

- 原文地址:Hunting for the Optimal AutoML Library
- 原文作者:Aimee Coelho
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:zhusimaji
- 校对者:regon-cao、lsvih
寻找最优化 AutoML 库
在过去的几年中,关于如何自动化构建机器学习模型已经有了大量的研究。现在业内有许多提供了 AutoML 功能的开源库。这些库之间存在何种联系,更重要的是,如何去比较他们的优劣?为此,我们需要一个独立的团队基于广泛的数据集在可控的条件下测试所有软件包。
Marc-André Zöller 和 Marco F. Huber 的论文,Benchmark and Survey of Automated Machine Learning Frameworks,已经进行全部的基准测试。我们发现他们的测试方案非常有趣,这也是我们想在这里分享的。请注意:
一般来说,除网格搜索之外的所有算法都会生成性能相似的模型。

AutoML 定义
首先,确定我们即将讨论研究的 AutoML 究竟包括哪些内容。这是一个非常宽泛的术语,可能意味着机器学习项目中的所有内容,从数据清理和特征工程到超参数搜索,再到部署,生产以及后续模型的增量更新和部署。
在本文中,我们将讨论可以构建数据预处理,模型选择和超参数调整的工作流的 AutoML 工具。
我们可以将此流程分解为以下步骤:结构搜索以及组合算法选择和超参数搜索(CASH),如图1所示。
![图 1: 机器学习管道的自动创建可以分为对管道结构的搜索以及组合的算法选择和超参数优化。[1]](https://cdn-images-1.medium.com/max/2000/0*xrpOs9x1LxmjK6xT)
在本文中,他们将工具分成了以下几部分:执行 CASH 和 维持一个线性管道,如图 2 所示;能够搜索更复杂的管道的,包括平行分支和数据重组,如图 3 所示。以上就是图 1 中的结构搜索。
![图 2: 固定管道的示例,包括数据预处理以及模型选择和调整。这是本文中基准的所有 CASH 工具创建的管道。[1]](https://cdn-images-1.medium.com/max/2000/0*DbRoH4JKItL7d-IY)
![图 3: 专为特定任务设计的更复杂管道的示例。这种类型的管道是由本文中基准的 AutoML 平台创建的。[1]](https://cdn-images-1.medium.com/max/2000/0*Tn6lLnLFi5nzb1wm)
他们在实验过程中发现 CASH 算法的性能更好。我们将在这里重点介绍这些工具。
算法概述
可用于超参数搜索的算法总结如下:
网格搜索和随机搜索
首先最简单的方法:对超参数值进行网格搜索操作简单,可以帮你快速找到最佳模型参数。
接下来是随机搜索,按照指定分布和范围内生成超参数的随机组合。
如图 4 所示,这样做的好处就是不会丢失最优解(如果它们介于两个网格点之间),如果无限期运行,则将任意接近最最优解,这与网格搜索不同。
对于网格搜索和随机搜索,作者都选择了 scikit-learn 实现。
![图 4: 在超参数搜索中使用固定的网格可能会丢失某些超参数的最佳值,这中情况在高维搜索中变得更加明显。[2]](https://cdn-images-1.medium.com/max/2000/0*TmRzOwAVCP55ZG90)
基于序列模型的优化搜索
因此我们有了一系列模型优化方法 (SMBO)。 算法目标是在评估完成时从中学习,类似于数据科学家如何构造超参数搜索。这些算法在每次评估后都会学习一个替代模型,然后使用一个查询函数来查询替代模型,以决定下一个评估点。查询代理模型比训练模型以获取真实的性能值要快得多。
基于模型的优化技术旨在学习搜索空间中最优解区域,并进行探索以找到最好的模型。
