基本概念
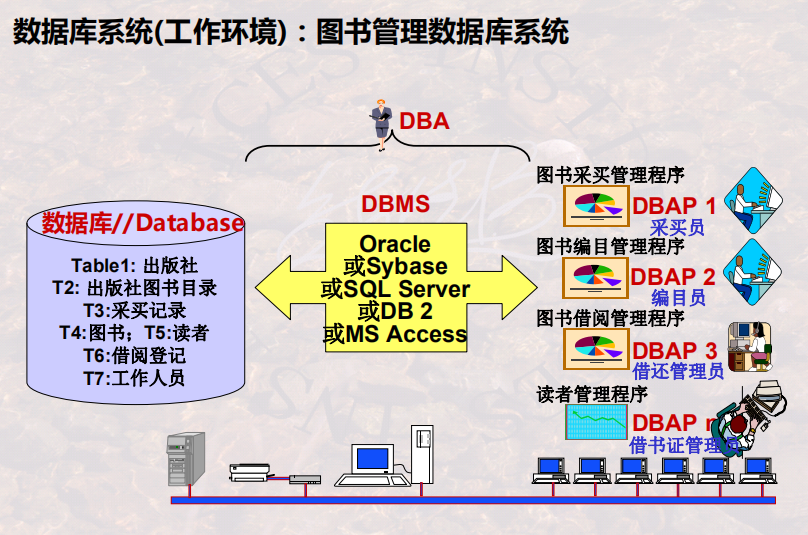
数据库 DB,即database,一般指一个具体的数据集/库(可以理解成database instance)。如果是关系模型的话,就是一堆数据表、索引和视图啥的
数据库管理系统 DBMS,即database management system,一般指一个数据库管理系统(软件系统),比如MySQL、PostgreSQL,Oracle。
数据库应用 DBAP , 即DataBase Application 。基于DBMS开发的应用,如 图书采买管理程序 , 图书编目管理程序 , 读者管理程序
数据库管理员 DBA ,即DataBase Administrator。管理该数据库的人。
数据库系统 DBS,即 Database System,一般指一个运行的、或者可提供服务的数据库系统。可以简单的理解:DBS = DB + DBMS + DBA + DBAP 。
数据库管理系统的功能
数据库定义 : 定义数据库中Table 的名称、标题(内含的属性名称及对该属性的值的要求)等
- DBMS 提供一套数据定义语言**(DDL**:Data Definition Language) 给用户,用户使用DDL 描述其所要建立表的格式,DBMS 依照用户的定义,创建数据库及其中的Table。
数据库操纵 : 向数据库的Table中增加/删除/更新数据及对数据进行查询、检索、统计等。
- DBMS 提供一套数据操纵语言(DML:Data Manipulation Language) 以及 DQL ( 数据查询语言 ) 给用户,用户使用DML 描述其所要进行的增、删、改、查等操作,DBMS 依照用户的操作描述,实际执行这些操作。用户使用 DQL 查询数据库。
数据库控制 : 控制数据库中数据的使用 ( 哪些用户可以使用, 哪些不可以 )
- DBMS 提供一套数据控制语言(DCL:Data Control Language) 给用户,用户使用DCL 描述其对数据库所要实施的控制,DBMS 依照用户的描述,实际进行控制。
数据库维护 : 转储/恢复/重组/性能监测/分析
- DBMS 提供一系列程序( 实用程序/ 例行程序) 给用户,在这些程序中提供了对数据库维护的各种功能,用户使用这些程序进行各种数据库维护操作,数据库维护的实用程序,一般都是由数据库管理员(DBA)。
分布式数据库系统的透明性
分片透明:是指用户或应用程序不需要知道逻辑上访问的表具体是如何分块存储的。
复制透明:是指采用复制技术的分布方法, 用户不需要知道数据是复制到哪些节点及如何复制的
位置透明:是指用户无须知道数据存放的物理位置:
逻辑透明:即局部数据模型透明,是指用户或应用程序无须知道局部场地使用的是哪种数据模型。


三级结构/两级映像
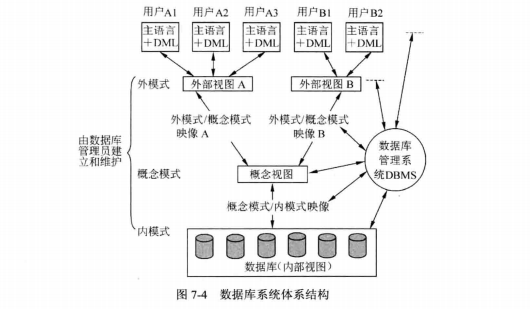
外模式
外模式也称用户模式或子模式,是用户与数据库系统的接口,是用户用到的那部分数据的描述。有了外模式后,程序员不必关心概念模式,只与外模式发生联系,按外模式的结构存储和操纵数据。
内模式
内模式也称存储模式,是数据物理结构和存储方式的描述。内部层次的数据是存储在介质上的数据,包括存储路径、存储方式、索引方式(聚簇索引,普通索引)等。
例如,记录的存储方式是顺序存储,按照B树结构存储,还是Hash方法存储∶索引按照什么方式组织∶数据是否压缩存储,是否加密;数据的存储记录结构有何规定。
概念模式
概念模式也称模式,它是数据库中全部数据的逻辑结构和特征的描述,由若干个概念记录类型组成,只涉及型的描述,不涉及具体的值。
