

一 概述
Redis (Remote Dictionary Service)远程字典服务
Redis是一个开源(BSD许可),内存存储的数据结构服务器,可用作数据库,高速缓存和消息队列代理。它支持字符串、哈希表、列表、集合、有序集合,位图,hyperloglogs等数据类型。内置复制、Lua脚本、LRU收回、事务以及不同级别磁盘持久化功能,同时通过Redis Sentinel提供高可用,通过Redis Cluster提供自动分区
-
性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
-
丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
-
原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
-
丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
参考资料:
1.1 基础命令
Redis中设有16个数据库,默认使用0号数据库,可通过select命名切换数据库
# 切换数据库 select 1 # 查看当前数据库中的数据量 dbsize # 查看当前数据库中的所有值 keys * # 清空当前数据库 flushdb # 清空所有数据库 flushall # 判断某个key是否存在 exisit key # 设置带有过期时间的key(单位:秒) expire key 10 # 获取key剩余过期时间 ttl key # 查看key的类型 type key
Redis是单线程,为什么依然这么高效?
-
Redis是基于内存操作,性能瓶颈是内存和网络带宽,而不是CPU
-
数据结构简单,对数据的操作命令也简单
-
采用单线程,避免了不必要的上下文切换和竞态条件
-
使用多路复用I/O模型,非阻塞IO
-
使用底层模型不同,Redis自己构建了VM机制,更高效
1.2 基础类型
String
# 设置key-value值 set key name # 查看key get key # 获取所有的key keys * # 判断某个key是否存在 exists key # 为key追加内容,如果key不存在,则新增该key append key "Hello" # 获取key长度 strlen key # 自加1 incr key # 自减1 decr key # 每次增加n incrby key n #每次减少n decrby key n # 获取字符串指定位置字符, 0 -1 获取全部 getrange key start end # 使用新值替换指定位置的字符 setrange key index newValue # 创建带有过期时间的key(set with expire) setex key expiretime value # 如果数据库中无key则新增该key (set if not exists) 在分布式锁中经常使用 setnx key value # 先获取再设置 getset key value
List
# 从头部设置值 lpush list value # 从尾部设置值 rpush list value # 获取list指定范围的值 0 -1 获取所有的值 lrange list start end # 从头部移除值 lpop list value # 从尾部移除值 rpop list value # 获取list中指定位置的值 lindex list index # 获取list中指数组长度 llen list # 移除指定的值 lrem list 1 value # 截断list ltrim list start end # 移除列表中的最后一个元素到另一个list中 lpoplpush srcList targerLsit
-
List可看做是一个链表
