0/获得各种日期
import datetime
from dateutil.relativedelta import relativedelta
datetime.date.today()
datetime.datetime.now()
yesterday = datetime.date.today() + datetime.timedelta(-1)
last_month_date = datetime.date.today() - relativedelta(months=+1)
last_year_date = yesterday - relativedelta(years=+1)
1/编码方式
gb18030 gb2312 utf-8
2/在一行代码中创建一个列表
list1 = [1 if i > 0 else 0 for i in list2]
list1 = [1 for i in list2 if i >0]
3/回车换行符\n\r
<1>回车换行是2个字符,不是一个字符。
<2>回车符‘\r’会将光标定位到行首(是当前行的行首,不是下一行的行首),此时新输入的字符会覆盖之间已经存在的字符,用来做类似进度条的数据原地更新。\r return
<3>换行符‘\n’会将光标移到下一行的同一位置。\n new
<4>因此,回车换行符一般同时使用,这样可以将光标移动到新的一行的行首
4/python 的复制/浅拷贝/深拷贝的的区别?
python是面向对象的语言
在python中,给对象赋值实际上是对象的引用。
创建一个对象,然后把它赋值给一个变量,python并没有拷贝这个对象,只是拷贝了这个对象的引用。
一般有3种方法
<1> 直接赋值:
原始对象改变,被赋值的变量也会跟着改变。相当于2个变量a和b同时指向同一个对象,
所以如果对象发生了改变,变量会做相同的改变。
temp_list = [1,2,3,4]
b = temp_list
如果temp_list发生改变,则b也会跟着改变
<2> 浅拷贝:
a = copy.copy(b)
只是拷贝了对象,没有拷贝原始对象中的子对象,
所以原始对象的子对象发生改变,被赋值的变量的子对象也会发生改变
import copy
c = copy.copy(alist) # 浅拷贝
print(alist)
print(c)
[1, 2, 3, ['a', 'b']]
[1, 2, 3, ['a', 'b']]
alist.append(5) # 改变的是对象,不是子对象
prin(alist)
print(c)
[1, 2, 3, ['a', 'b'], 5]
[1, 2, 3, ['a', 'b']]
alist[3].append('cccc') # 改变了原始对象的子对象,所以一个改变,另一个也跟着改变
print(alist)
print(c)
[1, 2, 3, ['a', 'b', 'cccc'], 5]
[1, 2, 3, ['a', 'b', 'cccc']] # 里面的子对象被改变了
<3> 深拷贝
a = copy.deepcopy(b)
对原始对象的子对象也进行拷贝,
所以原始对象的任何改变不会造成赋值变量中任何元素的改变。建议使用这种
import copy
temp_list = [1,2,3,4]
d = copy.deepcopy(temp_list)
temp_list不管如何改变,d变量都不会发生改变
5/python中字符串转化为字典,有3种方法:
<1> 通过json转换:json.loads()
>>> import json
str= '{"name" : "john", "gender" : "male", "age": 28}'
dict = json.loads(str)
dict {u'gender': u'male', u'age': 28, u'name': u'john'}
但是使用 json 进行转换存在一个潜在的问题。
由于 json 语法规定 数组或对象之中的字符串必须使用双引号,不能使用单引号
<2> 使用eval()函数
str = '{"name" : "john", "gender" : "male", "age": 28}'
dict = eval(str)
dict {'gender': 'male', 'age': 28, 'name': 'john'}
str = "{'name' : 'john', 'gender' : 'male', 'age': 28}"
dict = eval(str)
dict {'gender': 'male', 'age': 28, 'name': 'john'}
<3> 使用ast.literal_eval()函数
import ast
user = '{"name" : "john", "gender" : "male", "age": 28}'
user_dict = ast.literal_eval(user)
user_dict {'gender': 'male', 'age': 28, 'name': 'john'}
user_info = "{'name' : 'john', 'gender' : 'male', 'age': 28}"
user_dict = ast.literal_eval(user)
user_dict {'gender': 'male', 'age': 28, 'name': 'john'}
6/字典之间的加减法
<1> 字典相加就是字典之间的合并,对所有的健取并集,
from collections import Counter
x = { 'apple': 1, 'banana': 2 }
y = { 'banana': 10, 'pear': 11 }
dict(Counter(x)+Counter(y))
结果:{'apple': 1, 'banana': 12, 'pear': 11}
<2> 字典相减,就是对相同键对应值的减法,如果没的,就保持原来的kv
dict(Counter(y)-Counter(x))
结果:{'banana': 8, 'pear': 11}
7/创建一个空的列表,有2种方式:
aaa = []
aaa = list()
8/全部删除列表中指定的元素?
