

本文介绍 万字长文盘点2021年paper大热的Transformer(ViT)
万字长文盘点2021年paper大热的Transformer(ViT)
This article was original written by Jin Tian, you are welcomed to repost, first publish at blog.tsuai.cn. Please keep this copyright info, thanks, any question could be asked via wechat:
jintianiloveu
很久未写文章了,在这之前,请允许我打个广告,由于github.io再也无法舒适的访问了(因为你懂得原因),我将博客指向了我的国内域名:blog.tsuai.cn , 不定期的会更新一些技术文章,感兴趣的朋友可以了解一下,当然你也可以关注我的知乎账号,我也会不定义的再知乎更新.
这篇文章主要是一篇Medium文章的翻译,但我会加入一些我自己的理解和查阅的资料补充知识点,希望给大家一个transformer使用的全貌,水平有限,如有不足还请友情指点.原文地址在最下方参考链接处.
很多时候提到transformer大家肯定会想到facebook的那篇DETR,而我更想从这篇文章开始,也就是来自谷歌大脑团队的这篇:一张图片值16x16个字:
为什么想从这篇文章开始呢?因为这是谷歌大佬的论文.这篇文章讲的不是注意力机制简单的嵌套改改模型骨干去跑benchmark, 也不是讲如何将transformer用在某个特定的任务,而是探究了视觉任务本身,如何将其从传统的CNNs当中剥离,并且达到现有的高度,是一篇2021年必看的论文.在讲解谷歌大脑团队如何牛逼之前,我们先来做一个总结吧.看看过去的一年中,在视觉领域(包括3D点云)大家都用它来干啥了.
01. Transformers in NLP
开始之前,还是回顾一下transformer在NLP领域的巨大成功吧!相比搞NLP的同学应该或多或少都认同一个观点:Transformer已经成了NLP的标配,有多标配?就比如我3年前搞NLP的时候LSTM统一天下一般.大名鼎鼎的GPT-3也是基于transformer的巨大模型,并获得了NIPS2020最佳论文奖.
那么在2021年的视觉领域,transformers也会像在NLP领域一样如日中天吗?事实上,使用transformer进行视觉任务的研究已经成了一个新的热点,大家为了更低的模型复杂度以及训练的效率,都在研究如何将这一技术应用在视觉任务上.
02. Transformers in CV 2020
在过去的一年里,至少这几篇论文是很有用的工作,他们就是在于transformer构建的模型,并且在各方面的指标上超越了许多领先的传统方法:
- DETR: End-to-End Object Detection with Transformers, 使用transformer做目标检测的端到端的方法;
- ViT: AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE, 探讨transformer应用于基础的视觉任务,比如分类任务;
- Image GPT: Generative Pretraining from Pixels: 使用transformer进行图像填补;
- LDTR: transformers for lane detection: 使用transformer进行车道线检测.
通常来说,有两个比较大的架构,在所有的关于transformer的论文以及工作中,其中一个就是传统的CNNs加transformer组合而成的结构,另一种是纯粹的Transformers.
- 纯粹的transformers;
- 混合的transformers.
其中ViT那篇论文,也就是开头讲到的谷歌大脑的那篇,使用的就是纯粹的transformer去完成视觉任务,也就是说,它没有使用任何的CNNs. 我知道你现在很想知道这句话是什么意思,为什么说没有用到任何CNNs,别着急,我会在本文的最后一个内容讲解这个东西,有时间我会做一起视频,结合谷歌开源的代码来和大家一行代码一行代码去推敲,为什么.但现在大家只要知道它是一个纯粹的transformer就可以了.
那什么东西是混合的transformer呢?比如DETR这篇论文,它实际上是采用了transformer的一个思想,但在特征提取的骨干网络上,并没有太多的变化.我们可以称之为混合型的transformer.
写到这里,很多好奇的宝宝就会产生很多问题了:
- 为什么要在视觉里面用它?怎么用?
- 和现有的结果对比效果怎样?
- 有什么约束挑战吗?
