

客户端从服务器获取到需要渲染页面的代码后,【开辟一个GUI渲染线程,自上而下解析代码,最后绘制出对相应的页面】
自上而下渲染代码的过程是同步,但是有些操作也是异步的
css资源加载,
1.遇见style标签,内联样式,同步的交给GUI渲染线程,
2.遇见link标签外联样式;异步的开辟一个http网络请求线程,不等待资源请求回来,GUI渲染线程继续向下渲染,CUI渲染线程同步操作完成之后,早把基于http请求的回来的网络资源进行解析;
3.遇见@import 导入样式; 同步开辟一个新的http网络请求线程,去请求资源文件,但是资源文件没请求hi来之前,GUI线程会被阻塞,不允许其向下渲染
浏览器同源下最多只允许开辟4-7个http 线程;
js资源的加载;
1.通过script资源请求 默认是同步的,必须基于http网络线程,请求回来之后并且交给js渲染线程,当js渲染线程完成后,GUI渲染线程才能继续向下渲染。所以script标签是默认阻塞GUI的渲染的,
2.script async首先会开辟一个http网络线程去加载资源文件,同时GUI渲染线程会继续渲染(默认把GUI线程的同步改为异步),但是js资源请求回来之后,会中断GUI线程的渲染,先把请求回来的js 进行渲染解析;之后在继续进行GUI线程渲染。
3 script defer 和 async 类似,都是开辟新的http网络请求去加载资源文件,同时GUI渲染线程修改为异步;但不一样得地方就是defer和link 类似,是等待GUI渲染线程完成后才会渲染解析请求回来的JS代码。
遇见img 标签或者音频,视频
遇见这些资源,也会发送http网络线程,请求加载对应得资源文件,不回阻碍GUI得渲染【异步】,当GUI渲染线程完成后,才会把请求回来得资源信息进行渲染解析;
webkit 浏览器预解析;chrome的预加载扫描器html-preload-scanner通过扫描节点的src link等属性,找到外部的资源进行预加载,避免了资源长时间等待,避免了资源加载的等待时间,同时实现了提前加载以及加载和执行分离
页面渲染的步骤:
1.生成DOM树自上而下渲染完页面,整理好整个页面的DOM结构关系,
2.CSSOM 树,当我所有的样式资源加载回来之后,按照引入css的顺序,依次渲染样式代码生成样式树
3.生成渲染树:把生成的DOM树和CSSOM树何合在一起生成渲染树(设置的display:none属性不进行处理)
4.Layout:布局回流重排;根基生成的渲染树,计算他们在设备视口(viewport)内的位置和大小;
5.分层处理,按照层级定位分层处理,每一层级都有有详细规划具体的绘制步骤, 6. Painting:根据每一个层级计算处理绘制步骤,开始绘制页面。
根据页面底层的渲染机制进行性能优化;
生成dom树时进行优化;
1减少不必要的层级嵌套,2 不使用非标准的标签, 生成cssom 树时进行优化 1尽量不使用import,(阻塞GUI渲染线程的渲染),2.如果css 样式少可以直接使用内联样式,3。如果使用link 尽可能的把所有资源合并成一个 并压缩(减少http的请求数量,渲染css 时候不用计算依赖关系了)4.css选择器短一点(因为css渲染器是从右到左的) 4.把link 放在css样式的head中,(目的:一加载页面就开始请求资源,同时GUI线程生成DOM树,css等资源预加载) 对于js 资源的优化; 1.script 标签尽可能的放在页面的底部(防止GUI线程的渲染);对于部分的script标签使用async或者defer;2.async 是不管js依赖关系的,哪一个资源先获取到,就先把这个资源下的戴拿渲染执行;3.defer 和link是一样得,等待所有的defer 请求回来之后,按照导入顺序,依赖关系渲染执行的; 对于img 1.懒加载,第一次加载页面的时候不要请求加载图片资源,哪怕是异步的但是也占用Http的并发数量,导致其资源延后加载。2.图片加载用BASE64不去直接加载图片,而且渲染加载图片的时候速度也会变快,(慎用:但是在webpack 工程化的项目可以使用,因为它是基于file-loader可以自动转化BASE64d的)