a = [1,2,1,2,3,45,1,2,1]
方法1:
while 2 in a:
a.remove(2)
方法2:
result_list = list( filter(lambda x: x!= 2,a) )
9/ python的import的使用
<1>导入同一目录下的同级别模块
即2个.py文件在同一个目录下,直接导入即可,import xxx
<2>导入不同目录下的通级别模块
import sys
sys.path.append('../')
from xxx import xxx
<3>导入下级目录中的模块也很简单
需要下级目录中含有一个__init__.py模块,
from dirname import xxx
<4>导入上级(或者上上级)目录中的模块
需要先用import sys
sys.path.append('../../')
from xxx import *
<5>sys.path.append()的作用是先确定要导入模块的位置,然后再import位置下
10/关于时间
import datetime
import time
start = datetime.datetime.now()
time.sleep(30) # 什么也不操作,等待30秒
end = datetime.datetime.now()
print ( end - start)
print (end-start).days # 天数
print (end-start).total_seconds() # 30.029522 精确秒数
print (end-start).seconds # 30 秒数
print (end-start).microseconds # 29522 毫秒数
import datetime
datetime.datetime.now() 2019-04-30 20:27:20.384037
datetime.datetime.now().year 2019
datetime.datetime.now().month 4
datetime.datetime.now().day 30
datetime.datetime.now().hour 20
datetime.datetime.now().minute 27
datetime.datetime.now().second 20
datetime.datetime.now().microsecond() 384400
11/两种除法的区别?
<1> /是正常的除法,保留所有的商
<2> //是地板除,最后只保留整数部分,不会四舍五入,而是直接截取整数部分
<3> round(a,b),对a进行四舍五入,保留b位有效数字
<4> 17 % 3 # 取余
12/如何优雅地将多个字典里中相同键的值聚合在一个列表中
d= [ {'age':20,'name':"张三",'hometown':"北京"},
{'age':21,'name':"李四",'hometown':"河北"},
{'age':22,'name':"王五",'hometown':"天津"} ]
key1, key2, key3 = zip( *map(lambda x: (x['age'], x['name'], x['hometown']), d) )
print(key1)
print(key2)
print(key3)
(20, 21, 22)
('张三', '李四', '王五')
('北京', '河北', '天津')
13/如何求一个列表的均值/中位数/众数/最大值/最小值
import numpy as np
list1 = [1,2,3,4,5,6]
np.mean(list1)
np.median(list1)
counts = np.bincount(list1)
np.argmax(counts)
max(list1)
min(list1)
14/python如何写一个配置文件?
在pytcharm中之间新建一个普通文件(不是python文件),后缀名为.ini,因为configparser模块中的ConfigParser()函数只能识别.ini的文件
[oppo]
platformName = Android
platformVersion = 6.0
deviceName = 2a22cee
appPackage = com.sina.weibo
appActivity = .SplashActivity
url = http://127.0.0.1:4723/wd/hub
15/函数中怎么使用全局变量?
<1> 局部变量:是指在函数内部定义并使用的变量,它只在函数内部有效。
原因:每个函数在执行时,系统都会为该函数分配一块“临时内存空间”,所有的局部变量都被保存在这块临时内存空间内。当函数执行完成后,这块内存空间就被释放了,这些局部变量也就失效了,因此离开函数之后就不能再访问局部变量了,否则解释器会抛出 NameError 错误。
<2> 全局变量:和局部变量相对应,全局变量指的是能作用于函数内外的变量,即全局变量既可以在各个函数的外部使用,也可以在各函数内部使用。
<3> 全局变量约定使用大写字母。
<4> 定义全局变量的方式有以下2种:
1> 在函数体外定义的变量,一定是全局变量,例如:
demo = "C语言中文网"
def text():
print("函数体内访问:",demo)
text()
print('函数体外访问:',demo)
2>在函数体内定义全局变量。但是用global关键字对变量进行修饰后,该变量就会成为全局变量。例如:
def text():
global demo
demo = "C语言中文网"
print("函数体内访问:",demo)
text()
print('函数体外访问:',demo)
<5> 如果全局变量和局部变量使用了同一个名称,函数优先使用局部变量。
<6> global第一次是只能定义,不能赋值
def showvariable():
global a
a = '我是global'
print(a)
showvariable()
<7> 在函数内修改全局变量
count = 10
def f():
global count
count += 1
return count
<8> 在函数内修改全局变量,全局变量会被修改,如果再次访问全局变量,得到的是修改后的全局变量,尽量不要在函数内修改全局变量
用 global+变量名的形式,声明一个全局变量,我们看到通过关键字global,我们将count的值做了修改。但是我们建议尽量减少这种方式的使用,因为我们在函数内部修改了全局变量的值,如果后面还有其他函数使用这个变量的时候可能还认为count的值是还是10,其实已经变成11了,因此导致出错,而且不易排查。
16/数组和列表的区别?
