


文/ 阿里云 DataWorks 团队 - 秦奇
代码缺陷检测是什么?
在做代码审查(CodeReview, CR)时,你一定会有这样的想法:为什么每次都必须人工审查?机器能不能代替人工来做这件事?经过调研,我得出的结论是:目前机器并不能完全代替人工,但是可以做一些辅助性的工作来提升人工CR的效率。比如利用一些算法或者规则,可以自动发现代码中隐藏的缺陷,这就涉及到了代码缺陷检测相关的技术。 缺陷检测有两种思路,一种是 仅仅预测是否存在缺陷,另一种是能够识别出是什么缺陷,并且可以定位到具体到位置。 两个思路对于开发者都很有帮助,尽早发现代码中的问题便可以节省很大的精力和成本。另外,也存在缺陷修复相关的研究,可以针对缺陷提供修复的补丁(Patch),实现缺陷自动修复。
代码缺陷检测的发展
在软件测试技术发展的同时,就有了很多针对缺陷检测技术的研究,有效的缺陷检测可以提升软件测试的效率。大致总结了下,缺陷检测技术的发展可以分为以下几种:
- 最开始人们根据历史缺陷总结出一些明显的特征,比如文件修改次数、代码复杂度等,后续开发如果遇到类似特征的代码文件,则需要重点对待,其大概率存在缺陷。
- 后续人们总结出常见缺陷的固定写法或规则,出现了当前普遍的基于静态规则的缺陷检测方法,可以检测出指定的缺陷类型,甚至该能力已经集成到了开发阶段,在开发时即可进行实时检测,尽早避免问题。
- 随着近几年深度学习技术发展迅速,也有很多人将此技术运用在缺陷检测方面,基于历史缺陷数据的元信息或代码信息进行训练,即可对代码文件进行预测和识别指定缺陷。

代表性的产品和技术分析
下面介绍几款代码缺陷检测领域中有代表性的产品和背后技术。
Infer 和 Getafix(Facebook)
这两个是 Facebook 旗下的缺陷检测和自助修复工具。
Infer 是一个代码静态分析工具,它可以在发布前就发现代码中存在的缺陷,目前已经在 github 上开源,拥有12K的star,是一个面向 Java、C/C++、Objective-C 等语言的缺陷检测工具。针对于 Java 代码,它可以发现空指针异常、资源泄漏等众多缺陷。Infer一般的工作流程分为 捕获(Capture) 和 分析(Analysis) 两个阶段。在捕获阶段,Infer 会将代码编译为一种内部中间语言,然后在分析阶段,Infer 会单独针对每一个函数和方法进行分析检测,发现 bug 便会终止本方法的运行,同时不影响其他方法的继续分析。可以多次运行分析命令,直到没有任何bug被检测出来。参考下图:

运行 infer run -- javac Hello.java 之后,即可看见输出:

可以在这里进行简单试用。
而 Getafix 是一款缺陷修复工具,它可以针对 Infer发现的缺陷推荐可信的修复补丁进行修复,已经部署在Facebook 的应用中。Getafix 工作原理是将一种新的层次聚类算法应用到开发者过去所做的数千个代码更改(Code Change)中,同时查看更改本身和更改周围的上下文,以提供准确的修复建议。
