写在前面:episode pattern挖掘不同于itemset pattern挖掘,其复杂程度是远远超过itemset,首先“情节”意味着一系列事件的发生,在一段时间内有多个itemset产生,这些itemset之间可能先后发生,也可能同时发生。也就是说episode挖掘不仅要考虑横向的事件序列,而且还要结合纵向事件集。
-
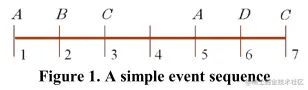
简单事件序列(Simple event sequence):设 ε={E1,E2,…,Em} 是有限个事件的集合,简单事件序列 SS=<(E1,T1),(E2,T2),…,(Em,Tm)> 是一组事件的有序序列,其中每一个事件 Ei∈ε 都与一个时间点 Ti∈N+ 相关联。例如下图(Figure 1.)中:
-
简单情节(Simple episode):简单情节 α 是一组非空有序事件集合。例如在图(FIgure 1.)中 <(A),(C)> 就是一个简单情节
-
同时事件集(Simultaneous event set):同时事件集 SE=(E1,E2,…,Em) 是指在同一个时间点 Ti 上发生的一组事件。
-
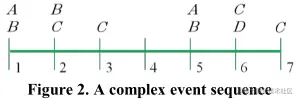
复杂事件序列(Complex event sequence):复杂事件序列 CS=<(SE1,T1),(SE2,T2),…, (SEn,Tn)> 是一系列有序事件集合,里面有多个同时事件集,各个同时事件集又组成一个事件序列 。例如下图(Figure 2.)中所示:
-
长度和大小(Length and Size):事件情节 α 的长度定义为 (其实就是该集合里事件的个数),称为 k-episode;而事件情节 α 的大小等于该情节中同时事件集合的个数。例如:<(AB),(C)> 就是大小为2的3-episode
-
发生(Occurrence):给定一个情节 ,当1)情节 α=<(SE1),(SE2),…,(SEm)> 发生在时间段 [Ts,Te];2)情节 α 的第一个同时事件集 SE1 发生在 Ts 时间点,最后一个同时事件集 SEm 发生在 Te 时间点,那么称情节 α 的发生在时间间隔 [Ts,Te] 上。其中,情节 α 的所有发生时间段组成集合 occSet(α) 。例如:在图(Figure 2.)中 occSet(<(AB),(C)>)={[1,2],[1,3],[1,6],[1,7],[5,6],[5,7]}
-
最短发生时间段(Minimal occurrence):给定情节 α 的两个时间间隔 [Ts,Te], [Ts′,Te′],[Ts′,Te′] 是 [Ts,Te] 的子集:当1)情节 α 的发生在[Ts,Te]时间段上;2)[Ts′,Te′] 不存在子集。最短发生时间段记为 mo(α)。其中,情节 α 的所有最短发生时间段组成集合 moSet(α)。例如:情节 <(AB),(C)> 的最短发生时间段 [1,2],且 moSet(<(AB),(C)>)={[1,2],[5,6]}
-
情节支持度(Support of an episode):情节 α 的支持度 SC(α) 定义为在最短发生时间段集 moSet(α) 中最短发生时间段的个数(Ps. 也就是在这个时间段发生了一次),支持率的定义为在CS中 SC(α) 与时间点的比值
-
频繁情节(Frequent episode):当一个情节的支持度不低于用户设置的支持度阈值(minSup),那么该情节称为频繁情节。
-
某个时间点的事件效用(Utility of an event at a time point):在某个时间点 Ti∈N+ 下某个事件 Ei 的效用定义为 u(Ei,Ti)=p(Ei,CS)×q(Ei,Ti) (利润 × 数量)
-
某个时间点并行发生事件集的效用(Utility of a simultaneous event set at a time point):在某个时间点 Ti∈N+ 下并行(同时)发生事件集 SE=(E1,E2,…,En) 的效用定义为 u(SE,Ti)=∑j=1nu(Ej,Ti)
-
基于复杂事件序列数据集的总效用(Total utility of database complex event sequence):基于复杂事件序列 CS 的总效用定义为 u(CS)=∑i=1nu(SEi,Ti)
-
关于最短发生时间段的情节效用(Utility value of an episode w.r.t its minimal occurrence):设 mo(α)=[Ts,Te] 是情节 α=<(SE1,SE2,…,SEn)> 的最短发生时间段,其中每一个并行发生事件集 SEi∈α 都与某一个时间点 Ti∈N+ 相关联。关于最短发生时间段的情节效用定义为 u(α,mo(α))=∑i=1nu(SEi,Ti)
-
