

vue相关
vue 响应式原理
-
数据改变触发set => set部分触发notify => 更改对应虚拟dom (diff算法)=> 重新render(注意get部分有个收集依赖)
-
手写简单响应式
//vue2.0 响应式 <!DOCTYPE html> <html> <head> <meta charset = "UTF-8"> </head> <body> <div id="app"></div> </body> <script> function vue(){ this.$data = {a: 1}; this.el = document.getElementById('app'); this.virtualdom=""; this.observe(this.$data); this.render(); } vue.prototype.observe= function(obj){ var _this = this let value; for(let key in obj){ value = obj[key] if(value instanceof Object){ this.observe(value)//嵌套对象会循环调用自己 }else { Object.defineProperty(obj,key,{ get: function(){ //省略了依赖收集 return value }, set: function(newValue){ value = newValue; //省略了触发依赖 _this.render(); } }) } } } vue.prototype.render = function(){ //省略了收集视图模板,生成js语法树 this.virtualdom = 'i am' + this.$data.a; this.el.innerHTML = this.virtualdom; } let vm = new vue(); setTimeout(() => { vm.$data.a = 2; }, 2000); </script> </html> -
数组的响应式
vue2.0中 只能使用push,shift等改变数据,直接通过下标改变不能触发更新
var methodsToPatch = [ 'push', 'pop', 'shift', 'unshift', 'splice', 'sort', 'reverse' ];//数组监听实现 var newArr = ['liyuqing']; //新建一个数组实例 var arr = Object.create(Array.prototype); //会重新的方法 var methodsToPatch = [ 'push', 'pop', 'shift', 'unshift', 'splice', 'sort', 'reverse' ]; // 重写方法() methodsToPatch.forEach( fn =>{ arr[fn] = function(){ var ret = Array.prototype[fn].apply(this,arguments); //dep.notify() console.log(fn) return ret } }) //重新设置数组实例的原型 Object.setPrototypeOf(newArr,arr) newArr.push('caoyang') console.log(newArr)
依赖收集
-
Vue要能够知道一个数据是否被使用,实现这种机制的技术叫做
依赖收集; -
Vue与Vue的依赖收集
Vue能够实现当一个数据变更时,视图就进行刷新,而且用到这个数据的其他地方也会同步变更;而且,这个数据必须是在有被依赖的情况下,视图和其他用到数据的地方才会变更。

-
每个组件实例都有相应的
watcher实例 -
渲染组件的过程,会把属性记录为依赖
-
当我们操纵一个数据时,依赖项的
setter会被调用,从而通知watcher重新计算,从而致使与之相关联的组件得以更新所以在getter里,我们进行依赖收集(所谓依赖,就是这个组件所需要依赖到的数据),当依赖的数据被设置时,setter能获得这个通知,从而告诉
render()函数进行重新计算。
-
-
依赖收集与观察者模式
我们会发现,上述vue依赖收集的场景,正是一种
一对多的方式(一个数据变更了,多个用到这个数据的地方要能够做出处理),而且,依赖的数据变更了,就一定要做出处理,所以观察者模式天然适用于解决依赖收集的问题。 那么,在Vue依赖收集里:谁是观察者?谁是观察目标? 显然:- 依赖的数据是
观察目标 - 视图、计算属性、侦听器这些是
观察者
和观察者模式实现代码相对应的,做出
notify动作可以在setter里进行,做出addObserver()动作,则可以在getter里进行。 - 依赖的数据是
-
从源码解析依赖收集
-
角色
Vue源码中实现依赖收集,实现了三个类:
-
Dep:扮演观察目标的角色,每一个数据都会有Dep类实例,它内部有个subs队列,subs就是subscribers的意思,保存着依赖本数据的观察者,当本数据变更时,调用dep.notify()通知观察者 -
Watcher:扮演观察者的角色,进行观察者函数的包装处理。如render()函数,会被进行包装成一个Watcher实例 -
Observer:辅助的可观测类,数组/对象通过它的转化,可成为可观测数据
-
每一个数据都有的
Dep类实例Dep类实例依附于每个数据而出来,用来管理依赖数据的Watcher类实例let uid = 0; class Dep { static target = null; // 巧妙的设计! constructor() { this.id = uid++; this.subs = []; } addSub(sub) { this.subs.push(sub); } removeSub(sub) { this.subs.$remove(sub); } depend() { Dep.target.addDep(this); } notify() { const subs = this.subs.slice(); for (let i = 0, l = subs.length; i < l; i++) { subs[i].update(); } } }由于JavaScript是单线程模型,所以虽然有多个
观察者函数,但是一个时刻内,就只会有一个观察者函数在执行,那么此刻正在执行的那个观察者函数,所对应的Watcher实例,便会被赋给Dep.target这一类变量,从而只要访问Dep.target就能知道当前的观察者是谁。 在后续的依赖收集工作里,getter里会调用dep.depend(),而setter里则会调用dep.notify()每个被观测的数据都对应一个Dep类实例,这个实例subs队列中可包含多个watcher实例;即实现一个数据变化,会使得与之相关联的视图,计算属性,等相应变化;
-
总结

