

第5部分- Linux ARM汇编 ARM 架构细节
ARM处理器有37个寄存器,包括31个通用寄存器,和6个状态寄存器。
通用寄存器是31个从x0-x30,31个数量是比较奇怪的,其实还有一个是Zero Register是wzr。如果是使用寄存器中的32位,就是w0-w30了。类型X86中的rax和eax寄存器,一个64位一个32位。
ARM处理器共有7种不同的处理器模式,在每一种处理器模式中有一组响应的寄存器组。
在AArch64时使用X30作为子函数调用时使用的link register
在AArch32时始终使用LR作为link register。
ARM64通用寄存器
后续主要都是ARM64架构了,所以这里以arm64例。
| Register | Volatile? | Role |
|---|---|---|
| x0 | Volatile | Parameter/scratch register 1, result register |
| x1-x7 | Volatile | Parameter/scratch register 2-8 |
| x8-x15 | Volatile | Scratch registers |
| x16-x17 | Volatile | Intra-procedure-call scratch registers |
| x18 | Non-volatile | Platform register: in kernel mode, points to KPCR for the current processor; in user mode, points to TEB |
| x19-x28 | Non-volatile | Scratch registers |
| x29/fp | Non-volatile | Frame pointer |
| x30/lr | Non-volatile | Link registers |
可以通过w0 ~ w30来访问这31个64位寄存器的低32位,写入时会将高32位清零。
ARM64浮点寄存器
也是有32个浮点寄存器。
每个寄存器都可以作为完整的128位值(通过v0-v31或q0-q31)进行访问。 可以以64位值(通过d0-d31),32位值(通过s0-s31),16位值(通过h0-h31)或8位值进行访问 (通过b0-b31)。 小于128位的访问仅访问整个128位寄存器的低位。 除非另有说明,否则它们保持其余位不变。 (AArch64与AArch32不同,在AArch32中,较小的寄存器封装在较大的寄存器的顶部。)
- 32个B寄存器(B0~B31),8bit
- 32个H寄存器(H0~H31),半字 16bit
- 32个S寄存器(S0~S31),单子 32bit
- 32个D寄存器(D0~D31),双字 64bit
- 32个Q寄存器(V0~V31),四字 128bit
| Register | Volatile? | Role |
|---|---|---|
| v0 | Volatile | Parameter/scratch register 1, result register |
| v1-v7 | Volatile | Parameter/scratch registers 2-8 |
| v8-v15 | Non-volatile | Scratch registers (only the low 64 bits are non-volatile) |
| v16-v31 | Volatile | Scratch registers |
浮点控制寄存器
浮点控制寄存器(FPCR)对其中的各个位字段有某些要求:
| Bits | Meaning | Volatile? | Role |
|---|---|---|---|
| 26 | AHP | Non-Volatile | Alternative half-precision control. |
| 25 | DN | Non-Volatile | Default NaN mode control. |
| 24 | FZ | Non-volatile | Flush-to-zero mode control. |
| 23-22 | RMode | Non-volatile | Rounding mode control. |
| 15,12-8 | IDE/IXE/etc | Non-Volatile | Exception trap enable bits, must always be 0. |
32位浮点寄存器
浮点寄存器的单精度命名为s0至s31,双精度命名为d0至d15。
这些寄存器分为4个存储区:s0–s7(d0–d3),s8–s15(d4–d7),s16–s23(d8–d11)和s24–s31(d12–d15)。
(存储体0,s0–s7,d0–d3)称为标量存储体,而其余三个是矢量存储体
VFPv2指令集
Vector Floating-point v2
可以通过软件来实现VFPv2当然相比硬件,其性能会更差。
VFPv2提供了三个控制寄存器,其中一个称为fpscr, 该寄存器与cpsr相似,保留了通常的比较标志N,Z,C和V。它还存储了两个非常有用的字段len和stride。 这两个字段控制浮点指令的行为。
大多数VFPv2指令的格式为vname Rdest,Rsource1,Rsource2或fname Rdest,Rsource1。 它们具有三种操作模式。
- 标量。当目标寄存器位于存储区0(s0–s7或d0–d3)中时,使用此模式。在这种情况下,该指令仅对Rsource1和Rsource2起作用。不涉及其他寄存器。
