

本文大量图片摘自网络,非商业用途。侵删。
数据结构
常见数据结构的优缺点
- 数组
优点:插入块如果知道坐标可以快速去地存取
缺点:查找慢,删除慢,大小固定
- 有序数组
优点:比无序数组查找快
缺点:删除和插入慢,大小固定
- 栈
优点:提供后进先出的存取方式
缺点:存取其他项很慢
- 队列
优点:提供先进先出的存取方式
缺点:存取其他项都很慢
- 链表
优点:插入快,删除快
缺点:查找慢
- 二叉树
优点:查找,插入,删除都快(如果数保持平衡)
缺点:删除算法复杂
- 红-黑树
优点:查找,插入,删除都快,树总是平衡的
缺点:算法复杂
- 2-3-4树
优点:查找,插入,删除都快,树总是平衡的。类似的树对磁盘存储有用
缺点:算法复杂
- 哈希表
优点:如果关键字已知则存取速度极快,插入快
缺点:删除慢,如果不知道关键则存取很慢,对存储空间使用不充分
- 堆
优点:插入,删除快,对最大数据的项存取很快
缺点:对其他数据项存取很慢
- 图
优点:对现实世界建模
缺点:有些算法慢且复杂
ArrayList
- ConcurrentModificationException
private class Itr implements Iterator<E> {
//...
public E next() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
int i = cursor;
if (i >= limit)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
limit--;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
//...
}
问题原因: 在遍历ArrayList时,调用了ArrayList.this.remove 方法。此时迭代器中的modCount加一,而expectedModCount并没有改变,再次调用next()则抛出并发修改异常。
解决办法:
- 使用Iterator的remove()方法
- 使用for循环正序遍历 - 正序fori遍历,在调用ArrayList.remove方法后,i--; 参考ArrayList#fastRemove。
- 使用for循环倒序遍历 - 倒序fori遍历,不需要修正下标。
HashMap
- 首先hash的概念:是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
例如:输入项为 12, 13, 15, 61, 63, 15, 63 ,通过散列算法(如取模运算) 映射到固定长度的数组中。这样就形成了一个散列表。
- hash碰撞
即通过散列算法运算插入数据时,取到了相同的输出(可以理解为数组中的下标相同)。此时通过输入的key不一定找到想要的数据。
-
解决hash碰撞
开放地址法和链地址法(拉链法)
- 数组+链表 -> 若发生了碰撞,则将数值存入同一下标的链表中。例如上面的输入项,对7取模时,
12mod 7 = 5 ,61mod 7 = 5。此时将12存到数组下标5中,将61存在下标5的next中。 - 再次哈希 -> 若发生碰撞,将输入再次取模,直到能存入一下空的下标中。
- 跳跃寻找 -> 若发生碰撞,向后跳跃N个位置尝试插入。
- 数组+链表 -> 若发生了碰撞,则将数值存入同一下标的链表中。例如上面的输入项,对7取模时,
-
HashMap的设计
首先看一下HashMap的类结构:

下面针对各个实现类的特点做一些说明:
(1) HashMap:它根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。 HashMap最多只允许一条记录的键为null,允许多条记录的值为null。HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。
(2) Hashtable:Hashtable是遗留类,很多映射的常用功能与HashMap类似,不同的是它承自Dictionary类,并且是线程安全的,任一时间只有一个线程能写Hashtable,并发性不如ConcurrentHashMap,因为ConcurrentHashMap引入了分段锁。Hashtable不建议在新代码中使用,不需要线程安全的场合可以用HashMap替换,需要线程安全的场合可以用ConcurrentHashMap替换。