-
render函数
-
render函数返回的是虚拟DOM树,render函数通过createElement(h) 创建虚拟dom树
//简洁版 import App from './App' render: h => h(App) // render: function(createElement){ return createElement('h3',[ createElement( 'a', { domProps : { href: this.title } }, ) ]) } -
createElement方法是render函数的核心
虚拟Dom
- Virtual Dom就是一种通过VNode类表达的,每个Dom元素或者组件都对应一个VNode对象,使用virtual dom可以充分的发挥js的编程能力,VNode大致可分为以下几类:
- TextVNode 文本节点
- ElementVNode 普通节点
- ComponentVNode 组件节点
- EmptyVNode 没有内容的注释节点
- CloneVNode 复制节点,可以为以上任意一种,只是VNodedata.isCloned 属性为true
-
查看Vnode 基本格式
在vue.js 源码中的_createElement方法中打印他的返回值Vnode即可;
注意Vnode是获取到变量值的,所以当函数执行或者变量的时候,进行依赖收集,即执行渲染此组件方法的watcher会被add,因此当组件用到的数据变化时,就会渲染此组件;
diff算法
-
真实dom 解析流程
浏览器渲染引擎工作流程都差不多,大致分为5步,创建DOM树——创建StyleRules——创建Render树——布局Layout——绘制Painting
第一步,用HTML分析器,分析HTML元素,构建一颗DOM树(标记化和树构建)。
第二步,用CSS分析器,分析CSS文件和元素上的inline样式,生成页面的样式表。
第三步,将DOM树和样式表,关联起来,构建一颗Render树(这一过程又称为Attachment)。每个DOM节点都有attach方法,接受样式信息,返回一个render对象(又名renderer)。这些render对象最终会被构建成一颗Render树。
第四步,有了Render树,浏览器开始布局,为每个Render树上的节点确定一个在显示屏上出现的精确坐标。
第五步,Render树和节点显示坐标都有了,就调用每个节点paint方法,把它们绘制出来。
**DOM树的构建是文档加载完成开始的?**构建DOM数是一个渐进过程,为达到更好用户体验,渲染引擎会尽快将内容显示在屏幕上。它不必等到整个HTML文档解析完毕之后才开始构建render数和布局。
**Render树是DOM树和CSSOM树构建完毕才开始构建的吗?**这三个过程在实际进行的时候又不是完全独立,而是会有交叉。会造成一边加载,一遍解析,一遍渲染的工作现象。
CSS的解析是从右往左逆向解析的(从DOM树的下-上解析比上-下解析效率高),嵌套标签越多,解析越慢。

-
JS操作真实Dom的代价
用我们传统的开发模式,原生JS或JQ操作DOM时,浏览器会从构建DOM树开始从头到尾执行一遍流程。在一次操作中,我需要更新10个DOM节点,浏览器收到第一个DOM请求后并不知道还有9次更新操作,因此会马上执行流程,最终执行10次。例如,第一次计算完,紧接着下一个DOM更新请求,这个节点的坐标值就变了,前一次计算为无用功。计算DOM节点坐标值等都是白白浪费的性能。即使计算机硬件一直在迭代更新,操作DOM的代价仍旧是昂贵的,频繁操作还是会出现页面卡顿,影响用户体验。
-
为什么需要虚拟DOM ?它有什么好处?
虚拟DOM就是为了解决浏览器性能问题而被设计出来的。如前,若一次操作中有10次更新DOM的动作,虚拟DOM不会立即操作DOM,而是将这10次更新的diff内容保存到本地一个JS对象中,最终将这个JS对象一次性attch到DOM树上,再进行后续操作,避免大量无谓的计算量。**所以,**用JS对象模拟DOM节点的好处是,页面的更新可以先全部反映在JS对象(虚拟DOM)上,操作内存中的JS对象的速度显然要更快,等更新完成后,再将最终的JS对象映射成真实的DOM,交由浏览器去绘制。
-
实现虚拟Dom
例如一个真实的DOM节点。

用JS来模拟DOM节点实现虚拟DOM。

虚拟DOM其中的Element方法具体怎么实现的呢?