基于复杂事件序列情节的效用(Utility of an episode in a complex event sequence):设 moSet(α)=[TI1,TI2,…,TIn] 是关于情节 α 的最小发生集。而基于复杂时间序列 CS 的情节效用定义为 uv(α,CS)=∑i=1nu(α,TIn),并且有 u(α)=uv(α)/u(CS)
-
最长持续时间(Maximum time duration):设 MTD 是用户预先设定的最长持续时间,mo(α)=[Ts,Te] 是情节 α 的最短发生时间段。当 (Te−Ts+1)≤MTD,称 mo(α) 受 MTD 的约束(或者是满足)(Ps. MTD起着时间窗口的作用,因为我们要计算就必须划定好一个范围,否则无穷大时间段或无穷小都不利于我们研究)
-
并行和串行连接(Simultaneous and serial concatenations):设 α=<(SE1),(SE2),…,(SEx)>, β=<(SE1′),(SE2′),…,(SEy′)>,α 和 β 的并行连结定义为 simul-concat(α,β)=<(SE1),(SE2), …,(SEx∪SE1′),(SE2′),(SEy′)>,α 和 β 的串行连接定义为 serial-concat(α,β)=<(SE1),(SE2), …,(SEx),(SE1′),(SE2′),…,(SEy′)> (Ps. 两种都是扩展项集,只是结合形式不一样)
-
高效用情节(High Utility Episode):当情节 Ei 的效用值 u(Ei)≥minUtil,则被视作是我们要的pattern(HUE),否则不是
-
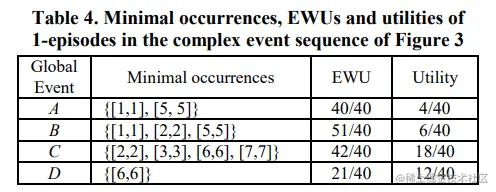
情节效用权重(Episode-Weighted Utilization of an episode):设 moSet(α)=[TI1,TI2,…,TIn] ,且TIi∈moSet(α) 满足 MTD 约束。那么基于复杂事件序列 CS 的情节 α 效用权重 EWU(α)=∑i=1nEWU(α,TIi)/u(CS)。例如:设 MTD=3,α=<(A),(C)>,那么 EWU(<(A),(C)>)=[u((AB),T1)+u((BC),T2)+u((C),T3)]+[u((AB),T5)+u((CD),T6)+u((C),T7)]/u(CS)=40/40
-
关于最短发生时间段的情节权重效用(Episode-Weighted Utilization of an episode w.r.t a minimal occurrence):设 mo(α)=[Ts,Te] 是情节 α=<(SE1),(SE2),…,(SEn)> 最短发生时间段,其中 mo(α) 受 MTD 的约束。那么在 [Ts,Te] 下情节 α 的情节权重效用 EWU(α,mo(α))= ∑i=1nu(SEi,Ti)+∑i=e(s+MTD−1)u(tSEi,Ti),其中 tSEi 是在 CS 中同时事件集的时间点 Ti 。例如:设 MTD=4,α=<(C),(A)>,mo(<(C),(A)>)=[3,5],那么 EWU(<(C),(A)>,[3,5])=[u((C),T3)]+[u((AB),T5)+u((CD),T6)]=25
-
高权重效用情节(High Weighted Utilization Episode):当一个情节 α 的 EWU(α)≥minUtil 时,该情节称为高权重效用情节(HWUE),也就是下一条定义的候选事件
-
候选事件(Promising event):当 EWU(e)≥minUtil 时,该事件 e 是候选事件,需要进一步计算其epsiode utility来准确判断。否则是 unpromising event,当 α 是非候选事件时,对任意情节 β,它们的超集 γ 都是低效用的。
-
情节权重的向下闭合性(Episode-Weighted Downward Closure property (EWDC)):设 α 和 β 都是情节,且 γ=simul-concat(α,β) 或 serial-concat(α,β),当 EWU(α)<minUtil 时,γ 是低效用情节
主体算法的思想是老规矩:找到一个长度为1的情节,然后把这个事件作为前缀再添加其它事件检查能否成为HEWU,需要注意的是每次扩展一个事件,这个事件的时间不能与前缀时间相差超过MTD
在学习了High-Utility Pattern Mining类算法后理解上并不是很难,大多定义加上了时间这个维度。从伪代码上来看该算法整体也不是很复杂,思路与HUI-Miner算法的思路大致一样,只是在这方面目前的研究比较少,还有很大的扩展空间。 该文献是第一个提出基于情节的高效用项挖掘概念,并成功实现。缺陷在于仅仅把提出的EWU作为边界值,难免太过模糊,会产生许多原本不需要的候选集。还需要使用更好的剪枝算法如FHM中使用的或更改数据存储结构,提高检索效率