<1> 二者都是用[]扩起来,但是数组的元素之间没有逗号,列表的元素之间用逗号隔开。
<2> 在pandas的df文件中,df.columns和df["列名"]得到的都是数组,而不是列表。但是可以通过.tolist()函数把数组转化为列表
17/小数转换为百分数?
<1>方法一
a = 0.3214323
bb = "%.2f%%" % (a * 100)
<2>方法二
a = 0.3214323
b = str(a*100) + '%'
18/如何查看同一个元素在列表中的所有下标?
temp_list = [1,2,4,4,5,5,5,8]
res = [idx for idx,i in enumerate(temp_list) if i ==5]
print(res)
print(res[-1])
19/数值型/离散型/标称型数据的区别
数值型:可以在无限的数据中取,而且数值比较具体化,例如4.02,6.23这种值(一般用于回归分析)
标称型:一般在有限的数据中取,而且只存在‘是’和‘否’两种不同的结果(一般用于分类)
离散型:一般在有限的数据中取,例如<25岁,介于25-30岁之间,介于30-35岁之间,>35岁(一般用于分类)
20/获得所在服务器的ip
import socket
myname = socket.gethostname()
myaddr = socket.gethostbyname(myname)
21/np.argmax()
对一个一维向量a,取出a中元素最大值所对应的索引
import numpy as np
a = np.array([3, 1, 2, 4, 6, 1])
b=np.argmax(a)
print(b)
22/如果你用的是anaconda,就是pip,如果你用的是python3,就是pip3,如果是python2,就是pip2
通过pip安装python包
pip install xxx
pip install xxx --upgrade
23/pycharm中Directory与Python packaged的区别
<1>Dictionary
Dictionary在pycharm中就是一个文件夹,放置资源文件,其中不包含__init__.py文件
<2>Python package
对于Python package而言,与Dictionary不同之处在于其会自动创建__init__.py文件。
简单的说,python package就是一个目录,其中包括一个或多个模块和一个__init__.py文件。
24/配置文件
import configparser
config = configparser.ConfigParser()
config.read("../config/config.ini")
a = config.get("PORT","idvr_port")
写ini文件
config.add_section("School")
config.set("School","IP","192.168.1.120")
config.set("School","Mask","255.255.255.0")
config.set("School","Gateway","192.168.1.1")
config.set("School","DNS","211.82.96.1")
config.write(open("../config/config.ini", "a"))
config.write(open("../config/config.ini", "w"))
修改int
config.read("../config/config.ini")
config.set("EMAIL","sendpwd","1234")
config.write(open("../config/config.ini", "r+"))
25/计算分位值
Python中可以利用Numpy库来计算分位数,示例如下:
import numpy as np
a = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
print(np.median(a))
print(np.percentile(a, 25)
print(np.percentile(a, 75))
26/ 什么是user-agent?
User-Agent是Http协议中的一部分,属于头域的组成部分,User Agent也简称UA。用较为普通的一点来说,是一种向访问网站(服务器)提供你所使用的浏览器类型、操作系统及版本、CPU 类型、浏览器渲染引擎、浏览器语言、浏览器插件等信息的标识。UA字符串在每次浏览器 HTTP 请求时发送到服务器!
27/ 什么是cookie?