(3) LinkedHashMap:LinkedHashMap是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。
(4) TreeMap:TreeMap实现SortedMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。如果使用排序的映射,建议使用TreeMap。在使用TreeMap时,key必须实现Comparable接口或者在构造TreeMap传入自定义的Comparator,否则会在运行时抛出java.lang.ClassCastException类型的异常。
对于上述四种Map类型的类,要求映射中的key是不可变对象。不可变对象是该对象在创建后它的哈希值不会被改变。如果对象的哈希值发生变化,Map对象很可能就定位不到映射的位置了。
通过上面的比较,我们知道了HashMap是Java的Map家族中一个普通成员,鉴于它可以满足大多数场景的使用条件,所以是使用频度最高的一个。下文我们主要结合源码,从存储结构、常用方法分析、扩容以及安全性等方面深入讲解HashMap的工作原理。
以上是备用知识
a. 数据结构
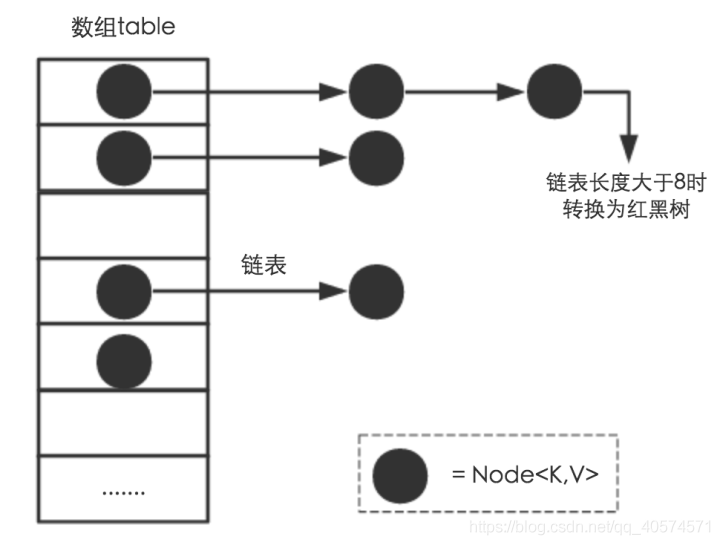
HashMap内存采用数组(hash桶/Node[] table) + 链表 (Node<K , V> next) + 红黑树(在链表的长度大于8时,链表转换为红黑树)
-
代表性的方法实现
- 确定哈希桶数组索引位置
HashMap中的hash算法主要分为3步:取key的hashCode值、高位运算、取模运算。

- put方法

-
resize扩容
- 数组扩容:创建一个新的Entry空数组,长度是原数组的2倍。
- rehash:遍历原Entry数组,把所有的Entry重新Hash到新数组。为什么要重新Hash呢?因为长度扩大以后,Hash的规则也随之改变。
JVM特性
类加载
- 加载过程
加载 -> 验证 ->准备 -> 解析 -> 初始化 -> 使用 -> 卸载
当程序主动使用某个类时,如果该类还未被加载到内存中,则JVM会通过加载、连接、初始化3个步骤来对该类进行初始化。如果没有意外,JVM将会连续完成3个步骤,所以有时也把这个3个步骤统称为类加载或类初始化。
- 双亲委托
运行时内存区域
图二:
表格:
| 名称 | 作用 | 生命周期 | 所有者 |
|---|---|---|---|
| 程序计数器 | 占用较小的空间,可以看作当前线程所指向的字节码的行号指示器。是程序控制流的治时期:分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器完成。 | 跟随独立线程的生命周期 | 线程私有 |
| Java虚拟机栈 | 描述Java方法执行的线程内存模型。方法执行的时候VM创建栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。方法的开始与结束对应这栈帧的入栈和出栈。 | 跟随独立线程的生命周期 | 线程私有 |
| 本地方法栈 | 作用与虚拟机栈一致,只是服务对象变为了本地(Native)方法。在Hotspot虚拟机中与虚拟机栈合二为一了。 | 跟随独立线程的生命周期 | 线程私有 |
| Java堆 | 存放对象实例。其中所有线程共享的Java堆中可以划分出多个线程私有的分配缓冲区(Thread Local Allocation Buffer,TLAB),以提升对象分配时的效率。 | 同Java虚拟机 | 所有线程共享 |
| 方法区 | 存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。需要注意,不能将方法去等同于“永久代”,而且在JDK 7就开始了移除永久代(PermGen)[在堆上分代]的工作,在JDK 8中已经不存在永久代。-- 后续有同学讲解GC可以详细讨论这个问题。 | 同Java虚拟机 | 所有线程共享 |
| 运行时常量池 | 是方法区的一部分。存放类被加载后的class文件中的常量池表(Constant Pool Table) // 下面的对象布局可以看到。 | 同Java虚拟机 | 所有线程共享 |
JMM
JMM 主要基于原子性、有序性和可见性三个特征来建立的。
- 可见性问题。
- 有序性问题(竞争现象)
-
重排序
- as-if-serial
as-if-serial语义的意思指:不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。编译器,runtime 和处理器都必须遵守as-if-serial语义。