- 矢量。当目标寄存器和Rsource2(或对于只有一个源寄存器的指令为Rsource1)不在存储区0中时,使用此模式。在这种情况下,指令将操作尽可能多的寄存器(从指令中的给定寄存器开始并环绕fpscr字段len中定义的寄存器组(至少1)。下一个操作的寄存器由fpscr的跨度字段定义(至少1)。如果发生折回,则任何寄存器都不能操作两次。
- 标量扩展(也称为混合矢量/标量)。如果Rsource2(如果指令只有一个源寄存器,则为Rsource1)位于bank0中,而目的地则不是,则使用此模式。在这种情况下,Rsource2(或对于只有一个源的指令为Rsource1)被固定为源。其余寄存器的操作与矢量情况一样(即使用fpscr的len和stride)。
示例
| ```html // 假设len = 4, stride = 2
vadd.f32 s1, s2, s3 /* s1 ← s2 + s3. 标量操作,因为s1在bank 0 */
``````html
vadd.f32 s1, s8, s15 /* s1 ← s8 + s15. 同上 */
``````html
vadd.f32 s8, s16, s24 /* s8 ← s16 + s24
``````html
s10 ← s18 + s26
``````html
s12 ← s20 + s28
``````html
s14 ← s22 + s30
``````html
矢量操作{s8,s10,s12,s14} ← {s16,s18,s20,s22} + {s24,s26,s28,s30}因为Rdest and Rsource2 没有在 bank 0
``````html
*/
``````html
vadd.f32 s10, s16, s24 /* {s10,s12,s14,s8} ← {s16,s18,s20,s22} + {s24,s26,s28,s30}.*/
``````html
vadd.f32 s8, s16, s3 /* {s8,s10,s12,s14} ← {s16,s18,s20,s22} + {s3,s3,s3,s3}标量扩展,因为Rsource2 在bank 0*/
``` |
| -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
### Load和store
单精度是:`vldr`/`vstr`
加载/存储的地址必须已经在通用寄存器中
| ```html
vldr s1, [r3] /* s1 ← *r3 */
``````html
vldr s2, [r3, #4] /* s2 ← *(r3 + 4) */
``````html
vldr s3, [r3, #8] /* s3 ← *(r3 + 8) */
``````html
vldr s4, [r3, #12] /* s4 ← *(r3 + 12) */
``````html
``````html
vstr s10, [r4] /* *r4 ← s10 */
``````html
vstr s11, [r4, #4] /* *(r4 + 4) ← s11 */
``````html
vstr s12, [r4, #8] /* *(r4 + 8) ← s12 */
``````html
vstr s13, [r4, #12] /* *(r4 + 12) ← s13 */
``` |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
可以Load/store多个寄存器:
vldm indexing-mode precision Rbase{!}, floating-point-register-set
vstm indexing-mode precision Rbase{!}, floating-point-register-set
| ```html
vldmias r4, {s3-s8} /* s3 ← *r4
``````html
s4 ← *(r4 + 4)
``````html
s5 ← *(r4 + 8)
``````html
s6 ← *(r4 + 12)
``````html
s7 ← *(r4 + 16)
``````html
s8 ← *(r4 + 20)
``````html
其中i表示increase,a表示after,s表示单精度*/
``````html
vldmias r4!, {s3-s8} /* Like the previous instruction
``````html
最后r4 ← r4 + 24 ,r4会指向最后一个值。
``````html
*/
``````html
vstmdbs r5!, {s12-s13} /* *(r5 - 4 * 1) ← s12
``````html
*(r5 - 4 * 2) ← s13
``````html
r5 ← r5 - 4*2
``````html
*/
``` |
| ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
32位中还有vpush
| ```html
vpush {s0-s5} /* Equivalent to vstmdb sp!, {s0-s5} */
``````html
vpop {s0-s5} /* Equivalent to vldmia sp!, {s0-s5} */
``` |
| ---------------------------------------------------------------------------------------------------------------------------------- |
### 寄存器间移动
指令是vmov.