-
在头尾插入元素效率高,在中间插入数据效率低
-
可作为消息队列使用(Lpush Rpop)
-
可作为栈使用(Lpush Lpop)
Set
# 新增元素 sadd mySet hello # 查看元素内容 smembers mySet # 判断集合中是否有某个元素 sismember mySet hello # 获取集合中的元素数量 scard mySet # 移除集合中的元素 srem mySet hello # 随机获取元素 srandmember mySet # 随机删除元素 spop mySet # 移动指定集合中的元素到另一个集合中 smove mySet anotherSet hello # 两个集合中的差集 sdiff mySet1 mySet2 # 两个集合中的交集 共同好友 sinter mySet1 mySet2 # 两个集合中的并集 sunion mySet1 mySet2 # 获取所有的keys hkeys myHash # 获取所有的value hvals myHash
-
无序不重复集合
-
微博好友,关注等
Hash
# 设置key-value hset myHash userName hello # 获取指定key的value hget myHash userName # 获取所有的vlue hgetall myHash # 删除指定key hdel myHash userName # 获取hash长度 hlen myHash # 判断是否存在指定的key hexists myHash key1
-
结构类似于java中的Map
-
适合于存储经常变动的数据,更适合对象的存储
Zset
# 添加值,需指定顺序 zadd mySet 1 one zadd mySet 2 two # 获取所有元素 zrange mySet 0 -1 # 排序 zrangebyscore mySet -inf +inf zrangebyscore mySet -inf +inf withscores # 逆序 zrevrange score 0 -1 # 获取集合中的元素个数 zcard mySet
-
在set的基础上,增加排序
-
对象排序,
Geospatial
# 设置城市的经纬度 geoadd china:city 39.90 116.40 beijing # 获取经纬度 geopos china:city beijing # 返回两个位置间的距离 geodis china:city beijing shanghai km # 寻找指定位置附近的人 georadius china:city 110 30 1000 km georadiusbymember chiba:city beijing 1000 km # 查看地图中所有元素 zrange china:city 0 -1 # 移除地图中的指定元素 zrem china:city beijing
-
设置经纬度可以计算距离以及查询附近的人
-
底层使用Zset实现
Hyperloglog
# 增加值 pf add myKey a b c d # 统计 pfcount myKey # 合并 pfmerge myKey1 myKey2
-
基数-不重复的元素 ,有一些误差
-
占用的内存很小,2^64
-
常用于浏览器计数、访问量、粉丝数,
Bitmap
# 第一个位置设为有效
setbit sign 0 1
setbit sign 1 0
# 获取某个位置的状态
getbit sign 1
# 统计 状态为1的个数
bitcount sign start end
-
位存储,省空间
-
统计活跃用户、休眠用户
-
适用于只有两种状态的场景
1.3 事务
Redis事务本质
将一组命令打包运行,这些命令都会被序列化,然后按照顺序依次执行,Redis事务不保证原子性
-
开启事务(multi)
-
命名入列 (redis命令)