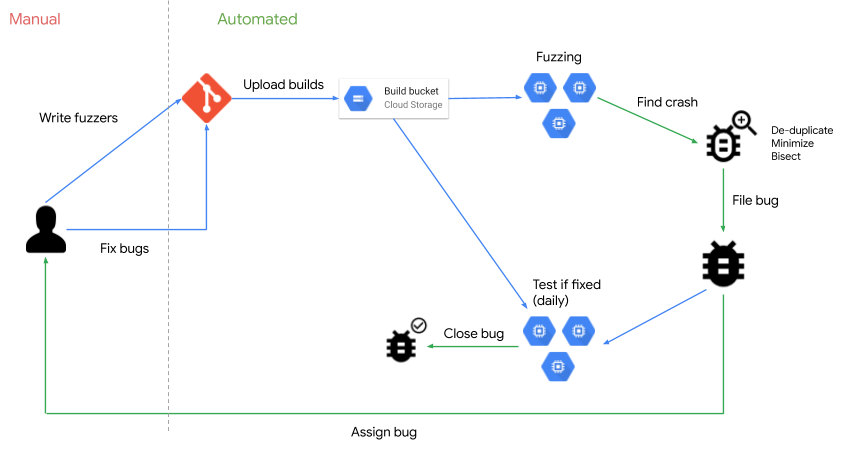
ClusterFuzz(谷歌)
谷歌的 ClusterFuzz 采用模糊测试(Fuzzing)的理论进行软件安全和稳定性的问题检测。Fuzzing 技术是一种基于黑盒的测试技术,通过自动化生成并执行大量的随机测试用例来发现产品或协议的未知漏洞。截止2021年2月,ClusterFuzz 已经在谷歌产品中发现了将近29000个 bug,在开源产品中发现了26000多个 bug。详细结构可以参考下图:
SonarQube
SonarQube 是有名的基于静态分析规则的实时代码检查工具,可以方便进行本地集成。它支持上千条相关规则,支持包括JS、TS等语言在内的27种编程语言。它基于复杂度分布、重复代码、单元测试统计、代码规则检查、注释率、潜在的 bug 和结构与设计 七个维度检测代码质量。其中bug检测是通过 Findbugs、PMD、CheckStyle 等工具进行检测的。并且 SonarQube 除了 部署服务器版本之外,也提供了轻量的IDE插件,比如 VsCode 中的SonarLint 插件,支持多种语言的编码格式和缺陷检测。
PRECFIX(阿里巴巴)
PRECFIX(Patch Recommendation by Empirically Clustering)是阿里巴巴工程师提出的代码缺陷检测和修复的工具,它会基于代码提交数据,提取“缺陷修复对”,即缺陷修复前的片段和修复后片段,然后将相似的“缺陷修复对”聚类,提取成模版。之后对源码进行扫描,根据模版内容进行匹配,从而推荐出对应的修复建议。
经过初步试用,可以进行简单总结对比下:
| SonarQube | Infer | |
|---|---|---|
| 支持语言类型 | Java、C、JS、Python等27种语言 | Android、Java、C、C++、Objective-C |
| 使用方式 | 本地服务器或IDE插件 | 命令行 |
| 支持CI(持续集成) | 是 | 是 |
| 效果 | 1、IDE插件支持多种规则,类似于ESLint的工作方式,可以检测出常见的缺陷、代码规范等问题 | |
| 可以发现空指针异常、未关闭的IO流等 |
常用的缺陷检测技术方案
根据资料总结出一些缺陷检测常用的方案,列举如下:
机器学习算法:基于代码变更信息训练缺陷预测模型
首先不得不提到 SZZ算法,它一般用来识别缺陷引入的变更,促进了缺陷检测技术的发展。它基于版本控制系统(如Git)的变更记录进行识别,主要流程为:
- 识别缺陷修复变更:在所有的代码变更中,识别包含缺陷Id的变更
- 识别被修复的缺陷代码:利用版本控制系统的diff算法来确定对应缺陷所修改的代码行(即缺陷代码)。
