

一 概述
1.1 基础命令
MySQL分为服务端和客户端,服务端和客户端分别对应一个进程,通常服务端进程的默认名称为mysqld,客户端的进程名为mysql
# 首先将mysql注册为windows服务 "C:\Program Files\MySQL\MySQL Server 5.7\bin\mysqld" --install # 开启mysql服务端 net start mysql # 关闭mysql服务器 net stop mysql # 连接mysql服务器,连接本机时可省略主机地址 mysql -hlocalhost -uroot -p1234 # 退出mysql服务器 exit quit \q
服务端处理客户端请求
mysql服务端与客户端支持TCP/IP、命名管道、共享内存、Unix套接字文件等进程间通信方式
-
连接管理
-
解析与优化
-
存储引擎
# 查看支持的引擎 mysql> show engines; +--------------------+---------+----------------------------------------------------------------+--------------+------+------------+ | Engine | Support | Comment | Transactions | XA | Savepoints | +--------------------+---------+----------------------------------------------------------------+--------------+------+------------+ | InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES | | MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO | | MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO | | BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO | | MyISAM | YES | MyISAM storage engine | NO | NO | NO | | CSV | YES | CSV storage engine | NO | NO | NO | | ARCHIVE | YES | Archive storage engine | NO | NO | NO | | PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO | | FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL | +--------------------+---------+----------------------------------------------------------------+--------------+------+------------+ 9 rows in set (0.00 sec)
1.2 启动项设置
常用的启动项
长命令需要用“–”前缀并且值与命令中间有空格,短命令只有“-”前缀与值没有空格(也可以加空格),注意短命令区分大小写
长命令形式
短命令形式
含义
–host
-h
主机名
–user
-u
用户名
–password
-p
密码
–port
-P
端口
–version
-v
版本信息
系统变量
mysql内部定义了众多内部变量,在服务器启动时默认加载这些变量,如
-
max_connections 最大的并发客户端数
-
default_storage_engine 默认的存储引擎
-
query_cache_size 查询缓存的大小
为了支持客户端的定制化操作,mysql服务端将系统变量的范围设置为Global和Session两个作用范围
# 查询出的结果默认是Session作用范围的系统变量 show variables like 'default_storage_engine';
状态变量
为了更好地监控和观察mysql的运行状态,mysql提供了一些常用的状态变量来描述服务器的内部行为和运行状态
-
Threads_connected 当前连接了多少客户端
-
Handler_update 已经更新了多少行数据