- 内存屏障——禁止重排序
- 先行发生(happens-before)原则
happens-before部分规则如下:
1、程序顺序规则:一个线程中的每个操作happens-before于该线程中的任意后续操作(前一个操作的结果可以被后续操作获取)
2、监视器锁(同步)规则:对于一个监视器的解锁,happens-before于随后对这个监视器的加锁(必须先解锁后加锁)
GC
- 作用 : 垃圾收集。
- 对象是否存活
- 引用计数 - 在对象中添加计数器字段,每当有地方引用,计数器加一,反之减一。缺点:相互循环引用。
- 可达性分析 - GC Roots作为根对象,搜索所有引用链。
- 垃圾收集算法
- 分代收集理论
- 标记-清除算法
- 标记-复制算法 - 半区复制
- 标记-整理算法
Java特性
线程与进程
-
进程是程序的一次执行过程,是一个动态概念,是程序在执行过程中分配和管理资源的基本单位,每一个进程都有一个自己的地址空间,至少有 5 种基本状态,它们是:初始态,执行态,等待状态,就绪状态,终止状态。 -
线程是CPU调度和分派的基本单位,它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
多线程同步
- 同步关键字 synchronized
- Java锁类,如
ReentrantLock,包括Object的wait和notify、Condition中的await和signal、辅助类CountDownLatch和CyclicBarrier。 volatile关键字- 局部变量
ThreadLocal管理变量
注:ThreadLocal与同步机制
a.ThreadLocal与同步机制都是为了解决多线程中相同变量的访问冲突问题。
b.前者采用以"空间换时间"的方法,后者采用以"时间换空间"的方式
- 原子变量 - 在java的util.concurrent.atomic包中提供了创建了原子类型变量的工具类。
- 使用阻塞队列 - > 生产者 - 消费者问题
线程池
/**
* Creates a new {@code ThreadPoolExecutor} with the given initial
* parameters.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
* @param unit the time unit for the {@code keepAliveTime} argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
* tasks submitted by the {@code execute} method.
* @param threadFactory the factory to use when the executor
* creates a new thread
* @param handler the handler to use when execution is blocked
* because the thread bounds and queue capacities are reached
* @throws IllegalArgumentException if one of the following holds:<br>
* {@code corePoolSize < 0}<br>
* {@code keepAliveTime < 0}<br>
* {@code maximumPoolSize <= 0}<br>
* {@code maximumPoolSize < corePoolSize}
* @throws NullPointerException if {@code workQueue}
* or {@code threadFactory} or {@code handler} is null
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
- 参数表
| 参数 | 作用 | 常用赋值对象 |
|---|---|---|
| corePoolSize | 主要线程数 | - |
| maximumPoolSize | 最大线程数 | - |
| keepAliveTime | 线程存活时间 | - |
| unit | 时间单位 | - |