Element方法实现
第一个参数是节点名(如div),第二个参数是节点的属性(如class),第三个参数是子节点(如ul的li)。除了这三个参数会被保存在对象上外,还保存了key和count。其相当于形成了虚拟DOM树。

虚拟DOM树
有了JS对象后,最终还需要将其映射成真实DOM

虚拟DOM对象映射成真实DOM
-
diff 算法
我们已经完成了创建虚拟DOM并将其映射成真实DOM,这样所有的更新都可以先反应到虚拟DOM上,如何反应?需要用到Diff算法。
两棵树如果完全比较时间复杂度是O(n^3),但参照《深入浅出React和Redux》一书中的介绍,React的Diff算法的时间复杂度是O(n)。要实现这么低的时间复杂度,意味着只能平层的比较两棵树的节点,放弃了深度遍历。这样做,似乎牺牲掉了一定的精确性来换取速度,但考虑到现实中前端页面通常也不会跨层移动DOM元素,这样做是最优的。
-
深度优先遍历,记录差异
在实际代码中,会对新旧两棵树进行一个深度的遍历,每个节点都会有一个标记。每遍历到一个节点就把该节点和新的树进行对比,如果有差异就记录到一个对象中。
下面我们创建一棵新树,用于和之前的树进行比较,来看看Diff算法是怎么操作的。

old Tree

new Tree
平层Diff,只有以下4种情况:
1、节点类型变了,例如下图中的P变成了H3。我们将这个过程称之为REPLACE。直接将旧节点卸载并装载新节点。旧节点包括下面的子节点都将被卸载,如果新节点和旧节点仅仅是类型不同,但下面的所有子节点都一样时,这样做效率不高。但为了避免O(n^3)的时间复杂度,这样是值得的。这也提醒了开发者,应该避免无谓的节点类型的变化,例如运行时将div变成p没有意义。
2、节点类型一样,仅仅属性或属性值变了。我们将这个过程称之为PROPS。此时不会触发节点卸载和装载,而是节点更新。

查找不同属性方法
3、文本变了,文本对也是一个Text Node,也比较简单,直接修改文字内容就行了,我们将这个过程称之为TEXT。
4、移动/增加/删除 子节点,我们将这个过程称之为REORDER。看一个例子,在A、B、C、D、E五个节点的B和C中的BC两个节点中间加入一个F节点。

例子
我们简单粗暴的做法是遍历每一个新虚拟DOM的节点,与旧虚拟DOM对比相应节点对比,在旧DOM中是否存在,不同就卸载原来的按上新的。这样会对F后边每一个节点进行操作。卸载C,装载F,卸载D,装载C,卸载E,装载D,装载E。效率太低。
如果我们在JSX里为数组或枚举型元素增加上key后,它能够根据key,直接找到具体位置进行操作,效率比较高。常见的最小编辑距离问题,可以用Levenshtein Distance算法来实现,时间复杂度是O(M*N),但通常我们只要一些简单的移动就能满足需要,降低精确性,将时间复杂度降低到O(max(M,N))即可。

