MapReduce简易剖析
一、MapReduce
- 分布式计算框架
- Map(映射):指一组数据按照规则映射为一组
- Reduce(归约):汇总结果(类似SQL语言的group by)
- Shuffle(洗牌):数据根据key进行网络传输规整到一起,按规则计算。
二、MapReduce流程
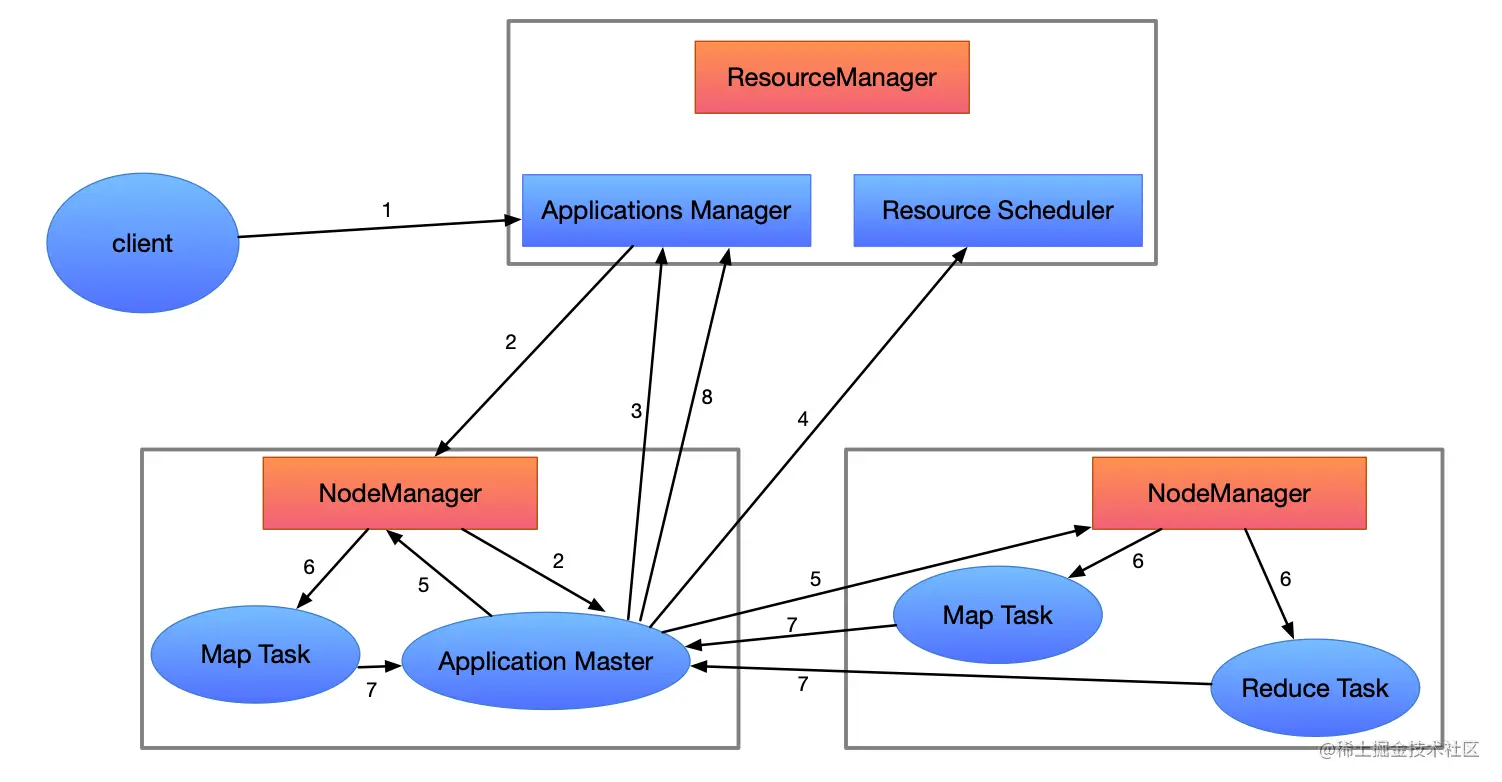
- 描述:
- 1、Client向RM提交应用程序,其中包含Application Master主程序和启动命令。
- 2、Applications Manager会为应用程序分配第一个container容器,来运行Application Master主程序。
- 3、Application Master主程序就会向Applications Manager注册,在yarn的web界面上看到job的运行状态。
- 4、Application Master主程序采取轮询的方式通过RPC协议向Resource Scheduler申请和领取资源(哪台机器、领取多少内存、多少CPU VCORE)。
- 5、Application Master主程序拿到资源的列表后,与对应的NM进程通信,要求启动container来运行task任务。