<1> Cookie是当你浏览某网站时,网站存储在你机器上的一个小文本文件,它记录了你的用户ID,密码、浏览过的网页、停留的时间等信息,当你再次来到该网站时,网站通过读取Cookie,得知你的相关信息,就可以做出相应的动作,如在页面显示欢迎你的标语,或者让你不用输入ID、密码就直接登录等等。
<2> 你可以在IE的“工具/Internet选项”的“常规”选项卡中,选择“设置/查看文件”,查看所有保存到你电脑里的Cookie。这些文件通常是以user@domain格式命名的,user是你的本地用户名,domain是所访问的网站的域名。
<3> 如果你使用NetsCape浏览器,则存放在“C:PROGRAMFILESNETSCAPEUSERS”里面,与IE不同的是,NETSCAPE是使用一个Cookie 文件记录所有网站的Cookies。
28/计算2个列表的并集/交集/差集
并集: set(a).union(b)
交集: set(a).intersection(b)
差集: set(a).difference(b)
对称差集:set(a).symmetric_difference(b)

29/字典排序
方法一:
dic = sorted(dic.items(),key=lambda x:x[1],reverse=True)
dic = sorted(dic.items(),key=lambda x:x[0],reverse=True)
sorted()函数默认是升序排序,reverse=True是进行降序排序
这样得到是元组构成的列表,如果要转换为字典,需要用dict()函数,及dic = dict( sorted() )
方法二:
import operator
dic = sorted(dic.items(),key = operator.itemgetter(1))
dic = sorted(dic.items(),key = operator.itemgetter(1))
30/字典与json之间的转化?
在mysql数据库中不能存放字典类型的数据,因此需要把字典转换为json格式
import json
json_data = json.dumps(dict_data,ensure_ascii=False)
dict_data = json.loads(json_data)
31/正则表达式
import re
cols = sum( [re.findall(".+_.+", i) for i in list(data_df.columns)], [] ) # sum()函数中有2个列表,最终是把第一个列表的元素放在第二个列表中
32/os的使用
import os
os.path.abspath(__file__) # 得到当前.py文件的全部路径
os.path.dirname(os.path.abspath(__file__)) # 得到当前.py文件所在目录的全称
cwd = os.getcwd() # 得到当前.py文件所在目录的全称,和os.path.dirname(os.path.abspath(__file__))一样
os.path模块的常用方法
os.path.dirname(__file__): 返回当前文件所在的目录,不包含文件名
os.path.basename('/root/runoob.txt') ) # 返回文件名
os.path.dirname('/root/runoob.txt') ) # 返回目录路径
os.path.join(a,b) # 把2个文件可以连接在一起
33/转义
Python 使用反斜杠(\)转义特殊字符,如果你不想让反斜杠发生转义,可以在字符串前面添加一个 r,表示原始字符串:
print('Ru\noob')
Ru
oob
print(r'Ru\noob')
Ru\noob
34/把一个列表分成一定数量的份数
import numpy as np
aaa = range(100)
bbb = np.array_split(aaa,10)
35/单引号/双引号/三引号
<1> 在Python中,我们都知道单引号和双引号都可以用来表示一个字符串,二者没有任何区别,比如
str1 = 'python‘
str2 = "python"
<2> 如果字符串中有单引号
str3 = 'I\'m a big fan of Python.'
str4 = 'We all know that \'A\' and \'B\' are two capital letters.'
可以注意到,原来的字符串中有一个',而Python又允许使用单引号' '来表示字符串,所以字符串中间的'必须用转移字符\才可以。如果不想用转义符,就需要用双引号扩起来
str3 = "I'm a big fan of Python."
str4 = "We all know that 'A' and 'B' are two capital letters."
<3> 如果字符串中有双引号,为了避免使用转义符,你可以使用单引号来定义这个字符串。比如:
str5 = 'The teacher said: "Practice makes perfect" is a very famous proverb.'
