

- 原文地址:Working toward fairer machine learning
- 原文作者:Michele Donini, Luca Oneto
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:PingHGao
- 校对者:shentaowang, PassionPenguin
让机器学习更加公正
编者注:Michele Donini 是 Amazon Web Services(AWS)的一名高级应用科学家。他和他的合著者热那亚大学计算机工程学副教授 Luca Oneto,已经论述了关于如何使数据驱动型预测对代表性不足的群体更公平的不同方法。Oneto 也因自己在算法公正性方面的工作而获得了 2019 机器学习研究奖。在本文中,Donini 和 Oneto 探讨了他们和其他合作者发表的关于从以人为本的角度设计机器学习(ML)模型和构建负责任的人工智能的研究。
什么是公正?
可以用许多不同的方式来定义公正,并且存在许多不同的概念形式,例如人口统计学均等,机会均等和机率均等。
算法的公正性是一个非常重要的主题,对许多应用都有影响,而这个问题需要进一步研究。对于机器学习模型而言,“公正”的定义仍然是一个开放的研究问题。
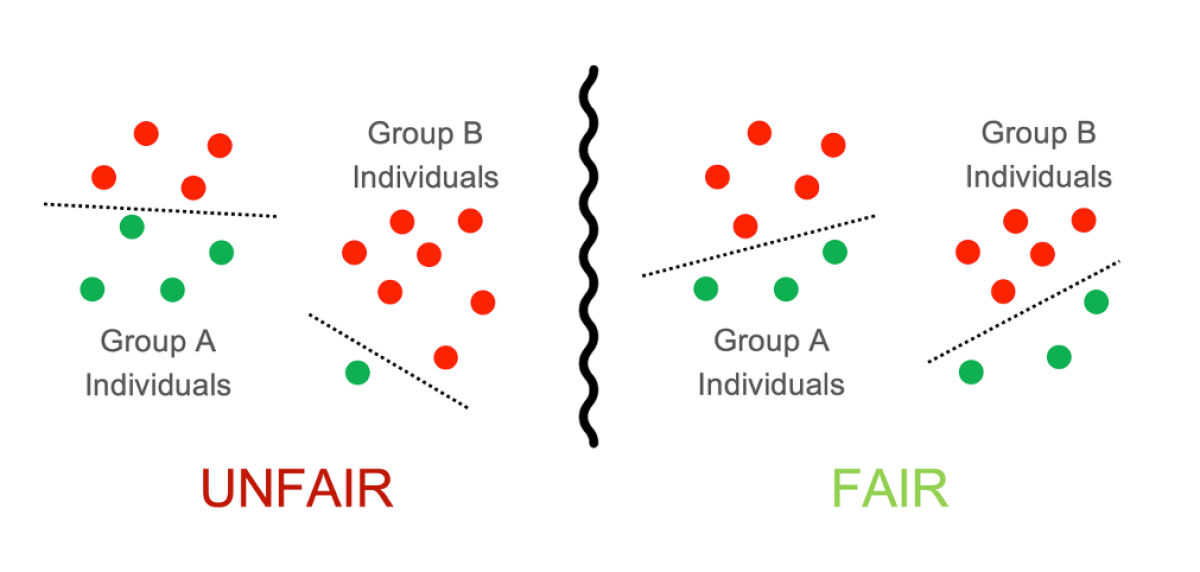
然而,关于公正普遍接受的想法是,学习到的机器学习模型无论是应用于人口的哪一个子群体(例如男性群体或女性群体),其表现都应相同或至少类似。
以人口统计学均等这一最常见的公正概念为例(有争议),它表示机器学习模型的某个输出(例如,决定贷款)的概率不应该取决于人口特定的属性值(例如性别,种族或年龄)。
让模型更公正
从广义上讲,我们可以将现有关于算法公正性的文献归纳为三类:
- 第一种方法是先对数据进行预处理以消除历史偏差,然后再将数据提供给经典的机器学习模型。
- 第二种方法是对已有的机器学习模型进行后处理。当需要使用复杂的机器学习模型而又不能改变其内部结构,或者重新训练它们不可行(由于计算成本或时间要求)时,此类方法很有用。
- 第三种方法,称为在线处理,是通过在模型的学习阶段施加特定的统计约束来实现公正性。这是最自然的方法,但是到目前为止,它需要针对特定的任务和数据集来量身定制临时解决方案。
广义上讲,当前关于算法公正性的文献主要可分为以下三种方法:数据预处理、对已有的机器学习模型进行后处理以及在线处理以及在线处理,通过在模型的学习阶段施加特定的统计约束来实现公正性。

我们决定探索和分析可能的技术,以使机器学习算法能够得到更加公正的模型。
我们从统计学习理论(描述机器学习的数学框架)最为基本的概念出发,具体指经验风险最小化理论。经验风险最小化的核心概念是,模型在测试数据上的性能可能无法准确预测其在真实数据上的性能,因为现实数据可能具有不同的概率分布。
经验风险最小化理论提供了一种从模型的“经验风险”估计模型的“真实风险”的方法。而模型的“经验风险”可以从已有数据中计算出来。我们将此概念扩展到机器学习模型的真实和经验公正风险。
以下是我们针对这些主题发表的三篇论文的摘要。
这篇文章提出了一种新的在线处理方法,这意味着我们将公正性约束纳入学习问题中。我们得出了所得模型的准确性和公正性的理论保证,并展示了如何将我们的方法应用于众多系列的机器学习算法中,包括线性模型和用于分类的支持向量机(一种广泛使用的监督学习方法)。