- transformer的结构千奇百怪,有什么典型的同时兼顾精度和高效率的结构吗?为什么呢?
很好,你已经学会了问问题,而这些问题都将不是本文要解答的内容,因为过于硬核.但我会尝试深入谷歌大脑的ViT,去和大家一起弄清楚这些问题的答案.事实上,要弄清楚其中一个和很基础的问题,我们需要把场景切换一下,先来看看如何展示以一个transformer,并且知道注意力机制为什么有用.
关于讲解transformer的视频,我这里推荐一个YoutuberUP主的视频,但是由于你懂得原因,你可能无法观看,于是我废了九牛二虎之力将其搬运到了Bilibili,就充这个严谨,大家可以给我可怜的B站账号点个赞,同时关注一波,现在只有5个粉丝,可怜.
言归正传了,关于注意力机制,仍然是主推这篇论文:attention is all you need, 链接请看脚注.有童鞋可能会问,你发的貌似都是讲NLP的视频和论文,和视觉怎么联系起来呢?没错,我们现在讨论的transformer, 其实就是NLP里面的transformer.
接下来我们就进一步的讲解一下ViT.
03. Vision Transformer
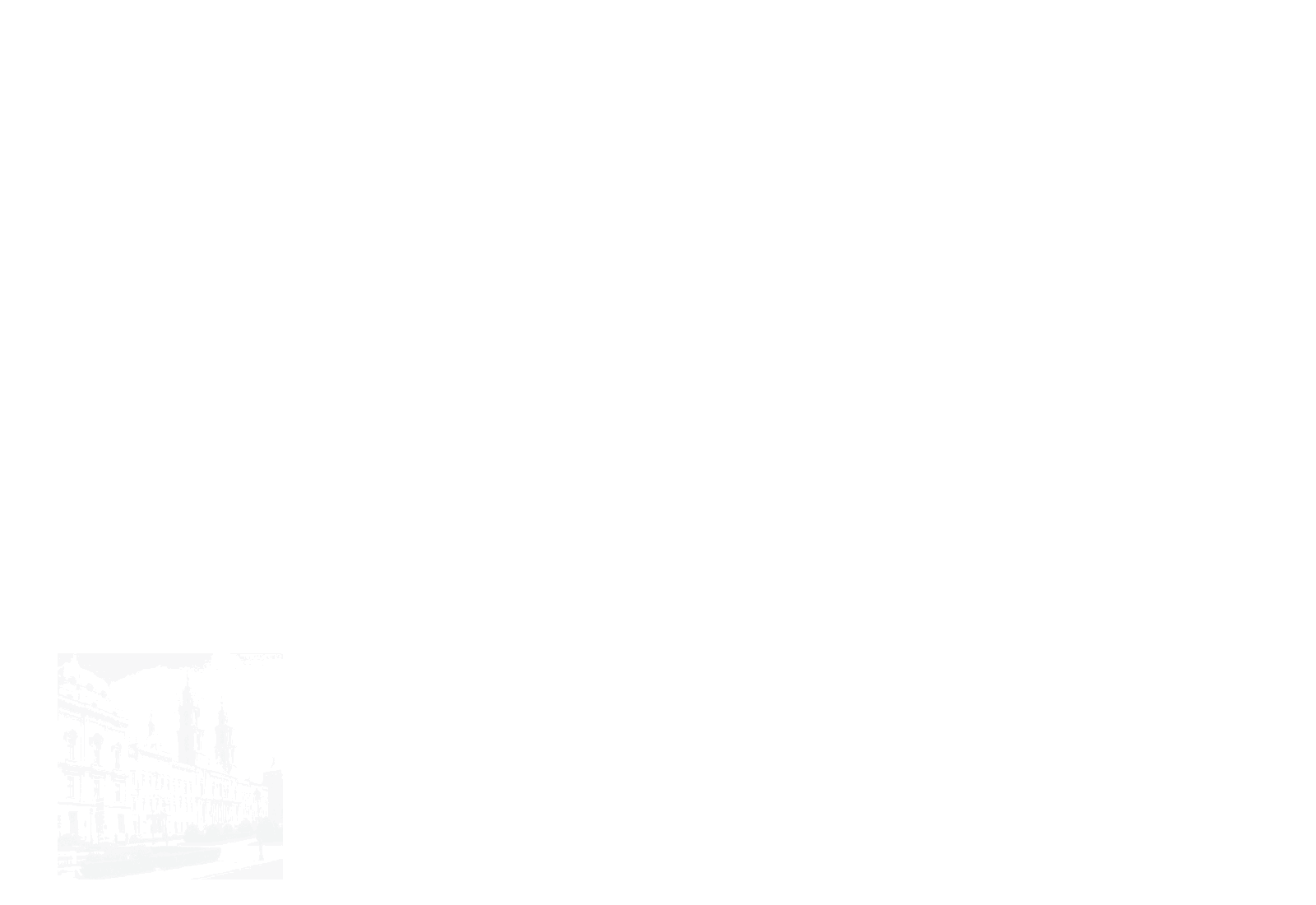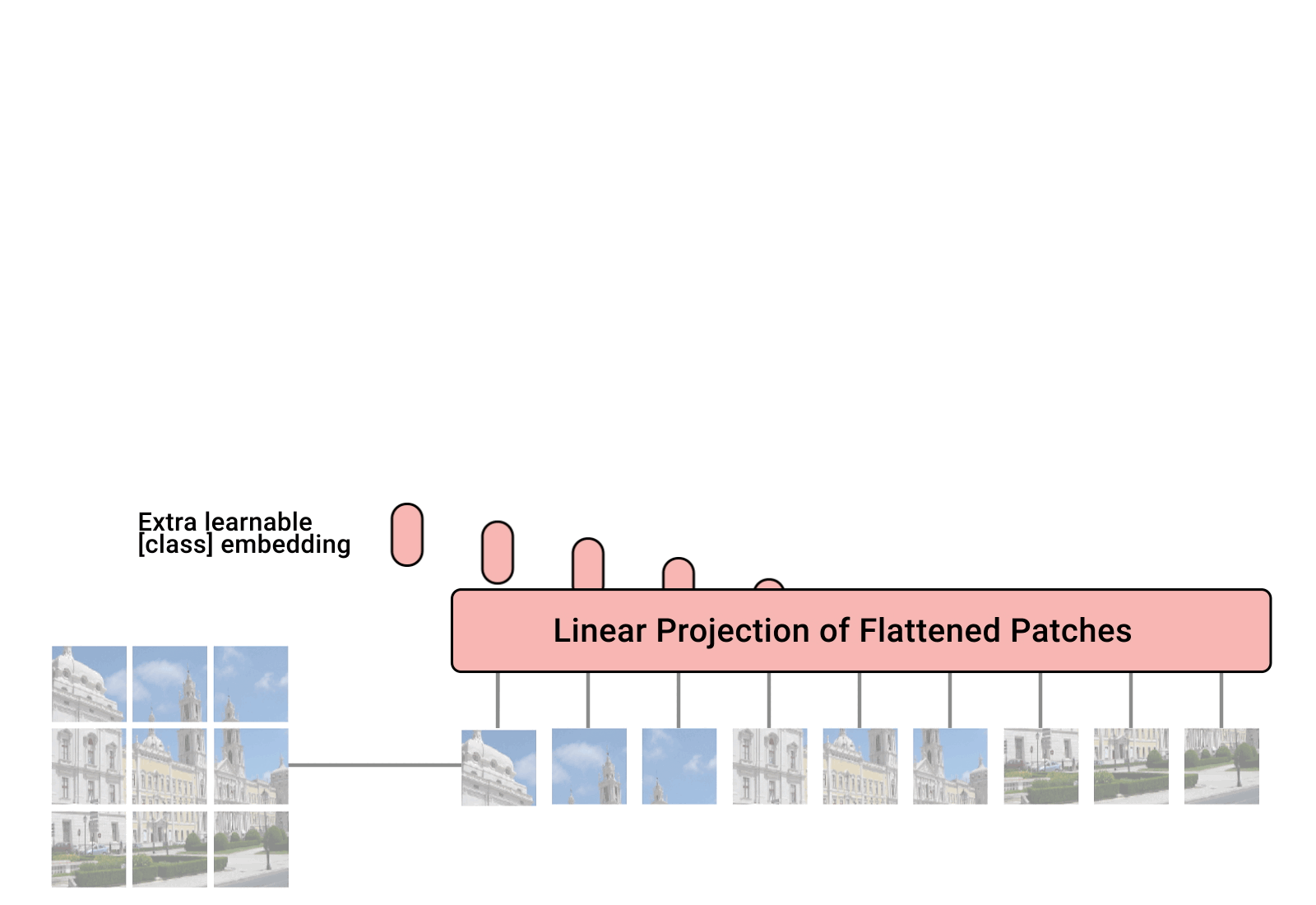