机器学习中涉及大量的矩阵运算,线性代数知识对学习机器学习非常关键,本文对机器学习中所涉及到的线性代数部分进行总结
一. 基本符号概念
1.1 标量(scalar)
标量, 是只有大小、没有方向、可用实数表示的一个量
1.2 向量(vector)
向量,是同时具有大小和方向的几何对象。向量可以表示为行向量或者列向量
a=[abc]
or
a=⎣⎡abc⎦⎤
1.3 矩阵(matrix)
一个的矩阵是一个由 m 行 n 列 元素排列成的矩形阵列。通常用大写字母表示,一个矩阵 A 从左上角数起的第 i 行第 j 列上的元素称为第 i,j 项,通常记为 Aij 。如下是一个3行4列的矩阵:
A=⎣⎡1−1042944−1981⎦⎤
方阵:行数与列数相同的矩阵称为方阵
对角矩阵:如果一个方阵只有主对角线上的元素不是0,其它都是0,那么称其为对角矩阵
单位矩阵:如果一个对角矩阵的主对角线元素都是1, 那么该矩阵就是单位矩阵
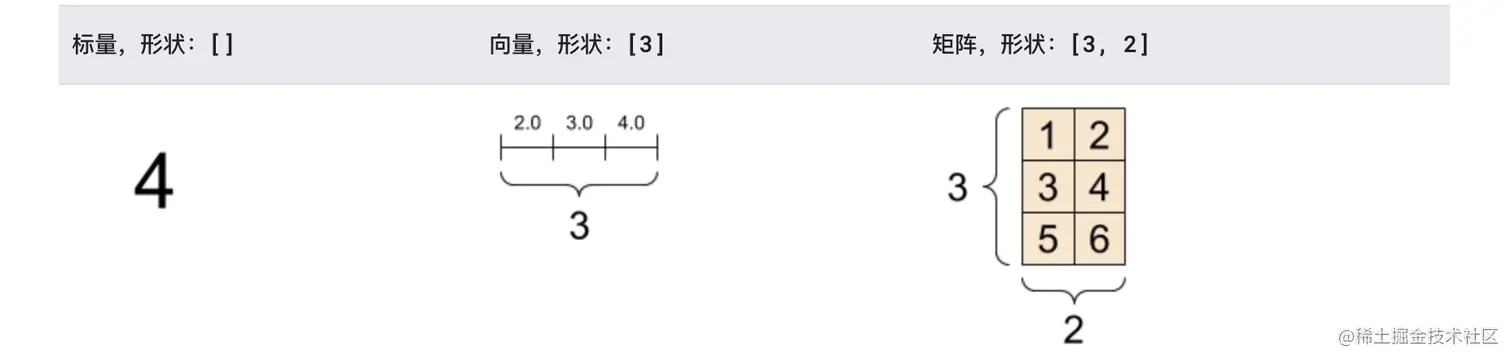
1.4 张量(tensor)
张量可以看作是多维数组,它们是标量,1维矢量和2维矩阵的多维推广。
参考TensorFlow文档,可认为:
- 标量可称为 "0 秩" 张量,包含单个值,没有轴
- 标量可称为 "1 秩" 张量, 包含一个值得列表,有一个轴
- 矩阵可称为 "2 秩" 张量,有 2 个轴
下图非常形象的阐述了上述内容:
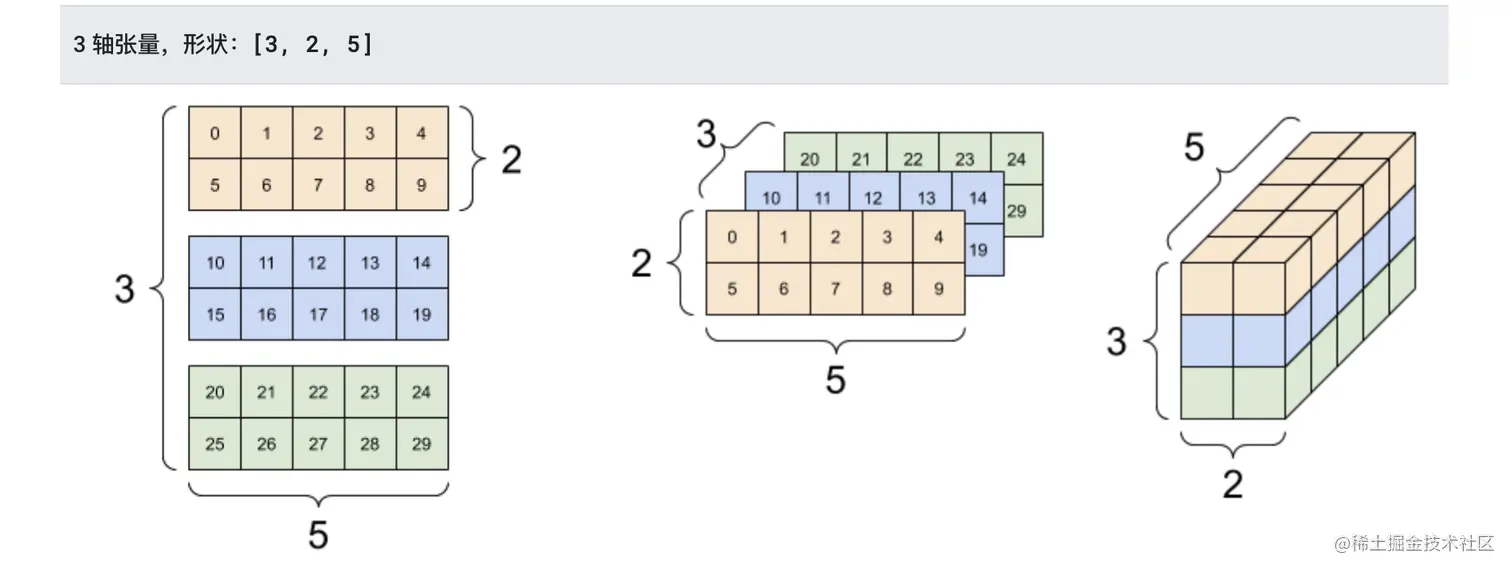
而张量的可视化,下图是同一个3轴张量的3种可视化方式:
二. 运算
2.1 向量内积
内积 (dot product),也称点积,数量积,其结果是一个标量
两个 向量 a=[a1,a2,⋯,an] 和 b=[b1,b2,⋯,bn] 的点积定义为:
a⋅b=i=1∑naibi=a1b1+a2b2+⋯+anbn
2.2 向量外积
外积 (outer product),在线性代数中一般指两个向量的张量积,其结果为一矩阵,举例如下:
⎣⎡b1b2b3b4⎦⎤⊗[a1a2a3]=⎣⎡a1b1a1b2a1b3a1b4a2b1a2b2a2b3a2b4a3b1a3b2a3b3a3b4⎦⎤
2.3 矩阵乘法
若 A 为 m×n 矩阵,B 为 n×p 矩阵,则他们的乘积 AB 会是一个 m×p 矩阵。其乘积矩阵的元素如下面式子得出:
(AB)ij=r=1∑nairbrj=ai1b1j+ai2b2j+⋯+ainbnj
用图示来表示即为:
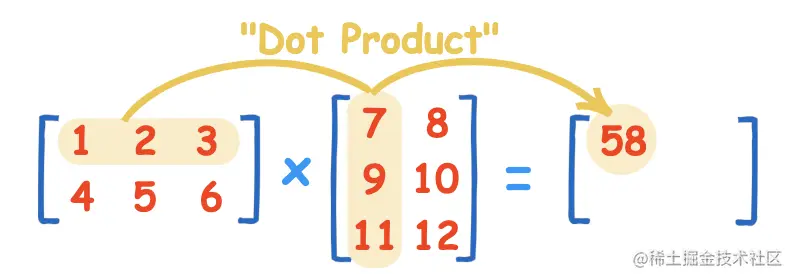
可以认为,矩阵乘法是向量内积的一个拓展,对相对应的行和列向量进行内积(点积),即可得到矩阵在相应位置的元素
2.4 矩阵转置
转置(transpose),表示为 AT ,即把矩阵 A 的横行写为其纵列,把 A 的纵列写为其横行。数学表示为:
AijT=Aji
举例如下:
⎣⎡135246⎦⎤T=[123456]
2.5 逆矩阵
逆矩阵 (inverse matrix),给定一个n阶方阵 A ,若存在一n阶方阵 B ,使得 :
AB=BA=In ,
其中 In为 n 阶单位矩阵,则称 A 是可逆的,且 B 是 A 的逆矩阵,记作 A−1 只有方阵(n×n 的矩阵)才可能有逆矩阵。若方阵 A 的逆矩阵存在,则称 A 为非奇异方阵或可逆方阵
三. 矩阵分解
3.1 特征值和特征向量
给定一个方阵 A, λ 被称为 A 的一个特征值(eigenvalue),当存在一个向量 v 满足
Av=λv,
此时, v 是 A 的特征向量(eigenvector)
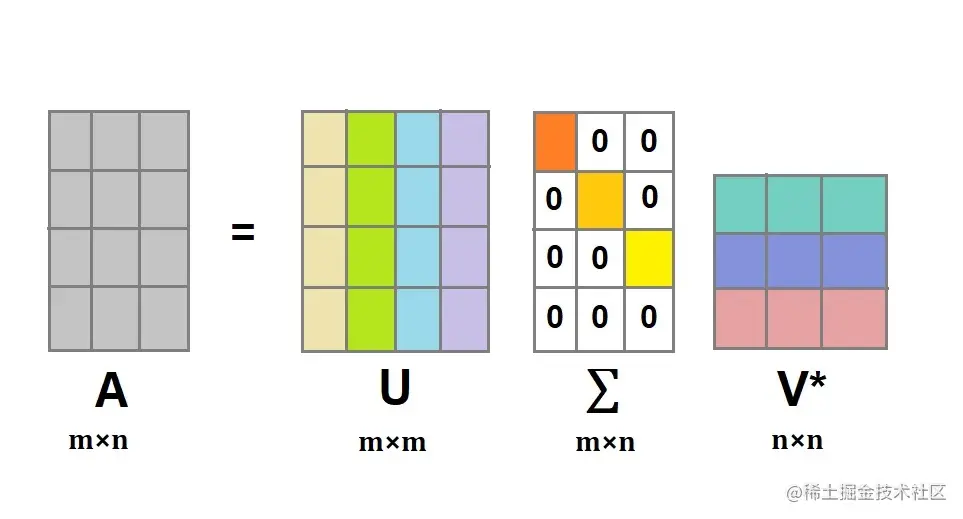
3.2 奇异值分解
奇异值分解(singular value decomposition, SVD) 分解能够用于任意 m×n 矩阵,而特征分解只能适用于特定类型的方阵,故奇异值分解的适用范围更广
假设 A 是一个 m×n 阶矩阵,我们定义 A 的奇异值分解为
A=UΣV∗,