最终Diff出来的结果
-
映射成真实DOM
虚拟DOM有了,Diff也有了,现在就可以将Diff应用到真实DOM上了。深度遍历DOM将Diff的内容更新进去。

根据Diff更新DOM

根据Diff更新DOM
-
-
总结
我们会有两个虚拟DOM(js对象,new/old进行比较diff),用户交互我们操作数据变化new虚拟DOM,old虚拟DOM会映射成实际DOM(js对象生成的DOM文档)通过DOM fragment操作给浏览器渲染。当修改new虚拟DOM,会把newDOM和oldDOM通过diff算法比较,得出diff结果数据表(用4种变换情况表示)。再把diff结果表通过DOM fragment更新到浏览器DOM中。
虚拟DOM的存在的意义?vdom 的真正意义是为了实现跨平台,服务端渲染,以及提供一个性能还算不错 Dom 更新策略。vdom 让整个 mvvm 框架灵活了起来
Diff算法只是为了虚拟DOM比较替换效率更高,通过Diff算法得到diff算法结果数据表(需要进行哪些操作记录表)。原本要操作的DOM在vue这边还是要操作的,只不过用到了js的DOM fragment来操作dom(统一计算出所有变化后统一更新一次DOM)进行浏览器DOM一次性更新。其实DOM fragment我们不用平时发开也能用,但是这样程序员写业务代码就用把DOM操作放到fragment里,这就是框架的价值,程序员才能专注于写业务代码**。**链接:www.jianshu.com/p/af0b39860…
vue异步渲染
-
为什么vue要异步渲染
因为如果不采用异步渲染,这样每次数据更新都会组更新渲染这个组件,而且为了这个组件所有的更改结束后统一渲染,因此为了性能考虑,会在本轮数据更新后,再去渲染;
-
过程
dep.notify() => watcher.upDate() => queueWatcher() => nextTick(flushSchedulerQueue)
nextTick实现原理
-
简单来说就是将flushSchedulerQueue(用于遍历运行每个Watcher的更新方法),封装成异步方法,优先是封装成promise,或者setImmediate(fn)或者setTimeout(fn,0),也就是利用了js的事件循环机制,将微任务或者宏任务在本轮事件循环结束或者宏任务开始时运行;(具体实现可参照源码)
-
过程
nextTick(cb) => callbacks.push(cb) => TimeFunc()(是优先promise封装的异步方法)
computed,watch,method的特点
-
computed可以让我们很好的监听多个数据或者一个数据来维护返回一个状态值,只要其中一个或多个数据发生变化,则会重新计算整个函数体.computed对象里的属性无需在data里声明,computed有缓存,一般用于多个数据改变,返回一个值的情况
watch 对象里的属性需要事先在data里声明,一般用于一个数据改变影响多个的情况;
method一般用于和用户的交互逻辑操作;不建议{{fn()}},可以直接通过computed获取;如果组件中的数据变化了,组件会重新渲染,会重新计算method,而computed要是依赖的数据没有变化的话则会使用之前的计算数据,也就是说computed具有缓存功能;
-
computed 实现过程(源码)
initComputed => new Watcher(lazy,dirty = true,会使的新建watcher时并不会执行watcher的get()方法) => defineComputed(将计算属性绑定在实例上,更改set,get方法) => createComputedGetter()=> watcher.evaluate(修改dirty为false,如果依赖的数据没有更新的话,下次取值会直接取这个值) => get()
watch deep的实现
vue生命周期
-
生命周期
beforeCreate 实例初始化之后,数据未观测之前被调用
created 在实例创建之后被调用,在这一步,实例已完成一下的配置:数据观测,属性和方法的运 算,watch/event 事件回调,但是这里没有$el
beforeMount 在挂载之前被调用,相关的render函数首次被调用(用的较少)
mounted el被新创建的vm.$el替换,并挂载到实例上去之后调用该钩子
beforeUpdate 数据更新时调用,发生在虚拟dom更新渲染和打补丁之前
updated 由于数据更新会导致虚拟dom更新渲染和打补丁,这个钩子再次之后被调用
beforeDestroy 实例销毁之前被调用,实例完全可用
destroyed 实例销毁后调用,调用后,vue实例指示的所有东西都会解除绑定,所有的事件监听器会
被移除,所有的子实例也会被销毁。
-
比较常用的生命周期,一般做什么操作
created: 实例已经创建完毕,可以进行异步请求去请求数据
mounted: 可以进行dom的一些操作
beforeUpdate: 可以进一步的更改状态,这不会触发附加的重渲染过程
updated: 可以执行依赖于dom的操作,但是不能在此更新状态,否则会造成死循环;
beforeDestroy: 实例销毁之前解除事件的绑定,或者清除定时器等等;
-
源码
//index.js function Vue{ this._init(options) } initMixin(Vue) //初始化_init方法 stateMixin(Vue) //初始化$set $delete $watch方法 eventsMixin(Vue) //初始化vue中的$on $emit事件 lifecycleMixin(Vue) //初始化_update方法 renderMixin(Vue) //初始化_render方法//Vue.prototype._init Vue.prototype._init = function(){ initLifecycle(vm) //初始化组件的父子关系 initEvents(vm) //初始化组件事件 initRender(vm) //初始化slot以及createElement方法 callHook(vm, 'beforeCreate') //无法获取实例的数据 initInjections(vm) // resolve injections before data/props initState(vm) //初始化状态 initProvide(vm) // resolve provide after data/props callHook(vm, 'created') // 可以获取数据 }vm.$mount | mount.call | $mount() 挂载组件 | mountComponent 进行组件的挂载 | callhook(vm,'beforeMount') | vm._update(vm._render()) 初次渲染和更新会执行此方法 | callhook(vm,'mounted') | 当页面数据变化时,触发beforeUpdate,updated方法 | 实例要销毁时,会调用beforeDrestroy destroyed方法
