

一. 代码流程
refreshNodes 逻辑
1.读取 dfs.host 和 dfs.hots.excludes 执行的文件内容,获取两种机器列表 includes 和 excludes
2.refreshDatanodes 遍历所有 DN,检查是否在 includes 列表里
(1)若不在 includes,禁止 DN 和 NN 联系(若未指定 include 文件的时候,默认认为都在)
(2)若在
在 excludes 里,startDecommission
不在 excludes 里,stopDecommission
3.startDecommission
(1)直接 skip decommissioning / decommissioned 的 DN
(2)Dead DN 直接设为 DECOMMISSIONED,返回
(3)设置状态为 DECOMMISSION_INPROGRESS,记录时间
(4)checkDecommissionState 检测 DN 的下线状态
4.checkDecommissionState
主要是调用 isReplicationInProgress 对 DN 上的「所有 blk」的副本进行状态(坏块/下线/冗余/LIVE ...)统计。
因为下线,造成 LIVE 副本数 < 期望副本数:
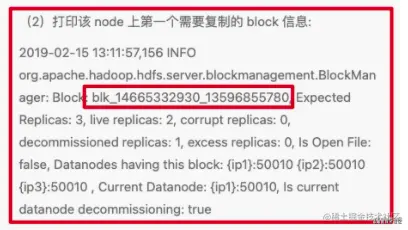
(1)UC 状态的 blk 若当前副本数 > 最小副本数要求(默认 1),直接 skip,先不处理,等待写完;否则 underReplicatedInOpenFiles 计数器+1(2)打印该 node 上第一个需要复制的 block 信息:
2019-02-15 13:11:57,156 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockManager: Block: blk_14665332930_13596855780, Expected Replicas: 3, live replicas: 2, corrupt replicas: 0, decommissioned replicas: 1, excess replicas: 0, Is Open File: false, Datanodes having this block: {ip1}:50010 {ip2}:50010 {ip3}:50010 , Current Datanode: {ip1}:50010, Is current datanode decommissioning: true
(3)如果只在 decommission 的 node 上有副本,decommissionOnlyReplicas计数器+1
(4)若该 blk 不在 neededReplications 和 pendingReplications里,加入到 neededReplications(blk划分优先级,插入优先级队列)
(5)该 DN 上的 blk 都处理完,检查 DN
<1> 若 DN dead 且 无blk 需要复制 和 等待复制,返回 false (可以置为 Decommissioned)
<2> 否则,返回 true (还在 Decommissioning)(6)更新 DN 的 decommissioningStatus 计数器
5.上一步说了,需要复制的 blk 会放入 neededReplications,内部维护了 List<LightWeightLinkedSet> priorityQueues 优先级队列。
优先级的划分:
ReplicationMonitor
neededReplications 和 pendingReplications 这个类比较核心,NN 有一个 ReplicationMonitor 线程,用于处理「副本恢复」和「冗余删除」,其中「副本恢复」逻辑,就是围绕着这 2 个类进行的。
首先,根据 LIVE 节点个数,计算出 最多「恢复」和「删除」的个数
(1)「最多」可「复制的」blks 数
blocksToProcess = LIVE DN 个数 * dfs.namenode.replication.work.multiplier.per.iteration(默认 2)
(2)「最多」可「删除的」blks 数
nodesToProcess = LIVE 节点个数 * 0.32(可配置的系数)
然后,计算「复制」和 「删除」工作
(1)从 neededReplications 里,按照「优先级」从高到低,最多选出 blocksToProcess 个要复制的 block list(有优先级)
(2)按优先级处理选出的 block list,选择复制源 srcNodes
注意:
<1> UC blk 不会被复制<2> 可能存在某个 block 无满足条件的复制源,只打印block日志 ,不处理
<3> LIVE副本 + pendingReplications>= requiredReplication 也不需要复制
(3)选择目标 targetNodes
注意:
<1> 无 target ,跳过不处理<2> UC blk不处理
<3> 副本足够不处理
<4> 副本足够,rack 不足,但是选出的 targetDN 的 rack 和 srcDN 一样(没有新 rack),skip 不处理
(5)把 BlockTargetPair(blk, targets) 保存到 srcDN 的 replicateBlocks队列里
(6)把 blk 记录放到 pendingReplications 里
(7)若 选出的 targetDN 足够了,从 neededReplications 里移除 blk
blk 的流转
1.PendingReplicationMonitor 线程会检测 pendingReplications 中,在规定时间内还没完成 copy 的数据块,从 pendingReplications 移到 timedOutItems 列表里;
2.ReplicationMonitor 线程的 processPendingReplications() 方法又会处理 timedOutItems 里的 blks,最终再次放入 neededReplications 优先级队列里。
CMD 下发
NN 处理 srcDN 心跳的时候,会从 srcDN 的 replicateBlocks 取出 maxTransfer个blks,给 DN 下发 cmd=DNA_TRANSFER 命令。
(1)maxTransfer = dfs.namenode.replication.max-streams(NN 端参数,默认2) - xmitsInProgress