| workQueue | 工作的阻塞队列的实现 | ArrayBlockingQueue(数组实现的阻塞队列)、LinkedBlockingDeque(双向链表实现的阻塞队列)、LinkedBlockingQueue(单链表阻塞队列)、LinkedTransferQueue(链表构成的无界阻塞队列)、SynchronousQueue(无缓冲的等待队列)、PriorityBlockingQueue(优先级阻塞队列) |
| threadFactory | 线程工厂 - 生产线程 | DefaultThreadFactory、PrivilegedThreadFactory |
| handler | 线程池满时的阻塞的处理者 |
阻塞队列值得研究一下数据结构!!以及生产者-消费者问题。
使用时在构造好线程池后,会调用execute方法添加Runnable任务。此方法中可以分为3步:
- 如果核心线程数未满,增加新线程(
addWork) - 检查池是否正在允许和尝试任务入队。此处有double-check,来决定是否添加任务。
- 如果不能入队,尝试添加新线程。失败将reject任务。
JUC
Synchronzied
Java 泛型
- 基础概念与特性
- 泛型的本质是参数化类型,它把类的数据类型参数化了,使得它们可以从外部传入,从而扩展了类处理数据的范围。
- 当类型确定后,泛型会对类型进行检测,若不符合类型,则编译不通过。
- 提高代码的可读性,不需等到运行时才做强制转换。在定义或实例化数据时就能明确操作的数据类型。
- 泛型的使用
- 泛型类
- 泛型接口
- 泛型方法
- 泛型通配符
- 无限制通配符
<?> - 上界通配符
<? extends E> - 下界通配符
<? super E>
PECS原则:Producer extends , Consumer super(生产者有上限,消费者有下限)。如果既是生产者又是消费者,则不应使用通配符。
- 泛型擦除
Java中的泛型基本上都是在编译器这个层次来实现的。在生成的Java字节码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会在编译器在编译的时候去掉。这个过程就称为类型擦除。
反射
反射是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为 Java 语言的反射机制。
JAVA语言编译之后会生成一个.class文件,反射就是通过字节码文件找到某一个类、类中的方法以及属性等。
注解
注解的使用流程:
- 第一步,定义注解——相当于定义标记;
- 第二步,配置注解——把标记打在需要用到的程序代码中;
- 第三步,解析注解——在编译期或运行时检测到标记,并进行特殊操作。
String类
- 为什么String被设计为不可变类
- 相比可变类的不确定性,不可变类稳定可靠,适合作为散列表的键。
- 不可变对象本质是线程安全的,不需要同步。
- 风险:创建不可变类的对象代价可能很高,为提高性能使用可变配套类,StringBuilder和StringBuffer可以理解为String的配置类
反射可以破坏String的不可变性
- String + 的实现原理
String + 操作符是编译器的语法糖。编译后+操作符被替换为StringBuilder#append()。由于StringBuilder的方法是加了synchronized关键字修饰的,并且在编译后会产生中间变量(若是在循环中使用将产生大量的中间变量)。所以处于极限性能的考虑,某些情况会不建议使用。
- String对象的内存分配
- “str” -> 字符串常量池中的对象,多次声明使用的都是同一个对象
- new String("str") ->
new操作符会新建对象。
- String#intern()的实现原理
intern方法会先去查询常量池中是否有已经存在,如果存在,则返回常量池中的引用,这一点与之前没有区别,区别在于,如果在常量池找不到对应的字符串,则不会再将字符串拷贝到常量池,而只是在常量池中生成一个对原字符串的引用。简单的说,就是往常量池放的东西变了:原来在常量池中找不到时,复制一个副本放到常量池,1.7后则是将在堆上的地址引用复制到常量池。
Android特性
Activity
- 启动模式
