可以说线性代数为机器学习提供了数据表示及计算方法,而概率与统计则为机器学习算法本身的设计提供了理论依据,机器学习算法参数的求解一般均基于统计学中的频率学派或者贝叶斯学派
频率学派认为参数虽未知,但却是客观存在的固定值,故通常使用极大似然估计来确定参数。而贝叶斯学派则认为参数是未观测到的随机变量,其本身具有某种分布,故可假定参数服从一个先验分布,然后基于已有数据来计算参数的后验分布
本文将机器学习中常见的概率与统计知识做一个梳理
一. 基本概念
1.1 随机试验 (Experiment)
随机试验指试验结果存在不确定性的试验,符合三个特点:
- 可以在相同的条件下重复进行
- 每次试验结果不止一个,且能提前明确所有可能的结果
- 进行一次试验之前不能确定哪个结果会出现
1.2 样本空间 (Sample space)
样本空间是一个随机实验的所有可能结果的集合。通常记作 S (space)
举个例子
- 如果抛掷一枚硬币,那么样本空间就是 {正面,反面};
- 如果投掷一个骰子,那么样本空间就是 {1,2,3,4,5,6}
1.3 随机事件 (Random event)
样本空间中的任意一个子集称为随机事件,通常记作 E (event)
这里指的是一次实验可能出现结果的集合,而不是多次实验的集合
听起来有点拗口,举个例子:
- 事件1:投掷一枚骰子,出现点数 2 , 就是一个事件
- 事件2:投掷一枚骰子,不出现点数 2 ,也是一个事件
但很明显,事件2的出现的可能性比事件1大的多(事件2的概率比事件1大)
1.4 概率 (Probability)
对于事件 E ,我们记 P(E) 为事件 E 发生的概率
有三条公理:
- 0<= P(E)<=1 , 概率大小在0到1 之间
- P(S) =1 ,样本空间的概率为1
- P(i=1⋃nAi)=i=1∑nP(Ai)
二. 随机变量
2.1 随机变量 (Random variable)
一个随机变量,通常记作X,是一个将样本空间中的每一个元素映射到一个实值的函数。
实际上,随机变量即是将随机事件数值化的一个概念,看下图:
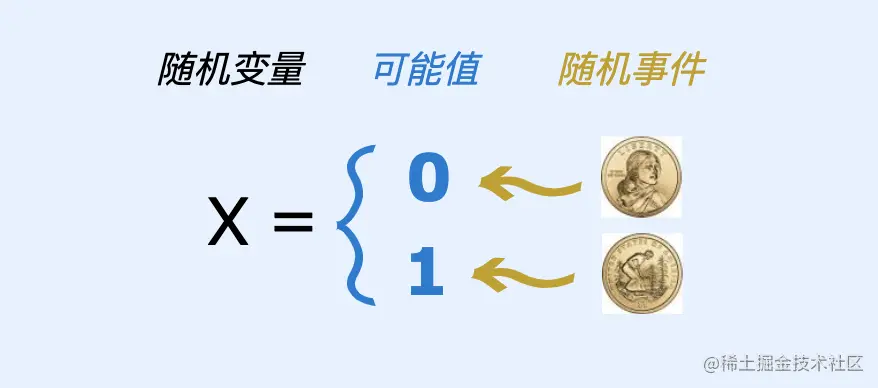
投掷一枚硬币,会出现正反面,我们将正反面表示为 0和1,此时 {0, 1} 便是随机变量的所有可能取值。实际上,我们并不一定要将硬币正反面表示为 {0, 1}, 想表示为 {-100, 20} 也可以
随机变量可分为:
- 离散随机变量:只能去某些值,例如 X = {1, 2, 3}, X 就是离散随机变量
- 连续随机变量:可以取一个范围内的任意值,例如上海的温度,人的身高
2.2 累计分布函数 (Cumulative Distribution Function, CDF)
累积分布函数定义如下:
- FX(x)=P(X≤x)
累积分布函数的性质:
- x→−∞limFX(x)=0
- x→+∞limFX(x)=1
2.3 概率密度函数 (Probability Density Function, PDF)
概率密度函数是一个描述随机变量的输出值,在某个确定的取值点附近的可能性的函数。简单理解就是,当X取到某个值时,其概率的大小
概率密度函数和累积分布函数的关系:
- 累积分布函数求导即可得到概率密度函数
- 概率密度函数求积分即可得到累积分布函数
2.4 期望 (Expectation)
一个离散性随机变量的期望是试验中每次可能的结果乘以其结果概率的总和。期望值可能与每一个结果都不相等,换句话说,期望值是该变量输出值的加权平均
例如:
掷一枚公平的六面骰子,其每次“点数”的期望值是3.5,计算如下:
- E(X)=1⋅61+2⋅61+3⋅61+4⋅61+5⋅61+6⋅61=61+2+3+4+5+6=3.5
如果 X 是连续的随机变量,存在一个相应的概率密度函数 f(x) ,若积分 ∫−∞∞xf(x)dx 绝对收敛,那么 X 的期望值可以计算为:E(X)=∫−∞∞xf(x)dx ,
是针对于连续的随机变量的,与离散随机变量的期望值的算法基本一致,由于输出值是连续的,所以把求和改成了积分
2.5 方差 (Variance) 和标准差 (Standard Deviation)
一个随机变量的方差描述的是它的离散程度,也就是该变量离其期望的距离
方差的公式:
- Var(X)=E[(X−μ)2] , 其中 μ 为 X 的期望
标准差: 方差的正平方根称为该随机变量的标准差
2.6 协方差 (Covariance)