(2)xmitsInProgress 表示当前 DN中正在进行DataTransfer 的线程数
DecommissionManager
DecommissionManager 维护了一个 Monitor 线程,默认每隔 30s 检测一次,一轮检查 5 个 DN。
调用前面说到的 checkDecommissionState 方法,检查 DN 是否下线完成。
二. 细节注意点
1.decommission 和 取消 decommission 操作比较简单,调整 exclude 文件的内容(node 在不在 exclude 文件里),然后执行 refreshNodes 操作即可
2.已经处于 decommission 的节点,再次执行 refresh,不做处理(直接 skip),只有未 decommission 的节点才会执行 startDecommission (如果 startDecommission 耗时,那么一次性 decommission 多个 DN 耗时会更多,少量多次更稳妥)
3.取消 decommission 时,只处理处于 Decommission In Progress和 Decommissioned 状态的节点,其他状态的节点不处理(直接 skip)
4.dead 节点,会直接变更状态为 decommissioned,因此很快
5.非 dead 的节点,要做全量的 block 副本检测,block 多的节点,耗时会增加
6.liveReplicas 是指非 corrupt,非 excess,非 decommissioned 的节点(实际副本数不会变化,因为 node 处于 decommission 状态,所以 liveReplicas 会比期望副本数小,触发后面的「副本检测线程」执行块的复制)
7.blk 会根据 liveReplicas 副本节点情况,划分优先级
8.每次最大的复制量:blocksToProcess = live datanode * dfs.namenode.replication.work.multiplier.per.iteration (默认值 2)
随着 decommission 机器的释放, live DN 会变少,每轮最大的复制量 blocksToProcess 会随之变小,decommission 的速度会下降,此时可以适当上调 dfs.namenode.replication.work.multiplier.per.iteration 参数,增加每次的最大复制量9.UC 状态的块不处理,会直接从 neededReplications 中移除 。如果因为租约未释放的情况导致某些 blk 一直处于 UC 状态导致一直无法被复制,进而导致 decommission 卡住,无法到达 decommissioned 状态
10.block 会在 neededReplications 和 pendingReplications 之间流转(有过期时间)
11.decommission 状态的节点不会作为 targetNodes 节点,新的写请求,不会落到 decommission 节点(可读,不会新写)
12.如果节点上的 blk 较多,那么检测节点上的 block 是否达到目标副本数的过长是比较耗时的
13.dfs.namenode.decommission.interval 每次检测的时间间隔(如果一个节点未达到目标副本数的 blk 比较多,decommission 的时间会比较长,不需要过于频繁的检测)
14.dfs.namenode.decommission.nodes.per.interval 每次检测的节点个数(如果每轮检测的节点很多,那么持有 namesystem 写锁的时间会随之变长,delay 其他请求的响应)
踩的一些坑
1.取消 DN decommission 后,残留大量剩余复制块
处于复制状态的 blks 正常情况是 0

FIX:
重启 DN 或 引入 HDFS-9685
2.一次性 decommission 多个 DN 可能触发 zkfc 切主
分析:
执行 dfsadmin -refreshNodes 后,NN 会对所有将要 decommision 的 DN 上的全量 blocks 做副本数检测,如果一次性 decommission 的 DN 数较多,这个检测时间会随之变长。 如果在这个期间正在执行 HA 健康检测(ha.health-monitor.check-interval.ms 控制频率,默认值 1s),可能会导致 RPC 请求超时(ha.health-monitor.rpc-timeout.ms 设置超时时间,默认值是 45s),导致误以为 NN 不健康,而切主。
FIX:
1. 适当上调 HA 健康检测超时时间 ( ha.health-monitor.rpc-timeout.ms 参数)
2. 执行 decommission 时,少量多次执行 refresh,每次间隔一段时间观察 namende rpc 指标的变化情况
3.decommission 调优
取块 和 transfer 相关数量
dfs.namenode.replication.work.multiplier.per.iteration dfs.namenode.replication.max-streams
检测是否完成的相关参数:
dfs.namenode.decommission.interval dfs.namenode.decommission.nodes.per.interval
4.DN 一直卡在 Decommissioning 状态,无法到达 Decommissioned 状态
分析:
造成这个问题的原因是个别文件的租约未释放,blk 处于 UC 状态,而该状态的块 decommission 不会去处理,直接 skip,因此导致一直卡在 Decommissioning 状态。排查:
1.前面分析 refresh 逻辑的 checkDecommissionState 方法的时候,有这样一步
2.排查 NN 日志,找到 blkId
3.根据 blkId 找到对应的文件
4.分析文件状态
5.最终定位到是 Flume 落 HDFS 的个别文件存在租约问题
FIX:
执行租约释放,卡住的 Decommissioning DN 达到了Decommissioned 状态
其他
1.因为 blk 是按照优先级从高到低处理的。可以考虑让 blk 变为高优先级。
2.按 DN 顺序检查,然后放入优先级队列,有可能出现同个优先级下,同一个 DN 的 blks 集中,不均匀。