ajax 放在哪个生命周期中
- created之后都可以,一般是放在created或者mounted这两个钩子中,created不能操作dom,mounted可以,多以一般统一放在mounted中,但是要是服务端渲染的话,一般都是放在created中;
beforeDestroy 什么时候调用
-
当前组件中使用了$on
在组件(当前组件实例)的emit的执行原理:
emit在事件中心找到对应的自定义事件后调用事件
$off 在当前时间中心取消订阅
methods: { changename(){ // this.$off('msg') //取消订阅msg事件 this.$emit('msg','hahahaha') //发布msg事件 }, }, mounted(){ this.$on('msg',function(msg){//订阅msg事件 this.name = msg }) },父子组件通过@传递事件详解:
父组件在编译模板后将子组件(@自定义事件="回调")的自定义事件及其回调通过$on添加到子组件的事件中心(this._events)
-
清除当前组件的定时器 clearTimeout(timer) clearInterval(timer) this.timer = null;
-
解绑自定义的原生事件 removeEventListener()
模板引擎的实现
编译template
`<div id="container"><p>hello<span>zf</span></p></div>`
生成ast(抽象语法树)
{
tag: 'div',
type: 1, //普通节点
children: [{
tag: 'p',
type: 1,
children: [Array],
attrs: [],
parent: [Circular]
}
],
attrs: [{name: 'id',value: 'container'}],
parent: null
}
//和虚拟DOM树的区别,虚拟DOM是描述真实节点的,对应的变量的值都有获取到,这个是描述编译后的模板的,vue中对静态节点打了个标记,优化性能
遍历ast对象,生成一串字符串
_c('div',{attrs: {id:container}},[_c('p',[_v("hello"),_c('span',[_v('zf')])])])
用with封装成新的字符串
`with(this){return _c('div',{attrs: {id:container}},[_c('p',[_v("hello"),_c('span',[_v('zf')])])])}`
//目的是绑定当前实例作用域
在利用new Function()封装成render函数
var renderfn = new Function(`with(this){return 遍历ast生成的字符串}`)
console.log(renderfn.toString())
ƒ anonymous() {
with(this){return 遍历ast生成的字符串}
}
补充知识:with的使用
var obj ={
name: 'lisi'
};
with(obj){console.log(name)}
with执行时,当解析到name变量时,会去获取obj.name;
v-if,v-show的区别
-
v-if
编译的render函数,会先判断v-if对应的变量存不存在,不存在的话就不执行相应的代码;_c,_v等都是vue源码中定义的关于渲染的辅助类函数;
-
v-show(可查看源码对于不同vue指令的处理)
el.style.display = value ? originalDisplay : 'none'
为什么v-for,v-if不能连用
-
v-for的优先级要比v-if要早
let vue = require('vue'); let vueCompiler = require('vue-template-compiler') var ast = vueCompiler.compile('<div id="container" v-if="show" v-for="i in 3">{{name}}<p>hello<span>zf</span></p></div>') console.log(ast) { ast: { type: 1, tag: 'div', attrsList: [ [Object] ], attrsMap: { id: 'container', 'v-if': 'show', 'v-for': 'i in 3' }, rawAttrsMap: {}, parent: undefined, children: [ [Object], [Object] ], for: '3', alias: 'i', if: 'show', ifConditions: [ [Object] ], plain: false, attrs: [ [Object] ], static: false, staticRoot: false, forProcessed: true, ifProcessed: true }, render: 'with(this){return _l((3),function(i){return (show)?_c(\'div\',{attrs:{"id":"container"}},[_v(_s(name)),_m(0,true)]):_e()})}', staticRenderFns: [ 'with(this){return _c(\'p\',[_v("hello"),_c(\'span\',[_v("zf")])])}' ], errors: [ 'Cannot use v-for on stateful component root element because it renders multiple elements.' ], tips: [] } -
一般v-if,v-for这样使用