mysql> show status like 'thread%'; +-------------------+-------+ | Variable_name | Value | +-------------------+-------+ | Threads_cached | 6 | | Threads_connected | 4 | | Threads_created | 10 | | Threads_running | 1 | +-------------------+-------+ 4 rows in set (0.00 sec)
1.3 字符集和比较规则
编码-将一个字符映射成一个二进制数据的过程
解码-将一个二进制数据映射到一个字符的过程
1.3.1 常见的字符集
-
ASCII字符集
共收录128个字符,包括空格、标点符号、数据、大小写字母等,采用一个字节俩编码
-
GB2312字符集
收录了汉字、拉丁字母、希腊字母、日本平假字、俄语字母等,其中收录汉字6763个,其他文字符号682个。如果该字符在ASCII中,采用一字节编码,否则采用二字节编码
-
GBK字符集
对GB2312字符集的扩充,编码方式上兼容GB2312
-
UTF8字符集
俗称万国集,形式上兼容ASCII,采用变长编码方式,一个汉字需要1~4个字节
1.3.2 MySQL字符集和比较规则
MySQL中特殊处理了字符集,保留了两种UTF8编码格式
-
utf8mb3 阉割过的uft8字符集,使用1~3个字节表示字符,也就是平时所用的utf8字符集
-
utf8mb4 真正的uft8字符集,使用1~4个字节表示字符,
可以存储表情
查看MySQL中支持的字符集
# 查询支持的字符集 show charst; # 查询支持的比较规则 mysql> show collation like 'utf8\_%'; +--------------------------+---------+-----+---------+----------+---------+ | Collation | Charset | Id | Default | Compiled | Sortlen | +--------------------------+---------+-----+---------+----------+---------+ | utf8_general_ci | utf8 | 33 | Yes | Yes | 1 | | utf8_bin | utf8 | 83 | | Yes | 1 | | utf8_unicode_ci | utf8 | 192 | | Yes | 8 | | utf8_icelandic_ci | utf8 | 193 | | Yes | 8 | | utf8_latvian_ci | utf8 | 194 | | Yes | 8 | | utf8_romanian_ci | utf8 | 195 | | Yes | 8 | | utf8_slovenian_ci | utf8 | 196 | | Yes | 8 | | utf8_polish_ci | utf8 | 197 | | Yes | 8 | | utf8_estonian_ci | utf8 | 198 | | Yes | 8 | | utf8_spanish_ci | utf8 | 199 | | Yes | 8 | | utf8_swedish_ci | utf8 | 200 | | Yes | 8 | | utf8_turkish_ci | utf8 | 201 | | Yes | 8 | | utf8_czech_ci | utf8 | 202 | | Yes | 8 | | utf8_danish_ci | utf8 | 203 | | Yes | 8 | | utf8_lithuanian_ci | utf8 | 204 | | Yes | 8 | | utf8_slovak_ci | utf8 | 205 | | Yes | 8 | | utf8_spanish2_ci | utf8 | 206 | | Yes | 8 | | utf8_roman_ci | utf8 | 207 | | Yes | 8 | | utf8_persian_ci | utf8 | 208 | | Yes | 8 | | utf8_esperanto_ci | utf8 | 209 | | Yes | 8 | | utf8_hungarian_ci | utf8 | 210 | | Yes | 8 | | utf8_sinhala_ci | utf8 | 211 | | Yes | 8 | | utf8_german2_ci | utf8 | 212 | | Yes | 8 | | utf8_croatian_ci | utf8 | 213 | | Yes | 8 | | utf8_unicode_520_ci | utf8 | 214 | | Yes | 8 | | utf8_vietnamese_ci | utf8 | 215 | | Yes | 8 | | utf8_general_mysql500_ci | utf8 | 223 | | Yes | 1 | +--------------------------+---------+-----+---------+----------+---------+ 27 rows in set (0.07 sec)
后缀