我们发现,在实践中,我们可以简单地通过要求两个向量之间的标量积保持较小(描述模型的权重向量与描述不同子组之间的区别的向量之间的正交性约束)来满足公正性约束。我们进一步发现,对于线性模型,此要求转化为一种简单的预处理方法。实验表明,我们的方法在经验上是有效的,并且相比最新方法表现出色。
“基于 Wasserstein barycenters 公正性回归”
在本文中,我们考虑了机器学习模型学习回归函数(与分类任务相对)的情况。我们提出了一种后处理方法,用于将实值回归函数(即机器学习模型)转换为满足人口统计学均等约束条件函数的方法(即,对于不同的子组而言,获得正向结果的可能性实际上应该是相同的)。特别是,新的回归函数与原始函数尽可能的相似,同时仍满足约束条件,使其成为最优的公正预测模型。
在该文章中中,我们考虑了机器学习模型学习回归函数的情况,并提出了一种后处理方法,用于将实值回归函数 —— 机器学习模型 —— 转换为满足人口统计学均等约束条件的函数。
我们假设敏感属性(不应使结果产生偏差的人口统计学属性)不仅在训练过程中对机器学习模型可见,在推断时也是可见的。我们在学习公正的回归模型和最佳转换理论之间建立了联系,后者描述了如何测量概率分布之间的距离。在此基础上,我们推导了关于最优公正预测模型的完备的表达式。
具体来说,在不公正回归函数下,不同的人群具有不同的概率分布。该类函数使具有敏感属性的群体对应的概率发生偏移。子群分布之间的差异可以使用 Wasserstein 距离进行计算。我们证明,最优公正预测模型的分布均值是使用 Wasserstein 距离计算得出的不同子组分布的均值。这个平均值被称为 Wasserstein 重心。
该结果提供了对最佳公正预测的直观解释,并提出了一种实现公正性的简单的后处理算法。我们为此过程建立了公正风险保证。数值实验表明,我们的方法在训练公正模型方面非常有效,错误率的相对增加小于公正性的相对收益。
"利用 MMD 和 Sinkhorn divergences 进行公正可迁移的表示学习”
第一篇论文描述了一种通用的学习方法,第二篇论文描述了一种回归方法,本文则涉及的是深度学习。我们展示了如何通过修改多任务学习的设置来提高人口统计均等性。在该设置中,深度学习模型将学习对多个任务有用的输入数据的单一表达。我们从理论上证明了,哪怕是将模型迁移到新的任务上,模型学习到的数据表达仍然有助于减少模型的偏差。
我们提出了一种学习算法,该算法基于两种不同的测量概率分布之间距离的方法来施加约束。这两种方法是最大平均差异和 Sinkhorn 散度。保持该距离较小可确保我们对相似输入有相似的表达方式,使它们仅在敏感属性上有所不同。我们在三个真实数据集上进行了实验,结果表明,所提出的方法明显优于当前最好方法。
算法公正性是一个非常重要的主题,对许多应用都有影响。在我们的工作中,我们尝试着成功地迈出了一小步,但是这个问题需要进一步研究。对于机器学习模型而言,即使对“公正”的含义进行定义仍然是一个开放的研究问题。
越来越清楚的是,我们需要在机器学习模型的生命周期中持续进行研究,以评估模型是否按照我们的期望进行工作。从这个意义上讲,我们需要着重注意许多其他研究主题(例如模型的可解释性和隐私性)与算法公正性研究有着深远的联系。它们可以协同工作,共同目标是提高机器学习模型的可信赖性。
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