协方差 用于衡量两个随机变量的联合变化程度。而方差是协方差的一种特殊情况,即变量与自身的协方差
协方差公式:
-
cov(X,Y)=E((X−μ)(Y−ν))=E(X⋅Y)−μν ,
其中, μ 为 X 的期望, ν 为 Y 的期望
三. 条件概率与贝叶斯定理
3.1 条件概率(conditional probability)
条件概率: 事件A在事件B发生的条件下发生的概率,记作 P(A∣B) ,在英文中读作 the conditional probability of A given B
联合概率: 表示两个事件共同发生的概率,A与B的联合概率表示为: P(A∩B) 或 P(AB)
条件概率公式: 在事件 B 发生的条件下,事件 A 发生的条件概率为:
P(A∣B)=P(B)P(AB)
3.2 贝叶斯定理 (Bayes rule)
贝叶斯定理描述 在已知一些条件下,某事件的发生概率。
贝叶斯定理的公式:
P(A∣B)=P(B)P(B∣A)P(A)
贝叶斯定理推导:
-
根据条件概率的定义,在事件B发生的条件下事件A发生的概率是:
P(A∣B)=P(B)P(AB)
-
同样地,在事件A发生的条件下事件B发生的概率:
P(B∣A)=P(A)P(AB)
-
整理与合并这两个方程,我们可以得到:
P(A∣B)P(B)=P(AB)=P(B∣A)P(A) ,
即: P(A∣B)P(B)=P(B∣A)P(A)
-
当 P(B) 不等于 0时,两边同除以 P(B) ,得:
P(A∣B)=P(B)P(AB) ,即贝叶斯公式
在贝叶斯定理中,每个名词都有约定俗成的名称,在贝叶斯理论中:
- P(A)是 A 的先验概率(Prior probability),因为它不考虑 B ;
- P(A∣B) 是给定 B 时 A 发生的概率,称其为后验概率(Posterior probability);
- 而 P(B∣A) 则是已知结果 A 时, B 的概率,称为 B 的似然性/可能性(likelihood)
贝叶斯定理最重要的应用就是贝叶斯推断,是机器学习中非常重要的部分
四. 概率分布
4.1 伯努利分布 (Bernoulli distribution)
伯努利分布,也称 0-1 分布
其概率质量函数(针对离散型分布):
期望为:
- E[X]=i=0∑1xifX(x)=0+p=p
方差为:
- Var[X]=i=0∑1(xi−E[X])2fX(x)=(0−p)2(1−p)+(1−p)2p=p(1−p)
4.2 二项分布 (Binomial distribution)
二项分布是n个独立的伯努利试验的离散概率分布。当 n =1 时, 二项分布就是伯努利分布
n次试验中正好得到k次成功的概率有概率质量函数:
-
f(k,n,p)=Pr(X=k)=Cnkpk(1−p)n−k
对于k = 0, 1, 2, ..., n,其中 Cnk=k!(n−k)!n!
期望为:
- E[X]=np
方差:
- Var[X]=np(1−p)
4.3 几何分布 (Geometric distribution)
几何分布指的是在伯努利实验中,得到一次成功所需要的试验次数X的分布
概率质量函数为:
- P(X=k)=(1−p)k−1p
期望是:
- E(X)=p1
方差是:
- Var(X)=p21−p
4.4 泊松分布 (Poisson distribution)
泊松分布描述单位时间内随机事件发生的次数的概率分布
例如:
- 某服务设施在一定时间内受到的服务请求的次数
- 某客服中心在一定时间内接到呼叫的次数
- 某台机器在一定时间内出现故障的次数
泊松分布的概率质量函数为:
期望与方差:
-
服从泊松分布的随机变量,其期望与方差相等, 同为 λ :
E(X)=V(X)=λ
4.5 正态分布(Normal Distribution)
也称高斯分布(Gaussian distribution)
若随机变量 X 服从一个位置参数为 μ ,尺度参数为 σ 的正态分布,记为:
其概率密度函数(PDF)为:
- f(x)=σ2π1e−2σ2(x−μ)2
正态分布的期望 μ 决定了分布的位置;其方差 σ2 决定了分布的幅度
4.6 指数分布(Exponential distribution)
指数分布可以用来表示随机事件发生的时间间隔
例如:
- 旅客进入机场的时间间隔
- 打进客服中心电话的时间间隔
概率密度函数为:
累积分布函数为:
- F(x;λ)=1−λe−(λx)
期望值是:
方差为:
- V[X]=λ21