<4> 这就是Python易用性和人性化的一个极致体现,当你用单引号' '定义字符串的时候,它就会认为你字符串里面的双引号" "是普通字符,从而不需要转义。反之当你用双引号定义字符串的时候,就会认为你字符串里面的单引号是普通字符无需转义。
<5> 结论:如果你不想使用转义符,那么:
如果字符串中含有单引号,那么字符串就用双引号表示
如果字符串中含有双引号,那么字符串就用单引号表示
<6> 三引号: 把字符串换行输出。至于是使用3个单引号还是双引号都是一样的,只需要注意如果字符串中包含有单引号就要使用双引号来定义就好了。
36/format()函数字符串格式化
使用大括号{}作为特殊字符代替%
<1> 默认位置
S = 'I {} {}, and I\'am learning'.format('like', 'Python')
I like Python, and I'am learning
<2> 设置数字顺序指定格式化的位置
S = 'I {0} {1}, and I\'am learning'.format('like', 'Python')
I like Python, and I'am learning
<3> 打乱顺序
S = 'I {1} {0} {1}, and I\'am learning'.format('like', 'Python')
I Python like Python, and I'am learning
<4> 设置关键字
S = 'I {l} {p}, and I\'am learning'.format(p='Python', l='like')
I like Python, and I'am learning
<5> 字典传参
D = {'l':'like', 'p':'Python'}
S = 'I {l} {p}, and I\'am learning'.format(**D)
<6> 列表传参
L0 = ['like', 'Python']
L1 = [' ', 'Lerning']
S = 'I {0[0]} {1[1]}, and I\'am learning'.format(L0, L1)
I like Lerning, and I'am learning
<7> 元组传参
T = 'like', 'Python'
S = 'I {} {}, and I\'am learning'.format(*T)
S = 'I {0} {1}, and I\'am learning'.format(*T)
37/在python中,None和"None"的区别
<1>None是python中自带的空对象,其类型是NoneType,None不能参与计算
<2>"None"是字符串
<3>np.nan是是float型,可以参与计算
<4>None和np.nan在数据中都是NULL类型,及是空值
38/ 内核和cpu的关系
<1> cpu,即处理器,一个cpu可以有多个内核,也就是多核处理器,内核(core)是cpu的核心,cpu是内核的载体,但是一个内核只能属于一个cpu
<2> cpu的中间,就是我们称作核心芯片的地方,由单晶硅做成,是电脑的大脑,所有的计算,接受,存储命令,处理数据,都是在这个只有指甲盖大小的地方进行的
<3> 中央处理器是一块超大规模的集成电路,是一台计算机的运算核心和控制核心。
<4> 多核处理器是指在一枚处理器中,集成了2个或者多个完整的内核。
39/ lambda()匿名函数
<1>python的匿名函数写作lambda,
当需要实现一定功能而又不想“大张旗鼓”的def一个函数时,lambda就是最优的选择。
<2>语法格式
f = lambda x: x**2
f(2) = 4
<3> lambda函数更广泛的应用场景在于该匿名函数作为另一个函数的参数传递时,应用就比较合适了,
例如,将lambda作为sort()函数的key参数,就可以实现特定功能的排序。
my_dict = {'a':2, 'b':1, 'c':5}
sorted(my_dict.items(),key=lambda x:x[1],reverse=True)
40/ zip()解压
zip函数人如其名,是打包或者解包的函数,接受2个以上可迭代变量(例如列表,数组等),输出对应位置组成元组后的迭代类型
a = ['a', 'b', 'c']
b = (4, 5, 6)
zip(a,b)