-
执行事务(exec)
-
放弃事务(discard)
开启事务
multi
执行命令
set key1 value1 set key2 value2 set key3 value3
执行事务
exec #放弃事务 discard
编译时异常会回滚所有命令
运行时异常会导致部分成功,部分失败
1.4 监控(乐观锁)
Redis支持监控数据,相当于一个乐观锁
# 监视指定的key,记录此刻的值,在执行事务时比较,如果值发生改变则执行不成功
watch key
unwatch
二 核心功能
2.1 Redis配置文件
Redis配置文件保存了redis启动时的一些默认命令
redis对大小写不敏感
# 指定默认的端口号
prot 6379
# 设置密码
requirepass abcd123
# 连接队列的大小 backlog队列总和= 未完成三次握手队列+已经完成三次握手队列
# 通常用于高并发场景下提高客户端连接数量
tcp-backlog 511
# 将redis服务设置为守 候服务,仅在Unix有效
daemonize yes
# 绑定主机
bind 127.0.0.1 10.0.0.1
# 保持会话时间,推荐60s
tcp-keepalive 0
# 设置日志级别
loglevel notice
# 指定日志存储的文件
logfile "Logs/redis_log.txt"
# 自动开启wondows的事件日志
syslog-enabled yes
# 设置Redis的数据库,共有16(0~15)个,通常默认为0
databases 16
# 持久化机制
save 900 1 # 900s(15min)内至少发生一次变更
save 300 10 # 300s(15min)内至少发生10次变更
save 60 10000 # 60s(1min)内至少发生10000次变更
# 如果持久化失败,是否继续工作
stop-writes-on-bgsave-error yes
# 是否压缩rdb文件,需要消耗一些cpu
rdbcompression yes
# 保存rdb文件时,自动校验
rdbchecksum yes
# rdb文件保存位置
dir ./
# 设置连接redis的最大客户端数量
maxclients 10000
# 设置最大内存
maxmemory <bytes>
# 内存超限后的处理策略
# volatile-lru 使用LRU算法删除过期集合的key
# allkeys-lru 在主键空间中,优先移除最近未使用的key
# volatile-random 在设置过期时间的键空间中,随机删除某个key
# allkeys-random 岁间删除全部键空间的某个key
# volatile-ttl 在设置了过期时间的键空间中,优先删除更早过期时间的key
# novaiction 直接报错
maxmemory-policy noeviction
# 是否开启AOF持久化方式
appendonly no
# 设置AOF持久化方式的文件名
appendfilename "appendonly.aof"
# 设置同步策略,默认每秒同步一次(可能会丢失数据)
appendfsync everysec
# 设置同步策略,每次修改都会同步
appendfsync always
# 设置同步策略,不执行同步,依赖操作系统的同步机制
appendfsync no
2.2 数据持久化
Redis中的数据全部存储在内存中,如果突然宕机,数据会全部丢失,因此必须有一种持久化机制来存储redis中的数据
2.2.1 RDB
RDB持久化是指在指定时间间隔内将内存中的数据快照写入磁盘,类似于一个快照,通常会生成一个dump.rdb文件
-
触发方式
-
save
save命令手动触发RDB持久化,save命令会阻塞主进程,直到RDB持久化结束。当Redis中有大量数据需要持久化时,会造成较长时间的阻塞,不建议生产上使用