DOM的回流和重绘;
DOM的重绘:元素的样式改变但是宽高,位置,大小等不变; DOM的回流:元素的大小或位置发生变化(当页面布局,和几何信息发生变化的时候),触发从新布局,导致渲染树重新计算布局或者渲染;如:删除DOM元素,元素位置发生变化,元素尺寸发生变化;元素内容发生变化(比如文本变化,图片被另一个不同尺寸的图片所代替);页面一开始渲染的时候(这个不可以避免);因为回流是根据视口的大小和元素的位置和大小的,所以浏览器的窗口尺寸变化也会引起回流
回流必定重绘,而重绘不一定回流
性能点的优化重点在回流上;
当代浏览器的渲染队列机制;
当上下文操作中,遇到一行修改样式的代码,并没有立即通知浏览器渲染,而是把它放置在渲染队列中,接下来看下面是否还有修改样式的代码,如果有继续修改样式的代码就放在队列中..一直等到没有在修改样式的代码或者“获取遇见一行获取样式的操作”,这样都会刷新浏览器的渲染队列机制(也就是把现在队列中修改样式的操作,统一告诉浏览器,这样只会引起一次回流。)看以下代码:
box.style.wdith="100px"
box.style.height="200px"
box.style.position="absolute"
box.style.top="100px"
以上代码只会引起一次回流
box.style.wdith="100px"
box.style.height="200px"
box.offsetHeight // 所有获取样式的操作都会重新刷新渲染队列
box.style.top="100px"
所以以上代码会引起两次回流
如何避免多次回流优化方法
1.分离读写,把修改样式的代码和获取样式的代码分开写
增加类名一次修改
修改样式时尽量不做获取样式的操作
2 往页面里添加DOM 引发的回流
模板字符串处理的缺陷,因为当了字符串处理,所以绑定的事件就全部丢失了,
用文档碎片处理只引发一次回流;
布局前分层 分层的特点:只把当前的层面进行从新渲染。
有些功能的实现需要故意增加回流操作,只需要在中间获取一次样式。
http网络层性能优化;
产品性能优化方案: 1.http网络层性能优化 2.代码编译层性能优化 webpack, 3. 代码运行层性能优化 4.安全优化 xss+csrf 5.数据埋点及性能监控,
从输入一个url到到显示页面经历的过程
第一步url解析:
协议:分为http超文本传输协议,https 安全ssl加密【产品涉及支付】,ftp 文件上传下载(例如本地代码上传到服务器)
客户端 服务器的数据通信,传输协议就是负责运送这些信息的
域名:
顶级域名:qq.com
一级域名:www.qqq.com
二级域名:sports.qq.com
三级域名: kbs.sports.qq.com
端口号
端口号:是用来区分服务器上不同的服务(不同的服务其实简单理解就是一个项目)
端口号在0-65535之间
url加密方式:
加密方式:最经常用的是encodeURL和encodeURLCompoment
对url编码是常见的事情,所以这两个方法应该是实际中特别注意的,他们都是编码url的唯一的区别就是编码的字符范围,其中encodeURL方法不回对下列字符编码SCII字母、数字、!@#$&*()=:/,;?+',!*()'所以encodeURLCompoment比encodeURL的编码范围更大
encodeURIComponent方法不会对下列字符编码 ASCII字母、数字、
实列说明:encodeURIComponent会把 http:// 编码成 http%3A%2F%2F 而encodeURI却不会。
url 编码的使用场景
1.如果只是编码字符串,不和url有任何关系,那么用escape.