实验 假设一个简单的二维二次函数,其最小值为 X_0 = 50 和 X_1 = -50。当使用贝叶斯优化时,首先基于 10 个随机配置评估并且学习替代模型后,随后的评估就开始朝着最小值逐渐聚拢。 在图 5 的左侧绘制了该目标函数,在右侧绘制了 — 序列点的选择由 scikit-optimize 中的贝叶斯方法和高斯过程选取得到 -- 随着迭代次数增加,从紫色变为红色,会不断的逼近最小值。

替代模型有不同的选择,包括高斯过程,随机森林 and Tree Parzen 预估器. 作者选取 RoBo 和高斯过程,SMAC 和随机森林、Hyperopt和Tree Parzen 预估器 测试 SMBO。
其他搜索方法
还可以将多臂 bandit 学习与贝叶斯优化相结合,类别参数的选择由 bandit 处理,并将空间分成称为超分区的子空间,每个子空间仅包含通过贝叶斯优化的参数。为此基准选择了基于贝叶斯和 Bandits(BTB)。
另一种方法是使用进化算法。有多种不同的基于人口的算法正在使用,例如粒子群优化。 在此基准测试中使用了 Optunity 算法。
性能提升
除了这些主要算法外,还有许多有关如何增强这些技术的建议-它们主要是为了减少找到最佳模型所需的时间。
低保真度
一种流行的方法是使用低保真度评估。这可以是对数据样本进行训练,也可以对模型进行较少的迭代训练-因为这是一种快速了解每种配置性能的方法,因此可以尽早测试更多的配置,并且只有大多数有前途的配置经过全部训练。
一个很好的例子是 hyperband。BOHB 是一种结合了hyperband 和贝叶斯优化的工具,并且包含在此基准测试中。
元学习
如果您已经对要探索的搜索空间中最有希望的区域有所了解,您可以从头开始缩小搜索范围,而无需从随机搜索开始,从而加速模型优化过程。一种方法是研究通常最重要的超参数,在各种数据集上,对于给定算法而言,它们通常具有哪些好的参数。
另一种方法是使用您以前可能在其他数据集上进行的超参数搜索的结果。如果可以确定数据集相似,则可以使用该任务中的最佳超参数来开始搜索-这被称为热启动搜索。
auto-sklearn 实现了这个方案, 更多关于评价数据集相似性的方法可以参考他们的论文。
基准实验
此次基准测试的数据是 OpenML100[3],OpenML-CC18[4]和 AutoML Benchmark[5]的组合,总共 137 个分类数据集。
所有库都进行 325 次迭代,因为确定该时间足够使所有算法收敛,并且任何单个模型训练都限于 10 分钟。
这些库具有 13 种不同的算法,总共有 58 个超参数可以优化。使用四折交叉验证评估每种配置的性能,并使用不同的随机种子将实验重复 10 次。
结论
为了比较具有不同难度级别的数据集的准确性,使用了两个基线模型。一个是虚拟分类器,另一个是简单的未调优随机森林算法。然后将这些基准的结果用于归一化结果,以使虚拟分类器的性能变为零,而未调整的随机森林的性能变为1。因此,任何库的性能都比 1 好,这意味着它的性能要比未调整的随机森林好。
![图 6: 本文 [1] 中测试的所有 CASH 求解器的标准化性能都得到了扩展,其中 0.5 到 1.5 之间的区域被拉伸以提高可读性。](https://cdn-images-1.medium.com/max/2432/0*12T-aS3AlyDPgLKG)
令人惊讶的是,他们发现除网格搜索外,所有工具的性能均相似!
经过十次迭代后,除网格搜索之外的所有算法均胜过了随机森林基线,图 6 示出了所有算法 325 次迭代后的最终性能。
令人好奇的是,用于网格搜索的网格的定义方式也是自动的,并且随机森林的默认参数不会出现在网格中,这比未调整的随机森林的效果更差,完整的网格包含在本文的附录中。
实验中的惊人差异
作者还强调指出,仅更改随机种子时,某些数据集显示出相当大的方差。这也是我们在 Dataiku 进行的基准测试中也观察到的,它证明了重复实验的重要性。
你可以在图 7 的清晰的看到此现象,原始和平均精度一起绘制出来显示在图中。对于方差最大的数据集,糖尿病,随机搜索的结果相差超过20%!