英文释义
描述
_ai
accent insensitive
不区分重音
_as
accent sensitive
区分重音
_ci
case insensitive
不区分大小写
_cs
case sensitive
区分大小写
_bin
binary
以二进制形式比较
-
服务器级别
# 服务器级别的字符集 mysql> show variables like 'character_set_server'; +----------------------+-------+ | Variable_name | Value | +----------------------+-------+ | character_set_server | utf8 | +----------------------+-------+ 1 row in set (0.07 sec) # 服务器级别的比较规则 mysql> show variables like 'collation_server'; +------------------+-----------------+ | Variable_name | Value | +------------------+-----------------+ | collation_server | utf8_general_ci | +------------------+-----------------+ 1 row in set (0.06 sec) 如果想更改服务器级别的编码集和比较规则,需在配置文件中指定:
[server] character_set_server=gbk collation_server=gbk_chinese_ci -
数据库级别
# 创建数据库scheme时指定默认编码集和比较规则 create database demo_db character set GBK collate set gbk_chinese_ci # 服数据库级别的字符集 mysql> show variables like 'character_set_database'; +------------------------+---------+ | Variable_name | Value | +------------------------+---------+ | character_set_database | utf8mb4 | +------------------------+---------+ 1 row in set (0.05 sec) # 数据库级别的字符集 mysql> show variables like 'collation_database'; +--------------------+-------------+ | Variable_name | Value | +--------------------+-------------+ | collation_database | utf8mb4_bin | +--------------------+-------------+ 1 row in set (0.05 sec)在创建数据库Scheme时指定默认编码集和比较规则后,后面这两个参数为只读,无法更改
-
表级别
# 在创建表的时指定编码集和比较规则 CREATE TABLE `orders` ( `order_num` int(11) NOT NULL AUTO_INCREMENT, `my_name1` char(1) COLLATE utf8_bin NOT NULL, `order_date` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP, `cust_id1` int(11) NOT NULL, PRIMARY KEY (`order_num`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=20010 DEFAULT CHARSET=utf8 COLLATE=utf8_bin ROW_FORMAT=DYNAMIC; # 如果没有指定,则向上继承数据库级别的编码集和比较规则 -
列级别