# <zip at 0x1da016d15c8>
list(zip(a,b)) # 最外层是列表
# [('a', 4), ('b', 5), ('c', 6)]
tuple(zip(a,b)) # 最外层是元组
# (('a', 4), ('b', 5), ('c', 6))
a = ['a', 'b', 'c', 'd', 'e']
b = (4, 5, 6, 7)
c = [True, False, True]
list(zip(a,b,c))
# [('a', 4, True), ('b', 5, False), ('c', 6, True)]
解包
aZip = (('a', 4, True), ('b', 5, False), ('c', 6, True))
a, b, c = zip(*aZip)
# a:('a', 'b', 'c')
# b:(4, 5, 6)
# c:(True, False, True)
41/ map() 映射:一个输入对应一个输出
<1> map函数也正如其取名一样,是一个将接受的迭代变量依次经过某种映射,并输出映射后的迭代变量
<2> a = [1, 2, 3, 4] map(str, a) --> ['1', '2', '3', '4'] # 改变数据类型
<3> a = [1, 2, 3, 4] b = [2, 2, 3, 3] list(map(lambda x, y:x**y, a, b)) [1, 4, 27, 64]
<4> 与zip函数中类似,当map里的函数参数长度不匹配时并不会报错,只是输出结果将由最短的决定
a = [1, 2, 3, 4]
b = [2, 2]
list(map(lambda x, y:x**y, a, b))
[1, 4]
42/ filter() 过滤作用,一夫当关,万夫莫开
与map函数类似,filter函数也接受一个函数及其变量作为参数,只是要求这个函数的返回结果是bool型,并用这个bool的结果决定输出的取舍问题。例如需要对一个输入列表过滤,要求保留3的倍数:
a = range(10)
filter(lambda x:x%3==0, a)
list(filter(lambda x:x%3==0, a))
43/ reduce() 万剑归宗:多输入,单输出
语法 reduce( func, 可迭代序列)
map()和filter()函数都是多入多出函数,实质上是完成了特定的变化或者筛选。reduce()函数是规约函数,将一系列的输入变量经过特定的函数后转换为一个结果输出。reduce()函数在python3中已经不再是全局调用函数,必须from functools import reduce
from functools import reduce
a = range(5)
reduce(lambda x, y: x+y, a)
# 10
44/ numpy对数组求平均值时如何忽略np.nan值
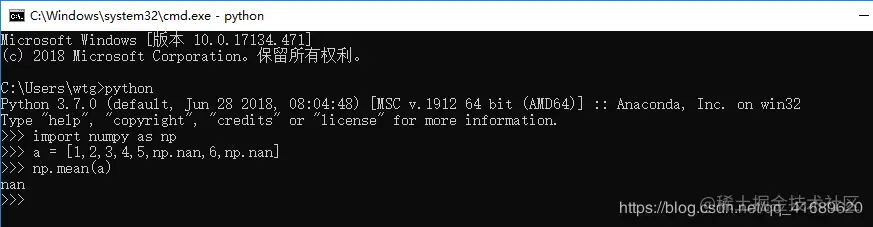
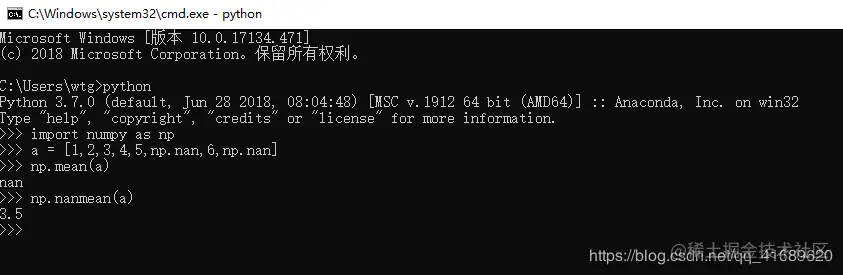
<1>前沿:在对numpy数组求平均np.mean()或者求数组中最大最小值np.max()/np.min()时,如果数组中有np.nan,此时求得的结果为:nan,那么该如何忽略其中的np.nan呢?此时应该用另一个方法:np.nanmean(),np.nanmax(),np.nanmin()
<2> 使用np.mean()的效果
<3>使用np.nanmean()的效果
<4> pd.pivot_table(final_data_df,index="",value="",aggfunc=np.mean),在这种情况下,如果value这一列中有np.nan,np.mean是可以忽略np.nan的,直接计算均值
<5> 计算中位数
np.median(list)
np.nanmedian(list)
<6> 计算方差
np.var()
np.nanvar(list)
48/列表之间的子集关系
A = [1,2,3,4,5]
B = [1,2,3]
C = [1,2,3,4,5]
set(A) < set(B) #A是B的真子集?
False
set(A) > set(B) #B是A的真子集?
True
set(A) > set(C) #C是A的真子集?
False
set(A) >= set(C) #C是A的子集?
