

零、分篇幅看
一、 JS的9种数据类型的一些细节点
(1)JS中的数据类型
基本数据类型
1、 string ,可以用双引号、单引号、反引号
2、 number ,比如:值有123/1.2/NaN/Infinity/-Infinity...
3、 boolean,值为true/false
4、 null,值为null
5、 undefined,值为undefined
6、 bigint
7、 symbol,用于创建唯一值
引用数据类型
1、 object 例如:
① {}普通对象
② []数组对象
③ 日期对象
④ 正则,比如:/^\d+$/
⑤ ......
2、 function
① 普通函数
② 构造函数
③ 箭头函数
④ 生成器函数
⑤……
(2)number 的一些细节
number类型的值有:
1、正数、负数、零、小数......
2、NaN not a number 不是一个有效数字,但是它是number类型的
xxx,你不是一个人。不是一个人,那是什么都有可能了
① NaN 和 NaN 本身不相等,和其他值也不相等
② isNaN(vlaue)检测当前值是否不是一个有效数字,不是有效数字返回true;反之,是有效数字返回false
③ Object.is(NaN, NaN)结果是true,它的内部做了特殊处理
3、Infinity无限大 -Infinity无限小
console.log(typeof NaN); //=> 'number'
console.log(typeof Infinity); //=> 'number'
console.log(NaN == NaN); //=> false
console.log(NaN === NaN); //=> false
console.log(Object.is(NaN, NaN)); //=> true
△ NaN
Object.is developer.mozilla.org/zh-CN/docs/…
把其它数据类型值转换为number类型:
1、显式转换:Number(vlaue) 或者 parseInt(value)/parseFloat(value) 他们底层处理的规则不一样
2、隐式转换(逻辑用的是Number(value)的)
① 数学运算
② 基于==比较的时候
③ isNaN(value)
④ ....
(3)字符串的一些细节点
string字符串:单引号、双引号、反引号,里面的内容都是字符串
其它值转换为字符串:
1、显式转换:String(value)或者(vlaue).toString()涉及到数据类型检测,后面再说
2、隐式转换:加号除了数学运算,还会产生字符串拼接
+ 加号是斜杠青年
let n = '10',
m = 10;
console.log(10 + n);
console.log(+n);
console.log(++n);
let obj = {};
console.log(10 + obj);
console.log(10 + new Number(10));
console.log(10 + {id:'zhaoxiajingjing'});
△ 结果是多少?
+ 作为斜杠青年,本职工作是数学运算符,还斜杠担任了字符串拼接的工作,那它什么时候切换角色呢?
+只有一边有内容时:比如+n,把值转换为数字;++n/n++也会把值转换为数字,然后再进行前置/后置自增的运算
+两边都有内容时:
1、"+" 有一边出现了字符串,就会变成字符串拼接
2、"+" 有一边是对象,则也可能会成为字符串拼接:
△ 图1.1_"+"作为一枚斜杠青年
其中:①③得到的是数字10,原因是:{...} 没有参与运算,浏览器认为这是一个代码块,计算的是+10
而:console.log({}+10) 有一个括号把{}+10包起来了,它会认为这是一个整体再进行运算
那么,对象在做数学运算时的底层机制:
(1)检测对象的Symbol.toPrimitive 【primitive [ˈprɪmətɪv] n.原始的】 这个属性值,如果有则基于这个值进行运算,如果没有,走下一步
(2)检测对象的valueOf()这个值【原始值/基本类型值】,如果有则基于这个值进行运算,如果不是原始值,走下一步
(3)获取对象的toString()把其变为字符串 => 如果是" +"处理,则看到字符串了,变为字符串拼接
(4)如果最后就是想要得到的数字,则再把字符串转换为数字即可
let obj = {
[Symbol.toPrimitive]:function (){
return 10;
}
};
console.log(10 + obj); //=> 20
△ 对象获得的是数字
而, console.log(10 + new Number(10))的结果就是数字20,是因为new Number(10).valueOf()获得的原始值就是数字10
∴ 答案是:
let n = '10',
m = 10;
console.log(10 + n); //=> 字符串拼接:'1010'
console.log(+n); //=> 把值转换为数字:10
console.log(++n); //=> 把值转换为数字,在前置自增:11
let obj = {};
console.log(10 + obj); //=> '10[object Object]'
console.log(10 + new Number(10)); //=> 20
console.log(10 + {id:'zhaoxiajingjing'}); //=> '10[object Object]'
△ + 是一枚斜杠青年
那么,请问:i=i+1 i+=1; ++i/i++ 这三个一样吗?
其中:i=i+1和i+=1是一样的;++i/i++大部分情况是与前面的一样的。
如果i的值是字符串则不一样了:
i=i+1 i+=1会处理为字符串拼接
++i/i++先把值转为数字,再进行前置/后置累加
(4)symbol 唯一值
API:developer.mozilla.org/zh-CN/docs/…
Symbol():创建唯一值
Symbol() 函数会返回symbol类型的值
new Symbol()报错:Uncaught TypeError: Symbol is not a constructor
△ 图1.2_symbol类型
Symbol.toPrimitive
API developer.mozilla.org/zh-CN/docs/…
Symbol.toPrimitive是一个内置的Symbol值,它是作为对象的函数值属性存在的,当一个对象转换为对应的原始值时,会调用此函数
let obj = {
[Symbol.toPrimitive]:function (hint){
console.log(hint); // hint 取值:"number/string/default"
return 10;
}
};
console.log(10 + obj); //=> 20 hint输出 'default'
Number(obj); //=> hint输出 'number' obj的原始值 10
String(obj); //=> hint输出 'string' obj的原始值 '10'
△ Symbol.toPrimitive
(5)BigInt 大数
API:developer.mozilla.org/zh-CN/docs/…
△ 图1.3_bigint
二、 JS的4大数据类型转换规则
0 / 把其他数据类型转换为Number类型
(1)指定需要转换为Number的
1、Number(value)
2、parseInt(string, radix)/parseFloat(string)
Number转换机制
把其他类型(string/boolean/null/undefined/symbol/bigint/object)使用Number转换为数字:
1、字符串中只要出现非有效数字,结果就是NaN
2、Number(true) 是1,Number(false) 是0
3、Number(null)是0,Number(undefined)是NaN
4、Number(Symbol('A')) 报错
5、Number(BigInt(10)) 是数字
6、对象变为数字:先调取Symbol.toPrimitive 获取原始值,没有再通过valueOf获得原始值;如果没有原始值,再调取toString变为字符串,最后把字符串转为数字
△ 图1.1_Number的转换
parseInt/parseFloat转换机制
parseInt转换机制:从字符串左侧第一个字符开始,查找有效数字字符(遇到非有效数字字符就停止查找,不管后面是否还有数字都不要了),把找到的有效数字字符转换为数字,如果一个都没找到结果就是NaN
parseFloat比parseInt多识别一个小数点
(2)隐式转换
1、isNaN(value),其他数据类型先通过Number转为数字类型
2、数学运算:+-*/%。数学运算,其他数据类型先用Number转换为数字类型再计算(特殊情况:+ 作为斜杠青年,当遇到字符串时,是字符串拼接)
3、在==比较时,有些值需要转为数字再进行比较
4、……
(3)练习题
parseInt("")
Number("")
isNaN("")
parseInt(null)
Number(null)
isNaN(null)
parseInt("12px")
Number("12px")
isNaN("12px")
parseFloat("1.6px")+parseInt("1.2px")+typeof parseInt(null)
isNaN(Number(!!Number(parseInt("0.8"))))
typeof !parseInt(null) + !isNaN(null)
△ 其他数据类型转换为数字类型
L1:parseInt("") 没有找到有效数字字符=> NaN
L2:Number("") => 0
L3:isNaN("") => isNaN 方法调用的是 Number 转换数据类型 => false
L4:parseInt(null) => parseInt("null") => NaN
L5:Number(null) =>0
L6:isNaN(null) => false
L7:parseInt("12px") => 12
L8:Number("12px") => NaN
L9:isNaN("12px") => true
L10:parseFloat("1.6px")+parseInt("1.2px")+typeof parseInt(null)
=> typeof parseInt(null) => typeof NaN => "number"
=> 1.6 + 1 + "number"
=> "2.6number"
加号左右两边出现字符串,此时加号变为字符串拼接(有特殊性),如果出现对象也会变成字符串拼接,原本应该是把对象转为数字,但是对象要先转换为字符串,则遇到加号字符串就变成字符串拼接了
L11:isNaN(Number(!!Number(parseInt("0.8"))))
=> parseInt("0.8") => 0
=> !!Number(0) => false
=> Number(false) => 0
=> isNaN(0) => false
L12:typeof !parseInt(null) + !isNaN(null)
=> typeof !NaN + !false
=> typeof true + true
=> "boolean" + true
=> "booleantrue"
let result = 10+false+undefined+[]+'Tencent'+null+true+{};
console.log(result);
△ 答案是?