对于存储字符串的列,同一张表中的不同列可以设置不同的编码集和比较规则
alter table test modify name varchar(10) character set gbk collate gbk_chinese_ci; -
小结
由于字符集与比较规则紧密相连,如果我们仅修改了字符集,比较规则也会随之改变,反之亦然。
-
如果创建或修改列时没有显示指定字符集和比较规则,则该列默认使用表的字符集和比较规则
-
如果创建表时没有显示指定字符集和比较规则,则该表默认使用数据库的字符集和比较规则
-
如果创建库时没有显示指定字符集和比较规则,则该数据库默认使用服务器的字符集和比较规则
二 核心原理
2.1 InnoDB存储页
MySQL服务器上负责对表中数据进行读取和写入工作的部分是存储引擎,而服务器又支持不同的存储引擎,如InnoDB、MyISAM、Memory等,MySQL5.7后默认的存储引擎为InnoDB。InnoDB存储数据的策略是:将数据分为若干个页,以页作为 磁盘和内存之间交互的最小单位,其中一页的大小一般为
16Kb
。通常情况下,我们是以记录为单位向表中插入数据的,这些记录在磁盘上的存储方式也被称为
行格式
,InnoDB存储引擎定义了四种不同的行格式以适应不同的应用场景-Compact、Redundant、Dynamic、Compressed。因为InnoDB默认是Dynamic行格式,我们着重分析此种行格式的存储格式。
从上图可看出,一条完整的记录被分为记录的额外信息和记录的真实数据两部分,
变长字段长度列表+ NULL值列表+记录头信息 => 额外信息
每个字段的具体值 => 记录的真实数据
mysql> SELECT * FROM record_format_demo; +------+-----+------+------+ | c1 | c2 | c3 | c4 | +------+-----+------+------+ | aaaa | bbb | cc | d | | eeee | fff | NULL | NULL | +------+-----+------+------+ 2 rows in set (0.00 sec)
变长字段类表
mysql中支持各种变长字段的存储类型,如varchar(M),varbinary(M),text,blob等,这些数据类型存储的真实数据长度是不定的,mysql使用
真正的数据内容
和
占用的字节数
管理这些数据。
第一行数据存储格式
格式说明
-
W 字符集中表示一个字符最多使用的字节数,utf8为3,gbk为2,ascii为1
-
M 规定字段类型最多能够存储的
字符数
,字节数为W*M,varchar(8)表示该字段类型最多支持保存8个字符
-
L 该字段实际存储的数据长度
如果W*M <= 255 使用一个字节俩表示真正字符串占用的字节数
如果W*M > 255 && L <= 127 ,使用一个字节来表示真正的字符串占用的字节数
如果W*M > 255 && L > 127 ,使用两个个字节来表示真正的字符串占用的字节数
NULL值列表
mysql支持某些列值为null,当某个类值允许存储null值时,该字段对应的标志位置1,不够整数位时补0对齐。
记录头信息
记录头信息存储了该记录是否被删除、非叶子节点标志、当前记录数、记录类型、下条记录指针等
名称
大小(bit)
描述
预留位1
1
没有使用
预留位2
1
没有使用
delete_mask
1
标记该记录是否被删除
min_rec_mask
1
B+树每层非叶子节点的最小记录标记
n_owned
4
该Slot(槽)拥有的记录数
heap_no
13
当前记录的堆位置信息
record_type
3
当前记录类型,0-普通记录,1-B+数非叶子节点记录,2-最小记录,3-最大记录
next_record
16
下一条数据的相对位置
记录的真实数据
mysql除了保存真实的数据外,还会给每条记录增加默认列(隐藏列)
列名
是否必须
占用空间(bit)
描述
row_id
否
6
行ID,唯一标识一条记录
transaction_id
是
6
事务ID
roll_pointer
是
7
回滚指针
mysql的主键生成策略
优先使用用户自定义主键,如果没有指定,则使用表的唯一键,否则会内部自动生成一个唯一键
行溢出数据
varchar(M)类型的字段最多可以占用65535(64kb)
-
字符集为ASCII,最多存储(65535) 64kb
-
字符集为GBK,最多处处(65535/2) 32kb
-
字符集为UTF8,最多存储(65535/3) 21kb
