

Jsoup爬虫
数据源、爬数据、flume收集、大数据分析、sqoop迁移到mysql
1.数据采集功能介绍
发送请求地址:https://movie.douban.com/subject/1292052/reviews?start=0
任务:
爬取:肖申克的救赎的影评
爬取字段:影评标题、发影评人、评分、影评时间、useCount、notUseCount、replyCount
爬取内容存储:采用logback(实现日志存储)
浏览器:谷歌(F12进入开发者工具)
实现数据爬取:jsoup 开发指南(https://jsoup.org/)
-模仿多个客户端(设置请求头部信息,模仿不同的客户端发请求)
-长任务(可以一直执行),间断爬取数据(sleep)(一直执行会占用人家网站的并发数量,人家发现就会把你的IP地址禁掉,但是有线无线IP地址不一样)
2基于爬虫实现数据采集
2.1网络访问工具
浏览器
-Postman
-抓包工具:Fiddler
-编程实现:Apache HttpClient(模拟浏览器发送请求,获取响应数据),要设请求头,要让豆瓣认为我们写的这个程序是浏览器的正常访问。
2.2实现网络资源的访问
- HttpClient
2.3 解析网络资源数据
- JSoup
jsoup解析页面数据
document/selector/reg
2.4抽取数据的存储
- logback
2.5编程实现
-
创建maven项目
-
pom.xml添加依赖
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.com.chinahitech.spider</groupId> <artifactId>film_spider</artifactId> <version>1.0-SNAPSHOT</version> <name>film_spider</name> <!-- FIXME change it to the project's website --> <url>http://www.example.com</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.7</maven.compiler.source> <maven.compiler.target>1.7</maven.compiler.target> </properties> <!-- 配置国内maven仓库源 --> <repositories> <repository> <id>ali-maven</id> <url>http://maven.aliyun.com/nexus/content/groups/public</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>true</enabled> <updatePolicy>always</updatePolicy> <checksumPolicy>fail</checksumPolicy> </snapshots> </repository> <repository> <id>central</id> <name>Maven Repository Switchboard</name> <layout>default</layout> <url>http://repo1.maven.org/maven2</url> <snapshots> <enabled>false</enabled> </snapshots> </repository> </repositories> <!-- 添加依赖 http-client、jsoup、logback--> <dependencies> <!--基于httpclient模拟浏览器进行网络请求 --> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpcore</artifactId> <version>4.4.10</version> </dependency> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.6</version> </dependency> <!-- 进行html解析的jsoup--> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.12.1</version> </dependency> <!--logback 日志进行存储--> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>1.2.3</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.13</version> </dependency> </dependencies> </project> -
pom.xml添加打包插件
<!--打包的插件--> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.2.0</version> <configuration> <archive> <manifest><!--配置应用程序的主类--> <mainClass>cn.com.chinahitech.spider.FilmSpider</mainClass> </manifest> </archive> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <encoding>utf-8</encoding> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> -