- 识别可能的缺陷引入变更:根据变更历史,第一次对于缺陷代码的提交记录可能就是引入缺陷的变更。
- 噪音数据消除:从可能的缺陷引入变更中去除噪音数据(即一些无关的代码提交,比如缺陷发现之后的提交)
SZZ算法提供了识别缺陷引入变更的方法,后来的研究发现,SZZ算法产生的数据存在大量噪音,所以产生了很多针对此问题的优化算法:
- Annotation Graph SZZ(AG-SZZ ) :它会去除空行、代码风格相关的修改,并且使用Annotation Graph(一种代码变更过程的追踪工具)来对代码变更提交历史进行追踪。
- Meta-change Aware SZZ(MA-SZZ ):它会忽略包括分支创建、合并和修改文件属性的变更,即元变更。
- Refactoring Aware SZZ(RA-SZZ):它会在忽略代码重构修改,因为重构不会更改软件的外部行为。
虽然SZZ存在噪音,但是大部分代码缺陷检测方案还是经常会使用SZZ算法来进行数据标注的工作。
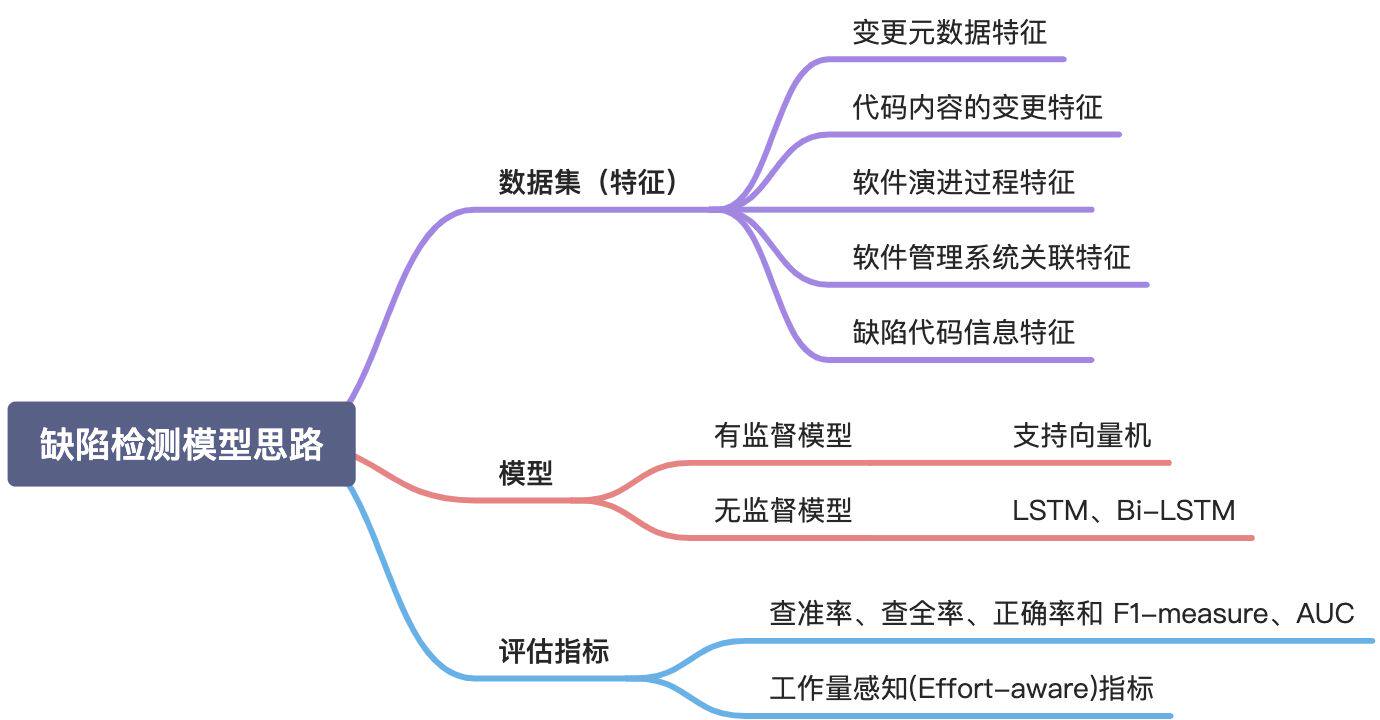
基于SZZ算法检测出的缺陷变更,可以提取不同纬度的特征进行表示,之后利用机器学习技术代构建码缺陷预测模型。一般提取的特征包含:
- 基于变更元数据的特征,比如开发者、提交时间、变更日志、修改文件行数等
- 基于变更代码内容的变更,比如代码复杂度特征,变更代码、日志和文件名的词频率、或者基于变更前后代码文件的抽象语法树(AST)相同类型节点数量的差值。
- 基于软件演进过程的变更,即基于项目代码修改历史量化变更,比如变更相关文件被修改的次数、修改文件的开发者人数等信息
- 与软件项目管理系统相结合,可以提取更多纬度特征,比如CR信息、缺陷信息等。
- 有缺陷的代码信息特征,一般是源代码或者对应的抽象语法树
常用的模型分为有监督模型(Supervised )和无监督模型(Unsupervised)。两者的区别就是是否有已知标签的数据集(即已知是否有缺陷的代码变更数据), 其中有监督可以根据标注后的代码构建分类或者回归模型,常用的是支持向量机(Support Vector Machine, SVM)分类器等;无监督模型不需要这些标注数据,可以根据代码变更的不同角度提取特征,并用特征向量进行表示,常用的模型有LSTM、双向LSTM(Bi-LSTM)等。
该方案一般的评估指标有:
- 查准率、查全率、正确率和 F1-measure、AUC等机器学习领域常用的指标
- 工作量感知(Effort-aware)指标 是针对在有限的时间和资源内如何检查到更多的缺陷问题提出的,是指当开发者根据预测模型的预测结果进行代码审查时,审查一定数量的代码(即工作量)所能检查到的缺陷数量或者比例。
总结一下,机器学习模型的一般思路可以参考下图:
代码相似性分析
