalWeight += weight;
}
return totalWeight;
}
private DivideUpstream random(final int totalWeight, final List<DivideUpstream> upstreamList) {
// If the weights are not the same and the weights are greater than 0, then random by the total number of weights
int offset = RANDOM.nextInt(totalWeight);
// Determine which segment the random value falls on
for (DivideUpstream divideUpstream : upstreamList) {
offset -= getWeight(divideUpstream);
if (offset < 0) {
return divideUpstream;
}
}
return upstreamList.get(0);
}
private DivideUpstream random(final List<DivideUpstream> upstreamList) {
return upstreamList.get(RANDOM.nextInt(upstreamList.size()));
}
}
响应速度均衡(Response Time)
负载均衡设备对内部各服务器发出一个探测请求(例如Ping),然后根据内部中各服务器对探测请求的最快响应时间来决定哪一台服务器来响应客户端的服务请求。此种均衡算法能较好的反映服务器的当前运行状态,但这最快响应时间仅仅指的是负载均衡设备与服务器间的最快响应时间,而不是客户端与服务器间的最快响应时间。
最少连接数均衡(Least Connection)
客户端的每一次请求服务在服务器停留的时间可能会有较大的差异,随着工作时间加长,如果采用简单的轮循或随机均衡算法,每一台服务器上的连接进程可能会产生极大的不同,并没有达到真正的负载均衡。最少连接数均衡算法对内部中需负载的每一台服务器都有一个数据记录,记录当前该服务器正在处理的连接数量,当有新的服务连接请求时,将把当前请求分配给连接数最少的服务器,使均衡更加符合实际情况,负载更加均衡。此种均衡算法适合长时处理的请求服务,如FTP
处理能力均衡
此种均衡算法将把服务请求分配给内部中处理负荷(根据服务器CPU型号、CPU数量、内存大小及当前连接数等换算而成)最轻的服务器,由于考虑到了内部服务器的处理能力及当前网络运行状况,所以此种均衡算法相对来说更加精确,尤其适合运用到第七层(应用层)负载均衡的情况下
引用
tech.meituan.com/2017/01/05/… 美团网关实战 【重点推荐】
www.cnblogs.com/kevingrace/… linux负载均衡总结性说明(四层负载/七层负载) 【重点推荐】
programtip.com/zh/art-1247… 四层负载均衡转发模式
soul源码,负载均衡具体实现