10+false+undefined+[]+'Tencent'+null+true+{}
=> 10 + false 没有遇到字符串和对象,数学运算:10+0 => 10
=> 10 + undefined => 10 + NaN => NaN
=> NaN + [] =>"NaN"
对象数据类型转换为数字:先转换为字符串再转换为数字
在转换为字符串后,遇到了加号=>字符串拼接
=>"NaN" + 'Tencent' +null+true+{}
=> "NaNTencentnulltrue[object Object]"
链接:"+" 的斜杠身份:数学运算,字符串拼接
(4)思考题
let arr = [10.18, 0, 10, 25, 23];
arr = arr.map(parseInt);
console.log(arr);
△ 思考题
1 / 把其他数据类型转为字符串
(1)显式转换
1、toString()
2、String()
其他数据类型(number/boolean/null/undefined/symbol/bigint/object)转换为字符串,一般都是直接用""引号包起来,只有{}普通对象调取toString()方法。调取的是Object.prototype.toString()方法(返回值:"[object Type]"),不是转换字符串,而是检测数据类型的:({id:"zhaoxiajingjing"}).toString() => "[object Object]"
△ 图1.2_其他数据类型转换为字符串
(2)隐式转换(一般调取toString方法)
1、加号运算时候,如果有一边出现字符串,则是字符串拼接
2、把对象转为数字:需要先调用toString()转换为字符串,再去转换为数字
3、基于alert/confirm/prompt/document.write...这些方法输出内容,都是先把内容转化为字符串,再输出的
4、……
3 / 把其他数据类型转换为布尔
把其他类型(string/number/null/undefined/symbol/bigint/object)转换为布尔类型:
只有5个值会变成布尔类型的false:空字符串/0/NaN/null/undefined,其他都是true
(1)其他数据类型转换为布尔
1、!转换为布尔值后取反
2、!!转换为布尔类型
3、Boolean(value)
(2)隐式转换
在循环或者条件判断中,条件处理的结果就是布尔类型值
4 / 在==比较时,数据类型转换的规则
(1)需要注意的点
1、{}=={} false 对象数据类型比较的是堆内存地址
2、[]==[] false 对象数据类型比较的是堆内存地址
3、NaN==NaN false
(2)类型不一样的转换规则
1、 null==undefined true 其他数据类型的值与null/undefined都不相等
null===undefined false 它俩类型不一样
2、字符串==对象 把对象转换为字符串
3、剩下的,如果==两边数据类型不一致,需要转换为数字再进行比较
(3) 题
console.log([] == false);
console.log(![] == false);
△ 比较 ==
[] == flase
类型不一样,需要转换为数字再进行比较:隐式转换
1、对象转换为数字:先toString转换为字符串(先基于Symbol.toPrimitive获得原始值,没有的话基于valueOf获得原始值,没有原始值再去toString),在转换为数字
2、[]=>""=>0
3、false=>0 true=>1
4、结果是:[]==false => 0==0 => true
![]==false
运算符优先级:!比==的要高
1、![] 把数组转换为布尔类型,再取反:!true => false
其他数据类型转换为布尔类型,是false的只有5个:空字符串/0/NaN/null/undefined,其他都是true
2、结果是:false == false => true
三、 变量提升处理机制
0 / 变量提升处理机制
变量提升:在当前上下文中(全局/私有/块级),JS代码自上而下执行之前,浏览器会处理一些事情(可以理解为词法解析的一个环节,词法解析一定是发生在代码执行之前的):
会把当前上下文中所有带var/function关键字的进行提前声明或者定义
var a = 10;
① 声明 declare:var a;
② 定义 defined:a = 10;
带VAR的只提前声明
带FUNCTION的会提前声明+定义
函数名就是变量名,函数是对象数据类型的需要堆内存存储
现在代码基本都用ES6语法的let/const写了,所以var的变量提升会少很多。声明函数也尽量使用函数表达式来写,这样可以规避掉直接使用function声明函数的而产生的变量提升
1 / 练习题目
(1)var的变量提升
/*
EC(G) 全局执行上下文
VO(G) 变量对象
var a; 默认值是undefined
-----
代码执行:
*/
console.log(a); //=> undefined
var a = 12; //=> 创建12,a=12 赋值(声明在变量提升阶段完成了,浏览器懒得不会做重复的事情)
a = 11; //=> 全局变量 a = 11;
console.log(a); //=> 11
△ 变量提升
数据类型:
① 基本数据类型(string/number/boolean/null/undefined/symbol/bigin)
② 对象数据类型(object/functioin)
① 基本数据类型值:直接存储在栈内存中
② 对象数据类型值:由于数据类型比较复杂,存储在堆内存中,把堆内存的16进制地址放到栈内存中与变量关联起来
(2)function 的变量提升
/*
EC(G) 全局执行上下文
VO(G) 变量对象
fn = 0x000001堆内存地址[声明+定义]
-----
代码执行:
*/
fn(); //=> 函数执行的结果:输出"hello"
function fn(){
var a = 12;
console.log('hello');
}
△ 函数
项目开发中推荐:函数表达式 var fn = function (){};
这样,在变量提升阶段只会声明变量,不会赋值
函数表达式
fn(); //=> Uncaught TypeError: fn is not a function
// 报错后面的代码就不执行了
var fn = function (){
// 函数表达式:在变量提升阶段只会声明fn,不会赋值了
console.log('hello');
};
fn();
△ 函数表达式
匿名函数具名化
var fn = function AA(){
console.log('hello');
};
AA(); //=> Uncaught ReferenceError: AA is not defined
△ 匿名函数具名化
var fn = function AA(){
