

Redis基本数据类型
String
可以用来存储int(整数)、float(单精度浮点数)、String(字符串)
存储模型
以set hello world 为例
key
key是字符串,Redis自己实现了一个字符串类型:SDS,hello使用SDS进行存储。
SDS的优点:
- 不用担心内存溢出,如果需要可以进行扩容。
- 获取字符串长度的时间复杂度为O(1),因为定义了len属性。
- 通过空间预分配与惰性空间释放,防止多次重分配内存。
- 判断是否结束是len属性,可以包含‘\0’。
value
value使用的RedisObject对象进行存储(Redis中五种基本数据类型的value都是使用RedisObject进行存储)
底层数据结构
使用type key可以查询value对应的存储类型
- int:存储8个字节的长整型(long,2^63-1)
- embstr:SDS的格式之一,存储小于44个字节的字符串
- raw:SDS的格式之一,存储大于44个字节的字符串
embstr,raw的区别:
- embstr的RedisObject和SDS是连续的,只需要分配依次内存空间,
而raw的RedisObject和SDS是不是连续的,所以需要分配两次内存空间。 - embstr是只读的,如果被修改则转为raw进行存储。
当长度小于阈值时,是否会自动转换编码:
不会,编码转换在数据写入时完成,且转换过程不可逆,只能由小内存编码转大内存编码(除非是重新set值)。
Hash
Hash存储键值对,最大值是2^32-1
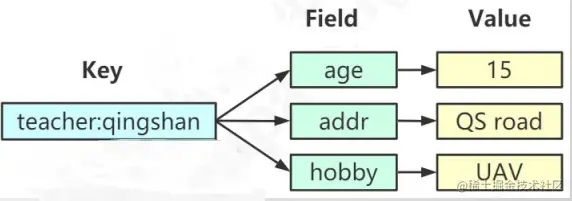
Hash与String的区别:
- Hash将所有key相关的值聚集到一个key中,节省存储空间。
- 只使用一个key,减少key的冲突。
- 当需要批量获取时只需要一个命令,减少I/O消耗。
Hash的缺点:
- Field不能单独设置过期时间。
- 由于field都聚集到一起,也就无法分布到多个节点。
底层数据结构
ziplist(压缩列表)
连续内存组成的双向链表
什么时候使用ziplist?
- 键值对数量少于512个。
- 所有键值对的键和值的字符串长度都低于64bytes。 如果超过一个条件编码类型就会变为hashtable
hashtable(哈希表)
数组+链表结构
如上图所示,一个value中有两个哈希表,ht[0]中存储数据,但ht[1]中为null。
Redis默认使用的是ht[0],h[1]不会初始化和分配空间。h[1]是用来rehash扩容的
rehash扩容
- 为字符ht[1]分配内存空间。
- 将ht[0]上所有节点重新rehash到ht[1]上,重新计算hash值和索引,并放到对应位置。
- 当所有数据迁移完毕,清空ht[0],并设置ht[1]为ht[0],创建新的ht[1]。
总结下
- String的底层使用INT,embstr,row
- Hash底层使用了ziplist,hashtable
list
早期版本:数据较少时使用ziplist存储,达到临界值时转换成linklist存储
3.2版本以后,统一使用quicklist存储
主要用来存储有序数据。
quicklist
quicklist是一个双向链表+数组的结构。
- head:指向双向列表的表头;
- tail:指向双向列表的表尾;
- count:所有ziplist中存储了多少元素;
- len:双向列表的长度,即node的数量;
Set
存储不重复,无序数据
如果元素都是整数型用inset存储,个数超过512会用hashtable存储
如果不是整数型就用hashtable存储
应用场景:点赞,签到,打卡,商品标签
Zset
有序不重复集合。 每个元素都有个score属性,按照score进行从小到大排序,score相同时,按照key的ASCLL码排序。
数据结构对比
底层数据结构
默认使用ziplist
如果元素个数大于128个,或者任意member长度大于64字节就会转成skiplist+dict存储。
skiplist
随机选择一个元素成为level元素,带有指向对应level的下个节点
应用场景:百度热搜,微博热搜
Bitmap
是在字符串上面定义的位操作,一个字节由8个二进制组成。
Hyperloglogs
不太精准的基数统计方法,用来统计一个集合中不重复的元素个数。
Geo
存储位置信息,有对应的位置操作api
Streams
支持多播的可持久化的消息队列,用于实现发布订阅功能。
总结
事务
Redis提供了事务功能,可以把一组命令一起执行。
