

elasticsearch小白入门
介绍
第一次在掘金发表文章,有些不足之处,求勿喷!求勿喷!求勿喷! 身为一个前端,居然搞es原因在于我们公司内部的wiki文档全栈项目的使用,由于日益增多的文章和想要全文检索的需求,并且原本的mongodb数据库,查询全文检索时特别慢,才引入了es。 车300工具平台,项目目前还没公开出来,预计2021年公开。
起源Lucene
一个叫 Doug Cutting 的美国工程师迷上了搜索引擎,他做了一个用于文本搜索的函数库(软件功能组件),命名为Lucene。Lucene是JAVA写的,目标是为各种中小型应用软件加入全文检索功能。因为好用且开源,非常受程序员欢迎。
早期是由这个人自己维护,后期做大后,2001年底,成为Apache软件基金会jakarta项目的一个子项目。
Lucene 是一个信息检索工具包,jar包,不包含搜索引擎系统!
包含了:索引结构、读写索引的工具、排序、搜索规则...工具类!
Lucene 和 Elasticsearch
elasticSearch 是基于Lucene 做了一些封装和增强。es是一个开源的、高拓展的、分布式、全文检索引擎。诞生于21世纪大数据时代。(Restful Api)。2016年超过solr,成为排名第一个的搜索引擎类应用。
Elasticsearch历史
多年前,一个叫做Shay Banon刚结婚不久的失业开发者,由于妻子要去伦敦学习厨师,他就跟老婆一起去了,在他找工作的过程中,为了给妻子构建一个食谱搜索引擎,他就开始使用Lucene工具包开发。由于直接使用原生工具包非常麻烦,于是他就开始抽象化Lucene代码写自己的封装,后来他在找到工作后又重写了 自己的封装,并命名为elasticsearch。
再后来,2010年2月,第一个公开版es发布,es在短时间内瞬间成为当时 github 上最受欢迎的项目之一,一家主营es的公司就此成立,他们一边开发新功能,一边提供商用,并永远开源,
遗憾的是,Shay的妻子依然在等待食谱搜索....
什么是搜索?
1)百度,谷歌。我们可以通过输入一些关键字去搜索我们需要的东西。 2)互联网的搜索:电商网站。招聘网站。新闻网站。各种APP(百度外卖,美团等等) 3)windows系统的搜索等等
总结:搜索无处不在。通过一些关键字,给我们查询出来跟这些关键字相关的信息
什么是全文检索?
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
什么是 Elasticsearch?
使用 java 语言开发的一套开源的全文搜索引擎 用于搜索、日志管理、安全分析、指标分析、业务分析、应用性能监控等多个领域 底层基于
Lucene开源库开发,提供restAPI,可以被任何语言调用 支持分布式部署,可水平扩展 更新迭代快、社区活跃、文档丰富(2020年9月写的这篇文章是7.9.1,而现在11月已经7.10.x了)
自行去官网下载 win linux 及其他版本安装包
链接: elasticsearch下载
ik分词器是一个github项目,可以选择git clone 或者 直接download zip
为了方便演示,这边是windows系统下的教程,linux后续推出如何发布线上等等。
熟悉es目录
bin 是启动目录
config 配置文件
--- log4j2 日志配置文件
--- jvm.options java虚拟机相关配置
--- elasticsearch.yml elasticsearch配置文件,默认 9200 端口!