在一个通用寄存器和一个单精度寄存器之间vmov,数据不会转换。 只有位会被复制,因此不要将浮点值与整数指令混合使用,反之亦然。
| ```html
vmov d3, r4, r6 /* Lower32BitsOf(d3) ← r4
``````html
Higher32BitsOf(d3) ← r6
``````html
*/
``````html
vmov r5, r7, d4 /* r5 ← Lower32BitsOf(d4)
``````html
r7 ← Higher32BitsOf(d4)
``````html
*/
``` |
| -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
### 转化
单精度转换为整型的时候丢失精度是必然的的,是多少问题。
指令:
vcvt
两个寄存器都必须是浮点寄存器。浮点寄存器将包含一个不是IEEE 754值的值。
| ```html
vcvt.f64.f32 d0, s0 /* 单精度s0 为双精度,并保存到d0 */
``````html
vcvt.f32.f64 s0, d0 /*双精度d0 为单精度s0,并保存到s0*/
``````html
``````html
vmov s0, r0 /* 从通用寄存器 r0 到浮点寄存器s0 */
``````html
vcvt.f32.s32 s0, s0 /* 将符号整型s0 为单精度并保存到s0 */
``````html
vmov s0, r0 /*从通用寄存器 r0 到浮点寄存器s0 */
``````html
vcvt.f32.u32 s0, s0 /*将无符号整型s0 为单精度并保存到s0 */
``````html
``````html
vmov s0, r0 /*从通用寄存器 r0 到浮点寄存器s0 */
``````html
vcvt.f64.s32 d0, s0 /*将符号整型s0 为双精度并保存到d0 */
``````html
vmov s0, r0 /*从通用寄存器 r0 到浮点寄存器s0 */
``````html
vcvt.f64.u32 d0, s0 /*将无符号整型s0 为双精度并保存到d0 */
``` |
| -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
### 修改fpscr
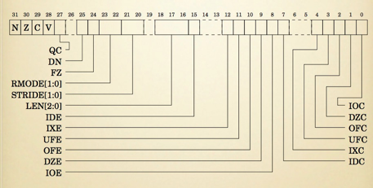
设置了len和stride的特殊寄存器fpscr无法直接修改。
必须使用vmrs指令将fpscr加载到通用寄存器中。 然后使用vmsr指令对寄存器进行操作,并将其移回fpscr。
len的值存储在fpscr的第16至18位中。 len的值不直接存储在这些位中。这是因为len不能为0(操作0个浮点数没有意义)。 这样,这些位中的值000表示len = 1,001表示len = 2,…,111表示len =8。以下是将len设置为8的代码。
| ```html
/* Set the len field of fpscr to be 8 (bits: 111) */
``````html
mov r5, #7 /* r5 ← 7. 7 is 111 in binary */
``````html
mov r5, r5, LSL #16 /* r5 ← r5 << 16 */
``````html
vmrs r4, fpscr /* r4 ← fpscr */
``````html
orr r4, r4, r5 /* r4 ← r4 | r5. Bitwise OR */
``````html
vmsr fpscr, r4 /* fpscr ← r4 */
``` |
| -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
stride存储在fpscr的20至21位中。 与len相似,这些位中的值00表示1,01表示 2,10表示 3,11表示 4。
*<https://developer.arm.com/docs/ddi0595/d/aarch32-system-registers/fpscr>*
该寄存器中的命名字段映射到AArch64 FPCR和FPSR中的等效字段。
寄存器FPEXC中,EN表示NEON和VFP是否使能。清零是关闭

要使能,将EN置1。
### 函数调用约定和浮点寄存器
* fpscr的len和stride字段的所有位在函数输入时均为零,离开时这些位必须为零。