特点:
开启事务后,客户端发送的命令不是立刻执行,而是放到队列中。- 按照进入队列的顺序执行。
- 不会受到其他客户端请求的影响。
- 事务不能嵌套,多个multi命令效果一样。
相关命令:
- multi(开始事务)
- exec(执行事务)
- discard(取消事务)
- watch(监视)/unwatch(取消监视):监视一个或者多个key,防止其被其他客户端修改,如果被修改,事务会被取消。
发生异常时的回滚:
- 在exec执行前发生异常:命令存在异常,事务不会执行,所有命令都不会被执行。
- 在exec执行后发生异常:运行时发生异常,事务不会回滚,已经执行的命令会生效。不能满足原子性的定义。
Lua脚本
轻量级脚本语言,批量执行命令,保证原子性
优点:
- 一次发送多个命令。
- Redis会将整个脚本作为一个整体执行,不会被其他客户端请求影响,保证
原子性。 - 对于复杂的组合命令,可以利用lua来实现命令的复用。
lua脚本缓存
script load "return 'hello world'"
>evalsha
脚本超时
脚本有个默认的超时时间,5秒
中止脚本
- script kill:脚本没有修改操作(set,del)
- shutdown nosave:脚本有修改操作(set,del)
redis为什么这么快
- 纯内存结构,时间复杂度O(1);
- 请求单线程;
- 同步非阻塞I/O:多路复用机制;
单线程
这里说的单线程是指的处理客户端请求是单线程的,在4.0版本之后,redis引入了其他线程去处理其他事情,如清理脏数据,无用连接,清理大key等。
优点:
- 没有创建、销毁线程带来的消耗;
- 避免上下文切换带来的CPU消耗
- 避免线程之前带来的竞争问题,例如加锁释放锁,死锁等。
注意:因为请求是单线程的,不要在生产环境运行长命令,比如save,keys *,flushall,flushdb否则会导致请求堵塞
多路复用
多路:多个TCP连接(Socket或者Channel)
复用:复用一个或者多个线程
问:select和epoll的区别?
答:
- select采用无差别轮询所有FD,且FD数量受限(32位1024个,64位2048个);
epoll采用事件监听方式触发,FD数量无限制,在FD数量多时epoll效率高,少则select更优。 - select需从内核空间复制到用户空间,性能消耗比较大; epoll数据是放在内核空间和用户空间共用的内存中,效率较高。
redis内存回收机制
LRU:删除最近最少使用
LFU:删除最不常使用,按使用频率删除
Random:随机删除
volatile:针对设置过期时间的key
allkeys:针对所有key
Redis的LRU
Redis的每个对象都有个lru属性24位字节LRU_BITS,用来记录当前对象最后一次被访问的时间。当对象被创建时会被赋值,在被访问时也会更新对应的值。
这个lru记录的时间不是当前的系统时间,而是redis的server.lruclock全局变量(自己定时更新时间),主要是为了提升效率。
Redis的LFU
基于访问频率的淘汰机制
LRU_BITS用作LFU时,高16位用来记录访问时间,低8位用来记录访问频率。
同时会有一个定时器,当这个对象一段时间没有被访问就会减少。
redis持久化机制
RDB
RDB是Redis默认的持久化方案(
当开启AOF时,优先使用AOF),当满足一定条件会把当前内存中的数据写入磁盘,生成一个快照文件dump.rdb。Redis会通过dup.rdb来恢复数据。
自动触发
- 配置的规则
- shutdown
- flushall
手动触发
- save:生成当前内存快照,会阻塞Redis,redis不能处理其他命令,如果数据较多,会造成较长时间阻塞。
- bgsave:fork一个子进程生产快照,不会记录fork之后的数据。阻塞发生在fork阶段,一半很短
优势
- RDB是一个非常紧凑的文件,非常适合用来备份和恢复。
- 生成RDB文件时,fork子进程进行处理,主进程不需要进行大量I/O操作,
- RDB在恢复数据的时速度比AOF快
劣势
- RDB没有办法做到实时持久化,且bgsave需要fork子进程,频繁执行成本过高。
- 如果redis挂掉,会丢失最新没有备份的数据
如果数据比较重要还是通过AOF进行备份。
AOF
默认不开启,将每个更改的命令都追加到文件中。Redis重启时,会把每个命令从前往后执行一次。
同步到磁盘的机制
重写机制
防止AOF文件越来越大,调用bgrewriteaof
- 当aof文件超过上一次AOF文件的百分之多少进行重写。