MySQL是以页为单位管理存储空间,且一个页的大小通常为16kb,varchar(M)类型的字段最多可以存储64kb,就会出现一个页无法存储一条记录的场景。Compact和Redundant会存储768字节的真是数据和剩余数据的页指针(溢出页),而Dynamic则不会保存部分数据,直接存储溢出页的指针
小结
2.2 InnoDB数据页
数据页(索引页)代表这16KB大小大的存储空间被分成的不同部分
名称
中文名称
占用空间(字节)
描述
File Header
文件头部
38
页的一些通用信息
Page Header
页面头部
56
数据页专有的一些信息
Infimum + Supremum
最小记录和最大记录
26
两个虚拟的行记录
User Records
用户记录
不确定
实际存储的数据
Free Records
空心空间
不确定
页中剩余的可用空间
Page Directoty
页面目录
不确定
页中某些记录的相对位置
File Trailer
文件尾部
8
检验页是否完整
首先定义一张Demo表
mysql> CREATE TABLE page_demo( -> c1 INT, -> c2 INT, -> c3 VARCHAR(10000), -> PRIMARY KEY (c1) -> ) CHARSET=ascii ROW_FORMAT=Compact; Query OK, 0 rows affected (0.03 sec)
User Records
一开始并没有User Records部分,每当我们插入一条数据,都会从Free Space中申请一个记录大小的空间划分到User Records中
Record Type
record_type表示该条记录的类型,0表示普通记录,1表示B+数非叶子节点记录,2表示最小记录,3表示最大记录。next_record表示从当前记录的真实数据到下一条真实数据的地址偏移量。此处的下一条数据并不是我们插入的顺序,而是按照主键值排序后的顺序。并且规定最小记录的下一条记录就是此页中的主键值最小的用户记录,本页中主键值最大的用户记录的下一条记录为Supremum记录
Page Header
页目录,内部维护了多个Slot,用于加速检索效率。
页目录中有两个槽,slot0和slot1,数字代表该槽中最大记录的偏移量,n_owned表示该槽中有多少条数据(包括最小记录和最大记录)。
规律:
-
初始情况下,一个数据页中只有最小记录和最大记录,它们属于两个分组
-
每插入一条记录,都会从页目录中找到主键值比本记录主键值的并且差值最小的槽,然后把该槽的n_owned+1,直到本组中的记录数等于8
-
当本组中的数据大于8时,会将组中的数据分拆成两个组,一个组4条,另一个组5条,同时会新增一个槽来存储插入的数据。
检索数据时,使用二分法找到对应的槽,确定该槽中主键值最小的那条记录,然后通过记录的next_record属性遍历该槽所在的分组数据。
Page Header
Page Header保存了一个数据页中存储的记录的状态信息,比如本页中已经存储了多少条记录,第一条记录的地址,页目录中的槽数。
FIle Header
上述的PageHeader是专门针对数据页记录的各种状态。File Header针对各种类型的页都通用,
名称
占用空间(字节)
描述
FIL_PAGE_SPACE_OR_CHKSUM
4
页的校验和
FIL_PAGE_OFFSET
4
页号
FIL_PAGE_REEV
4
上一个页号
FIL_PAGE_NEXT
4
下一个页号
FIL_PAGE_LSN
8
最后一次修改时的日志序列位置(LSN)
FIL_PAGE_TYPE
2
该页的类型
FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID
4
页属于哪个表空间
2.3 B+树索引
2.3.1 索引
-
record_type 0-普通记录 1-目录项记录 2-最小记录 3-最大记录
-
next_record 表示下一条地址相对于本条记录的地址偏移量
-
各个列的值
-
其他信息,包含隐藏列等
-
目录项记录的record_type=1
-
目录项记录只有主键值和页的编号两个列,数据记录则有用户定义的所有列
假如表中有大量数据,则目录项记录会继续分裂形成新的节点,最下面一层称为第0层,通常情况下B+树的层次不会超过4,通过主键值查询记录时,最多只需查询4个目录(三个目录项和一个用户记录页)。
2.3.2 聚簇索引
MySQL会自动根据主键值创建一个聚簇索引,有以下几个特点
-
页内的记录是按照主键的大小顺序排成一个单项链表
-
各个存放用户记录的页也是根据记录的主键大小排成一个双向链表
-