console.log('hello');
console.log(AA); //=> 输出当前函数体
};
fn();
△ 匿名函数具名化
把原本作为值的函数表达式的匿名函数“具名化”:
① 这个名字不能在函数体外部访问,也就是不会出现在当前上下文中
② 函数执行时,形成私有上下文,会把这个“具名化”的名字作为该上下文中的私有变量(它的值就是这个函数体)来处理
③ 在函数体内部不能修改这个名字的值,除非是重新声明这个变量
(3)不带var的
/*
EC(G) 全局执行上下文
VO(G) 变量对象
-----
代码执行:
*/
console.log('ok'); //=> 'ok'
//=> 没有写VAR/FUNCTION的,不能在定义前使用
console.log(a); //=> Uncaught ReferenceError: a is not defined
a=12;
console.log(a);
△ 不带var的
(4)带let的
/*
EC(G) 全局执行上下文
VO(G) 变量对象
-----
代码执行:
*/
console.log('ok'); //=> 'ok'
//=>LET/CONST 没有变量提升
console.log(a); //=> Uncaught ReferenceError: a is not defined
let a = 12;
a = 13;
console.log(a);
△ 带LET的
(5)在全局上下文的映射
基于VAR/FUNCTION在 全局上下文EC(G) 中声明的变量(全局变量)会“映射”到 GO(window 全局对象) 上一份,作为它的属性;而且一个修改另外一个也会跟着修改
var a = 12;
console.log(a); //=> 12 全局变量
console.log(window.a); //=> 12 映射到GO上的属性
window.a = 11;
console.log(a); //=> 11 映射机制:一个修改另一个也会修改
△ 全局上下文的映射机制
2 / 变量提升的题目
fn();
function fn(){ console.log(1); }
fn();
function fn(){ console.log(2); }
fn();
var fn = function(){ console.log(3); }
fn();
function fn(){ console.log(4); }
fn();
function fn(){ console.log(5); }
fn();
△ 答案是?
四、 函数底层运行机制
(1)第一题
var a = {n: 1};
var b = a;
a.x = a = {n: 2};
console.log(a.x);
console.log(b);
△ 引用数据类型:object
(2)第二题
var x = [12, 23];
function fn(y) {
y[0] = 100;
y = [100];
y[1] = 200;
console.log(y);
}
fn(x);
console.log(x);
△ 引用数据类型:function
这些题是不是很简单?我们主要看逻辑:
1 / 引用数据类型:object
在Web浏览器中执行JS代码,会开辟一块栈内存来作为执行环境:ECStack(Execution Context Stack)
会开辟一块栈内存供全局代码执行:全局执行上下文 EC(G)(Execution Context Global),还有其他的上下文:函数私有执行上下文、块级私有上下文…… 自己管好自己那一摊的代码执行内容
形成的执行上下文都会 进栈 到执行环境栈中运行.私有上下文会在不被占用时出栈释放,浏览器的回收机制GC.当浏览器关闭时,全局执行上下文就会出栈释放了
△ 图2.1_第一题,简图
GO:全局对象 Global Object ,并不是VO(G)全局变量对象 Variable Object Global
全局对象,它是个对象,它就是个堆内存,浏览器打开一加载页面就默认开辟的堆内存。
浏览器提供的一些供JS调用的API,在Web浏览器中,全局对象可以通过window来访问的
注意:运算符优先级,要多看看多比划比划【上链接】
注意:基本数据类型值直接存储在栈内存中,引用数据类型值存在堆内存中
2 / 引用数据类型:function
var x = [12, 23];
function fn(y) {
y[0] = 100;
y = [100];
y[1] = 200;
console.log(y);
}
fn(x);
console.log(x);
△ 函数执行
(1)第二题,简图
△ 图2.2_函数执行
△ 图2.3_数组的格式:键值对
(2)创建函数
创建函数的步骤:【和创建变量区别不是很大,函数名就是变量名】
① 单独开辟一个堆内存:16进制地址,函数堆内存中存储的是函数体中的代码字符串
② 创建函数的时候,就声明了它的作用域[[scope]],也就是所在的上下文环境
③ 把16进制地址(16进制以0x开头)存放到栈中,供函数名变量名关联引用即可
只创建函数,不执行函数,没啥意义,那就是一堆字符串。
函数执行的目的:把创建函数的时候在堆内存中存储的 代码字符串 变为代码执行
代码执行一定会有一个执行的环境,它的上级执行上下文,是函数创建的地方
函数执行会形成一个全新的、私有的执行上下文,在私有上下文中,也有存放自己变量的对象:AO(Active Object 活动对象),它是VO的一种。
变量对象: ① 在全局上下文中:VO ② 在私有上下文中:AO
实参都是值。形参是变量。
fn(x):执行函数fn,把全局上下文中存储的x变量关联的值(0x000001),作为实参传递给函数的形参变量
(3)执行函数
执行函数做了哪些事情:
1、形成了一个全新的、私有的执行上下文EC(xxx)
2、当前私有的上下文中,有一个存放此上下文内声明的变量的地方 AO(xxx) 私有变量对象
① 形参变量
② 当前上下文中声明的变量
3、进栈执行
4、代码执行之前还要处理很多事情:
① 初始化作用域链
[[scope-chain]]:<当前自己的上下文, 上级上下文(创建函数时形成的作用域)>
(作用域链有两头,一头是自己执行的上下文,另一头是自己创建时所在的上下文)
即:当前函数的上级上下文是创建函数所在的上下文,就是作用域
以后再遇到函数内的代码执行,遇到一个变量,首先看是否为自己上下文中的私有变量(看AO中有没有,有,是自己私有的;没有,不是自己私有的)。如果是私有的变量,则当前变量的操作和外界环境中的变量互不干扰(没有直接关系);如果不是自己的私有变量,则按照作用域链,查找是否为其上级上下文中的私有变量.....一直找到EC(G)全局上下文为止:作用域链查找机制
② 初始化this....
③ 初始化arguments....
④ 形参赋值:形参都是私有变量,放在AO中的。如果不传递实参,默认值是undefined
⑤ 变量提升....
5、代码自上而下执行
6、.....