-
bgsave
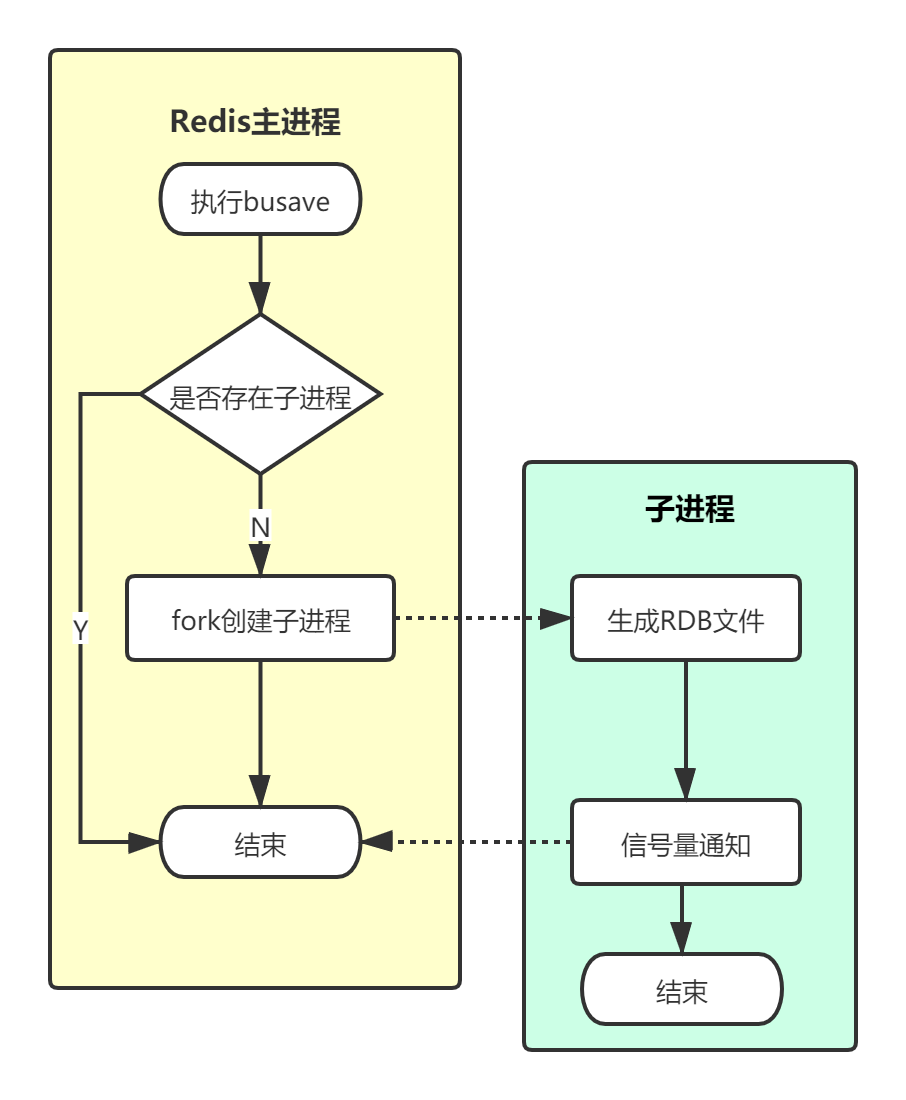
bgsave也会手动触发RDB持久化,不同的是,它不会阻塞主线程。在后台fork出子进程来执行持久化,仅在fork的一瞬间阻塞redis服务,通常时间很短
1) 执行bgsave命令,redis首先会判断当前是否存在子进程,如果存在直接结束
2) redis进程fork出子进程,此过程会阻塞服务
3) fork结束后,bgsave命令执行结束,此后主进程继续提供服务,子进程在后台进行持久化磁盘
4)子进程根据redis进程的内存生成快照文件,并替换原有的rdb文件
5)持久化结束后,子进程会通过信号量的方式告知主进程
-
-
拓展 Copy-On-Write
通常为了提高fork的效率,操作系统会采用COW方式来创建子进程
fork之后,kernel会把父进程中所有的内存页的权限设为read-only,然后子进程的地址空间指向父进程。当父子进程都只读内存时,共享同一份内存,当其中某个进程写内存时,会触发页异常中断(Page-Fault),中断进程就会把触发异常单内存页复制一份
fork-复制出一个完全一样的进程
exec-替换掉当前进程的地址空间
-
优点
RDB是一个非常紧凑的二进制压缩文件,是Redis在某个时间点的完整快照,因而RDB的文件数据恢复的速度要远远快于AOF,非常适合全量备份、灾难恢复等场景
-
缺点
需要一定的时间进行持久化操作,可能会丢失最后一次同步前的数据
fork子进程的时候,会占用一定的内存空间
2.2.2 AOF
AOF(Append Only File),把每次对Redis的写命令都记录到日志中,然后在指定时间内同步到磁盘中,当需要数据恢复时只需把AOF文件重新执行一遍即可。AOF解决了持久化的实时性。
-
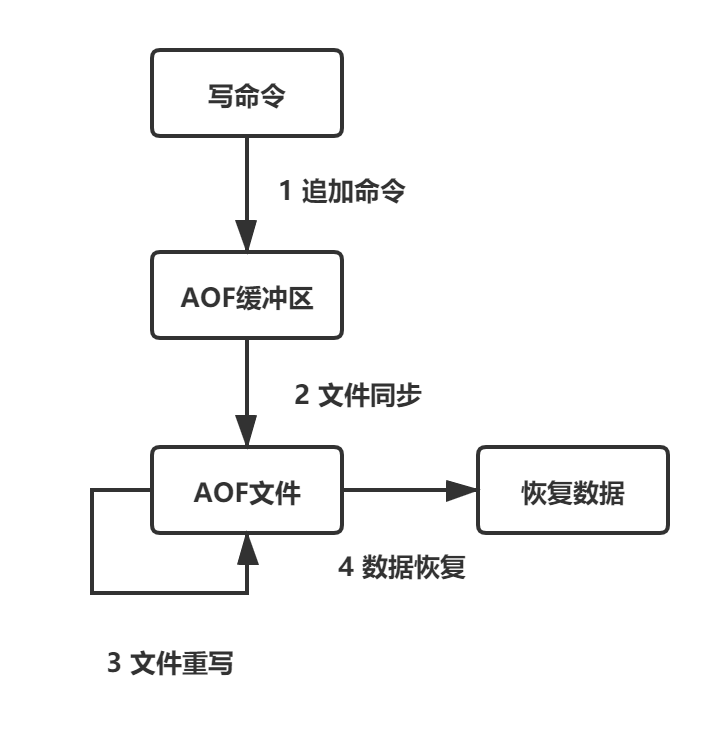
执行步骤
1)命令追加,将所有的写命令追加到AOF缓冲区内
2)文件同步,根据不同的策略将AOF缓冲区同步到AOF文件中
# 设置同步策略,默认每秒同步一次(可能会丢失数据) appendfsync everysec # 设置同步策略,每次修改都会同步 appendfsync always # 设置同步策略,不执行同步,依赖操作系统的同步机制 appendfsync no3) 文件重写,定期对AOF文件进行重写,节约空间
4)数据加载,当需要恢复数据时,重新执行AOF文件
-
优点
每次修改都会同步,实时性更好
以文本形式保存了写命令,更易读
-
缺点
AOF文件远大于RDB文件,修复速度也比较慢
AOF运行效率比较低,因而默认的持久化策略为RDB
2.3.3 混合持久化
Redis4.0后新增了新的功能-混合持久化。将RDB文件的内容和增量的AOF日志文件存在一起,这里的AOF文件不再是全量的日志,而是自持久化开始到持久化结束的这段时间内发生的增量的AOF日志,通常这部分日志的体积很小。当Redis重启时,可以先加载RDB文件,然后再重放AOF日志,数据恢复的速度得到很大的提高。
2.3 发布订阅
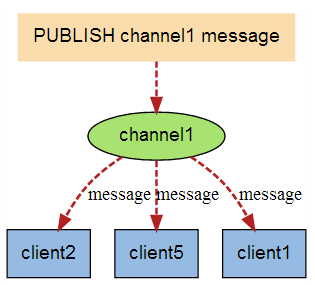
Redis支持有限的消息监听机制,以实现发布订阅模式。Redis客户端可订阅任意数量的topic
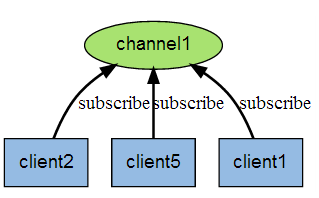
# 订阅主题
subscribe myTopic1 myTopic2 myTopic3
# 发送消息
publish myTopic1 Hello
# 取消订阅
unsubscribe myTopic1
Redis的消息并没有持久化,一旦redis宕机,所有的消息都会丢失。在消费过程中,一旦某个消费者宕机又恢复后,在此过程中的消息将不会被重新消费。
-
使用场景
实时消息系统
聊天室
订阅、关注等
2.4 主从复制