2.如果你需要编码整个url然后使用这个url,那么用encodeURL。
比如
encodeURI("http://www.cnblogs.com/season-huang/some other thing");
// 编码后会变为
"http://www.cnblogs.com/season-huang/some%20other%20thing";
// 其中空格被编码成%20,但是如果你用了encodeURLComponent,那么结果变为
"http%3A%2F%2Fwww.cnblogs.com%2Fseason-huang%2Fsome%20other%20thing"
// 看到区别没有连/都被编码了,整个URL已经没法用了;
3.当你需要编码url中的参数时,那么encodeURLCompoment的最好方法,
看到了把,把参数的"/"可以编码,如果用encodeURL肯定用出问题,因为后面的/是需要编码的。
第二部缓存检查
缓存位置
Menory Cache:内存缓存
Disk Cache:硬盘缓存 打开网页:查找 dis Cache 中是否有缓存,如果有则使用,如果没有则发送网络请求 普通刷新(F5):因为TAB没有关闭,因为memory cache 是可用的,会被优先使用,其次才是disk cache
强制刷新(Ctrl +F5):浏览器不使用缓存,因此发送的请求头部均带有Cache-control:no-cache,服务器直接返回200,和最新内容
强缓存和协商缓存
强缓存:Expires / Cache-Control
1.浏览器对于清缓存的处理;根据第一次请求资源时返回的响应头来确定的
Expires:缓存的过期时间,用来指定资源的到期时间(HTTP/1.0)
Cache-Control:Cache-control:max-age=2592000第一次拿到资源后的25920000秒内,再次发送,读取请求中的信息;
以上两者同时存在,Cache-Control 优先级高于Expires
强缓存和协商缓存是服务器设置的Expries,和Cache-Contor,本地没有缓存就从服务器上拿,本地有缓存和服务器就没关系了,
缓存注意点:html页面一般不设置强缓存【防止服务器端更新文件后,客户端获取的还是本地缓存的页面,这样页面不能及时更新】 项目中会做这样的处理:如果服务器会有更新首先页面会更新。1.在每一次有更新css和js 等,我们在请求css js的后面设置一个时间戳。2.基于webpack 只要资源文件有更新就生成不同的hash值。根据不同的hash 值更新资源。只有强缓存失效时,协商缓存才进行。html可以用协商缓存;
协商缓存
协商缓存 last-Mdified /ETag