存放目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的主键大小顺序排成一个双向链表
-
最下面一层存的是用户的完整记录
2.3.3 二级索引
如果根据非主键的列生成一个B+树,有以下特点
-
业内的记录时按照C2列的大小顺序排成一个单项列表
-
各个存放用户记录的页也是根据C2列大小顺序排成衣蛾双向链表
-
存放目录项记录的页分为不同的层次,在同一层次中的页也是根据野种目录项记录的C2列大小顺序排成一个双向链表
-
最下层的叶子节点存储的是
C2+主键
,而不是
主键+页号
为了保证B+树同一层的目录项记录除页号唯一条件,二级索引的目录项记录中额外存储了主键值,所以实际上二级索引的内节点目录项记录实际存储了三部分:
索引列+主键值+页号
2.3.4 联合索引
可以同时为多个列创建索引,比如说根据C2和C3列创建索引,有以下特点:
-
先把各个记录和页按照C2列进行排序
-
在记录的C2列相同情况下,再根据C3列排序
-
每条目录项记录都由C2+C3+页号三部分组成,首选按照C2排序然后根据C3排序
-
B+树的叶子节点的用户记录由C2、C3和主键C1组成
-
本质上也是一个二级索引
2.3.5 创建索引语句
-- 创建索引
alter table test add index idx_name (name);
-- 删除索引
alter table test drop index idx_name;
-- 创建索引规范
-- 主键索引必须使用pk开始
alter table test add pk_name (name) comment '索引说明';
-- 普通索引必须以idx开始
alter table test add idx_name (name) comment '索引说明';
-- 唯一索引必须使用uk开始
alter table test add uk_name (name) comment '索引说明';
2.4 B+树索引的应用
2.4.1 索引代价
建立索引一方面极大地提高了数据的查询速度,另一方面也给数据库的增、删、改以及磁盘空间带来了压力
-
空间上的代价
每建立一个索引都会创建一颗B+树,每个节点都是16kB的空间,如果数据量很大索引也会占用很大的空间
-
时间上的代价
每次对数据的增、删、改都会修改B+树,这些操作可能破坏原有的顺序结构,可能会触发页的分裂、数据移位、页面回收等操作,从而影响性能
CREATE TABLE person_info( id INT NOT NULL auto_increment, name VARCHAR(100) NOT NULL, birthday DATE NOT NULL, phone_number CHAR(11) NOT NULL, country varchar(100) NOT NULL, PRIMARY KEY (id), KEY idx_name_birthday_phone_number (name, birthday, phone_number) );
如上图所示,创建一张person_info表,同时创建了联合索引
idx_name_birthday_phone_number
-
首先按照name排序
-
name列相同按照birthday排序
-
birthday列相同按照phone_number排序
idx_name_birthday_phone_number (name, birthday, phone_number) -- 此语句可以使用索引,条件中的列都是联合索引中的且顺序保持一致 -- 对于精确查询的情况,查询条件的列可以互换,mysql会自动优化 select * from person_info where name = 'alice' and birthday='1993-06-20' and phone_number = 15005187966; select * from person_info where phone_number = 15005187966 and name = 'alice' and birthday='1993-06-20';