True
49/python对字典进行排序
字典是由一个或者多个键值对构成的
对字典进行排序,可以是按照键的大小进行排序,也可以按照值的大小进行排序
得到的结果形式为[(k,v),(k,v),(k,v)]
import operator
sortedClassCount = sorted( my_dict.items(),key=operator.itemgetter(0) )
sortedClassCount = sorted(my_dict.items(),key=operator.itemgetter(0),reverse=True)
sortedClassCount = sorted(my_dict.items(),key=operator.itemgetter(1))
sortedClassCount = sorted(my_dict.items(),key=operator.itemgetter(1),reverse=True)
50/批量删除列表中的某个值
以删除np.nan为例:
import numpy as np
houzhen = [11,22,np.nan,33,np.nan]
while np.nan in houzhen:
houzhen.remove(np.nan)
print(houzhen) --> [11,22,33]
删除某个值
result = list( filter(lambda x: x not in ["","",""],可迭代序列) )
51/在一定范围内,随机产出一个随机数
import random
resule = random.uniform(x,y)
# 随机产生一个介于x和y之间的浮点数,x和y都是闭区间
52/ reverse()函数和reversed()函数
功能: 对列表进行翻转,不是排序
temp_list.reverse() # 对列表进行翻转,没有返回值,直接对temp_list进行修改,,有点类似于temp_list.remove(删除某个元素)
new_list = list( reversed(old_list) )
53/return语句
在函数def中,如果有return语句,
一旦执行return语句,则return后面的语句不再执行,直接退出函数,
即使该return语句是在while循环中。
所以,return语句是和def配套使用的,return语句只能在函数中
54/ python中删除列表元素的坑
<1> 问题再现

<2> 原因分析
for i in item: 是对下标进行遍历操作,remove()是对元素进行删除
Python中,list 属于线性表,用一块连续的内存空间存储元素,调用remove()函数删除指定元素时,会删除内存地址中的元素,删除指定元素后,后面所有元素会自动向前移动一个位置;
本例列表中,第1个3的下标为2,当删除第1个3后,后面所有元素会自动向前移动一个位置,即第2个3的下标变成了2,因为 for i in item 已经遍历过下标为2,循环遍历时,会自动跳过第2个3;
使用list.pop()函数删除指定元素的时候,也存在上述的坑。
<3> 解决办法
方法一:深拷贝
import copy
a = [1, 2, 3, 3, 3, 4]
b = copy.deepcopy(a)
for i in a:
if i == 3:
b.remove(i)
print(b)
[1, 2, 4]
方法二:while判断
c = [1, 2, 3, 3, 3, 4]
while 3 in c:
c.remove(3)
print(c)
[1, 2, 4]
方法三:列表推到式
d = [1, 2, 3, 3, 3, 4]
new_d = [i for i in d if i != 3]
print(new_d)
[1, 2, 4]
方法四: filter(func,list)
new_list = list( filter( lambda x: x!=3,[1,2,3,3,3,4] ) )
[1,2,4]
<4>总结
删除列表中指定元素时,建议不要使用 for 循环
55/ python 中的strip()函数的作用
strip()方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
该方法只能删除开头和结尾的字符,不能删除中间部分的字符
lstrip()是只删除头部的指定字符串,
rstrip()是只删除尾部的指定字符串。
56/read() readline() readlines()的区别
readlines()
readlines()方法读取整个文件所有行,一列表形式存储,列表中每一个元素就是一行数据。
每行作为一个元素,但读取大文件会比较占内存。
for line in file.readlines(): # 对于每一行数据
line = line.strip() # 去掉首尾的空格或者换行符
temp_list = line.split("\t") # 根据制表符分割,返回列表
readline()
从字面意思可以看出,该方法每次读出一行内容,
所以,读取时占用内存小,比较适合大文件,该方法返回一个字符串对象。
f = open("a.txt")
line = f.readline()
print(type(line)) # 是字符串
while line:
print(line)
line = f.readline()
f.close()
57/把一个列表分成多个小列表
temp_list = ['B071LF9R6G',
'B0714BP3H4',
'B0756FL8R7',
'B072HX95ZR',
'B07CX389LX',
'B07D9MZ7BD',
'B07D9L15L5',
'B00L1UNPZ0',
'B07KDL9RSD',
'B01N02WUM3',
'B072KTNZMW',
'B071Z71BXW',
...
...
...