将一台Redis服务器中的数据复制到其他服务器中,数据的复制只能是单向的,只从Master到Slave。
-
数据冗余 主从复制实现了数据的热备份,持久化的一种数据冗余方式
-
故障恢复 主节点宕机后,可以平滑迁移到从节点中,实现故障的快速恢复
-
负载均衡 实现读写分离,主服务器提供写服务,从服务器提供读服务,从而提高Redis的并发量
-
高可用 实现哨兵以及集群的基础
Windows配置主从服务器
-
复制Redis安装包,重写redis.windows.conf文件
# 更改从服务器的端口号 port 6380 # 配置主服务器 slaveof 127.0.0.1 6379 masterauth jincong # 从机变成主机 slaveof no one -
查看主从服务器
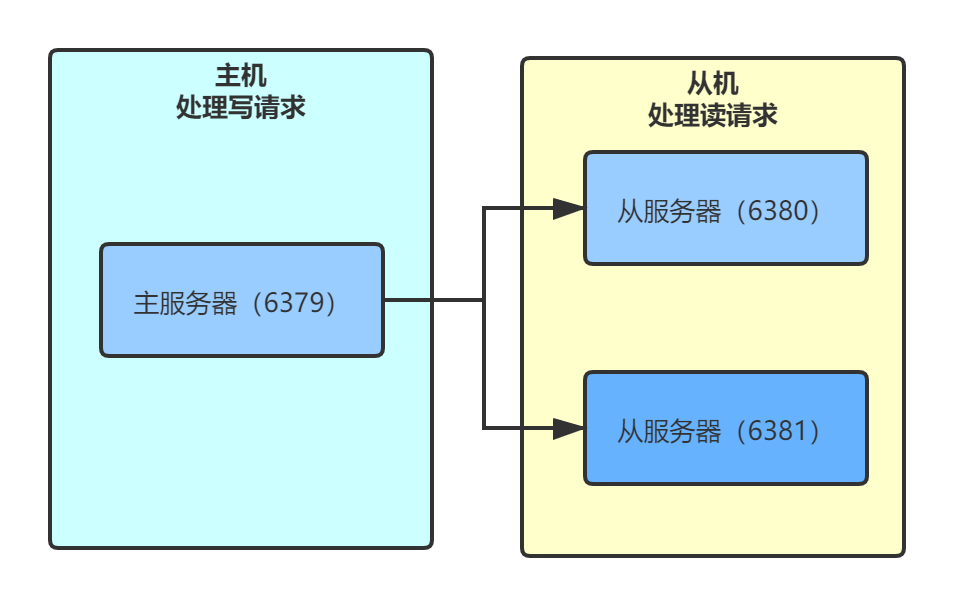
# 主服务器 > localhost:6379 connected! > info replication # Replication role:master connected_slaves:2 slave0:ip=127.0.0.1,port=6380,state=online,offset=827,lag=0 slave1:ip=127.0.0.1,port=6381,state=online,offset=827,lag=1 master_repl_offset:827 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:2 repl_backlog_histlen:826 # 从服务器6380 > info replication # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:up master_last_io_seconds_ago:7 master_sync_in_progress:0 slave_repl_offset:57 slave_priority:100 slave_read_only:1 connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 # 从服务器6381 > info replication # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:up master_last_io_seconds_ago:7 master_sync_in_progress:0 slave_repl_offset:57 slave_priority:100 slave_read_only:1 connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0
主从服务器特点
-
主机可以设置值,从机只能读取,从机会自动与主机保持同步
-
主机宕机,从机依旧保持与主机关系,无法处理写请求。主机恢复后,会自动同步数据。从机宕机恢复后,也是如此
-
Slave启动成功后,会向master发送一个sync命令
-
master接受到命令后,启动后台的存盘进程,同时收集所有接收到的用于修改数据集的命令,在后台进程执行结束后,master将传送整个数据文件到slave,并完成一次完全同步
-
全量复制 slave服务在接收到数据文件后,将其存盘并加载到内存中
-
增量复制 master继续将所有收集到的修改命令依次传给slave,完成同步
但是只要是重新连接master,就会自动执行一次全量复制
-
-
2.5 哨兵模式
当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,非但不高效还会导致一段时间内服务不可用。Redis从2.8开始提供Sentinel模式,来自动选取主服务器。哨兵模式是一个独立的进程,通过实时监控整个Redis服务来确定存活的实例,一旦主服务器宕机,就会触发内部的重新选举机制。哨兵模式实现了故障回复的自动化处理,缺陷是写操作无法负载均衡,存储能力受到单机的限制。