-- 匹配最左的列 -- 可以用到name索引 SELECT * FROM person_info WHERE name = 'Ashburn'; -- 可以使用(name,birthday)索引 SELECT * FROM person_info WHERE name = 'Ashburn' AND birthday = '1990-09-27'; -- 可以使用(name,birthday,phone_number)索引 select * from person_info where name = 'alice' and birthday='1993-06-20' and phone_number = 15005187966; -- 可以使用name索引 SELECT * FROM person_info WHERE name = 'Ashburn' AND phone_number = '15123983239'; -- 可以使用name索引 SELECT * FROM person_info WHERE name LIKE 'As%'; -- 可以使用name索引 SELECT * FROM person_info WHERE name > 'Asa' AND name < 'Barlow'; -- 只能使用奥name索引 SELECT * FROM person_info WHERE name > 'Asa' AND name < 'Barlow' AND birthday > '1980-01-01'; -- 可以使用(name,birthday)索引 SELECT * FROM person_info WHERE name = 'Ashburn' AND birthday > '1980-01-01' AND birthday < '2000-12-31' AND phone_number > '15100000000'; -- 可以使用(name,birthday,phone_number)索引 SELECT * FROM person_info ORDER BY name, birthday, phone_number LIMIT 10;
2.4.2 索引失效情况
-
排序列中DESC、ASC混用
SELECT * FROM person_info ORDER BY name, birthday DESC LIMIT 10; -
查询条件使用了函数
SELECT * FROM person_info WHERE upper(name) = 'Ashburn'; -
查询条件使用了全模糊
SELECT * FROM person_info WHERE name like '%Ashburn%'; -
查询条件中有or
SELECT * FROM person_info WHERE name = 'Ashburn' or birthday = '1990-09-27'; -
查询条件中null 值匹配条件
SELECT * FROM person_info WHERE name is null; -
数据库的编码和字段编码不一致也会导致无法使用索引
这种情况不好排查,工作中遇到过
-
字符型字段没有带引号,数据库会自动转换成数值型导致无法走索引(数据类型不统一)
SELECT * FROM person_info WHERE name = 123;
2.4.3 建立索引原则
-
只为用户查询、排序或者分组的字段创建索引
-
为字段区分度高的字段建立索引
-
索引列的类型尽量小,如果可能的话考虑为字符型字段建立前缀索引
-
尽量使用覆盖索引,避免回标性能损耗
-
尽可能建立联合索引,减少索引数量,降低增、删、改时的性能损耗
-
创建表时尽量加上
id int primary key not null auto_increment,减少数据变更时的页分裂、数据移位几率
2.5 MySQL数据目录
2.5.1 MySQL数据文件
查看MySQL的数据目录:
mysql> show variables like 'datadir';
+---------------+---------------------------------------------+
| Variable_name | Value |
+---------------+---------------------------------------------+
| datadir | C:\ProgramData\MySQL\MySQL Server 5.7\Data\ |
+---------------+---------------------------------------------+
1 row in set (0.06 sec)
MySQL会在数据目录中为每个数据库创建一个目录,然后在里面存储相关的表,每张表都有.frm和.idb两个文件组成
2.5.2 InnoDB表空间
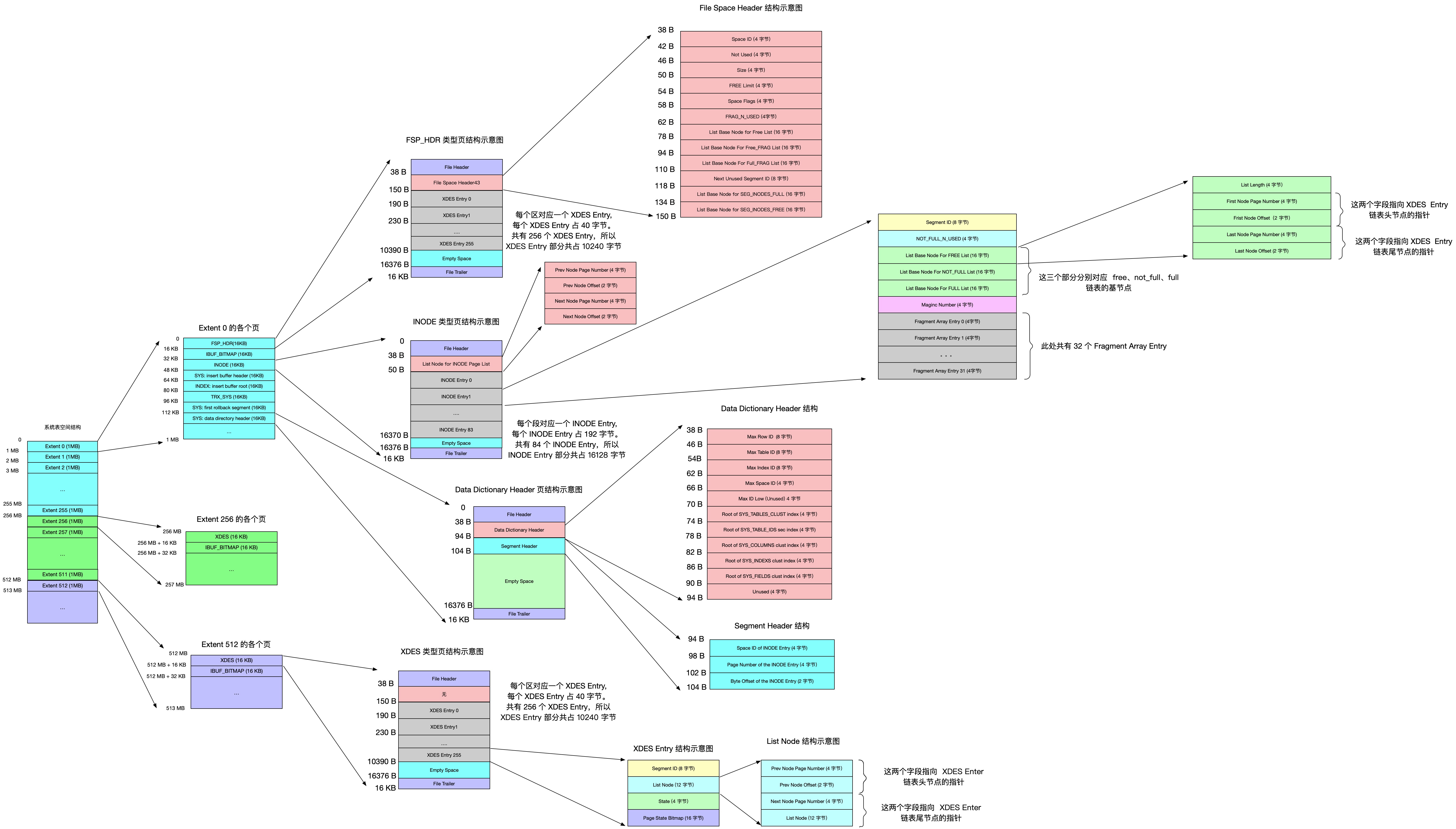
-
表空间被划分为许多连续的extend区(1M),每个区默认有64个页组成,每256个区又分为一组(256M)
-
一个索引会生成两个段,叶子节点段和非叶子节点段
-
mysql默认的information_schema中保存了各个表的详情信息