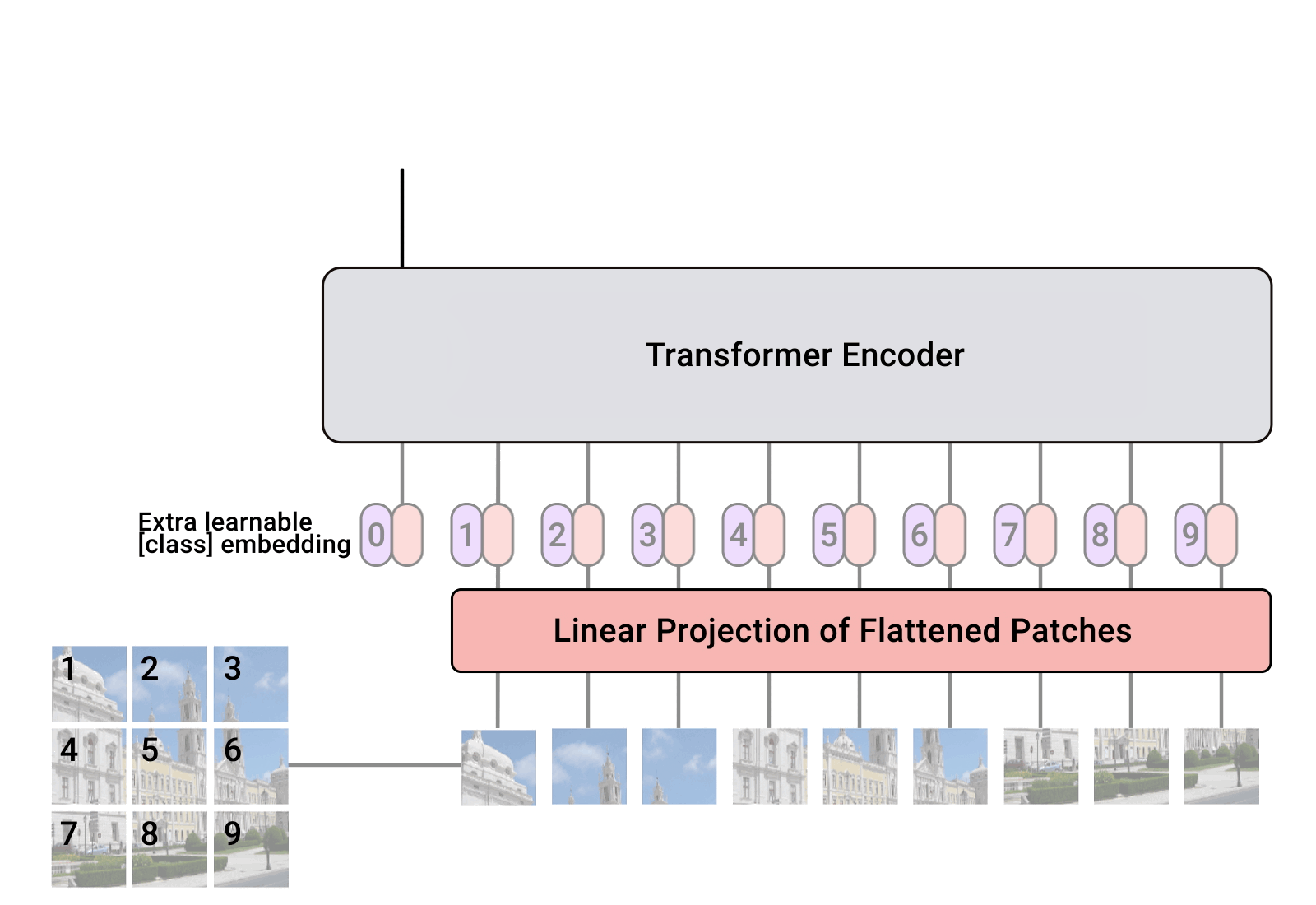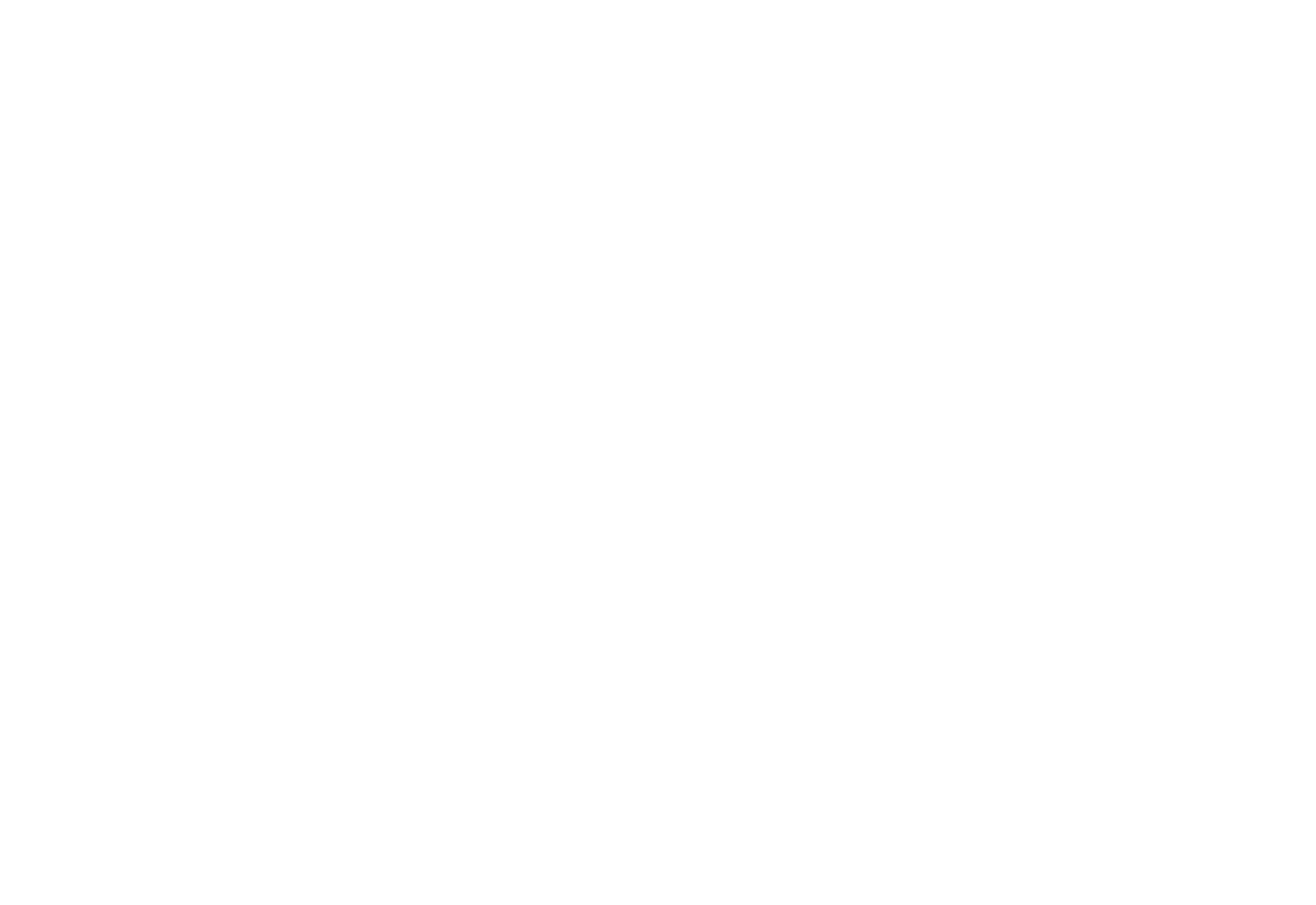
这是谷歌大脑那篇论文中的一张图.回到文章一开始提出来的问题,为什么我要拿这篇文章来讲解transformer.如同我在上一节提到的,transformer分为纯粹与混合,而这篇文章,是第一篇纯粹讨论并使用transfomer来进行视觉基础任务(分类)的论文.