lib 相关jar包
logs 日志
modules 相关模块
plugins 插件如ik
启动
直接访问 bin 目录下 elasticsearch.bat
安装可视化插件 elasticsearch-head
git clone https://github.com/mobz/elasticsearch-head.git
进入目录后
cnpm install
访问 localhost:9100, 发现跨域问题
去es config目录 的 elasticsearch.yml 添加跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"
*代表所有人都可以访问,实际正式环境不可以这样配置
重启 elasticsearch
这时再访问 localhost:9100 即可
kibana的安装与使用
了解 ELK
了解ELK工程师 ELK是 Elasticsearch Logstash Kibana 三大开源库的简称,市面上也称为 Elastic Stack。其中Elasticsearch是一个基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。像百度、谷歌这种大数据全文搜索引擎的场景都可以使用es这作为底层支持框架,可见es提供的搜索能力确实强大,Logstash 是中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后只支持输出到不同目的地(文件/MQ/redis/es等)。Kibana是一个es可视化工具,提供了实时分析的能力。
收集清洗数据 ---> 搜索,存储 --->Kibana
要保证Kibana版本和es保持一致
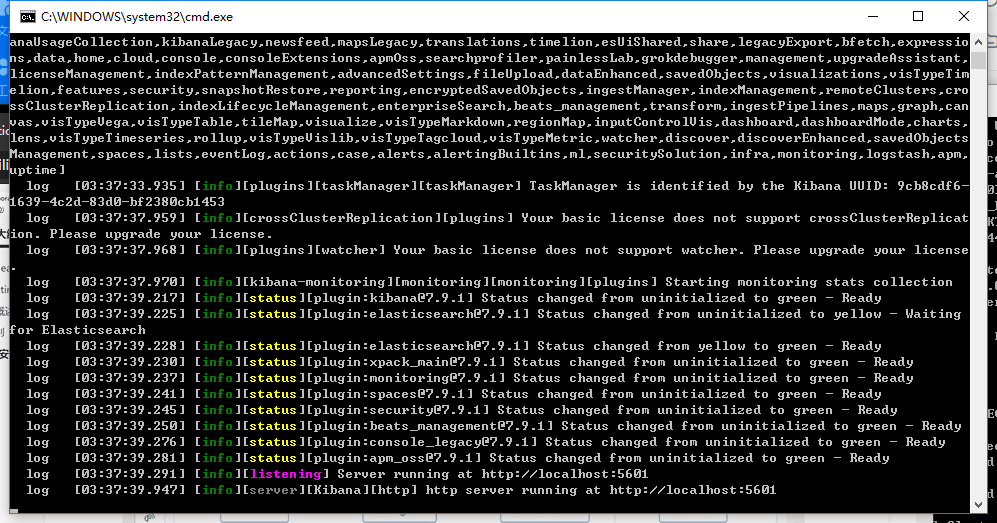
启动
kibana-7.9.1-windows-x86_64\bin 目录下的 kibana.bat
| 
|_
访问 5601端口即可访问
ps:开发工具!(postman等等其他的)
修改汉化
去配置文件D:\tools\kibana-7.9.1-windows-x86_64\config\kibana.yml中修改
i18n.locale: "zh-CN"
es核心概念
es是面向文档的非关系数据库
| 关系型数据库 | es |
|---|---|
| 数据库 | 索引 |
| 表 | types(慢慢被弃用了,7.x.x版本使用统一的_doc,并在查询命令中可以省略) |
| 行 | documents(文档) |
| 字段 | fields |
文档
es是面向文档的,
- 意味着索引和搜索数据的最小单位是文档,类似关系数据库中某张表中的一行记录(好理解)
- 文档会被序列化成 JSON 格式,JSON 对象由字段组成(以json格式存储)
- 每个字段都有对应的字段类型,类型可以自己指定,也可以使用 ElasticSearch 自动推算(智能化)
- JSON 文档支持数组和嵌套(自由度很高)
- 每个文档都有一个唯一性 ID,可以自己指定,也可以系统自动生成(智能化)
尽管我们可以随意新增忽略某个字段,但是每个字段的类型非常重要,比如一个年龄类型字段,可以是字符串也可以是整数,因为es中会保存字段和类型之间的映射以及其他的设置,这种映射具体到每个映射的每种类型,这也是为什么在es中,类型有时候也称为映射类型。
一个文档主要元素大致包含以下内容:
1. _index: 文档所属的索引名
2. _type: 文档所属的类型名(废弃品)
3. _id: 文档的唯一ID
4. _source: 文档存储的 Json 数据
5. _version:文档的版本信息
6. _score: 相关性打分
类型
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。
索引
最直接的理解就是数据库!