![图 7: 使用不同随机种子的每次运行的精度,以及种子之间差异最大的 40 个数据集的平均值。[1]](https://cdn-images-1.medium.com/max/2000/0*ysX2uUbDELr3yTQr)
作者的总结
作者总结到
一般来说,除网格搜索之外的所有算法都会生成性能相似的模型。
他们还得出结论,在大多数数据集上,准确性的绝对差值均小于 1%,因此,仅基于性能对这些算法进行排名是不合理的。对于将来的算法排名,应考虑其他标准(例如模型开销或可伸缩性)。
抛开准确性:收敛速度作为选择标准
尽管最终目标是获得最佳的模型,但实际上在计算资源和时间上还有其他限制,尤其是当我们在行业中使用大量数据时,可能无法训练数百种模型。
在这种情况下,重要的考虑因素是算法可以多快的速度接近最佳模型。当有足够的资源来训练数百个模型时,诸如模型开销之类的标准就很重要,但是,如果你只能负担例如 20 个模型的训练,那么收敛速度将成为非常重要的标准 。
为了更好地说明这一点,请参考以下图 8 中的曲线。
在 OpenML dataset Higgs 上,使用四种搜索算法来优化仅一个算法(随机森林)的四个超参数。绘制了每次迭代的最佳损耗。第一条垂直线表示第 20 次迭代。
至此,所有基于模型的优化算法都不再执行随机搜索,而是根据自己的模型选择要评估的点。在这里和第二个垂直线之间的 50 次迭代之间,我们看到,与所有算法完成 325 次迭代都达到收敛后的情况对比,这些算法发现的模型的性能之间存在更大的差异。
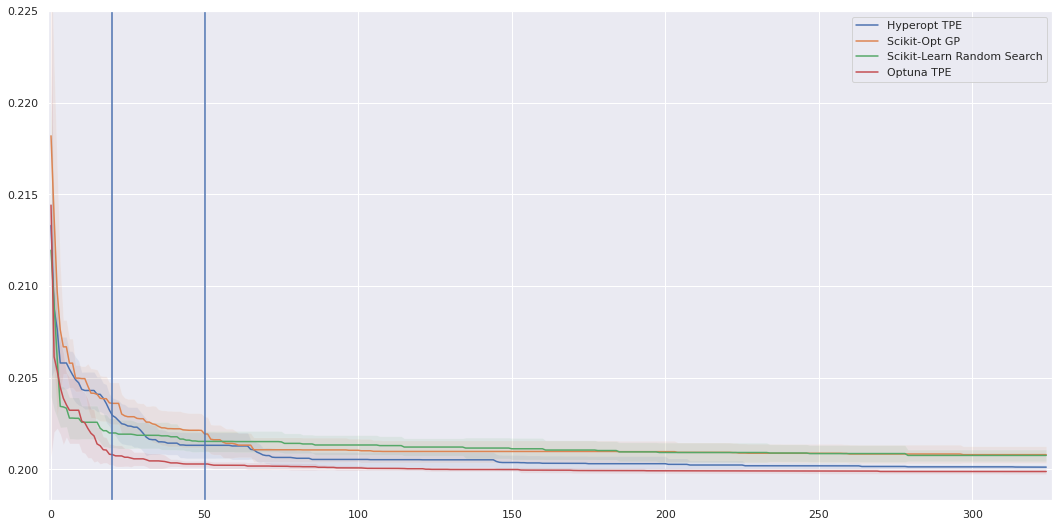
因此,如果你只能负担训练 20 个模型的费用,那么选择使用基于 Tree Parzen 预估器的算法,例如在 Optuna 中实现的算法,则将拥有一个更好的模型。
参考
- Zöller, M.-A. & Huber, M. F. Benchmark and Survey of Automated Machine Learning Frameworks. (2019).
- Bergstra, J. & Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 13, 281–305 (2012).
- Casalicchio, G., Hutter, F., Mantovani, R. G. & Vanschoren, J. OpenML Benchmarking Suites and the OpenML100. 1–6 arXiv:1708.03731v1
- Casalicchio, G., Hutter, F. & Mantovani, R. G. OpenML Benchmarking Suites. 1–6 arXiv:1708.03731v2
- Gijsbers, P. et al. An Open Source AutoML Benchmark. 1–8 (2019).
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