<template v-if="show"> <div id="container" v-for="i in 3">{{name}}<p>hello<span>zf</span></p></div> </template> -
如果条件出现在循环内部,可通过计算属性提前过滤掉那些不需要显示的项
diff算法 时间复杂度
- 两棵树的完全diff算法时间复杂度是o(n3),vue进行了一些优化,以牺牲精确性(只考虑同级,不考虑跨级问题)换的性能,时间复杂度为o(n);因为在前端中很少跨越层级的移动DOM
简述vue的diff原理
-
理解
- 先同级比较,再比较子节点
- 先判断一方有儿子,一方没儿子的情况
- 比较都有儿子的情况
- 递归比较子节点
-
原理
双指针法
旧开头---新开头(开头)
旧结尾---新结尾
旧开头---新结尾
旧结尾---新开头
每个节点的key值作比较
为什么要给v-for加key
-
图解
vuex使用与原理
-
vue是基于单向数据流,但是当我们的应用遇到多个组件共享状态时,单向数据流的简洁性很容易被破坏:
- 多个视图依赖于同一状态。
- 来自不同视图的行为需要变更同一状态。
-
图示
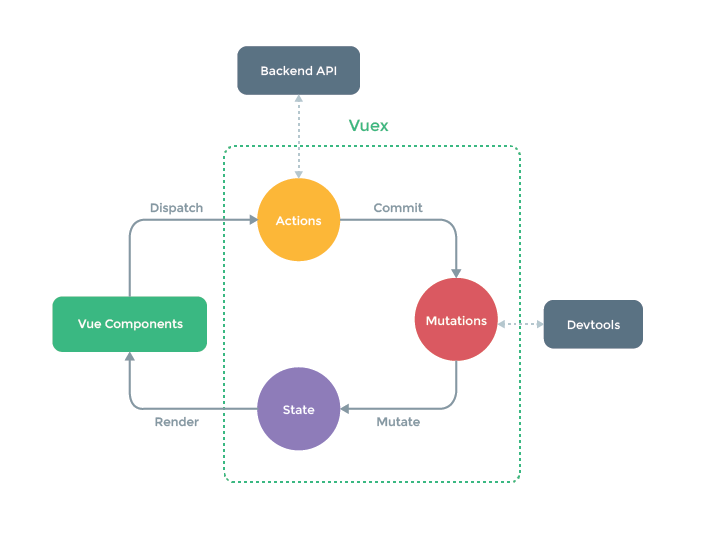
-
基本使用
//store.js import Vue from 'vue' import Vuex from 'vuex' import state from './state' import getters from './getters' import mutations from './mutations' import actions from './actions' Vue.use(Vuex) export default new Vuex.Store({ state, getters, mutations, actions }) //main.js import store from './store/store' new Vue({ router, store, render: h => h(App) }).$mount('#app') //home.vue import { mapState } from 'vuex'; computed: { ...mapState([ 'name', 'age']), } // this.$store.commit('changeName',name) //会去执行mutations对象中的changeName方法, this.$store.dispatch('changeName',name) //会去执行actions对象中的changeName方法,这个方法中允许异步操作 实例:用户打开网站获取登录信息 组件在created阶段请求数据并更新state.userInfo import { mapState, mapActions } from 'vuex' created(){ this.getUserInfo(); }, methods: { ...mapActions(["getUserInfo"]) }, //actions.js import { getUser } from '../service/getData' let actions = { async getUserInfo ({commit},data){ //这是个异步操作 let res = await getUser() commit('GET_USER_INFO',res) } } export default actions; -
vuex源码分析
//vuex对象包含的值 import { Store, install } from './store' import { mapState, mapMutations, mapGetters, mapActions, createNamespacedHelpers } from './helpers' export default {(import vuex from 'vuex') Store, install, version: '__VERSION__', mapState, mapMutations, mapGetters, mapActions, createNamespacedHelpers } export {(import {mapState,mapMutations} from 'vuex') Store, install, mapState, mapMutations, mapGetters, mapActions, createNamespacedHelpers }Vue.use(vuex) //调用的是vuex的install方法 vuex.install = function(Vue){ Vue.mixin({ beforeCreate() { if (this.$options && this.$options.store) { //找到根组件 main 上面挂一个$store this.$store = this.$options.store // console.log(this.$store); } else { //非根组件指向其父组件的$store this.$store = this.$parent && this.$parent.$store } } }) }//此install方法同vueRouter插件的install,这里的this.$options.store是vuex.Store()的实例// src/store.js Vue.Store() 构造方法 constructor (options = {}) { const { plugins = [], strict = false } = options // store internal state this._committing = false this._actions = Object.create(null) this._actionSubscribers = [] this._mutations = Object.create(null) this._wrappedGetters = Object.create(null) this._modules = new ModuleCollection(options) this._modulesNamespaceMap = Object.create(null) this._subscribers = [] this._watcherVM = new Vue() const store = this const { dispatch, commit } = this this.dispatch = function boundDispatch (type, payload) { return dispatch.call(store, type, payload) } this.commit = function boundCommit (type, payload, options) { return commit.call(store, type, payload, options) } // strict mode this.strict = strict const state = this._modules.root.state // init root module. // this also recursively registers all sub-modules // and collects all module getters inside this._wrappedGetters installModule(this, state, [], this._modules.root) // 重点方法 ,重置VM resetStoreVM(this, state) // apply plugins plugins.forEach(plugin => plugin(this)) }// src/store.js function resetStoreVM (store, state, hot) { // 省略无关代码 Vue.config.silent = true store._vm = new Vue({ data: { $$state: state }, computed }) }resetStoreVM(this, state) 他就是整个vuex的关键,去除了一些无关代码后我们发现,其本质就是将我们传入的state作为一个隐藏的vue组件的data,也就是说,我们的commit操作,本质上其实是修改这个组件的data值,结合上文的computed,修改被defineReactive代理的对象值后,会将其收集到的依赖的watcher中的dirty设置为true,等到下一次访问该watcher中的值后重新获取最新值。
这样就能解释了为什么vuex中的state的对象属性必须提前定义好,如果该state中途增加一个属性,因为该属性没有被defineReactive,所以其依赖系统没有检测到,自然不能更新。
由上所说,我们可以得知store._vm.$data.$$state === store.state, 我们可以在任何含有vuex框架的工程验证这一点。
vue路由的两种模式
-
hash,history使用
//hash function VueRouter(options){ this.mode= options.mode||'hash' this.routes = options.routes||[] this.history= new HistoryRoute; this.routesMap = this.createMap(this.routes) this.init(); } VueRouter.prototype.init = function(){ if(this.mode ==='hash'){ location.hash?'':location.hash='/'//自动加# window.addEventListener("load",() =>{ this.history.current=location.hash.slice(1) }) window.addEventListener("hashchange",() =>{ this.history.current=location.hash.slice(1) }) }else(this.mode ==='history'){ location.pathname?'':location.pathname='/'; window.addEventListener("load",() =>{ this.history.current=location.pathname; }) window.addEventListener("popstate",() =>{ this.history.current=location.pathname; }) } } VueRouter.install = function(vue){ if(VueRouter.install.installed) return VueRouter.install.installed = true vue.mixin({ beforeCreate(){ if(this.$options && this.$options.router){ this._root = this; this._router = this.$options.router vue.util.defineReactive(this,'current',this._router.history) }else { this._root = this.$parent._root } } }) vue.component('router-view',{ render(h){ let current = this._self._root._router.history.current; let routerMap = this._self._root._router.routesMap return h(routerMap[current]) } }) vue.component('router-link',{ props:{ to: String }, render(){ } }) }//history window.onpopstate事件介绍 history.pushState()或history.replaceState()不会触发popstate事件 在支持h5的浏览器中,有一个window.onpopstate事件,该事件可以监听如下操作 01.点击浏览器的前进按钮和后退按钮 02.