

本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
以下文章来源于腾讯云 作者:Mshu
( 想要学习Python?Python学习交流群:1039649593,满足你的需求,资料都已经上传群文件流,可以自行下载!还有海量最新2020python学习资料。 )

selenium 是一个web应用测试工具,能够真正的模拟人去操作浏览器。
用她来爬数据比较直观,灵活,和传统的爬虫不同的是,
她真的是打开浏览器,输入表单,点击按钮,模拟登陆,获得数据,样样行。完全不用考虑异步请求,所见即所得。
selenium语言方面支持java/python,浏览器方面支持各大主流浏览器谷歌,火狐,ie等。我选用的是python3.6+chrome组合
chrome
写python爬虫程序之前,需要准备两样东西:
1.[chrome][1]/浏览器 https://www.google.cn/chrome/
2.[chromedriver][2] /浏览器驱动 http://chromedriver.storage.googleapis.com/index.html
浏览器和浏览器驱动的搭配版本要求比较严格,不同的浏览器版本需要不同的驱动版本;我的版本信息:
chrome info: chrome=66.0.3359.139
Driver info: chromedriver=2.37.544315
其他版本对照

chrome浏览器
这里需要注意的是如果想更换对应的谷歌浏览器,要高版本的请务必直接升级处理,低版本的卸载时要彻底!彻底!彻底!卸载,包括(Google升级程序,注册表,残留文件等),再安装。否则爬虫程序启动不了浏览器。
chromedriver浏览器驱动
chromedriver 放置的位置也很重要,把chromedriver放在等会要写的.py文件旁边是最方便的方法。当然也可以不放这里,但是需要配置chromedriver的路径,我这里就不介绍这种方法了。
python
终于开始敲代码了
打开网站
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://segmentfault.com/")
三行代码即可自动完成启动谷歌浏览器,输出url,回车的骚操作。
此时的窗口地址栏下方会出现【Chrome 正在受到自动测试软件的控制】字样。
提交表单
下面我们来尝试控制浏览器输入并搜索关键字找到我们这篇文章;
先打开segmentfault网站,F12查看搜索框元素
<input id="searchBox" name="q" type="text" placeholder="搜索问题或关键字" class="form-control" value="">
发现是一个id为searchBox的input标签,ok
from selenium import webdriver
browser = webdriver.Chrome() #打开浏览器
browser.get("https://segmentfault.com/") #输入url
searchBox = browser.find_element_by_id("searchBox") #通过id获得表单元素
searchBox.send_keys("python爬虫之初恋 selenium") #向表单输入文字
searchBox.submit() #提交
find_element_by_id()方法:根据id获得该元素。
同样还有其他方法比如
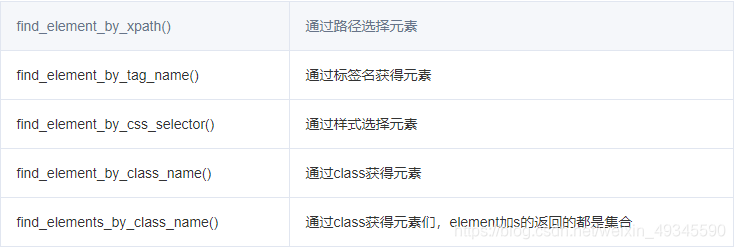
举个栗子:
1.find_elements_by_css_selector("tr[bgcolor='#F2F2F2']>td")
获得 style为 bgcolor='#F2F2F2' 的tr的子元素td
2.find_element_by_xpath("/html/body/div[4]/div/div/div[2]/div[3]/div[1]/div[2]/div/h4/a")
获得此路径下的a元素。
find_element_by_xpath方法使用谷歌浏览器F12选择元素右键copy->copyXpath急速获得准确位置,非常好用,谁用谁知道
3.find_element_by_xpath("..")获得上级元素
抓取数据
获得元素后.text方法即可获得该元素的内容
我们获得文章的简介试试:
from selenium import webdriver
browser = webdriver.Chrome() #打开浏览器
browser.get("https://segmentfault.com/") #输入url
searchBox = browser.find_element_by_id("searchBox") #通过id获得表单元素
searchBox.send_keys("python爬虫之初恋 selenium") #向表单输入文字
searchBox.submit() #提交
text = browser.find_element_by_xpath("//*[@id='searchPage']/div[2]/div/div[1]/section/p[1]").text
print(text)

除了捕获元素还有其他的方法:

启动前添加参数
chromeOptions = webdriver.ChromeOptions()
chromeOptions.add_argument("--proxy-server=http://101.236.23.202:8866") //代理
chromeOptions.add_argument("headless") //不启动浏览器模式
不加载图片启动
def openDriver_no_img():
options = webdriver.ChromeOptions()
prefs = {
'profile.default_content_setting_values': {
'images': 2
}
}
options.add_experimental_option('prefs', prefs)
browser = webdriver.Chrome(chrome_options=options)
return browser