其中 U 是 m×m 阶矩阵;Σ 是 m×n 阶; V∗是 n×n 阶矩阵; U 和 V∗都是酋矩阵,即满足 UTU=I , V∗TV∗=I , Σ 是除了主对角线上的元素以外全为0,主对角线上的元素称为奇异值。
下图很形象的展示了SVD:
 在机器学习中,用于降维的算法PCA非常常用,其在计算过程中可以转化为SVD,从而降低计算复杂度。除此之外,SVD在推荐系统中也几乎不可缺少
在机器学习中,用于降维的算法PCA非常常用,其在计算过程中可以转化为SVD,从而降低计算复杂度。除此之外,SVD在推荐系统中也几乎不可缺少
3.3 奇异值分解的计算
给定一个 M 的奇异值分解,根据上面的论述,两者的关系式如下 (其中 M∗ 是 M 的共轭转置矩阵(转置矩阵推广到复数)):
-
M∗M=VΣ∗U∗UΣV∗=V(Σ∗Σ)V∗
-
MM∗=UΣV∗VΣ∗U∗=U(ΣΣ∗)U∗
关系式的右边描述了关系式左边的特征值分解。于是:
-
V 的列向量(右奇异向量)是 M∗M 的特征向量。
-
U 的列向量(左奇异向量)是 MM∗ 的特征向量。
-
Σ 的非零对角元(非零奇异值)是 M∗M 或者 MM∗ 的非零特征值的平方根。
故通过计算出 M∗M 的特征向量和特征值, MM∗ 的特征向量和特征值, 即完成了对 M 的奇异值分解
四. 距离及相似度量
4.1 曼哈顿距离
也即 L1 范数,定义为:
∥x∥=i=1∑n∣xi∣ ,
其在机器学习中最常见的应用即 L1 正则化,也称 Lasso
4.2 欧氏距离
也称 L2 范数,定义为,各元素平方的和,表示为:
∥x∥2=i=1∑nxi2=x12+⋯+xn2 ,
其应用为 L2 正则化,也称 Ridge
L1 和 L2 正则化在机器学习模型中应用极为广泛,主要用于降低模型复杂度,减小过拟合
4.3 Lp 范数
Lp 范数定义为:
∥x∥∞=p→−∞lim(i=1∑n∣xi∣p)1/p=imin∣xi∣ ,
当 p 取不同值时,我们可以得到不同的范数
-
p=1 时:∥x∥1=i=1∑n∣xi∣ ,即 L1 ,范数是向量各分量绝对值之和,又称曼哈顿距离