执行js代码history.go(n)/history.forward()/history.back() 注意点: 不同浏览器在加载页面时处理popstate事件的形式存在差异,页面加载时Chrome和Safari通常会出发(emit)popstate事件,但是Fire则不会 需要注意的是调用history.pushState()或history.replaceState()不会触发popstate事件 只有在做出浏览器动作时,才会触发该事件,如用户点击浏览器的回退按钮(或者在Javascript代码中调用history.back()) 特别注意点:并不是只要浏览器点击前进后退按钮或者执行js代码history.go(n)/history.forward()/history.back()就能触发 该事件只针对同一个文档,如果浏览历史的切换,导致加载不同的文档,该事件也不会触发 举例子: 01.先访问www.baidu.com===>这时加载的是百度的首页文档 02.在访问www.taobao.com===>这时加载的是淘宝的的首页文档 03.点击浏览器的返回按钮从www.taobao.com到www.baidu.com就不会触发onpopstate事件 触发情况: 01.当前地址是:www.baidu.com 02.当我们使用了window.history.pushState("", "", '?id=btn2');后 浏览器地址为www.baidu.com?id=2 但是由于window.history.pushState只是使浏览器地址栏显示为 www.baidu.com?id=2,但并不会导致浏览器加载 www.baidu.com?id=2 甚至不会检查www.baidu.com?id=2 是否存在, 所以前后两次都是www.baidu.com这个文档,但是又给浏览器的history添加了一条历史记录 由于前后两次的文档相同,所以点击浏览的返回按钮或者js执行history.back()等操作从www.baidu.com?id=2到www.baidu时 会触发onpopstate事件 -
两种模式优缺点
- hash 一直带个#号,不是很优雅,history的路径则表现很正常;history设置新的URL可以是任意与当前URL同源的URL,而hash只能改变#后面的内容,因此只能设置与当前URL同文档的URL
- history模式,在刷新页面的情况下,有可能404,需要服务端配置,将不同路由的路径,统一指向一个文件;hash模式不会有这个问题的原因是他一直都是一个路径,只是hash值改变了而已;
- pushState()设置的URL与当前URL一模一样时也会被添加到历史记录栈中,而hash模式中,#后面的内容必须被修改才会被添加到新的记录栈中
- pushState()可以通过stateObject参数添加任意类型的数据到记录中,而hash只能添加短字符串
-
服务端渲染如何知道渲染哪个组件
因为在无服务端的情况,要是访问cn.vuejs.org/liyuqing,服务…
为什么要使用异步组件
-
如果组件功能多打包出的结果会变大,我可以采用异步的方式来加载组件,从而实现路由的懒加载。也是事先打包好的chunk块,一般会在main.js里处理请求js文件的逻辑处理,利用jsonp的特性;
-
两种常用方式
-
require -----------这里的require是AMD规范的引入关键词,resolve是全部引入成功以后的回调函数,第一个参数是依赖,require会先引入依赖模块,再执行回调函数。
{ path: '/', name: 'Hello', component: resolve => require(['@component/hello.vue'],resolve) } -
import() ---------import()方法是动态加载,返回一个Promise对象,then方法的参数是加载到的模块。类似于Node.js的require方法,主要import()方法是异步加载的。
const hello = ()=> import('@component/hello.vue')
-
Vue data为什么要求是函数
-
我们都知道,VUE的data实例必须是函数,那么有没有与之相反的情况呢?答案是肯定的,因为VUE的根实例就没有“必须是函数”这个限制的。
-
Vue组件可能存在多个实例,如果使用对象形式定义data,则会导致它们共用一个data对象,那么状态变更将会影响所有组件实例,这是不合理的;
采用函数形式定义,在initData时会将其作为工厂函数返回全新data对象,有效规避多实例之间状态污染问题。
而在Vue根实例创建过程中则不存在该限制,也是因为根实例只能有一个,不需要担心这种情况。
Vue 单向数据流与双向绑定
- 双向绑定
即view层变化改变会修改model层,model层变化会修改view层;
Vue可以说是响应式的,通过defineProperty方法,但不是双向绑定的,v-model 是一个语法糖,实现了双向绑定;
-
单向数据流
vue2.0之后改为单向数据流,为了进一步的解耦,即父级 prop 的更新会向下流动到子组件中,每次父级组件发生更新时,子组件中所有的 prop 都将会刷新为最新的值
- 若是想将父组件传入的值作为初始值,则可以在data声明一个变量,将props对应的值赋值给这个变量,这样,父组件的变化就不会影响子组件
- 若是一种原始的值传入且需要进行转换。在这种情况下,最好使用这个
prop的值来定义一个计算属性;
-
两者关系
两者并没有太大关系
Vue 3.0相关
-
composition-api 相关
-
产生的原因
-
更好的逻辑复用和代码组织
代码组织:当要去理解一个组件时,我们更加关心的是“这个组件是要干什么” (即代码背后的意图) 而不是“这个组件用到了什么选项”。基于选项的 API 撰写出来的代码自然采用了后者的表述方式,然而对前者的表述并不好。
使用composition-api(组合式API) 每个逻辑关注点的代码现在都被组合进了一个组合函数。这大大减少了在处理大型组件时不断“跳转”的需要。同时组合函数也可以在编辑器中折叠起来,使组件更容易浏览:
逻辑复用:
-
更好的类型推导(更加适配TypeScript)
-
-
一些api
/****/reactive() //几乎等价于2.0 Vue.observable() // state 现在是一个响应式的状态 const state = reactive({ count: 0, }) /****/watchEffect(() => { document.body.innerHTML = `count is ${state.count}` }) /****/computed(()=> state.count *2) /****/let count = ref(0)
-
-
Vue3 采用了TS来编写
-
Vue3 中响应式数据原理改成 proxy
-
vdom 的对比算法更新,只更新 vdom 的绑定了动态数据的部分