协商缓存就是强缓存失效后,浏览器携带缓存标识向服务器发起请求,由服务器根据缓存决定是否使用缓存的过程
vuex 和redux 相当于全局变量 存在页面的栈内存中,强缓存和协商缓存前端都不需要做,服务端做。
第三步DNS解析
通过域名和外网ip找到服务器,找服务器需要经过DNS 解析。购买域名后,我们需要在域名解析,域名外网ip 注册到DNS 服务器上
如何减少DNS解析次数
1.第一请求本地没有DNS缓存,需要一个完整的DNS 解析时间到20-120毫秒
2.第二次 基本上直接启用第一次DNS解析的缓存记录即可。
3.减少DNS请求次数,一个项目中,仅可能只访问相同的服务器,不要访问过多的服务器和域名(但是项目中为了做更好优化,往往服务器会很多,做服务器集训)
服务器拆分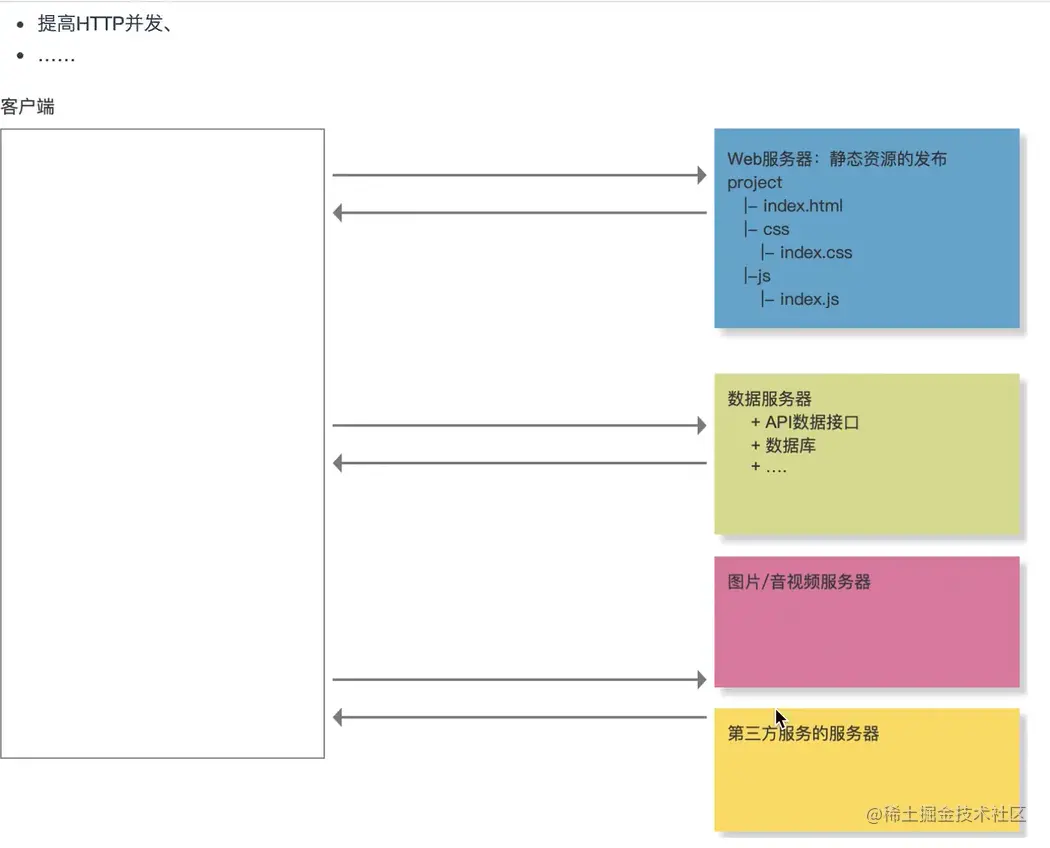
1.资源合理利用
2. 抗压能力强
3. 提高http并发数量
DNS预获取技术
第一次DNS解析时间预计在20-120毫秒 ,减少DNS请求次数,用DNS预获取(DNS Prefetch)
TCP三次握手
1.seq 序号,用来标识从TCP源端向目的端发送的字节流,发送方发起时,对此标记
2.ack 确认序号,只有ACK标记为1时,确认序号字段才有效,ack =seq +1
标志位
ACK:确认序号有效 RST 重置链接 ,SYN :发起一个新连接, FIN:释放一个连接
除了TCP连接,还有udp链接;
UDP连接的特点:快速不稳定,不是很安全。消息视频流可以用UDP
三次握手为什么不用两次,或者四次?
TCP 作为一种可靠的传输控制协议,其核心思想是即要保证数据的可传输性,又要提高传输效率!
第五步数据传输
第六步TCP四次挥手
为什么握手三次挥手是四次
1.服务器端收到客户端的SYN链接请求报文后,可以直接发送SYN+ACK报文
2. 但关闭链接的时候,当服务器接收到FIN报文时,很有可能并不会立即关闭链接,所有只能先回复一个ACK报文,所以只能先回复一个ACK报文,告诉客户端,你发送的FIN报文我接受到了,只有等服务器端所有报文发送完了,我才能发送FIN 报文,因此不能一起发送,故需要四次挥手。
http1.0 和http1.1的一些区别
1.缓存处理:HTTP1.0 中主要使用Last-Modfied Expires 来做缓存的判断标准,HTTP1.1,引入了更多的缓存策略 ETag,Cache-control
2.宽带优化及网络连接的使用,HTTP1.1支持断点续传,即返回码是206
3.错误通知处理,HTTP1.1中新增了24个错误状态码的处理:如409标识请求资源与资源的当前状态发生冲突;410表示服务器上的某个资源被永久删除;