'B00DU76BOY',
'B07D9NC33M',
'B07G82D89J',
'B076C9X4KS',
'B07CTMG6Y9',
'B071JZ78TD',
'B01NBPP89Y',
'B000LJ60F4']
size = 10
b = [ t[i:i+size] for i in range(0,len(temp_list),size) ]
58/datetime包
datatime包括date,time,datetime
datetime.datetime
datetime.date
datetime.time
59/向上取整,向下取整,四舍五入,分别取整数部分和小数部分
向下取整:
直接用内建的 int() 函数即可:
int(3.75) = 3
四舍五入:
round(3.25) = 3.0;
round(4.8) = 5.0
向上取整:
向上取整需要用到 math 模块中的 ceil() 方法
import math
>>> math.ceil(3.25)=4.0
>>> math.ceil(3.75)=4.0
>>> math.ceil(4.85)=5.0
分别取整数部分和小数部分
有时候我们可能需要分别获取整数部分和小数部分,这时可以用 math 模块中的 modf() 方法,
该方法返回一个包含小数部分和整数部分的元组,小数部分在前
import math
math.modf(3.25) (0.25 ,3.0)
math.modf(3.75) (0.75, 3.0)
math.modf(4.2) (0.2 ,4.0)
60/ random.sample()
import random
list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
for i in range(3):
slice = random.sample(list, 5)
print(slice)
print(list, '\n')
61/ %%time %time %timeit都是什么意思
%%time 是一个神奇的命令。这是伊普顿的一部分。
%%time:打印整个单元格的运行时间,
%time: 只打印该行的运行时间
比如在juypte notebook的一个cell中,在开头%%time,可以知道执行整个cell需要多少时间
如果想知道某一行代码需要多少时间,可以在这一行代码的开头写%time

62/python截取字符串
基本语法:
s = '123456789'
result = s[start_index:end_index]
这样就可以截取相应的字符串,其中index是从0开始的,可以是正数或者负数
end_index可以不写,如果不写,默认就是一直截取到末尾。
如果写了end_index,则end_index所在的字符不会被截取。
如果start_index和end_index一样,则返回的是 空
str = '12345678'
print str[0:1]
>> 1
print str[1:6]
>> 23456
num = 18
str = '0000' + str(num)
print str[-5:]
>> 00018
63/替换字符串.replace()
一般语法:
变量.replace('被替换的内容','替换后的内容',替换的次数)
一共有3个参数,第三个参数,及替换的次数这个参数可以为空,及表示替换所有的。
注意:使用replace()函数替换的字符串仅仅是临时的变量,需要赋值给新的变量才行。
str = 'akakak'
new_str = str.replace('k','8')
print(new_str)
>> 'a8a8a8'
64/查找字符串.find()
一般语法:
变量.find("要查找的内容target"[,开始位置,结束位置]),
开始位置和结束位置,表示要查找的范围,这2个参数为空则表示查找所有,及从整个变量中去查找。
查找到后会返回位置index,位置从0开始算,如果没有找到则返回-1。
该函数只要找到第一个就会返回,剩下的就不会去找了。
str = 'a,hello'
print str.find('hello')
>> 2
65/分割split()
变量.split("分割标示符号",[分割次数]),分割次数表示分割最大次数,为空则进行全部分割
返回一个列表
str = 'a,b,c,d'
a = str.split(',')
print(a)
['a','b','c','d']
b = str.split(',',1)
print(b)
['a','b,c,d']
66/re.split()
因为python中的string自带的split()函数不支持多种符号同时切分。
所以我们可以需要用正则表达式来进行分割。
import re
line='hello,world?您好'
a = re.split('[,?]',line.strip() )
print(a)
结果是:['hello', 'world', '您好']
66/sorted()排序函数
一般语法:有3个参数
sorted(可迭代序列,key=函数,reverse=True/False)
key参数可以写或者不写,用的着的时候就写,用不着的时候就不写
reverse参数,英文意思是颠倒,翻转,该参数默认是False,及不翻转,也就是从小到大排序。
如果reverse=True,则是降序排序。
temp_list = [8,45,52,94,563,12]
aa = sorted(temp_list)
bb = sorted(temp_list,reverse=True)
temp_dict = {'张三':125,'李四':256,'王五':9845,'赵六':1}
bb = sorted(temp_dict.items(),key=lambda x:x[1],reverse=True)
temp_dict = {'张三':125,'李四':256,'王五':9845,'赵六':1}
bb = sorted(temp_dict.items(),key=lambda x:x[1])
67/ifelse语句
if后面不一定要加else,没有else时,先判断if执行的条件,满足条件则执行if里面的代码,然后执行后面的代码;不满足条件则直接执行后面的代码。
有if语句一定要写else语句吗?
当然不是,怎么能有必须写else的道理。
这个错误在我刚开始学代码的时候也遇到过,我那时候的写法是
else:
pass
后来发现根本没有什么卵用。没有else不写就好了
68/continue和break的区别
continue语句用来告诉Python跳过当前循环的剩余语句,然后继续进行下一轮循环。
break是跳出整个循环,然后执行循环外面的语句。
demo:
for i in ['1','2','3','4']:
if i == '1':
continue
else:
pirnt('aaaaa')
print("bbbbb")
如果我们在i=='1'的时候,执行了continue,则跳过当前循环剩下的语句,直接进行接下来的循环,及i=='2'
如果我们在i=='1'的时候,执行了break,则完全跳出整个循环,直接执行print('bbbbb')