7、一般情况下,函数执行所形成的私有上下文,进栈执行完后,会默认出栈释放掉
【私有上下文中存储的私有变量和一些值都会被释放掉,目的:为了优化内存空间,减少栈内存的消耗,提高页面或者计算机的处理速度......】
不能出栈释放:当前上下文中某些内容(一般是堆内存地址)被当前上下文的外部的事物占用了,则无法出栈释放。一旦被释放,后期外部事物就无法找到对应的内容了
注意: 多次函数执行,会形成多个全新的、私有执行上下文,这些上下文之间没有直接的关系
(4)闭包
一般,很多人认为:大函数返回小函数是闭包。
这只是闭包机制中的一种情况。
闭包:函数执行形成一个私有的执行上下文,此上下文中的私有变量,与此上下文以外的变量互不干扰;也就是当前上下文把这些变量保护起来了,我们把函数的这种保护机制称为闭包。
闭包不是具体的代码,而是一种机制。
一般情况下,形成的私有上下文很容易被释放掉,这种保护机制存在时间太短了,不是严谨意义上的闭包。有人认为,形成的上下文不被释放,才是闭包。此时,不仅保护了私有变量,而且这些变量和存储的值也不会被释放掉,保存起来了。
闭包的作用:① 保护 ② 保存
利用闭包的两个作用,可以实现高阶编程技巧,以后再说~
3 / 练习题
(1)第一题
var x = 100;
function fn() {
var x = 200;
return function(y) {
console.log(y + x++);
}
}
var f = fn();
f(10);
f(20);
△ 第一题
i++ 后加
△ 图2.4_后加
(2)第二题
let a=0,
b=0;
function A(a){
A=function(b){
alert(a+b++);
};
alert(a++);
}
A(1);
A(2);
△ 第二题
(3)第三题
let x = 5;
function fn(x) {
return function(y) {
console.log(y + (++x));
}
}
let f = fn(6);
f(7);
fn(8)(9);
f(10);
console.log(x);
△ 第三题
五、 LET vs VAR 的5点区别
变量提升:在当前上下文中,代码执行之前,会把所有var/function关键字的进行提前声明或者定义
(1)带var的只是提前声明
(2)带function的是声明+定义
let 和 var 的区别:
(1)区别1:var 存在变量提升,而let不存在
console.log(n); //=> undefined
console.log(m); //=> Uncaught ReferenceError: m is not defined【运行时错误】
var n=12;
let m=11;
△ var的变量提升
(2)区别2:全局执行上下文的映射机制
在“全局执行上下文”中,基于var声明的变量,也相当于给GO(全局对象window)新增一个属性,并且任何一个发生值的改变,另外一个也会跟着变化(映射机制);但是,let声明的变量,就是全局变量,与GO没有任何关系
① let VS var
var n = 12; // VO(G): var n=12 <=> GO:window.n=12
console.log(n, window.n); //=> 12 12
window.n = 11;
console.log(n); //=> 11
let m = 12;
console.log(m, window.m); //=> 12 undefined
△ 映射机制
② 全局执行上下文中:不写var
x = 11; //=> window.x = 11; 没有写任何关键词声明,相当于给window设置一个属性
console.log(x); //=> 先看看是不是全局变量,如果不是,再看看是不是window的一个属性
console.log(y); //=> 两个都不是,那就报错,变量未定义 Uncaught ReferenceError: y is not defined【运行时错误】
△ 不写var:在项目中尽量不要这样写
③ 函数中:不写var
function fn(){
/*
当函数执行时,这里形成私有上下文
遇到变量x时,根据【作用域链查找机制】
变量x找到全局都没有,
如果是设置值的操作,
则相当于给window设置一个属性
window.x = 11
*/
x = 11; // window.x = 11
console.log(x); //11
}
fn();
console.log(x);// 11
△ 不写var
function fn(){
/*
当函数执行时,这里形成私有上下文
当遇到变量y时,根据【作用域链查找机制】
变量y找到全局都没有,
如果获取的操作,
则直接报错,后面的代码就不执行了
*/
x = 11;
console.log(y);// Uncaught ReferenceError: y is not defined【运行时错误】
}
fn();
console.log(x);
△ 不写var
(3)区别3:重复声明
在相同上下文中,let不允许重复声明【不论是基于何种方式声明的,只要声明过的,都不能基于let重复声明了】;而var 比较松散,重复声明也无所谓,反正浏览器也只会按照声明一次来处理的
console.log('hello');
var n = 11;
let n = 12;
△ let 不允许重复声明
在代码执行之前,浏览器需要干很多活儿,比如:词法分析,变量提升
【词法分析阶段】如果发现有基于let/const并且重复声明变量的操作,则直接报 语法错误Uncaught SyntaxError: Identifier 'n' has already been declared,整个代码都不会执行了
(4)区别4:暂时性死区与typeof
API:developer.mozilla.org/zh-CN/docs/…
console.log(n); //=>Uncaught ReferenceError: n is not defined
△ 未被声明过的变量
console.log(typeof n); //=> undefined
△ 未被声明过的变量
console.log(typeof n); //=> Uncaught ReferenceError: n is not defined
let n;
△ let 没有变量提升,在遇到声明之前是不能使用的
(5)区别5:块级作用域
let/const/function 会产生块级私有上下文,而var不会
① 上下文&作用域
哪些是,上下文 & 作用域:
1、全局上下文
2、函数执行形成的“私有上下文”
3、块级作用域(块级私有上下文),除了 对象/函数...的大括号之外的(例如:判断体、循环体、代码块)
API:developer.mozilla.org/zh-CN/docs/…
API:developer.mozilla.org/zh-CN/docs/…
while(1 !==1) {// 块级
}
for(let i = 0; i<10; i++){// 块级
}
if(1==1) {// 块级
}
switch(1) { // 块级
case 1:
break;
}
switch(1) {
case 1:{// 块级
break;
}
}
{// 块级
}
△ 块级作用域/块级私有上下文
{
var n = 12;
console.log(n); //=> 12
let m = 11;
console.log(m); //=> 11
}
console.log(n); //=> 12
console.log(m); //=>Uncaught ReferenceError: m is not defined
△ 块级作用域
n 是 全局上下文的:代码块不会对他有任何限制
m 是代码块所代表的块级上下文中 私有的
△ 图_debugger
② let 的闭包
浏览器的控制台并不能呈现很多东西,而是底层C++实现的
for(let i = 0; i<5;i++) {
console.log(i);
i+=2;
}
△ 形成了多少个块呢?