* 可以使用寄存器s0–s15和d0–d7传递浮点参数。 请注意,在单精度之后传递双精度可能涉及丢弃奇数单精度寄存器(例如,可以使用s0和d1,但请注意,s1将不被使用)。
* 所有其他浮点寄存器(s16-s31和d8-d15)在退出功能时必须保留其值。 可以使用vpush和vpop指令。
* 如果函数返回浮点值,则返回寄存器将为s0或d0。
注意有关可变参数函数(例如printf):不能将单精度浮点传递给此类函数之一。 只能通过双精度。 需要将单精度值转换为双精度值。 还要注意,通常使用整数寄存器(r0–r3),因此您最多只能传递2个双精度值,其余的必须在堆栈上传递。 特别是对于printf,因为r0包含字符串格式的地址,所以您只能在{r2,r3}中传递双精度。
### 编译
要将标志-mfpu = vfpv2传递给as,否则将无法识别VFPv2指令。
## 浮点和整数传输
VMRS/VMSR在ARM寄存器与NEON和VFP系统寄存器之间传输内容。
fmrx/fmxr在ARM寄存器和VFP系统寄存器之间传输内容。
Fmrs/fmsr 在ARM寄存器和浮点寄存器之间传输内容。
## ARM64系统寄存器
与AArch32一样,AArch64规范提供了三个系统控制的“线程ID”寄存器:
| Register | Role |
| ----------- | ----------------------------------------------- |
| TPIDR_EL0 | Reserved. |
| TPIDRRO_EL0 | Contains CPU number for current processor. |
| TPIDR_EL1 | Points to KPCR structure for current processor. |
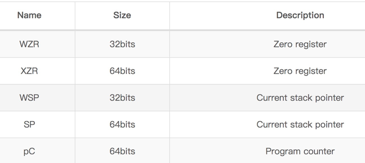
**程序计数器**
pc,保存着当前CPU执行指令的地址。不能用作算数指令的源或目的地以及用作加载或存储指令。
**堆栈指针**
sp,即x31,指向堆栈的顶部。sp不能被大多数指令引用, 但一些算术指令,例如ADD指令,可以读写当前的堆栈指针来调整函数中的堆栈指针。每个异常级别都有一个专用的SP寄存器。
fp,即**x29**,帧指针,指向当前frame的栈底,也就是高地址。
**链接寄存器**
lr,即x30,存储着函数的返回地址。
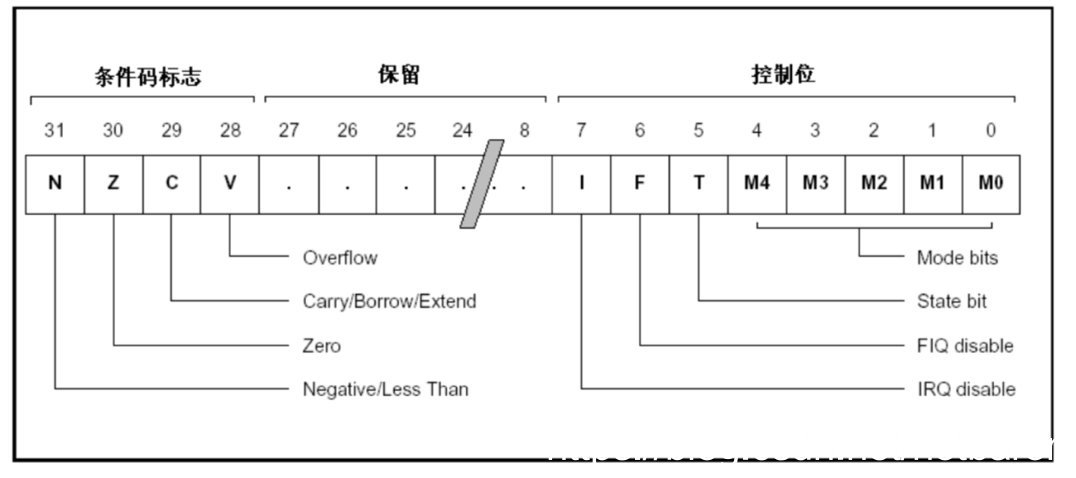
**程序状态寄存器**
在汇编中通过状态寄存器来控制分支的执行。
cpsr:与其他寄存器不太一样,其他寄存器用来存储数据的,但是这个寄存器是,按位起作用的,每一位都有专门的含义。
spsr:当发生异常时,cpsr会存入spsr直到异常恢复再复制回cpsr。
## 特殊寄存器

## 运行模式
ARM处理器支持7种运行模式,分别是:
* 用户模式(usr):ARM处理器正常的程序运行状态。
* 快速中断模式(flq):用于高速数据传输或通道处理。
* 外部中断模式(irq):用于通用的中断处理。
* 管理模式(svc):操作系统使用的保护模式。
* 数据访问终止模式(abt):当数据或指令预取终止时进入该模式,可用于虚拟存储以及存储保护。
* 系统模式(sys):运行具有特短的操作系统任务。
* 未定义指令终止模式(und):当未定义的指令执行时进入该模式。
各种处理器模式下的,通用寄存器
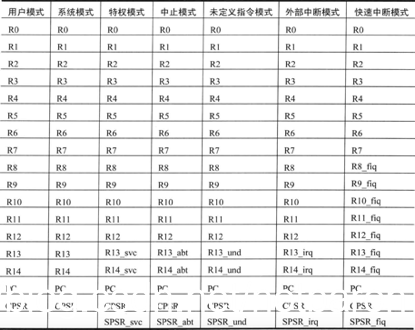
还有两个工作模式:
hyp:用于虚拟化扩展。
monitor:用于Security扩展。
## 工作状态
ARM状态:执行32位字对齐的ARM指令。
Thumb状态:执行16位字对齐的ARM指令。
Thumb状态下的寄存器的命名与ARM有部分差异,它们的对应关系如下所示:
Thumb状态下的R0\~R7与ARM状态下的R0\~R7相同。
Thumb状态下的CPSR与ARM状态下的CPSR相同。
Thumb状态下的FP与ARM状态下的R11相同。
Thumb状态下的IP与ARM状态下的R12相同。
Thumb状态下的SP与ARM状态下的R13相同。
Thumb状态下的LR与ARM状态下的R14相同。
Thumb状态下的PC与ARM状态下的R15相同。
## 程序状态寄存器
CPSR(当前程序状态寄存器)可以在任何处理器模式下被访问。
## 非对齐的存储访问操作
如果写入到寄存器PC中的值是非字对齐的,要么指令执行的结果不可预知,要么地址值中最低两位被忽略。