参考链接:[Redis哨兵模式与高可用集群(juejin.cn/post/684490…)
-
工作模式
1)创建一个Redis哨兵模式,通常由多个哨兵进程、一个主机、多个从机组成
2)Sential中记录了主从节点的信息,并持续监控主从节点的健康,一旦主节点宕机,内部会根基自己的投票算法自动选取一个从节点作为新的主机
3)客户端来连接集群时,会首先访问Sential节点获取当前的主节点,然后与主节点进行数据交互。当主节点宕机后,客户端会重定向到到sentinel获取新的主机地址。从而无需外部干预即可平滑切换主机。
-
如何启动哨兵模式
哨兵模式配置文件 1表示开启自动投票机制,得票多的称为新的主机
sentinel monitor mysentinel 127.0.0.1 6379 1
开启哨兵监控模式
redis-sentinel.exe sentinel.conf
-
主观下线和客观下线
默认情况下,每个Sentinel节点都会以每秒一次的频率对Redis的其他节点(主节点、从节点、其他的Sentinel节点)发送ping命令,并通过节点的 回复来判断节点是否正常
-
主观下线 适用于所有的主节点和从节点,如果在
down-after-milliseconds时间内,sentinel没有收到目标节点的有效回复,则会判定该节点为主观下线 -
客观下线 仅适用于主节点。如果主节点发生故障,Sentinel节点会通过
sentinel is-master-down-by-addr命令向其他Sentinel节点询问对该节点的状态判断,如果超过quorum个数的节点判定主节点不可达,则该Sentinel节点会判断主节点为客观下线
-
-
详解Sentinel的工作原理
1) 每个Sentinel以每秒一次的频率,向它所知的主服务器、从服务器及其其他Sentinel发送一个PING命令
2)如果一个实例节点距离最后一次有效回复PING命令的时间超过down-after-milliseconds,那么这个实例会被Sentinel标记为主观下线
3)如果一个主服务器被标记为主观下线,那么正在监视这个主服务器的所有Sentinel节点,要以每秒一次的频率确认主服务器的确进入了主观下线状态
4)如果一个主服务器被标记为主观下线,并且有足够数量的Sentinel在指定的时间范围内同意这一判断,那么这个主服务器就会标记为客观下线
5)一般情况下,每个Sentinel会以每秒10次的频率,向它已知的所有主服务器和从服务器发送INFO命令,当一个主服务器被Sentinel标记为客观下线时,Sentinel向下线服务器的从服务器发送INFO命令的频率,会从10秒1次提升到1秒一次。
6)Sentinel和其他Sentinel协商主节点的状态,如果主节点处于SDOWN状态,则投票自动选出新的主节点,将剩余的从节点指向新的主节点进行数据复制。
7)当没有足够数量的Sentinel同意主服务器下线时,主服务器的客观下线状态就会被移除,当主服务器重新向Sentinel的PING命令返回有效回复时,主服务器的主观下线状态就会被移除
2.6 缓存穿透、击穿和雪崩
缓存穿透
-
概念
客户端查询的数据不在缓存中,直接访问数据库,也没有查到导致查询失败。大量请求穿透缓存层直达数据库,从而导致缓存穿透
-
解决方案
-
布隆过滤器
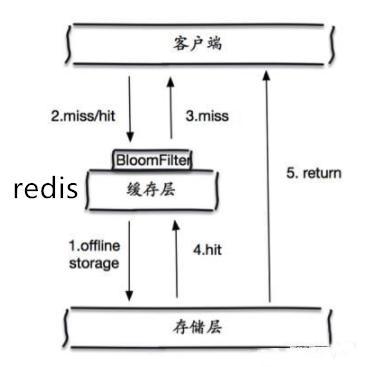
布隆过滤器是一种数据结构,它将数据经过多种hash运算后,生成一串二进制代码,映射到指定的数据结构中。工作时,首先将所有可能查询的参数以hash的形式存储。当查询时首先使用布隆过滤器判断是否存在,如果不存在直接返回。
-
缓存空对象