△图1_ 块级上下文
var buttons = document.querySelectorAll('button');
// 浏览器在每一轮循环时,会帮我们形成“闭包”
for (let i = 0; i < buttons.length; i++) {
/*
let i = 0; 【父级块级上下文:控制循环】
i = 0 ;第一次 循环 私有块级上下文EC(B1)
=> 当前上下文中,形成一个小函数,被全局的按钮的click占用了,
=> EC(B1) 不会被释放掉
=> 闭包
*/
buttons[i].onclick = function () {
console.log(`当前按钮的索引:${i}`);
};
}
△ let 的闭包
let i = 0; //=> 写在这里循环的时候,就不会产生块级上下文了
for(; i < 5; i++){
console.log(i);
}
console.log(i);
六、 高阶函数
0 / 题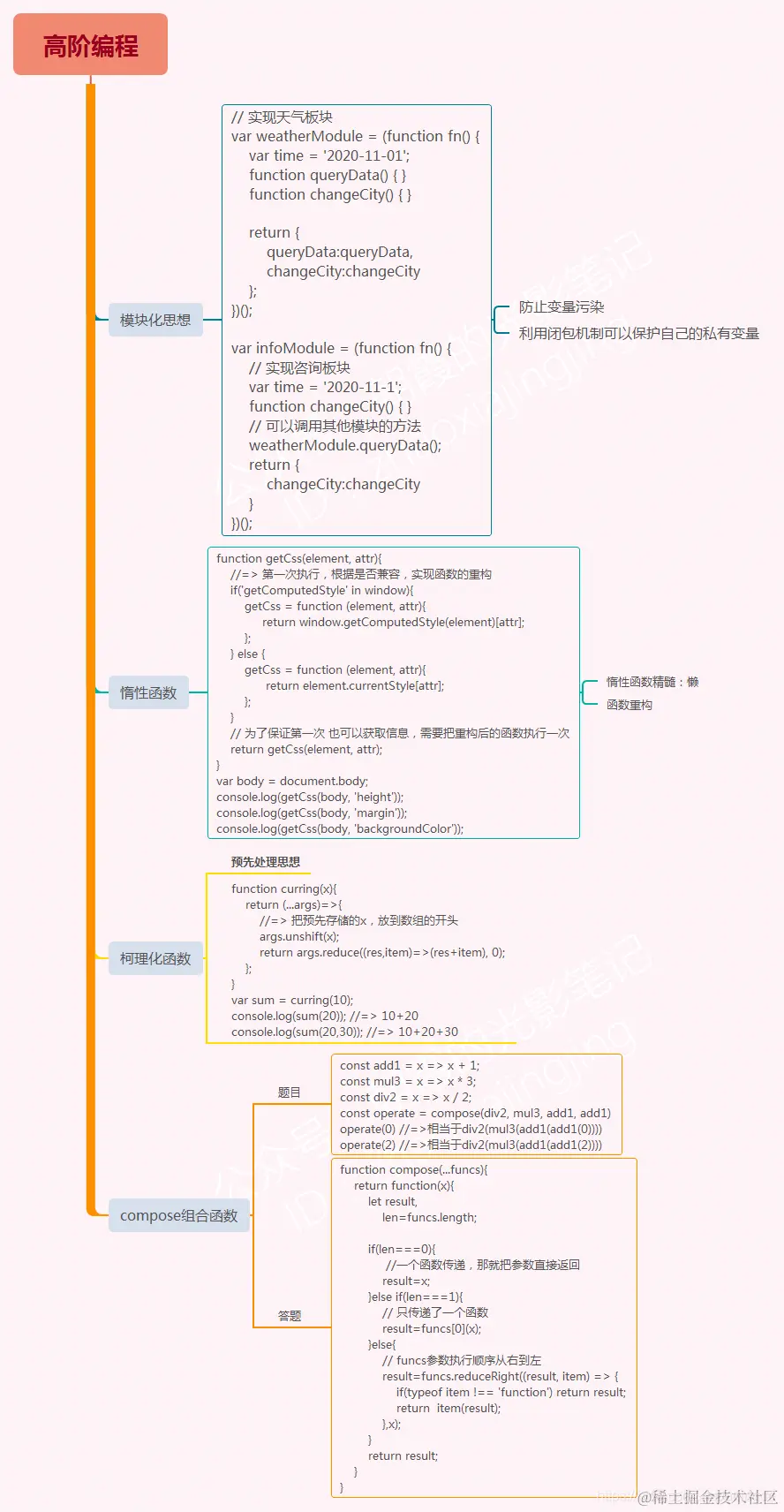
JS高阶编程技巧:利用闭包的机制,实现出来的一些高阶编程的方式
1、模块化思想
2、惰性函数
3、柯理化函数
4、compose组合函数
5、高阶组件 React中的
6、……
(1)模块化思想
单例 -> AMD(require.js)->CMD(sea.js)-> CommonJS(Node) ->ES6Module
// 实现天气板块
var time = '2020-11-01';
function queryData(){
// ...CODE
}
function changeCity(){
// ...CODE
}
// 实现咨询板块
var time = '2020-11-1';
function changeCity(){
// ...CODE
}
△ 很久以前的没有模块化思想之前
在没有模块化思想之前,团队协作开发或者代码量较多的情况下,会导致全局变量污染【变量冲突】
团队之前开发,合并到一起的代码,变量命名冲突了,让谁改都不合适,那怎么办呢?
① 闭包
闭包:保护
暂时基于闭包的“保护作用”防止全局变量污染
但是,每个版块的代码都是私有的,无法相互调用
// 实现天气板块
(function fn() {
var time = '2020-11-01';
function queryData() { }
function changeCity() { }
})();
(function fn() {
// 实现咨询板块
var time = '2020-11-1';
function changeCity() { }
})();
△ 基于闭包的保护作用
② 某一种方案
把需要供别人调用的API方法,挂在到全局上
但是也不能写太多,还是会引起全局变量污染
// 实现天气板块
(function fn() {
var time = '2020-11-01';
function queryData() { }
function changeCity() { }
window.queryData=queryData;
window.changeCity=changeCity;
})();
(function fn() {
// 实现咨询板块
var time = '2020-11-1';
function changeCity() { }
window.changeCity=changeCity;
})();
△ 挂在window上
③ 再一种方案
对象的特点:每一个对象都是一个单独的堆内存空间每一个对象也是单独的一个实例:Object的实例,这样即使多个对象中的成员名字相同,也互不影响
仿照其他后台语言,obj1/obj2不仅仅是对象名,更被称为【命名空间】给堆内存空间起个名字
let obj1 = {
name:'朝霞的光影笔记',
id:'zhaoxiajingjing',
show:function(){}
};
let obj2 = {
name:'zxjj',
show:function (){}
};
△ 对象
每个对象都是一个单独的实例,用来管理自己的私有信息,即使名字相同,也互不影响:【JS中的单例设计模式】
④ 进阶一下
实现私有性和相互调用
// 实现天气板块
var weatherModule = (function fn() {
var time = '2020-11-01';
function queryData() { }
function changeCity() { }
return {
queryData:queryData,
changeCity:changeCity
};
})();
var infoModule = (function fn() {
// 实现咨询板块
var time = '2020-11-1';
function changeCity() { }
// 可以调用其他模块的方法
weatherModule.queryData();
return {
changeCity:changeCity
}
})();
△ 单例模式
(2)惰性函数
惰性函数,一定要抓住精髓:惰性 => 懒
window.getComputedStyle(document.body)获取当前元素经过浏览器计算的样式,返回样式对象
在IE6~8中,不兼容这个写法,需要使用 元素.currentStyle 来获取
① 一开始这样写
function getCss(element, attr){
if('getComputedStyle' in window){
return window.getComputedStyle(element)[attr];
}
return element.currentStyle[attr];
}
var body = document.body;
console.log(getCss(body, 'height'));
console.log(getCss(body, 'margin'));
console.log(getCss(body, 'backgroundColor'));
△ 获取样式
当浏览器打开后,在第一次调用getCss方法时,就检测了兼容性了,那么,在第二次、第三次调用时是不是就没必要再去检测了
【优化思想】:第一次执行getCss我们就知道是否兼容了,第二次及以后再次调用getCss时,则不想再处理兼容的容错处理了,这就是“惰性思想”【就是“懒”,干一次可以搞定的,绝对不去做第二次了】
② 优化一下
也能实现,但不是严谨意义上的惰性思想
var flag = 'getComputedStyle' in window;
function getCss(element, attr){
if(flag){
return window.getComputedStyle(element)[attr];
}
return element.currentStyle[attr];
}
var body = document.body;
console.log(getCss(body, 'height'));
console.log(getCss(body, 'margin'));
console.log(getCss(body, 'backgroundColor'));
△ 优化一下
③ 惰性思想
惰性是啥?就是 懒
懒是啥?能坐着不站着,能躺着不坐着,能少干活就少干活
function getCss(element, attr){
//=> 第一次执行,根据是否兼容,实现函数的重构
if('getComputedStyle' in window){
getCss = function (element, attr){
return window.getComputedStyle(element)[attr];
};
} else {
getCss = function (element, attr){
return element.currentStyle[attr];
};
}
// 为了保证第一次 也可以获取信息,需要把重构后的函数执行一次
return getCss(element, attr);
}
var body = document.body;
console.log(getCss(body, 'height'));
console.log(getCss(body, 'margin'));
console.log(getCss(body, 'backgroundColor'));
△ 惰性函数+重构函数
(3)柯理化函数
函数柯理化:预先处理思想
形成一个不被释放的闭包,把一些信息存储起来,以后基于作用域链访问到事先存储的信息,然后进行相关处理。所有符合这种模式的(闭包应用)都称为 柯理化函数
//=> x 是预先存储的值
function curring(x){}
var sum = curring(10);
console.log(sum(20)); //=> 10+20
console.log(sum(20,30)); //=> 10+20+30
△ 请实现柯理化函数
① 把类数组转换为数组:
let arg = {0:10, 1:20, length:2};
let arr = [...arg];
arr = Array.from(arg);
arr = [].slice.call(arg);
△ 类数组转为数组
② 数组求和
数组求和
1、for循环/forEach
2、eval([10,20,30].join('+'))
3、[10,20,30].reduce()
命令式编程:[关注怎么做] 自己编写代码,管控运行的步骤和逻辑【自己灵活掌控执行步骤】
函数式编程:[关注结果] 具体实现的步骤已经被封装称为方法,我们只需要调用方法即可,无需关注怎么实现的【好处:使用方便,代码量减少。弊端:自己无法灵活掌控执行步骤】
③ 数组的reduce方法
API:developer.mozilla.org/zh-CN/docs/…