- 6、NM为task任务设置好运行的环境(container容器),将任务启动命令写在脚本里,并且通过脚本启动task任务。
- 7、各个container的task任务(map task和reduce task),通过RPC协议,向Application Master主程序进行汇报进度和状态,以此让Application Master主程序随时掌握task的运行状态。当task任务运行失败,会重启container任务。
- 8、当所有的task任务全部完成,Application Master主程序会向Applications Manager申请注销和关闭作业,这时在web界面可以查看任务是否完成,是否成功。
- 总结:
- 启动Application Master主程序,领取资源;
- 运行任务,直到任务完成。
- 注意:
- 主程序在NM节点运行;
- 主程序需要申请container容器;
- 一个作业的第一个container容器中运行主程序。
maptask决定机制
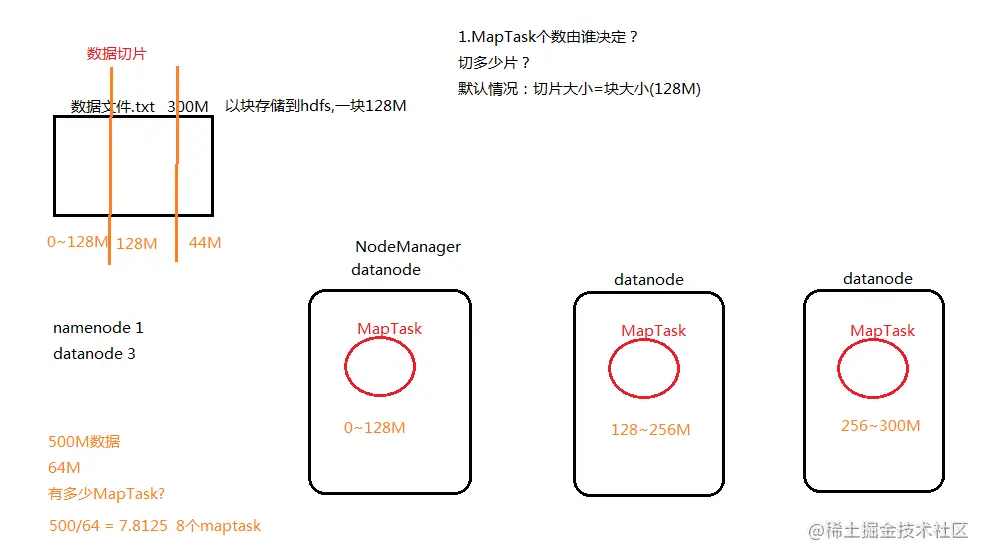
mapreduce流程——维度2