- 每个索引都是一个非常大的文档集合。
- 每个索引有自己的 Mapping 用于定义文档的字段名和字段类型
- 每个索引有自己的 Settings 用于定义不同的数据分布,也就是索引使用分片的情况(我没用过👻👻👻)
节点和集群如何工作
一个集群至少有一个节点,而一个节点就是一个es进程,节点可以有多个索引(默认的),如果你创建索引,那么索引将会有5个分片(primary shard,又称主分片)构成的,每一个主分片会有一个副本(replica shard,又称复制分片)
因为不是专职做这个的,所以这里关于这些东西就一带而过了。。。,小白入门不需要了解太多底层吧
倒排索引是什么
es使用的是一种称为倒排索引的结构,采用Lucene倒排索引作为底层,这种结构适用于快速的全文索引,一个索引由文档中所有的不重复的列表构成,对于每一个词,都有一个包含它的文档列表。例如,现在有两个文档,每个文档包含如下内容:
Study every day, good good up, to forever # 文档一
To forever, study every day, good good up # 文档二
为了创建倒排索引,我们要将每个文档拆分成独立的词(词条),然后创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档
现在我们要去搜索 to forever 只需要查看包含每个词条的文档
这里产生了权重!
总结:倒排索引帮我们完全过滤掉了一些无用的数据,帮我们提高了效率
1、索引(数据库) 2、字段类型(mapping) 3、文档 4、分片(了解,Lucene索引)
分词插件(IK分词器)
分词就是把一段中文或者英文划分为一个个关键字,我们在搜索的时候会把自己的信息进行分词,会把数据库中的或者索引库中的数据进行分词,然后进行一个匹配操作做,默认的中文分词是将每一个字看成一个词,比如“我爱育仪”会被分成“我”“爱”“育”“仪”,这里显然是不合理的,所以我们需要安装中文的分词器。
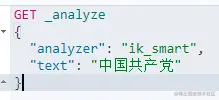
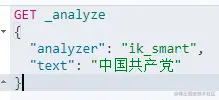
IK提供了两个分词算法:ik_smart 和 ik_max_word,其中 ik_smart是最少切分,ik_max_word是最细粒度划分!
附件中有IK分词器的安装包
1、安装
2、直接解压到es安装目录的plugin目录中命名为ik
3、重启es
验证 分词器是否安装完成,
4、使用 elasticsearch-plugin
5、用kibana测试!
ik_smart 最少划分
ik_max_word 最多划分
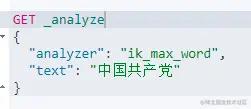
两种分词器使用的最佳实践是:索引时用ik_max_word,在搜索时用ik_smart。 即:索引时最大化的将文章内容分词,搜索时更精确的搜索到想要的结果。
1、ik_max_word
会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
2、ik_smart 会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
发现问题
这种自己需要的词,需要我们自己加上我们的分词器中,才会实现真正的分词
自己添加词典
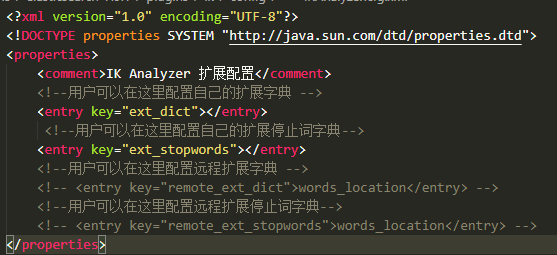
D:\tools\elasticsearch-7.9.1\plugins\ik\config\IKAnalyzer.cfg.xml(这是我的路径,别人和我不一样的)
在这个目录下修改
| 
|_
在elasticsearch-7.9.1\plugins\ik\config 目录下新建 自定义的词典例如:
1、新建yuyi.dic
2、在 该文件中写入
3、在下图位置加上自己的配置文件名
4、重启es
5、再次测试
GET _analyze
{
"analyzer": "ik_smart",
"text": "超级喜欢育仪讲"
}
返回值发生了变化
{
"tokens" : [
{
"token" : "超级",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "喜欢",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "育仪",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "讲",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 3
}
]
}
以后需要自己配置,就需要自己在分词中设置即可
Rest 风格说明
这是一种架构风格而不是标准,他用于客户端与服务器交互 类的软件,基于这个风格设计软件可以更简洁、更有层次等。
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/_update/文档id | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 通过文档id查询文档 |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有数据 |
创建文档
示例1
PUT /test1/type1/1
{
"name":"育仪",
"age":24
}
类型名未来在 8版本中会被删除
示例2
PUT /test3/_doc/1
{
"name":"育仪分享会",
"age":24,
"birth":"1996-09-12"
}
这里的_doc是未来es官方指定的类型,未来将去掉类型名称,统一为一个系统指定的_doc
如果我们没有指定 文档类型,es默认会帮我们指定类型
字段指定类型
- 字符串类型:text、keyword
- 数值类型:long、integer、short、byte、double、float、half float、scaled float
- 日期类型:date
- te布尔类型:boolean
- 二进制类型:binary
- 等等......