arr.reduce(callback()[, initialValue])
callback(accumulator, currentValue[, index[, array]])
let arr = [10,20,30,40];
let res = arr.reduce(function (result, item, index){
console.log(result, item, index);
});
△ reduce
△ 图1.6_reduce执行
1、initialValue 初始值不传递,result 默认初始值是数组的第一项,reduce是从数字第二项开始遍历的
2、每遍历数组中的一项,回调函数被触发执行一次
① result 存储的是上一次回调函数返回的结果。除了第一次是初始值或者数字第一项
② item 当前遍历这一项
③ index 当前遍历这一项的索引
let arr = [10,20,30,40];
let res = arr.reduce(function (result, item, index){
console.log(result, item, index);
return item + result;
});
console.log(res); //=> 100
△ arr.reduce
数组的reduce方法:在遍历数组过程中,可以累积上一次处理的结果,基于上次处理的结果继续遍历处理
let arr = [10,20,30,40];
let res = arr.reduce(function (result, item, index){
console.log(result, item, index);
}, 0 );
△ reduce 传递初始值了
arr.reduce 传递了initialValue了,则result 的第一次结果就是初始值,item从数组第一项开始遍历
△ 图1.7_reduce执行
自己实现reduce
Array.prototype.reduce = function reduce(callback, initialValue){
let self = this,
i = 0; //=> THIS:arr
if(typeof callback !== 'function') throw new TypeError('callback must be a function');
if(typeof initialValue === "undefined"){
initialValue = self[0];
i = 1;
}
// 迭代数组每一项
for(; i < self.length; i++){
var item = self[i],
index = i;
initialValue = callback(initialValue, item, index, self);
}
return initialValue;
};
△ 自己手写reduce
④ 柯理化函数
function curring(x){
return (...args)=>{
//=> 把预先存储的x,放到数组的开头
args.unshift(x);
return args.reduce((res,item)=>(res+item), 0);
};
}
var sum = curring(10);
console.log(sum(20)); //=> 10+20
console.log(sum(20,30)); //=> 10+20+30
△ 柯理化函数
(4)compose 组合函数
① 题目描述
在函数式编程当中有一个很重要的概念就是函数组合, 实际上就是把处理数据的函数像管道一样连接起来, 然后让数据穿过管道得到最终的结果。 例如:
const add1 = x => x + 1;
const mul3 = x => x * 3;
const div2 = x => x / 2;
div2(mul3(add1(add1(0)))); //=>3
△ 函数组合
而这样的写法可读性明显太差了,我们可以构建一个compose函数,它接受任意多个函数作为参数(这些函数都只接受一个参数),然后compose返回的也是一个函数,达到以下的效果:
const operate = compose(div2, mul3, add1, add1)
operate(0) //=>相当于div2(mul3(add1(add1(0))))
operate(2) //=>相当于div2(mul3(add1(add1(2))))
△ 可读性较好
简而言之:compose可以把类似于f(g(h(x)))这种写法简化成compose(f, g, h)(x),请你完成 compose函数的编写
② 答题
function compose(...funcs){
return function(x){
let result,
len=funcs.length;
if(len===0){
//一个函数传递,那就把参数直接返回
result=x;
}else if(len===1){
// 只传递了一个函数
result=funcs[0](x);
}else{
// funcs参数执行顺序从右到左
result=funcs.reduceRight((result, item) => {
if(typeof item !== 'function') return result;
return item(result);
},x);
}
return result;
}
}
△ 实现compose组合函数
七、 redux的compose函数
1 / redux 中的compose函数
function compose(...funcs) {
if (funcs.length === 0) {
return arg => arg
}
if (funcs.length === 1) {
return funcs[0]
}
return funcs.reduce((a, b) => (...args) => a(b(...args)))
}
△ redux中的compose函数
我们普通写调用函数,但是可读性太差
const add1 = x => x + 1;
const mul3 = x => x * 3;
const div2 = x => x / 2;
div2(mul3(add1(add1(0)))); //=>3
△ 普通调用函数
那么,需要写一个可读性较高的组合函数:
const operate = compose(div2, mul3, add1, add1);
operate(0);
△ 调用compose函数
compose(div2, mul3, add1, add1)传参的顺序与div2(mul3(add1(add1(0)))) 调用函数的顺序关系
那么,我们上次写的reduceRight从里面往外调用函数实现组合函数的调用
然而,redux使用的是reduce按照输入参数的顺序调用的
2 / 逐步分析
咱们就根据:执行上下文、作用域、作用域链、VO、AO这些一步步分析即可
// funcs=[div2,mul3, add1, add1] 函数集合
// return funcs.reduce((a, b) => (...args) => a(b(...args)))
return funcs.reduce((a, b) => {
let fn = (x) => {
return a(b(x));
};
return fn;
});
△ 分析reduce的写法
(1)compose()函数调用
【0】EC(C001) 假设这是compse() 执行形成的执行上下文
operate 是一个函数
那么 ,compose return 出去的是一个函数
let result = funcs.reduce((a,b)=>{
return function anonymous(x){
return a(b(x));
};
});
△ result 得到的是一个函数
result 接收到的结果是一个函数
此时,需要通过reduce每次调用callback形成 函数私有上下文
在每次的函数的私有上下文中,都会创建一个匿名函数
每个匿名函数所处的作用域是不同的
代码执行到:funcs.reduce(callback)
① reduce第一轮遍历
**【1】 第一轮遍历 EC(CB1)**私有执行上下文
AO(CB1) 变量对象
a=div2
b=mul3
anonymous=0xA001
作用域链:<EC(CB1), EC(C001)>
形参赋值:a=div2; b=mul3
变量提升:anonymous=0xA001
代码执行:
return function anonymous(x){
a(b(x));
}; //=====> 【return 0xA001】;
△ 第一轮循环返回的值
② reduce第一轮遍历
【2】第二轮遍历 EC(CB2) 私有执行上下文
AO(CB2) 变量对象
a=0xA001
b=add1
anonymous=0xA002
作用域链:<EC(CB2), EC(C001)>
形参赋值:a=0xA001; b=add1
变量提升:anonymous=0xA002
代码执行:
return function anonymous(x){
a(b(x));
}; //=> 【return 0xA002】;
△ 第二轮循环返回的值
③ reduce第三轮遍历
**【3】第三轮遍历 EC(CB3)**私有执行上下文
AO(CB3) 变量对象
a=0xA002
b=add1
anonymous=0xA003
作用域链:<EC(CB3), EC(C001)>
形参赋值:a=0xA003; b=add1
变量提升:anonymous=0xA003
代码执行:
return function anonymous(x){
a(b(x));
}; //=> 【return 0xA003】;