该方法借鉴自然语言处理(Natural Language Processing, NLP)中的向量化思想,结合数据挖掘技术提出一种缺陷检测方法:将含有已知缺陷的代码嵌入到向量中,同样将待检测的目标代码也进行向量化表示,然后根据向量间的距离来判断是否与缺陷代码相类似。
基于程序频谱的缺陷定位方法
**程序频谱 **主要是指程序执行过程中产生的关于程序语句的覆盖信息,以及执行是否通过的信息。这一概念后来被应用于程序代码分析。针对一条测试语句,执行通过的测试用例越多,则说明该语句存在缺陷的可能性(怀疑率)越小,反之则很可能存在缺陷。不过,一般正常的系统中,成功执行的测试用例都占绝大多数,这样不均衡的结果会对怀疑率产生影响,所以一般需要调节成功测试用例的贡献度,以产生较好的结果。
缺陷修复技术
下面还有一些关于缺陷修复的技术也大概介绍下:
生成-验证缺陷修复技术
英文是Generate-and-Validate,生成验证式的方法主要分为两步,第一步是通过搜索生成一系列的补丁方案,然后运行测试用例。如果所有的测试用例都通过,则认为修复成功,否则继续搜索、验证,直到成功或超时。常用的生成验证式的修复方法有GenProg,RSRepair等。
语义驱动
英文是 Semantics-driven,语义驱动式的方法将修复问题形式化表示,通过求解的方式来得到最终的补丁,比较经典的算法有 SemFix,DirectFix,Angelix,NOPOL,DynaMoth 等。
目前存在的技术挑战
上面介绍了很多代码缺陷检测相关的方法,但其实很难运用在实际的生产中。实践中会遇到很多困难,这些会直接影响到最终的缺陷检测效果。
- 缺乏高质量的数据集。一般采用打标数据进行训练会相对容易,但是实际生产中很难收集到含有打标信息的代码数据,而自动打标的准确率偏低。另外也依赖于开发人员的提交信息和软件管理系统的缺陷管理信息,如果这部分数据不够准确,也会影响到最终训练的结果。
- 业务复杂,缺陷类型繁多。实际生产当中,因为业务复杂且类型多样,而对应的缺陷类型也是多种多样,这样就要求训练集足够丰富,否则模型泛化能力就会很差,换一种业务代码可能效果就不会很好。
- 缺乏统一的评估方法。比如缺陷修复技术中基于测试用例的生成验证式方法,根据是否通过所有测试用例来判定其修复是否成功。但是实际当中,通过测试用例并不代表软件无任何隐藏缺陷,这样对于补丁的评估会带来很大误差。
未来展望
关于代码缺陷检测,市面上看到最多的是 基于静态规则扫描的检测方法,不过随着机器学习技术的发展,已经有了很多基于机器学习算法的研究。可以预见,最后一定是智能算法的天下,并且智能算法会介入到 软件开发的全生命周期,从而最大化的提升生产效率。之前看过 GPT-3 的在代码生成方向的惊艳效果,相信这一天的到来不会太久。
以上仅个人愚见,更细节的知识和内容还在学习中,如有疑问欢迎拍砖、交流。
参考文献
本篇文章前后参考了众多的论文和资料,部分内容列举如下:
-
深度学习源代码缺陷检测方法
除文章外还有更多的团队内容等你解锁🔓