测试
PUT /test2
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "long"
},
"birthday":{
"type": "date"
}
}
}
}
返回上图则成功
mappings、properties为指定字段类型的必须格式,内部的name、age、birthday为用户想要的类型,类似mysql的建表。
通过get请求获取信息
GET /test2
可以通过get请求,直接获取test2索引的全部信息
拓展:通过命令 查看 es 索引情况
查看数据库健康值
GET _cat/health
查看es很多信息
GET _cat/indices?v
等等还有很多
修改
修改提交还是使用PUT 然后覆盖即可!(曾经的方法)
PUT /test3/_doc/1
{
"name":"育仪分享会20200921",
"age":24,
"birth":"1996-09-12"
}
这种修改更新方式是整体修改,一旦丢掉数据则会产生修改错误的字段
更新的方法(新的)
POST /test3/_update/1
{
"doc":{
"name":"育仪大魔王"
}
}
更新成功,再调用查看方法即可发现就
name字段发生了变化。
值得注意的是 doc是固定写法
删除
删除整个索引
DELETE /test1
返回值:
删除一条数据
Delete /test3/_doc/1
使用RESTFUL风格是我们ES推荐大家使用的!
关于文档的操作
基本操作
1、先创建一个索引并加入数据
PUT /yuyi/_doc/1
{
"name":"朱育仪",
"age":24,
"desc":"我明天就要分享了,我慌的一批",
"tags":["技术宅","温暖","直男"]
}
PUT /yuyi/_doc/2
{
"name":"张三",
"age":24,
"desc":"我是张三",
"tags":["傻叉","旅游","渣男"]
}
PUT /yuyi/_doc/3
{
"name":"李四",
"age":30,
"desc":"我是李四",
"tags":["靓女","旅游","唱歌"]
}
2、查询 查询yuyi索引下的 1号人物
GET /yuyi/_doc/1
3、搜索 条件查询 获取一号用户的
GET /yuyi/_doc/_search?q=name:朱育仪
我们发现 上图中有一个 _score这个字段,如果有多条数据,匹配度越高则分值越高
略复杂的查询方式
GET /yuyi/_doc/_search
{
"query":{
"match":{
"name":"朱育仪"
}
}
}
还是一样返回上文图片的返回值
通过 _source 指定返回值
GET /yuyi/_doc/_search
{
"query":{
"match":{
"name":"朱育仪"
}
},
"_source":["name","age"]
}
![]
我们之后使用nodejs 操作es,所有的方法和对象就是这里面的key!