这也是它的价值所在,谷歌大脑团队在几乎没有修改任何基于NLP的transformer的结构基础之上,只是将输入进行了一个适配,将图片切分成许多的小格,然后将这些作为序列输入到模型,最终完成了分类任务,并且效果可以直追基于CNNs的SOTA.
他们的做法也十分的简单,将图片切分可以完美的构造成一个序列的输入,几乎可以无缝的接入到transformer的输入中.而为了进一步的保持这些小格子之间的局部与整体关系,对于每一个patch都保持着和原图对应的编号.这可以很好的保持空间和位置的信息,即便在打乱他们的顺序之后这些信息也可以得到保留.当然在论文的源文中,他们也做了使用和不使用这个空间编码方式的对比实验,感兴趣的同学可以仔细阅读原文看看.
这篇论文也直接和传统的CNNs进行了对比,他们在不同的数据集上进行了预训练, 比如:
- ILSVRC-2012 ImageNet, 包含1k类别和1.3M图片;
- ImageNet-21k 包含21k的类别, 14M图片;
- JFT包含18K类别,以及303M高分辨率图片.
这些数据集之大,达到了前所未有的地步,以至于他们训练时间单位不是Days, 而是k days:
2.5k天,如果不是谷歌大佬谁能做这样的论文,哎.我们来看看ViT的效果,事实上,ViT的模型也和BERT一样,我甚至认为谷歌其实一直想做一个和BERT一样的工作,在视觉领域,二者的确也被谷歌的研究者们很好的结合在了一起.他们的模型分为,Large, Base, Huge. 在Large的模型上,它的精确度已经超越了Resnet152x4. 而且看起来训练的时间更短.
这篇文章的一个有趣的结论,也是我们的直觉,transformer在数据的尺度不大的时候,表现是不好的.话句话说,训练一个transformer需要一个足够大的数据集.
这张图可以看出,当数据的数量不够的时候,它的精确度也不够好.
我们之前讲到,对于transformer的结构,我们有完全替代CNNs的ViT, 我们也有部分替代的DETR这样的结构,那么到底什么样的架构是最优的呢?谷歌的这张图,也给我们揭示了一些答案:
- 纯粹的transfomer结构,更加的高效,并且可扩张性更好,相比于传统的CNNs优势明显,不管是small,还是large的尺寸,效果都更好;
- 混合的结构在小尺度的时候效果比纯粹的结构要好.这可能是由于transformer不仅需要更大的数据,同时也需要更大的结构,但是它的上限值更高.
04. DETR
这篇文章是第一篇使用transformer做目标检测的论文,当然它是我们前面所述的混合类型的模型.放到今天来看,DETR也存在一些缺点,尽管它在指标上可以达到FasterRCNN这样的水准,比如它在小物体检测上表现出一些能力不足的迹象,而现如今也有一些论文去改进它,比如DeformableDETR, 感兴趣的同学可以仔细看看他们,但这些改进不是本文的核心要点,我们还是来回顾一下DETR里面使用transformer的思想.