-
p=2 时: ∥x∥2=i=1∑n∣xi∣2 , 即 L2 ,此时为欧式距离
-
p=+∞ 时: ∥x∥∞=p→+∞lim(i=1∑n∣xi∣p)1/p=imax∣xi∣,此即最大范数,也称切比雪夫距离
4.4 余弦相似性
给定两个向量 A 和 B ,其余弦相似性 θ 由点积和向量长度给出,如下所示:
similarity=cos(θ)=∥A∥∥B∥A⋅B=i=1∑n(Ai)2×i=1∑n(Bi)2i=1∑nAi×Bi,
余弦相似度取值范围为 [−1,1] ,−1 意味着两个向量指向的方向正好相反,1 表示它们的指向是完全相同的,0 通常表示它们之间是独立的,而在这之间的值则表示中间的相似性或相异性,值越大,相似度越大
4.5 汉明距离
汉明距离(Hamming distance) 是指将一个字符串变换成另外一个等长字符串所需要替换的字符个数
例如 "touch" 和 "teach" 之间的汉明距离为 2
4.6 Jaccard 相似系数
其定义为两个集合交集大小与并集大小之比:
J(A,B)=∣A∪B∣∣A∩B∣=∣A∣+∣B∣−∣A∩B∣∣A∩B∣
Jaccard 相似系数取值范围为:0≤J(A,B)≤1
Jaccard 距离 则用于量度样本集之间的不相似度,其定义为1减去雅卡尔系数,即:
dJ(A,B)=1−J(A,B)=∣A∪B∣∣A∪B∣−∣A∩B∣
4.7 皮尔逊相关系数
两个变量之间的皮尔逊相关系数定义为两个变量的协方差除以它们标准差的乘积:
ρX,Y=σXσYcov(X,Y)=σXσYE[(X−μX)(Y−μY)]
皮尔逊相关系数的变化范围为 [−1,1]。
系数的值为 1 意味着 X 和 Y 可以很好的由直线方程来描述,所有的数据点都很好的落在一条直线上,且 Y 随着 X 的增加而增加。
系数的值为 −1 意味着所有的数据点都落在直线上,且 Y 随着 X 的增加而减少。
系数的值为 0 意味着两个变量之间没有线性关系
持续总结和分享机器学习,数据科学方面的知识,欢迎小伙伴们交流讨论...