排序
GET /yuyi/_doc/_search
{
"query":{
"match_all":{}
},
"sort":[
{
"age":{
"order":"desc"
}
}
]
}
match_all代表全文匹配 sort 字段是个数组里面传递对象用来排序,上面的语句是对age进行排序,order代表排序规则“desc降序 asc升序”
有了固定的排序后,_score分值就没了。
分页
GET /yuyi/_doc/_search
{
"query":{
"match_all":{
}
},
"sort":[
{
"age":{
"order":"desc"
}
}
],
"from":0,
"size":2
}
from代表了从第几个开始,size表示每页多少个
布尔值查询
GET /yuyi/_doc/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"name":"育仪"
}
},
{
"match":{
"age":24
}
}
]
}
}
}
采用 bool字段, 内部可选参数:must(必须包含)must_not(必须不包含)should(有一个就可以了)(minimum_should_match: 用来控制至少匹配多少个should匹配的)
上面匹配的是 name包含 育仪字段 age 是 24的数据
should查询测试
GET /yuyi/_doc/_search
{
"query":{
"bool":{
"should":[
{
"match":{
"name":"育仪"
}
},
{
"match":{
"age":24
}
}
]
}
},
"from":0,
"size":2
}
会返回只要符合name 是育仪 或者 age是 24的就可以了。
过滤查询
GET /yuyi/_doc/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"name":"育仪"
}
}
],
"filter":{
"range":{
"age":{
"gte":10,
"lte":30
}
}
}
}
}
}
通过 filter查询过滤数据,将过滤age大于等于10小于等于30的
gt大于 lt小于 gte大于等于 lte小于等于
数组类型也可以匹配
GET /yuyi/_doc/_search
{
"query":{
"match":{
"tags":"男"
}
}
}
想要匹配多个条件直接空格隔开即可
GET /yuyi/_doc/_search
{
"query":{
"match":{
"tags":"男 技术"
}
}
}
我们发现只要匹配到了这两个词中的任意一个,就会被返回,然而第二条数据并不太符合技术这个关键词。
这个时候可以通过返回值中的分值进行基本的判断,匹配程度。
精确查询
term 直接通过倒排索引精确查找的
关于分词,term会直接查询精确值,match会使用分词器解析,再通过分析的文档查询
两个类型 text keyword text类型会被分词器进行解析 keyword不会被分割解析
测试代码一个一个请求
PUT testdb
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"desc":{
"type": "keyword"
}
}
}
}
PUT testdb/_doc/1
{
"name":"育仪准备分享会",
"desc":"育仪准备分享会"
}
PUT testdb/_doc/2
{
"name":"育仪准备分享会 name",
"desc":"育仪准备分享会 desc"
}
查看分词结果
GET _analyze
{
"analyzer": "keyword",
"text":"育仪准备分享会"
}
如上图所示,keyword形式将不再进行分词
GET _analyze
{
"analyzer": "ik_smart",
"text":"育仪准备分享会"
}
使用ik分词器后是这个结果
精准查询的测试
GET /testdb/_search
{
"query":{
"term":{
"name":"育"
}
}
}
查询name中含有育的数据,由于name属性是text类型,会被分词
GET /testdb/_search
{
"query":{
"term":{
"desc":"育"
}
}
}
此时我们发现 desc查询育字时无值,由于我们使用了keyword类型 ,所以我们必须使用育仪准备分享会 全部文字才能匹配到值。如下方的测试
GET /testdb/_search
{
"query":{
"term":{
"desc":"育仪准备分享会"
}
}
}
总结:keyword不会被分词器解析
多个值匹配的精确查询
测试代码(插入多个数据)
PUT testdb/_doc/3
{
"t1":"22",
"t2":"2020-09-23"
}
PUT testdb/_doc/4
{
"t1":"33",
"t2":"2020-09-24"
}
使用 term精确查询多个值
GET /testdb/_search
{
"query":{
"bool":{
"should": [
{
"term":{
"t1":"22"
}
},
{
"term":{
"t1":"33"
}
}
]
}
}
}
高亮查询
GET /yuyi/_search
{
"query":{
"match":{
"name":"育仪"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
通过 上文方式可以实现高亮,highlight``fields为固定写法
我们这里不想用em标签
想用其他的
GET /yuyi/_search
{
"query":{
"match":{
"name":"育仪"
}
},
"highlight": {
"pre_tags": "<p class='myClassName' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name": {}
}
}
}
这里使用
pre_tags post_tags 来自定义标签高亮
参考文档:
Elasticsearch 之(24)IK分词器配置文件讲解以及自定义词库
还有很多借鉴其他的出处忘记了。。。