在resources下引入logback.xml文件
<?xml version="1.0" encoding="utf-8" ?> <configuration> <property name="LOG_PATTERN" value="%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} -%msg%n" /> <!-- 核心爬取数据的格式 年月日 时分秒,分隔符是逗号 文本数据转换为数仓的时候,分隔符也是逗号 --> <property name="DATA_PATTERN" value="%d{yyyy-MM-dd HH:mm:ss},%msg%n" /> <property name="LOG_LEVEL" value="INFO"/> <!-- 标准输出日志(控制台输出) --> <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> <encoder> <pattern>${LOG_PATTERN}</pattern> </encoder> <filter class="ch.qos.logback.classic.filter.ThresholdFilter"> <level>${LOG_LEVEL}</level> </filter> </appender> <!-- 数据采集日志记录, 保存到文件!!!这个很重要 --> <appender name="COLLECT_ROLLING" class="ch.qos.logback.core.rolling.RollingFileAppender"> <rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"> <!--写明生成的日志文件的存放位置和文件名--> <fileNamePattern>data/collect/data_file.%d{yyyy-MM-dd}_%i.log</fileNamePattern> <maxFileSize>10MB</maxFileSize> <maxHistory>10</maxHistory> <!--要求每天总的日志的写入量是10G--> <!--每个文件的最大量是10M(上面哪个maxFileSize)--> <totalSizeCap>10GB</totalSizeCap> <cleanHistoryOnStart>true</cleanHistoryOnStart> </rollingPolicy> <encoder> <pattern>${DATA_PATTERN}</pattern> </encoder> </appender> <!-- 指定日志输出级别 --> <!--与项目的根路径一致--> <logger name="cn.com.chinahitech.spider" level="${LOG_LEVEL}" addtivity="false"> <appender-ref ref="COLLECT_ROLLING" /> </logger> <root level="${LOG_LEVEL}"> <appender-ref ref="STDOUT" /> </root> </configuration> -
编码实现爬取第一页
https://movie.douban.com/subject/1292052/reviews?start=0 start=0代表第一页 start=20代表第二页 每页20条数据 start=20代表第二页的第一条数据 start=40代表第三页/** * 根据指定网址, 爬取页面内容 * @param requestUrl 请求网址 */ public void requestByUrl(String requestUrl) { System.out.println(requestUrl); // 1. 创建客户端对象。用HttpClientBuilder创建了一个假的客户端 CloseableHttpClient httpClient = HttpClientBuilder.create().build(); // 2. 创建Http请求对象, HttpGet对象,给客户端一个地址 HttpGet httpGet = new HttpGet(requestUrl); // 设置httpGet header 设置请求头搞得像真得客户端请求 //改成自己浏览器的User-agent httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"); // 3. 执行请求, 获取响应 try { CloseableHttpResponse response = httpClient.execute(httpGet); // 4. 获取响应状态的状态行信息 StatusLine statusLine = response.getStatusLine(); if(statusLine.getStatusCode() != 200) { System.out.println("请求失败"); return; } // 5. 获取请求中的数据 HttpEntity httpEntity = response.getEntity(); // 6. 讲httpEntity转为String String content = EntityUtils.toString(httpEntity); // System.out.println(content); // 7. 解析当前页数据 parseHtml(content); } catch (ClientProtocolException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }自己浏览器得user-agent:
-
解析当前页数据
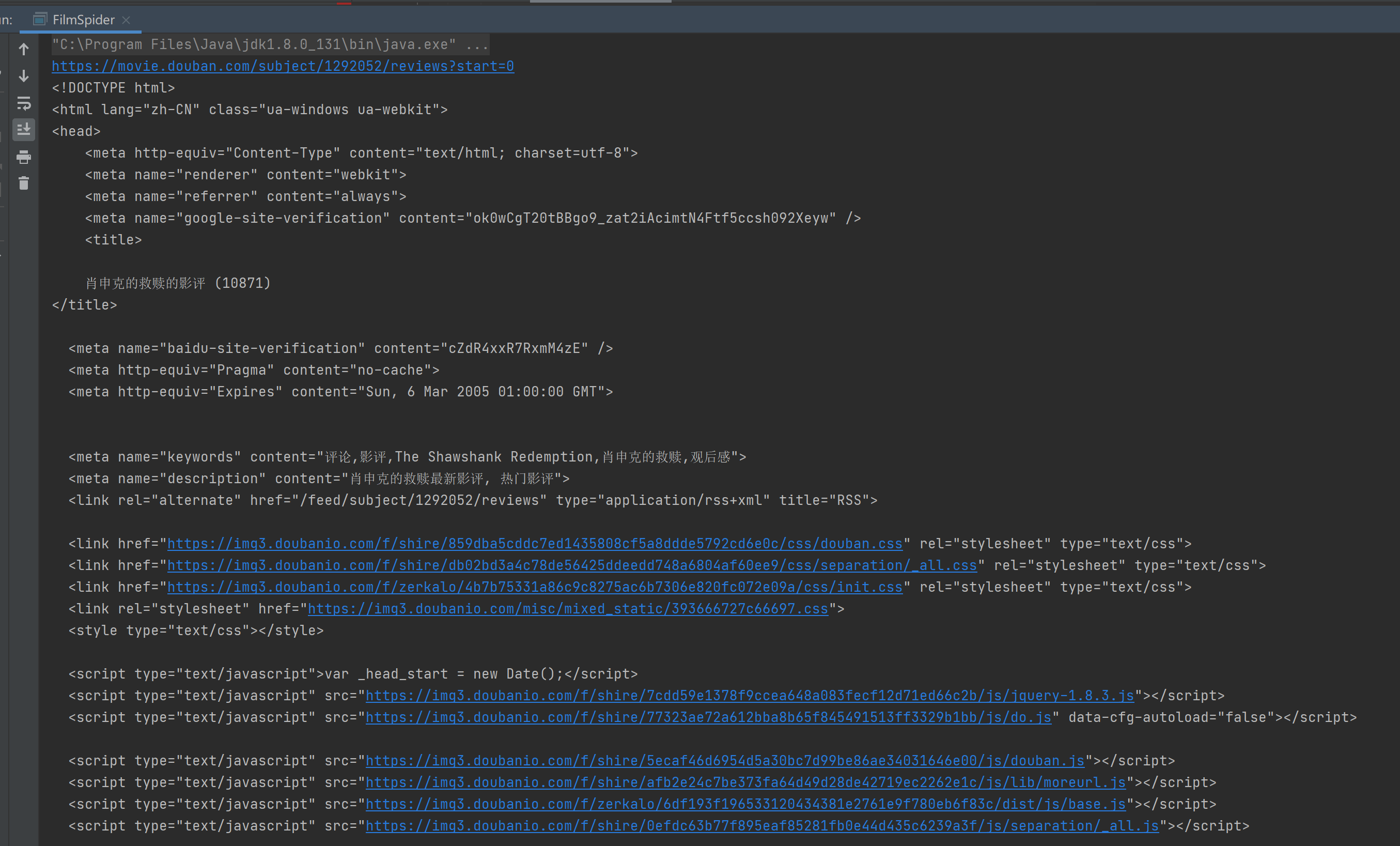
在没有解析之前我们得到得数据是什么。
我们直接控制台输出一下
是这些东西啦一些html数据
/** * 解析html内容 * @param content 待解析html内容 */ public void parseHtml(String content) { // 1. 用Jsoup封装响应数据, 转换成Document对象 Document document = Jsoup.parse(content); // 2. 使用Jsoup API提取该页面20块 影评信息 Elements elements = document.select("div.article > div.review-list > div > div.main.review-item"); // 3.解析数据(影评标题,影评人,评分,发影评时间,有用,没用,回复) for(Element item: elements) { // 1. header Element header = item.selectFirst("header"); String username = header.selectFirst("a.name").text(); //影评人 String rating = header.selectFirst("span").attr("title"); //评分 String date = header.selectFirst("span.main-meta").text(); //发影评时间 // 2. body Element body = item.selectFirst("div.main-bd"); String title = body.selectFirst("h2 > a").text(); //标题 //评论的综合元素 Element ratings = body.selectFirst("div.action"); String usefulCount = ratings.selectFirst("a.action-btn.up > span").text(); String uselessCount = ratings.selectFirst("a.action-btn.down > span").text(); String replyCount = ratings.selectFirst("a.reply").text(); // 3. 使用正则表达式 Pattern pattern = Pattern.compile("\\d*"); Matcher matcher = pattern.matcher(replyCount); replyCount = matcher.find() ? matcher.group() : "0"; // 4. String内容拼接 StringBuilder str = new StringBuilder(); str.append(title).append(",").append(username).append(",").append(rating).append(",") .append(date).append(",").append(usefulCount).append(",").append(uselessCount).append(",") .append(replyCount); // 5. 写入爬取到的内容 logger.info(str.toString()); } }jsoup解析得原理:jsoup.org/
-
爬取N页数据
/** * 爬取多页内容 */ public void requestByPages(int page){ int beginIndex = 0; for(int i = 0; i < page; ++i) { beginIndex = i * PAGE_SIZE; requestByUrl(BASE_URL + beginIndex); System.out.println(); } }
过程: main函数调用``requestByPages()告诉自己想要获得几页的内容,然后在requestByPages()里调用requestByUrl()把url传进去,然后requestByUrl()获得数据(字符串)调用parseHtml()`进行解析,变成目标格式写入日志
爬虫程序打包jar并再linux上部署
maven打包,双击package。
【上传到Linux】:
【基于后台执行爬虫程序,得到影评数据】
执行之后再本地会生成一个data文件 data/collect/ 里会存放日志文件