standard:标准模式:如果在mainfest中不设置就默认standard;standard就是新建一个Activity就在栈中新建一个activity实例; singleTop:栈顶复用模式:与standard相比栈顶复用可以有效减少activity重复创建对资源的消耗,但是这要根据具体情况而定,不能一概而论; singleTask:栈内单例模式,栈内只有一个activity实例,栈内已存activity实例,在其他activity中start这个activity,Android直接把这个实例上面其他activity实例踢出栈GC掉; singleInstance :堆内单例:整个手机操作系统里面只有一个实例存在就是内存单例;
Activity四种启动模式常见使用场景: 这也是面试中最为长见的面试题;当然也是个人工作经验和借鉴网友博文,如有错误纰漏尽请诸位批评指正;
LauchMode Instance standard 邮件、mainfest中没有配置就默认标准模式 singleTop 登录页面、WXPayEntryActivity、WXEntryActivity 、推送通知栏 singleTask 程序模块逻辑入口:主页面(Fragment的containerActivity)、WebView页面、扫一扫页面、电商中:购物界面,确认订单界面,付款界面 singleInstance 系统Launcher、锁屏键、来电显示等系统应用
-
启动过程
-
根Activity组件启动过程
- Launcher组件向AMS发送一个启动MainActivity组件的进程间通信请求。
- AMS首先将要启动的MainActivity组件的信息保存下来,然后向Launcher组件发送一个进入中止状态的进程间通信请求。
- Launcher组件进入中止状态后,向AMS发送一个已经进入中止状态的进程间通信请求,以便AMS可以继续执行启动MainActivity组件的操作。
- AMS发现用来运行MainActivity组件的应用程序进程不存在,因此,它就会先通过Zygote fork出一个新的应用程序进程。(Socket通信)
- 新的应用程序进程启动完成后,就会向AMS发送一个启动完成的进程间通信请求,以便AMS可以继续执行启动MainActivity组件的操作。
- AMS将第2步保存下来的MainActivity组件的信息发送给第4步创建的应用程序进程,以便它可以将MainAcitivty启动起来。
-
Service
-
Service的类型
- 前台 - 执行一些用户能注意到的操作。例如播放音频。必须显示通知。
- 后台 - 执行一些用户不会直接注意的操作。
- 绑定 - 通过
bindService绑定的服务。
-
Service生命周期
- startService : onCreate -> onStartCommand -> stopService
-
IntentService与Service
IntentService是Service的子类。
- IntentService会创建默认的工作线程,用于在应用的主线程外执行传递给
onStartCommand的所有Intent。
- IntentService会创建默认的工作线程,用于在应用的主线程外执行传递给
-
在新进程中的启动过程
-
在进程中绑定过程
Broadcast
- 注册过程
- 静态注册
- 动态注册
- 发送过程
sendOrderedBroadcast发送有序广播sendBroadcast发送常规广播LocalBroadcastManager.sendBroadcast发送本地广播
Handler
Handler - MessageQueue - Looper
- 为什么不会阻塞 - epoll机制。
Binder
Binder的作用是跨进程通信。基于这一点我们首先要理解什么是进程,Binder如何跨进程。其次,再来讨论Binder的架构设计。
-
进程
进程是由程序(即指令集)、(存在寄存器上的)数据和PCB(进程控制块,类似JVM中的程序计数器)。而在Android或者说Linux系统中,进程运行的空间可以划分为用户空间和内核空间,由于用户空间的相互隔离,使得用户态的进程无法直接通信,这就是跨进程的原因。
-
Binder如何跨进程
Binder跨进程的实现主要集中在Binder驱动。驱动使用内存映射进行通信。1.对发送端copy_from_user下沉下来的数据进行映射,存放在驱动的一块接收缓存区中;而这块缓存区又与目标进程有映射关系,所以目标进程可以使用映射读取数据,从而接收到数据。
-
Binder的架构设计:Client 、Server、 ServiceManager 和Binder Driver。采用C/S结构。然后同时使用分层设计:Java层、C++层和驱动层。
-
支持的数据类型
- 基本数据类型
- List集合
- Map集合