这个模型的特点是:
- 使用传统的CNN来学习2D的特征表征,同时抽取特征;
- CNN的输出被平铺出来,用来提供给transformer作为输入,这个平铺包含了特征的位置编码信息;
- transformer的输出,解码器的输出,被用来输入到一个FNN之中,然后预测类别和框.
这样的结构,相比如传统的目标检测,至少终结掉了achor的设定,并且去掉了冗余的NMS. 这些手工的操作被摒弃,尽管他们在现如今的目标检测算法中仍然发挥出巨大的作用.
DETR真正牛逼的地方,其实不是它在目标检测的效果,而是当我们把它扩展到全景分割上所展示出来的惊人效果:
那么他们是怎么做的呢?全景分割实际上是两个任务,一个是语义分割,这个任务将类别和每个pixel对应起来,另一个是实例分割,这个任务会检测每个目标,并且将这些目标区域分割出来.而DETR将这二者结合到了一起,并且展示出了令人惊奇的效果.
在这篇论文中,一个有趣的boners是来自于这个算法对于重叠目标的区分能力,这其实也反映出了注意力机制的巨大作用,而transformer本身就是一个巨大的注意力机制引擎.比如他们可以很好的区分这些高度重叠在一起的物体:
05. Image GPT
回到我们一开始讲到的OpenAI的DELL-E, 这个工作展示了transformer的强大能力,然而在这之前,他们就已经做了一些相关的工作,其中的Image GPT就是一个基于GPT-2构建的图片填补模型.在这里我需要插一句,正如同Le-CUN所说,transformer真的很擅长来做填补的工作,仿佛他们天生就是如此.
Image GPT使用图片的像素序列来生成图片,它可以递归的来预测图片中的下一个像素.Image GPT的工作亮点是:
- 使用了和GPT-2一样的transformer模型;
- 非监督的学习;
- 需要更大的计算量,如果我们需要更好的特征表示;
事实上,OpenAI可能就是基于这一工作,再结合文本的GPT-3, 完成了令人经验的DELL-E.
总结
我们在这篇文章中回顾了一些比较著名经典的transformer的工作,它展示了一个全新的视觉方向.这可能也是2021的一个重要的主线之一.
写这篇文章还有一个目的,不仅仅是总结,更多的是启发大家一个方向,这个结构完全不同于传统的CNNs,它赋予模型的是全新的表达局部与整体,甚至是时域和空间的关系,GPT3的成功也暗示我们这个方向可能如同CNNs一样,开启一个全新的视觉时代,因为它能够让超大规模训练成为可能,并且可以像BERT一样成为所有其他任务的预训练基石. 在我写这篇文章的时候,OpenAI刚刚发布他们的新一代文本到图片生成模型,DELL-E,这个模型展示了模型如何深刻学习到自然语言与图形的关系,并且二者完美的融合与应用,也进一步启发我们:也许基于这个全新的架构,未来的视觉学习到的不仅仅是纹理等的特征,而可能进一步的学习更高阶的信息,比如和自然语言联系起来的模型,试想现在的目标检测只告诉你这里是0 or 1 or 2 or 3, 以后的目标检测可能直接告诉你这是table, 这是apple, 剩下的让模型来推理.
总而言之,对于一些新的技术热点,我们还是要充满想象力的.在不远的未来,或许视觉任务也可以像GPT3一样,真正的接近人的推理特征,这或许是技术迭代的转折点.
关于更多的transformer的细节以及代码解读,我会在后面的章节中继续为大家讲解,觉得有用的老铁可以关注一波我的知乎账号,并点个赞,牛年快乐.
Reference
- SOURCE: towardsdatascience.com/transformer…
- DETR: arxiv.org/pdf/2005.12…
- ViT: arxiv.org/pdf/2010.11…
- Image GPT: cdn.openai.com/papers/Gene…
- Attention is all you need: arxiv.org/pdf/1706.03…