- 当aof文件到达最小文件大小。
优势
aof同步频率比rdb高的多
劣势
- aof文件比rdb文件大
- 在高并发下,rdb比aof性能更高
两种机制一起用,redis优先使用aof恢复数据,因为aof数据更完整。
Redis分布式
主从复制
主节点读写数据,从节点只能读,不能写
缺点
解决数据备份和一部分的性能问题,但是没有解决高可用问题(主节点挂了,对外不可用)。
Sentinel
启动奇数个sentinel监控redis节点,且互相监控。
选举master的基本流程:
在sentinel中基于raft协议选举一个leader,然后这个leader根据以下几个条件去选择一个节点成为master。
- 节点与哨兵断开连接过久就直接排除选举;
- 查看优先级,优先级高的中选;
- 优先级一致查看复制偏移量;
- 偏移量一致查看进程id,id最小中选。
master向其他节点发送slaveof no one 命令让他成为独立节点,然后发送slaveof x.x.xx.x成为master的从节点。
缺点
- 主从切换会丢失数据。
- 只能单点写,没有解决水平扩容问题。
分片
ShardingJedis
一致性哈希(哈希环)
把所有的哈希值空间组成一个圆环,整个空间顺时针组成,因为是环的,0-2^32-1重叠。
将数据放到比key的hash值大的第一个节点。
优点:
- 一致性哈希解决了动态增减节点数据需要重新分布的问题,他只会影响到下一个相邻的节点,对其他节点没有影响。
- 但是节点较少时,数据分布不均匀,但是在引入虚拟节点后这个问题也解决了。
- 不依赖其他中间件,分区逻辑可自定义。
具体实现:节点被放入红黑树中,当存取键值时,计算键的哈希值,然后从红黑树上找个比这个值大的第一个节点
代理
将分片的策略代码抽取出来,做成一个公共的服务,所有的客户端都连接到这个代理,由代理进行请求和转发。
Twemproxy
优点:稳定,可用性高 缺点:依赖其他组件,出现故障不能自动转移。
Redis Cluster
高可用,去中心化,客户端可以连接到任意节点。
节点之间两两交互,共享数据分片,节点状态等信息。
客户端不关心数据到底存在哪个节点,只需要关注整个集合整体。
数据分布
redis cluster没有采用哈希取模,也没有用一致性哈希,而是用虚拟槽来实现的。
具体实现:
- redis创建16384个虚拟槽,每个节点负责一定区间的slot。
- 对象进来的时候先对key用CRC16%16384取模,得到一个slot值,数据落到负责这个slot的redis节点上。
问:怎么让相关的数据落到同一节点上? 答:在key最加{hash tag} 。Redis在计算槽编号的时候只会获取{}之间的字符进行槽编号计算。
数据迁移
key和slot的关系不会变,当出现新的节点的时候,将属于这个节点slot对应的数据也要迁移到该节点上。
高可用与主从切换原理
当出现master挂点后:
- slave发现自己的master挂掉;
- 将自己记录的集群currentEpoch加1,并广播failover_request;
- 其他节点收到信息,只有master响应,判断合法性,返回failover_ack,对每个epoch只发送一个ack;
- 发起的slave收集ack;
- 超过半数则成为master;
- 广播Pong通知其他集群节点。
总结
- 无中心架构。
- 数据按照slot分布在多个节点,节点直接数据共享,可动态的调整数据的分布。
- 可扩展性,可线性的扩展到1000个节点,节点可动态的添加删除。
- 高可用,部分节点不可用,集群仍然可用。通过增加slave做standby数据副本,能够实现故障自动failover。
- 降低运维成本,提高系统的可扩展性和可用性。
Redis客户端
Jedsi
在springboot2.x版本之前默认使用的是Jedsi
缺点:
多线程使用一个连接的时候不安全。
解决版本:
连接池,为每个请求创建不同的连接。
连接池:JedisPool(普通连接池),ShardedJedisPool(分片连接池),JedisSentinelPool(哨兵连接池)
Cluster连接原理
使用Jedis连接Cluster时,我们只需要连接到任意一个或者多个redis group的实例地址,那我们怎么获取到应该操作的master实例呢?
为了避免get,set时发生重定向错误,我们需要把slot与Redis节点的关系保存起来,在本地计算key应该保存在哪个slot中,然后获取对应的redis节点。
如何保存slot与Redis连接池的关系?