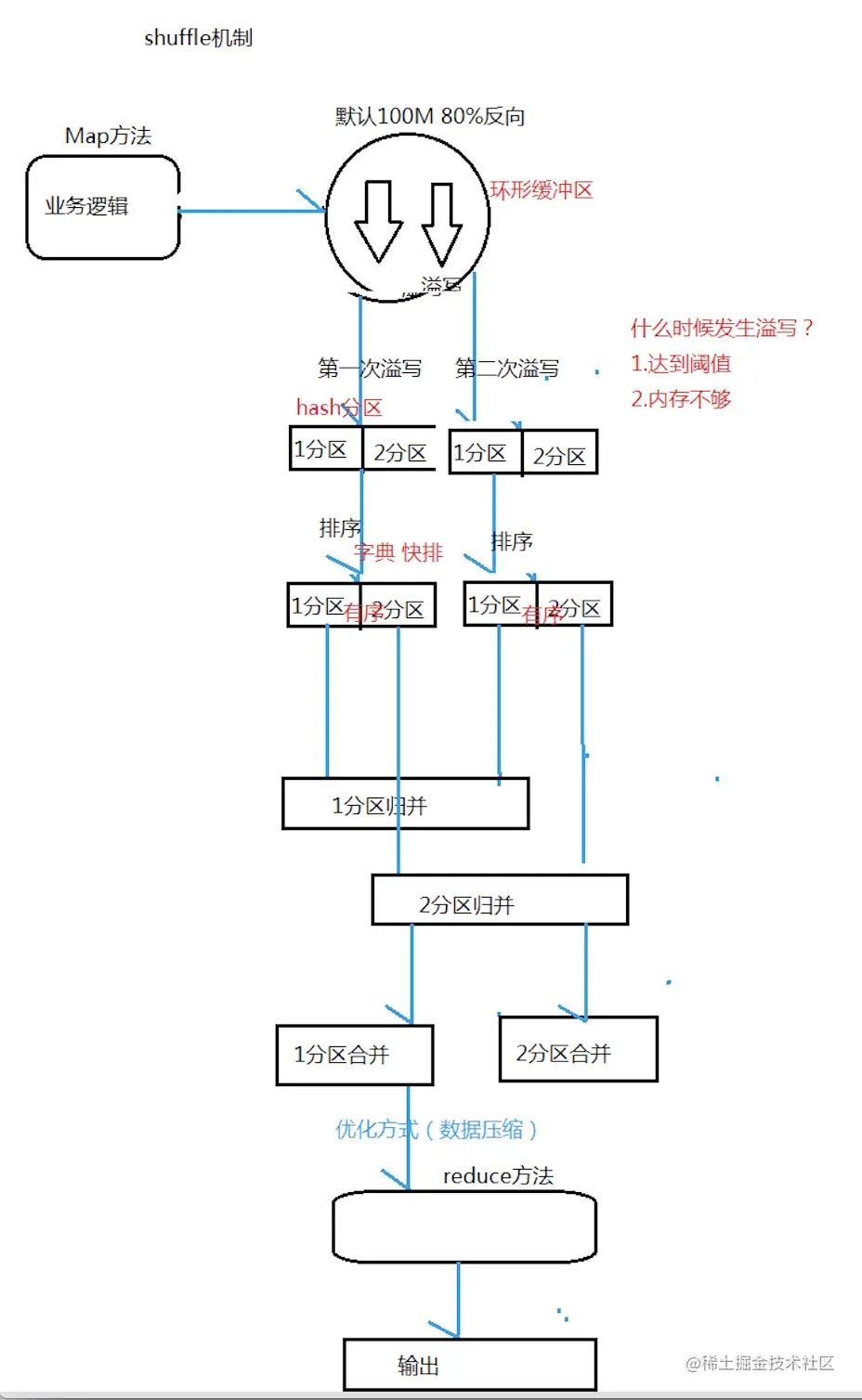
shuffle机制
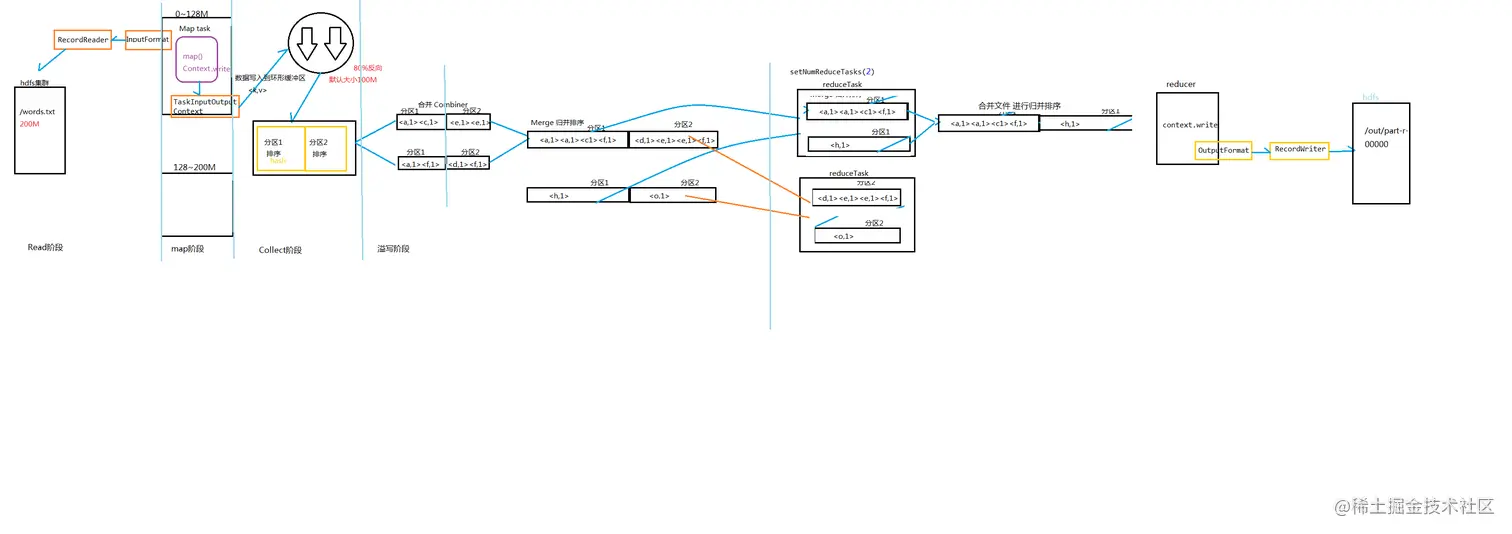
三、WordCount流程
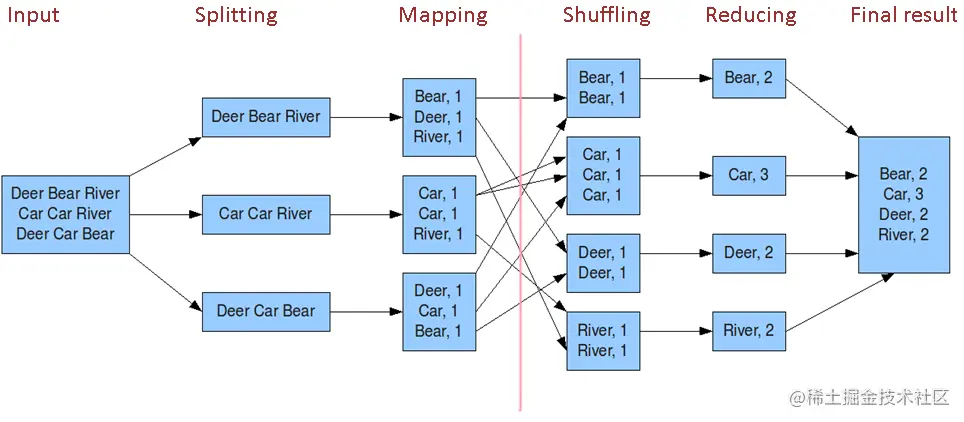
Map Task的整体流程:
- 1) Read: Map Task通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
- 2)Map:该阶段主要将解析出的key/value交给用户编写的map()函数处理,并产生一系列的key/value。
- 3) Collect: 在用户编写的map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输入结果。 在该函数内部,它会将生成的key/value分片(通过Partitioner)并写入一个环形内存缓冲区中。
- 4) Spill: 即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并,压缩等操作。
- 5) Merge: 当所有数据处理完成后,Map Task对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
Reduce Task的整体流程:
- 1) Shuffle: 也称Copy阶段。 Reduce Task从各个Map Task上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阀值,则写到磁盘上,否则直接放到内存中。
- 2) Merge: 在远程拷贝的同时,Reduce Task启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或者磁盘上文件过多。
- 3) Sort: 按照MapReduce语义,用户编写的reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现了对自已的处理结果进行了局部排序,因此,Reduce Task只需对所有数据进行一次归并排序即可。
- 4)Reduce:在该阶段中,ReduceTask将每组数据依次交给用户编写的reduce()函数处理。
- 5) Write: reduce()函数将计算结果写到HDFS。