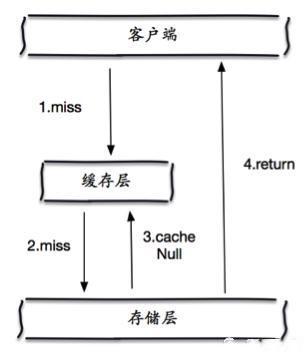
当没有命中存储层时,即使返回空对象也将其缓存起来,同时设置一个过期时间,之后再次访问时会直接命中缓存,从而保护存储层
-
缓存击穿
- 概念
在高并发场景下,多线程同时查询同一个热点对象,如果该热点对象不在缓存中或者恰巧缓存失效,导致同一时间大量请求打到数据库,从而导致数据库压力陡增
-
解决方案
-
设置热点数据永不过期
从缓存层面讲,没有设置过期时间热点数据就不会失效,从而保护数据
-
加互斥锁
后台使用分布式锁,保证同一时间对于某个key只能有一个线程访问,这种方式将压力转移到了分布式锁上。
-
缓存雪崩
-
概念
大量热点key在同一时间过期,或者缓存宕机,从而导致大量请求直达数据库,进而引发一系列业务问题。
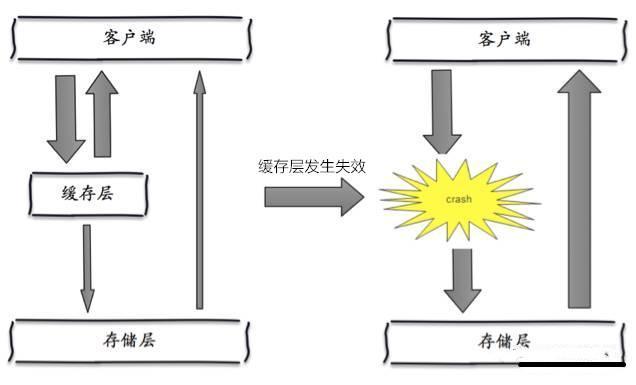
-
解决方案
-
redis高可用
既然Redis可能宕机,那就提供一种高可用机制,确保即使Redis宕机,也能正常提供缓存服务。通常可以采用哨兵或者集群的方案达到高可用目的。
-
限流降级
在缓存失效后,通过加锁或者对列来控制对数据库的访问。比如分布式锁、阻塞对列等技术
-
数据预热
在正式部署前,在缓存中预存储热点数据,从而在生产上拦截掉大部分的访问,同时将这些热点key设置不同的过期时间,使缓存失效时间尽量均匀。
-
三 Redis使用
3.1 Windows启动Redis服务
jingyan.baidu.com/article/f25… 启动过程
www.cnblogs.com/fyboke/p/62… 简单操作
www.cnblogs.com/skmobi/p/11… windows配置Redis
windows安装Redis服务
# 临时开启Redis
# 这个命令会创建Redis临时服务,不会在window Service列表出现Redis服务名称和状态,此窗口关闭,服务会自动关闭
redis-server.exe redis.windows.conf
# 连接redis
redis-cli.exe 127.0.0.1 -p 6379
# 停止服务
redis-server –service-start
# 配置windows开机自启Redis服务
安装服务:
redis-server.exe --service-install redis.windows.conf --service-name redisserver1 --loglevel verbose
启动服务:
redis-server.exe --service-start --service-name redisserver1
停止服务:
redis-server.exe --service-stop --service-name redisserver1
卸载服务:
redis-server.exe --service-uninstall--service-name redisserver1
3.2 Springboot集成Redis
Springboot中使用Redis,只需导入相关依赖即可,同时所有的对象必须支持序列化
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
Springboot的redis默认使用JdkSerializationRedisSerializer,如果想使用json必须手动配置redisTemplate
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
// 将对象解析为json
Jackson2JsonRedisSerializer serializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper mapper = new ObjectMapper();
mapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
mapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
serializer.setObjectMapper(mapper);
// 设置Redis的序列化方式
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(serializer);
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(serializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
3.3 缓存一致性
-
缓存优点
能够缩短服务响应时间,给用户带来更好的体验
能够增大系统的吞吐量,提升性能
减轻数据库压力,防止超载
-
缓存缺点
增加了开发难度和维护难度
增加系统复杂度
特殊场景下必须考虑缓存一致性
不更新缓存而是删除缓存
如果业务中只是到数据库中取值然后写入缓存,或者写入缓存中的值需要经过复杂的计算,更适合删除缓存 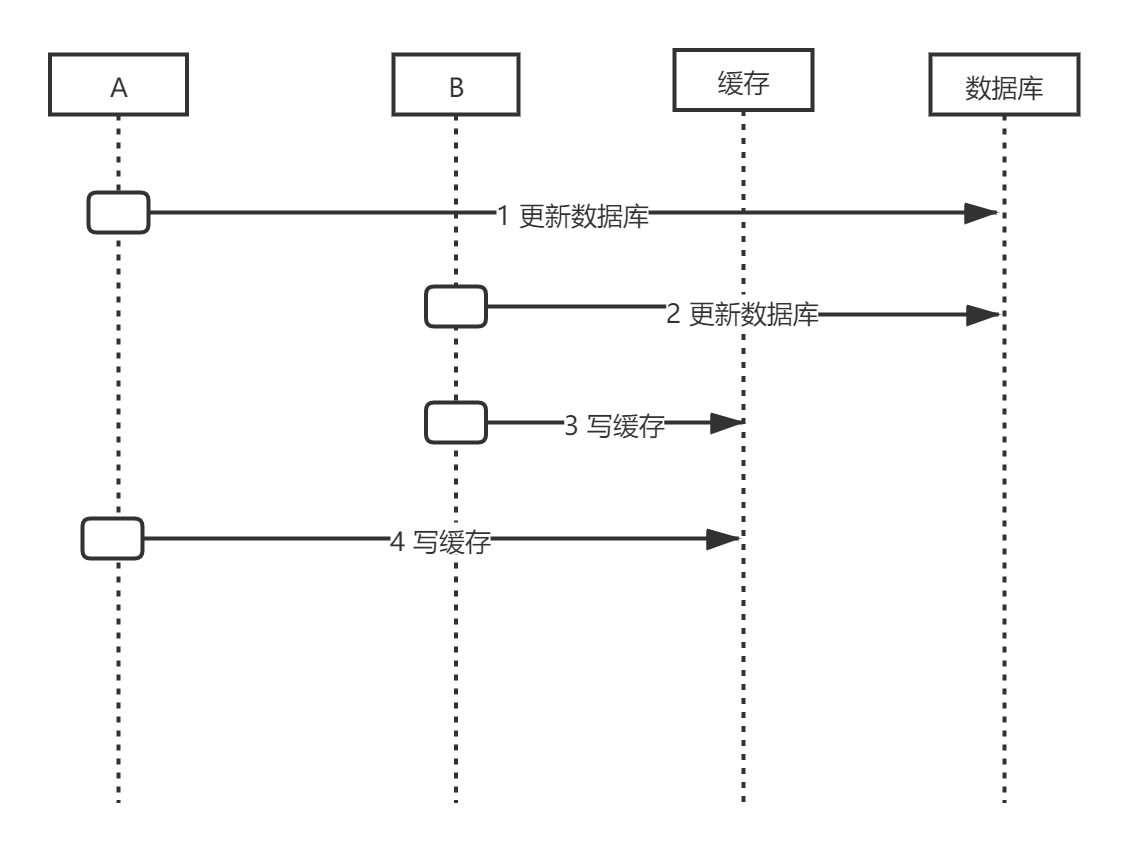
考虑以上场景
-
线程A更新数据库,x=1
-
线程B更新数据库,x=2
-
线程B更新缓存,cache=2
-
线程A更新缓存,cache=1
这就会出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络抖动等原因,B却比A更早更新了缓存,导致缓存了脏数据,如果仅仅是淘汰缓存,仅增加了异常cache miss。
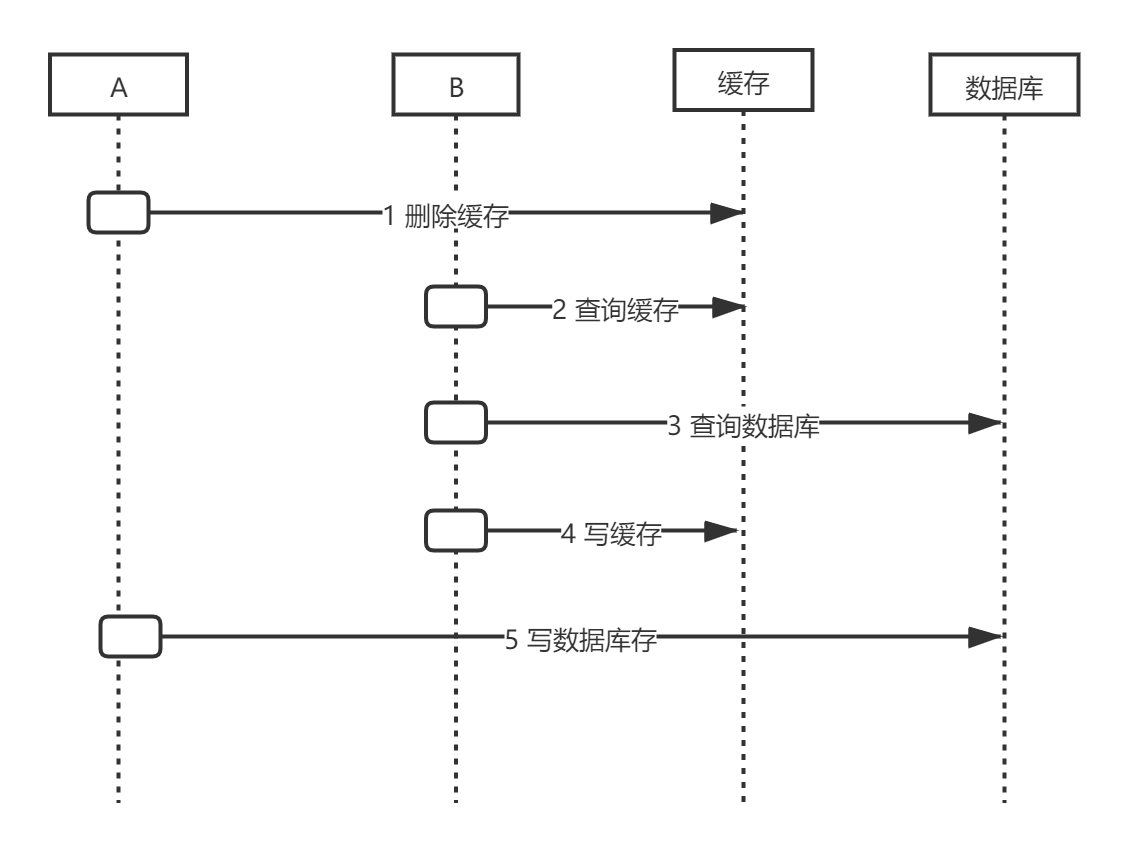
先删缓存,再更新数据库
-
请求A进行写操作,删除缓存 del cache
-
请求B查询缓存不存在,cache=null
-
请求B查询数据库,得到旧值,x=1
-
请求B将旧值写入缓存,cache=1
-
请求A将新值写入数据库,x=2
此种场景会出现数据不一致情况,而且如果没有给缓存设置过期时间,该数据永远为脏数据
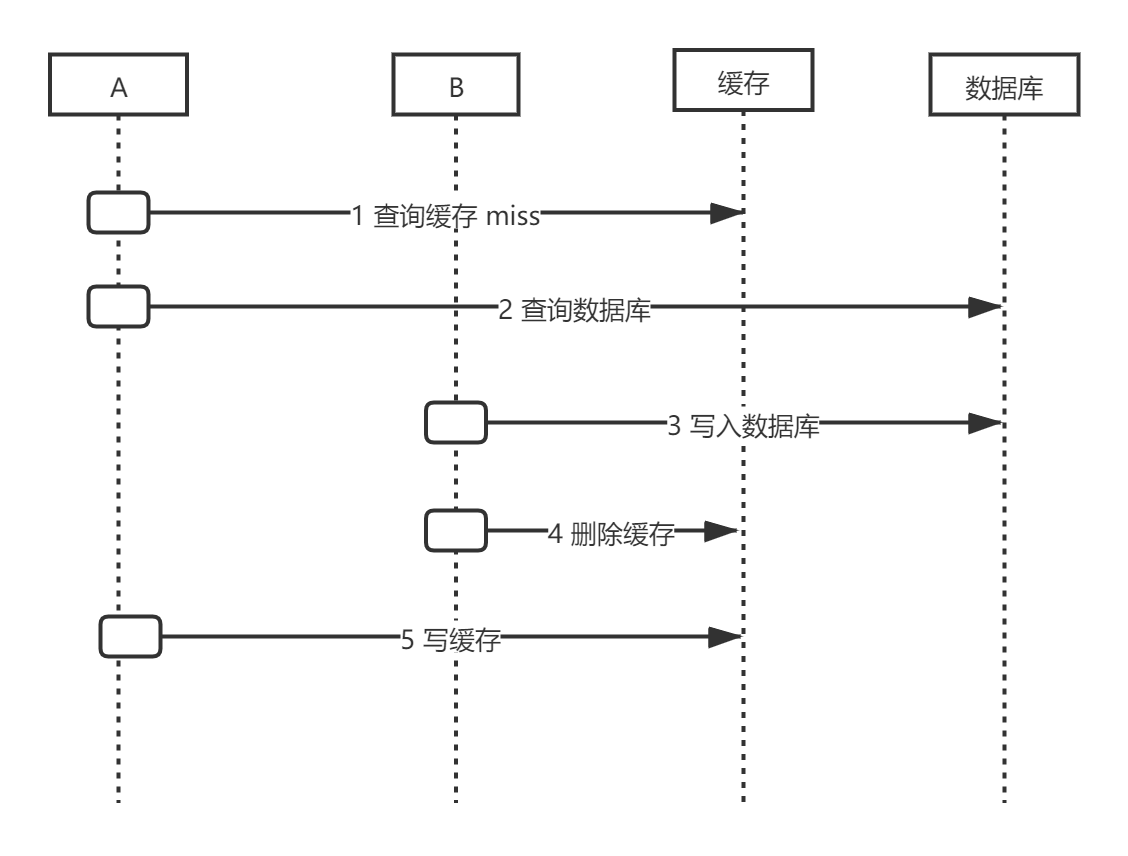
先更新数据库,再删除缓存
-
缓存刚好失效
-
请求A查询数据库,得到旧值
-
请求B将新值写入数据库
-
请求B删除缓存
-
请求A将查到的旧值写入缓存
此场景的出现有一定的限制,即步骤3写数据库操作比2数据库的读操作耗时更短,才有可能出现4优先于5执行。但是通常情况下,数据库的读操作要远快于写操作,因而上述的限制场景很难出现。
如果想实现基础的数据一致性策略,又不想增加太大工作量的情况下直接采用
删缓存、先更新数据库再删缓存
终极解决方案-缓存延时双删
CAP理论决定了不可能做到绝对的强一致性,缓存系统属于AP,可以做到最终一致性
采用延时双删+重试机制
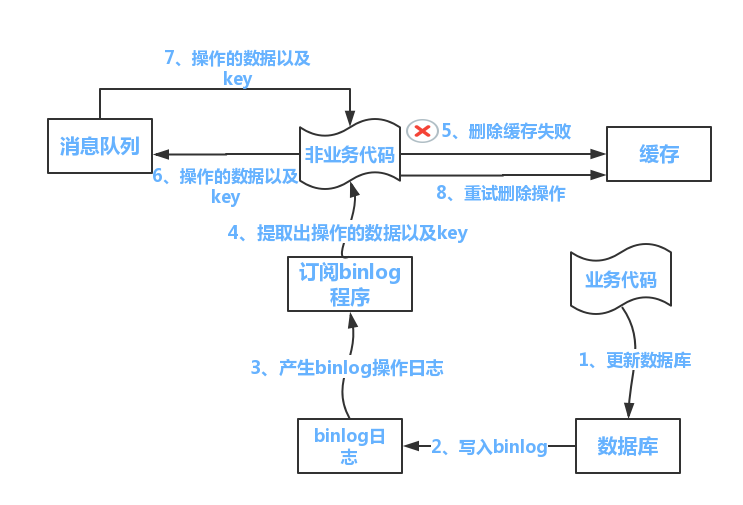
-
更新数据库
-
数据库操作日志写入binlog日志
-
订阅程序提取所需数据及key
-
另起一段非业务代码,获得该信息
-
尝试删除缓存操作、发现删除失败
-
将失败信息发送至消息队列
-
重新消费消息队列,重试操作
分布式系统中要么通过2PC或者Paxos协议保证一致性,要么就是拼命的降低并发时脏数据的概率,缓存系统适用的场景就是非强一致性的场景,所以它属于CAP理论中的AP、BASE理论,异构数据本来就没办法做到强一致性,只是尽可能减少时间窗口,达到最终一致性。最后,设置缓存的过期时间作为兜底方案。
3.4 分布式锁
-
设置key与过期时间应为原子操作
-
每个线程设置唯一的Id,保证只能释放自己的持有的锁
-
释放锁要放到finally语句块中,防止异常场景
-
可以采用分段锁提高并发场景