- 程序启动初始化集群环境时,读取配置文件中的节点配置,无论是主是从,无论是多少,只拿一个,获取对应的redis实例。
- 获取该redis连接实例对应的虚拟槽信息。
- 根据虚拟槽信息获取所有槽点值
- 获取对应的主节点,构建hostAndPost对象。
- 根据hostAndPort拿到缓存中对应的JedisPool信息。如果没有则创建,并存入。
- 将slot值与JedisPool存入Map<String,JedisPool>(key是slot的下标,value是连接池)。
获取时,根据key计算得到对应的slot值,从map中获取到对应的jedisPool实例,根据jedisPool拿到对应的Jedis实例,完成存取工作。
Redis分布式锁实现
加锁:利用Hash(key锁名称,value(线程Id,过期时间,获取锁等待时间,重入次数)存入线程Id,过期时间,获取锁的等待时间。判断对应的线程Id的key是否存在,不存在则直接创建锁,存在则判断是否是一个线程Id,是则重入,不是则等待。
释放锁:判断key的线程Id是否与当前的相同,相同则重入次数减一,为0直接释放锁(del)。不是则不管。
加锁释放锁都需要用Lua脚本去实现,防止在高并发情景下的不安全问题。
Pipleline
客户端需要批量发送多个命令,将这些命令缓存起来,这些命令大小超过8M就会一起发送过去。服务端逐个执行并一起返回结果。
有些场景,例如批量写入数据,对于结果的实时性和成功性要求不高,就可以用Pipeline。
Lettuce
springboot 2.x默认客户端。无线程安全问题,基于Netty,支持所有功能。
Redission
提供了分布式锁的api,实现思路同上。且有看门狗功能(定时给key续命)。
数据一致性
Redis和mysql之间是没有事务功能的。
当缓存的数据需要被修改时,是先修改数据库还是修改缓存?
先更新数据库,再删除缓存
异常情况:更新数据库成功,删除缓存失败
解决办法:提供重试机制
- 删除缓存失败,把需要删除的key发送给消息队列,通过消费者去删除。 缺点:会造成代码入侵。
- 因为更新数据库时会往binglog中写入日志,所以我们通过一个服务监听binlog的变化(比如阿里的canal),然后在客户端完成删除key的操作。如果删除失败再发送到消息队列中。
先删除缓存,再更新数据库
异常情况:并发情况下出现ABA的问题,A删除缓存还没有更新数据库时,B就重新查询数据库将值写入缓存。 解决办法:延时双删,在写入数据后再删除一次key.
高并发问题
如何发现热点数据
客户端
统计key的次数
问题:
- 对客户端代码有侵入
- 不知道有多少key的存入,可能会造成内存泄漏
- 只能统计当前客户端的热点key
创建一个统计用的服务端,客户端统一发送key信息给服务端做统计。
服务端
Redis有个monitor命令,可以监控到所有Redis执行的命令。
问题:
- 高并发有性能问题,不适合长时间使用
- 只能监听一个redis节点的信息
机器层面
tcp协议抓包。
缓存雪崩
大量热点数据因为设置同样的过期时间同时过期(失效),而这时的并发又比较高,导致所有的请求落入到mysql中。
解决方案:
- 加互斥锁或者使用队列,针对同一个key只允许一个线程到数据库查询。
- 缓存定时预先更新,避免同时失效。
- 通过加随机数,避免同时失效。
- 不设置过期时间。
缓存穿透
频繁查询不存的数据。
- 将不存在的值也缓存到redis中,但也有个问题,如果是恶心的攻击,每次都是查询不同的值,如果都放到redis中存储,就会导致redis存储大量垃圾数据。
- 布隆过滤器。项目启动时,将数据存入到布隆过滤器中,查询redis时,先去布隆过滤器中判断是否存在,如果不存在,则不去查询redis和数据库。
布隆过滤器
一个0,1数组,加诺干个哈希函数。
相关面试题:如何在在海量数据中(10亿,无序,不重复,不定长)快速判断一个元素是否存在?
原理
存:假设有三个哈希函数,将这个元素的分别哈希三次%数组长度,分别得到三个位置,标记数组上这个三个位置为1。
判断一个元素e是否存在,假设有三个哈希函数,将这个e哈希三次%数组长度,分别得到三个位置,如果这三个位置的数组元素都是1,则判定这个e可能存在,否则一定不存在。
总结
- 如果布隆过滤器中判断元素不存在,则一定不存在。
- 如果布隆过滤器存在,则可能存在
不足:没有删除,如果一个元素在数据库中删除了,没有办法在布隆过滤器中删除。
解决办法:类似HashMap的链式地址法,给每个位置的下标增加一个计数器,如果命中了两次则为2,删除则-1,布谷鸟过滤器已经实现相关功能。