△ 第三轮循环返回的值
(4)reduce遍历结束后,赋值
三轮遍历结束后,把0xA003 赋值给operate
operate(0) 执行
③ 0xA003(0) 执行
【3】EC(0xA003)
AO(0xA003)
x=0
作用域链:<EC(0xA003),EC(CB3) >
形参赋值:x=0
代码执行:
a(b(x));
=> x 是自己的:x=0; a和b都是上级上下文的
=> a=0xA002
=> b=add1
==> 0xA002(add1(0))
=> add1(0) => x+1=1
=> add1(0) 就当它是最后结果了,为了最后看到的效果是一样的,就不写计算了
=> 0xA002() 调用
② 0xA002() 调用
【2】EC(0xA002)
AO(0xA002)
x = add1(0)
作用域链:<EC(0xA002),EC(CB2) >
形参赋值:x=add1(0)
代码执行:
a(b(x));
=> x 是自己的:x=add1(0);a和b都是上级上下文的
=> a=0xA001
=> b=add1
==> 0xA001(add1(add1(0)))
=> add1(add1(0))就当是计算后的结果了
=> 0xA001() 调用
① 0xA001() 调用
【1】EC(0xA001)
AO(0xA001)
x = add1(add1(0))
作用域链:<EC(0xA001),EC(CB1) >
形参赋值:x = add1(add1(0))
代码执行:
a(b(x));
=> x 是自己的:x=add1(add1(0)); a和b都是上级上下文的
=> a=div2
=> b=mul3
==> div2(mul3(add1(add1(0))))
即:div2(mul3(add1(add1(0))))
八、 闭包应用之循环事件绑定的N种解决办法
(1)事件绑定
<button>我是1</button>
<button>我是2</button>
<button>我是3</button>
△ html
var buttons = document.querySelectorAll('button'); //=> NodeList “类数组”集合
for(var i = 0; i < buttons.length; i++){
buttons[i].onclick = function (){
console.log(`当前按钮的索引:${i}`);
};
}
△ JS 代码
问:以上的JS代码,能依次点击按钮能输出对应的索引吗?
△ 图1_事件执行
每次点击触发函数执行时,获取的i都是全局的,也就是循环结束后的结果3
那么,如何解决这个问题呢?
(2)方案一:基于闭包的机制完成
第一种闭包
var buttons = document.querySelectorAll('button');
for(var i = 0; i < buttons.length; i++){
(function (i){
/*【自执行匿名函数】
每一轮循环都会形成一个闭包
存储私有变量i的值,当前循环传递进来的i值
(1)自执行函数执行,产生一个私有的执行上下文EC(A),私有形参变量i=0/1/2
(2)EC(A) 上下文中创建一个小函数,并让全局的buttons中的某一项占用创建的小函数
*/
buttons[i].onclick = function (){
console.log(`当前按钮的索引:${i}`);
};
})(i);
}
△ 自执行函数
△ 图2_自执行函数图解
基于 闭包 的机制,每一轮循环时都会产生一个闭包,存储对应的索引。点击事件触发,执行对应的函数,让其上级上下文是闭包即可
第二种闭包
基于这个思路,还可以这样写,只要产生闭包就好啦
var buttons = document.querySelectorAll('button');
for(var i = 0; i < buttons.length; i++){
buttons[i].onclick = (function (i){
return function (){
console.log(`当前按钮的索引:${i}`);
};
})(i);
}
△ 闭包:自执行函数
let obj = {
fn:(function() {
// 自执行函数:把return的小函数赋值给obj.fn了
console.log('大函数');
return function () {
console.log('小函数');
};
})()
};
obj.fn(); //=> 每次调用时,执行的是【小函数】这个函数
第三种闭包
var buttons = document.querySelectorAll('button');
for (let i = 0; i < buttons.length; i++) {
buttons[i].onclick = function () {
console.log(`当前按钮的索引:${i}`);
};
}
△ 通过let形成闭包
(3)方案二:自定义属性
自定义属性的性能要比闭包好。
循环多少次闭包会形成多少个执行上下文,那如果有100个按钮,1000个按钮呢?非常耗性能
var buttons = document.querySelectorAll('button');
for (var i = 0; i < buttons.length; i++) {
// 每一轮循环都给当前按钮(对象)设置一个自定义属性:存储它的索引
buttons[i].myIndex = i;
buttons[i].onclick = function () {
// this:当前点击的按钮
console.log(`当前按钮的索引:${this.myIndex}`);
};
}
△ 自定义属性
△ 图3_自定义属性
(4)方案三:事件委托
<button index='0'>我是1</button>
<button index='1'>我是2</button>
<button index='2'>我是3</button>
△ 添加自定义属性
事件委托:不论点击BODY中的谁,都会触发BODY的点击事件
ev.target 是事件源:具体点击的是谁
document.body.onclick = function (ev){
var target = ev.target,
targetTag = target.tagName;
// 点击的是【BUTTON 按钮】
if(targetTag === 'BUTTON'){
var index = target.getAttribute('index');
console.log(`当前按钮的索引:${index}`);
}
};
△ 事件委托
在闭包中要占用栈内存,自定义属性中要占用对象堆内存空间写属性,而 事件委托 并没有额外的占用这些空间,性能是最好的
九、 函数防抖(debounce)和函数节流(throttle)
函数的防抖(debounce)和节流(throttle)
在 高频 触发的场景下,需要进行防抖和节流,比如:
① 狂点一个按钮 给你的爱豆投票的按钮
② 页面滚动 一下加载500+的数据,往下滚动的时候
③ 输入模糊匹配 百度的搜索条,每次输入都在触发搜索的接口
④ ……
函数防抖debounce
function debounce(func, wait, immediate){
if(typeof func !== 'function') throw new TypeError('func must be a function');
if(typeof wait === 'undefined') wait = 500;
if(typeof wait === 'blloelan') {
immediate = wait;
wait = 500;
}
if(typeof immediate !== 'boolean') immediate = false;
let timer = null;
return function proxy(...args){
let self = this,
now = immediate && !timer;
clearTimeout(timer);
timer = setTimeout(()=>{
timer = null;
!immediate ? func.call(self, ...args) : null;
}, wait);
now ? func.call(self, ...args) : null;
}
}
△ 函数防抖debounce
函数节流 throttle
function throttle(func, wait){
if(typeof func !== 'function') throw new TypeError('func must be a function');
if(typeof wait === 'undefined') wait = 500;
let timer = null,
previous = 0;
return function proxy(...args){
let self = this,
now = new Date(),
remaining = wait - (now - previous);
if(remaining <= 0) {
clearTimeout(timer);
timer = null;
previous = now;
func.call(self, ...args);
} else if(!timer){
timer = setTimeout(function (){
clearTimeout(timer);
timer = null;
previous = new Date();
func.call(self, ...args);
}, remaining);
}
};
}
function handle(){
console.log('world');
}