- String类型
- CharSequence类型
- 实现Parcelable接口的序列化对象。
in:只能在客户端设置值,传入服务端,服务端获取客户端设置的值
out:用于在服务端设置值,服务端设置这个值后,客户端也可以得到这个由服务端设置的值,客户端如果有设置初始值,到了服务端会得不到这个值
inout:服务端可以得到客户端设置的值,客户端也可以得到服务端设置的值
-
oneway
表示异步调用。
-
传输数据大小
Zygote
Zygote是Android系统创建新进程的核心进程,负责启动Dalvik虚拟机,加载一些必要的系统资源和系统类,启动system_server进程,随后进入等待处理app应用请求
事件分发
- 事件传递分为三个阶段
- 分发(Dispatch) 对应
dispatchTouchEvent()方法。是否分发事件。 - 拦截(Intercept) 对应ViewGroup及其子类的
onInterceptTouchEvent()方法。拦截后将不再对子view进行分发。 - 消费(Consume) 对应
onTouchEvent()当前view是否消费事件,消费后不再向上传递给父view。
- 分发(Dispatch) 对应
- 三种拥有事件传递处理能力的类
- Activity :
dispatchTouchEvent和onTouchEvent - ViewGroup :
dispatchTouchEvent、onInterceptTouchEvent和onTouchEvent - View :
dispatchTouchEvent和onTouchEvent
- Activity :
- 分发流程
- 事件由Activity依次到ViewGroup再到子view。
- ViewGroup中通过onIntercetptTouchEvent对事件进行拦截。
- 在子view消费后,ViewGroup将接收不到任何事件。
- 主线程handler收到事件的消息后,分发到Activity:
HANLDER -> InputEventReceiver#dispatchInputEvent
-> ViewRootImpl$WindowInputEventReceiver#onInputEvent
-> ViewRootImpl$ViewPostImeInputStage#processPointerEvent
-> View#dispatchPointerEvent
-> DecorView#dispatchTouchEvent
-> WindowCallbackWrapper#dispatchTouchEvent
-> MainAcitivty#dispatchTouchEvent
- Activity传递到ViewGroup
MainAcitivty -> Activity -> PhoneWindow#superDispatchTouchEvent -> DecorView#superDispatchTouchEvent -> ViewGroup#dispatchTouchEvent -> ViewGroup#dispatchTransformedTouchEvent -> onInterceptTouchEvent作为dispatchTouchEvent 内部的一个变量判断是否拦截事件。
- 提问:若有两个同级的view group。事件是如何保证传递到所需的view group中。
- View的遍历。依次分发。关键方法:**ViewGroup#dispatchTransformedTouchEvent **
- 滑动冲突
子控件调用requestDisallowInterceptTouchEvent决定父控件拦截事件的时机。
自定义view
onMeasure - 测量view
onLayout - 布局位置
onDraw - 绘制
RecyclerView
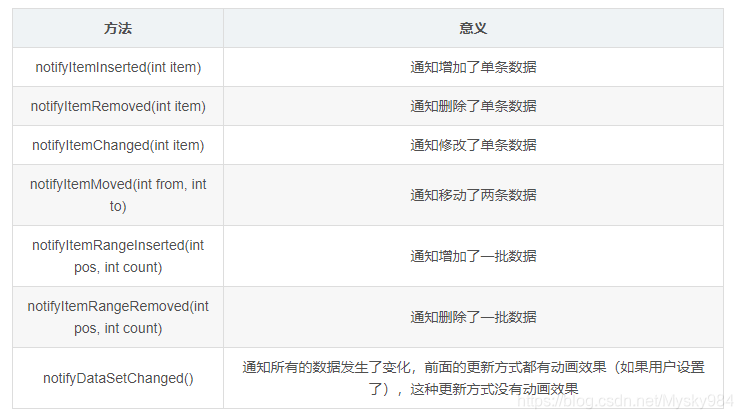
recyclerview的缓存,局部刷新用过吗?
缓存(复用与回收):
局部刷新:
设计模式
单例
- 懒汉式 - 线程安全 , 耗资源。
- 饿汉式 - 线程不安全。
- 双检锁 DCL 线程安全。
- 枚举 - 线程安全,不可破坏
观察者
Rx系列。发布 - 订阅模式。
工厂
代理
- 动态代理
- 静态代理
- 正向代理与反向代理
建造者
OkHttp、Retrofit
第三方库与其他
LRUCache
最近最少被使用,淘汰算法。定长链表
RxJava
基于事件流的观察者模式。