window.onscroll = throttle(handle, 500);
// window.onscroll = proxy;
△ 函数节流
十、 严格模式VS非严格模式的区别
开启严格模式:在执行上下文的最顶部"use strict";或者'use strict';
严格模式同时改变了 语法及 运行时行为,分为几类:
1、将问题直接转化为错误,比如:语法错误或运行时错误
(1)严格模式下无法创建全局变量
"use strict";
n = 12; //=>Uncaught ReferenceError: n is not defined
(2)严格模式下给NaN赋值、给不可写属性赋值、给制度属性赋值、给不可扩展对象的新属性赋值,都会抛出异常
"use strict";
NaN = 12;// Uncaught TypeError: Cannot assign to read only property 'NaN' of object '#<Window>'
"use strict";
let obj = {};
Object.defineProperty(obj, 'x', {value:12, writable:false});
obj.x = 11; //Uncaught TypeError: Cannot assign to read only property 'x' of object '#<Object>'
"use strict";
let obj1 = {get y() {return 11;}};
obj1.y = 12; // Uncaught TypeError: Cannot set property y of #<Object> which has only a getter
"use strict";
let obj2 = {};
Object.preventExtensions(obj2);
obj2.newProp = 'hello'; // Uncaught TypeError: Cannot add property newProp, object is not extensible
(3)严格模式下,删除不可删除的属性报错
"use strict";
delete Object.prototype; // Uncaught TypeError: Cannot delete property 'prototype' of function Object() { [native code] }
(4)严格模式下,函数参数名唯一
"use strict";
function sum(a, a, c) { //Uncaught SyntaxError: Duplicate parameter name not allowed in this context
return a + a + c;
}
(5)严格模式下的八进制
ES6中支持用0o表示八进制,在浏览器中支持以0开头的八进制语法
"use strict";
var sum = 015 + // Uncaught SyntaxError: Octal literals are not allowed in strict mode.
197 +
142;
// 写成 0o15
(6)非严格模式会忽略,严格模式下报错
(function () {
"use strict";
false.true = ""; // Uncaught TypeError: Cannot create property 'true' on boolean 'false'
(14).sailing = "home"; // Uncaught TypeError: Cannot create property 'sailing' on number '14'
"with".you = "far away"; // Uncaught TypeError: Cannot create property 'you' on string 'with
})();
2、简化变量的使用
(1)严格模式下禁用with
var x = 12;
var obj = {x:11};
with(obj) {
console.log(x); //=> 11。是obj上的【非严格模式】
};
(2)严格模式下的eval不再为上层范围引入新变量
var x = 17;
var evalX = eval(" var x = 42;x");
console.log(x, evalX); //=> 42 42
var x = 17;
var evalX = eval("'use strict'; var x = 42; x");
console.log(x, evalX);//=> 17 42
(3)严格模式进制删除声明变量,非严格模式下忽略
"use strict";
var x;
delete x; // Uncaught SyntaxError: Delete of an unqualified identifier in strict mode.
eval("var y; delete y;"); // !!! 语法错误
3、简化了eval以及arguments
(1)以下都会报语法错误:eval/arguments 不允许做变量名
"use strict";
eval = 17;
arguments++;
++eval;
var obj = { set p(arguments) { } };
var eval;
try { } catch (arguments) { }
function x(eval) { }
function arguments() { }
var y = function eval() { };
var f = new Function("arguments", "'use strict'; return 17;");
(2)严格模式下,参数的值不会碎arguments 对象的值的变化而变化。切断映射关系
function f(a) {
a = 42;
return [a, arguments[0]];
}
var pair = f(17);
console.log(pair); //[42, 42]
function f(a) {
"use strict";
a = 42;
return [a, arguments[0]];
}
var pair = f(17);
console.log(pair); //[42, 17]
(3)严格模式下,不支持arguments.callee, 直接使用函数名即可
"use strict";
var f = function() { return arguments.callee; };
f(); // 抛出类型错误
4、“安全的”JS
(1)函数执行主体THIS,严格模式下,传啥就是啥
"use strict";
function fun() { return this; }
console.assert(fun() === undefined);
console.assert(fun.call(2) === 2);
console.assert(fun.apply(null) === null);
console.assert(fun.call(undefined) === undefined);
console.assert(fun.bind(true)() === true);
function fun() { return this; }
console.log(fun() === undefined, fun()); // window
console.log(fun.call(2) === 2, fun.call(2)); // Number(2)
console.log(fun.apply(null) === null, fun.apply(null)); // window
console.log(fun.call(undefined) === undefined, fun.call(undefined)); // window
console.log(fun.bind(true)() === true, fun.bind(true)()); // Boolean(true)
(2)严格模式下,不允许使用fn.caller/fn.arguments(不可被删除的属性)了
function restricted() {
"use strict";
restricted.caller; // 抛出类型错误
restricted.arguments; // 抛出类型错误
}
function privilegedInvoker() {
return restricted();
}
privilegedInvoker();
(3)严格模式下,arguments.caller不允许使用了(在严格模式下也是不可删除属性)
"use strict";
function fun(a, b) {
"use strict";
var v = 12;
return arguments.caller; // 抛出类型错误
}
fun(1, 2); // 不会暴露v(或者a,或者b)
5、为未来的ECMAScript版本铺路
(1)严格模式下一部分字符变成了保留的关键字:implements/interface/let/package/private/public/yield/static,严格模式下,不允许用作变量名或形参名
(2)严格模式下,禁止了不在脚本或者函数层面上的函数声明
"use strict";
if (true) {
function f() { } // !!! 语法错误
f();
}
for (var i = 0; i < 5; i++) {
function f2() { } // !!! 语法错误
f2();
}
function baz() { // 合法
function eit() { } // 同样合法
}