在一个数据库系统中,『模式』与『内模式』都只能有一个,但『外模式』可以有很多个。
两级映像
数据库系统在三级模式之间提供了两级映像∶模式/内模式映像、外模式/模式映像。正因
为这两级映像保证了数据库中的数据具有较高的逻辑独立性和物理独立性。
-
模式/内模式映像。存在于概念级和内部级之间,实现了概念模式和内模式之间的相互转换。
-
外模式/模式映像。存在于外部级和概念级之间,实现了外模式和概念模式之间的相互转换
数据的物理独立性。数据的物理独立性是指当数据库的内模式发生改变时,数据的逻辑结构不变。由于应用程序处理的只是数据的逻辑结构,这样物理独立性可以保证,当数据的物理结构改变时,应用程序不用改变。但是,为了保证应用程序能够正确执行,需要修改概念模式和内模式之间的映像,
数据的逻辑独立性。数据的逻辑独立性是指用户的应用程序与数据库的逻辑结构是相互独立的。数据的逻辑结构(概念模式)发生变化后,用户程序也可以不修改。但是,为了保证应用程序能够正确执行,需要修改外模式和概念模式之间的映像。
试题1(2017年下半年试题51)
采用三级结构/两级映像的数据库体系结构,如果对数据库的一张表创建聚簇索引,改变的是数据库的( )。
A.用户模式
B.外模式
C.模式
D.内模式
试题答案
(51)D
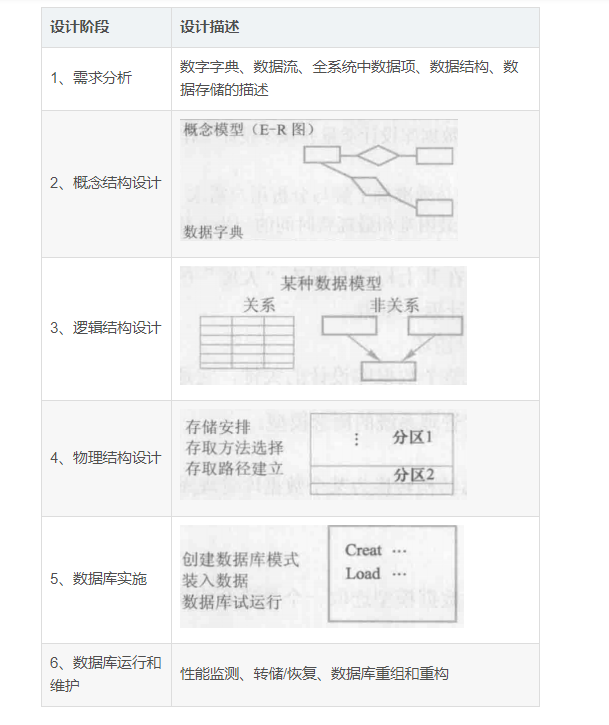
数据库设计过程
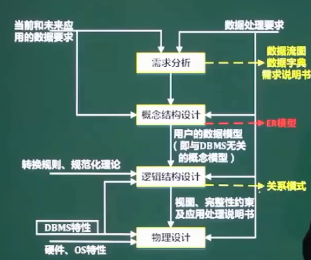
在数据库逻辑结构设计阶段,需要( )阶段形成的( )作为设计依据。(2014年下半年)
A.需求分析
B.概念结构设计
C.物理结构设计
D.数据库运行和维护
A.程序文档、数据字典和数据流图。
B.需求说明文档、程序文档和数据流图
C.需求说明文档、数据字典和数据流图
D.需求说明文档、数据字典和程序文档
答案 A C
视图
视图是指计算机数据库中的视图,是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。
-
简单性。看到的就是需要的
-
安全性。通过视图用户只能查询和修改他们所能见到的数据
视图定义
CREATE VIEW 视图名
AS 子查询
WITH CHECK OPTION //可以省略
[with check option]可选项,防止用户对数据插入、删除、更新是操作了视图范围外的基本表的数据。
视图查询、更新
和基本表的查询语句类似,只是把表名的位置换成视图名就可以
视图删除
DROP VIEW 视图名 【CASCADE】//CASCADE为级联删除,可以省略
关系代数
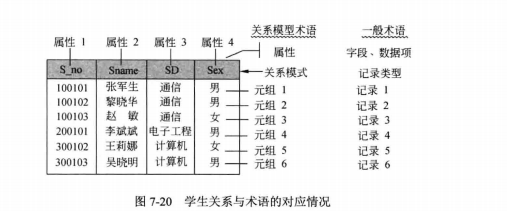
关系数据库的基本概念
属性和域
在现实世界中,要描述一个事物常常取若干特征来表示,这些特征称为属性(atribute)。例如,用学号、姓名、性别、系别、年龄和籍贯等属性来描述学生。每个属性的取值范围对应一个值的集合,称为该属性的域(domaim))。例如,学号的域是6位整型数∶姓名的域是10位字符;性别的域为 { 男,女 } 等。
关系的相关名词
候选码∶若关系中的某一属性或属性组的值能唯一的标识一个元祖,则称该属性或属性组为候选码。
主码∶若一个关系有多个候选码,则选定其中一个为主码。
主属性∶包含在任何候选码中的诸属性称为主属性,不包含在任何候选码中的属性称为非主属性。
外码∶如果关系模式R中的属性或属性组不是该关系的码,但它是其他关系的码,那么该属性集对关系模式R而言就是外码。
全码∶关系模型中的所有属性组是这个关系模式的候选码,称为全码。
关系运算

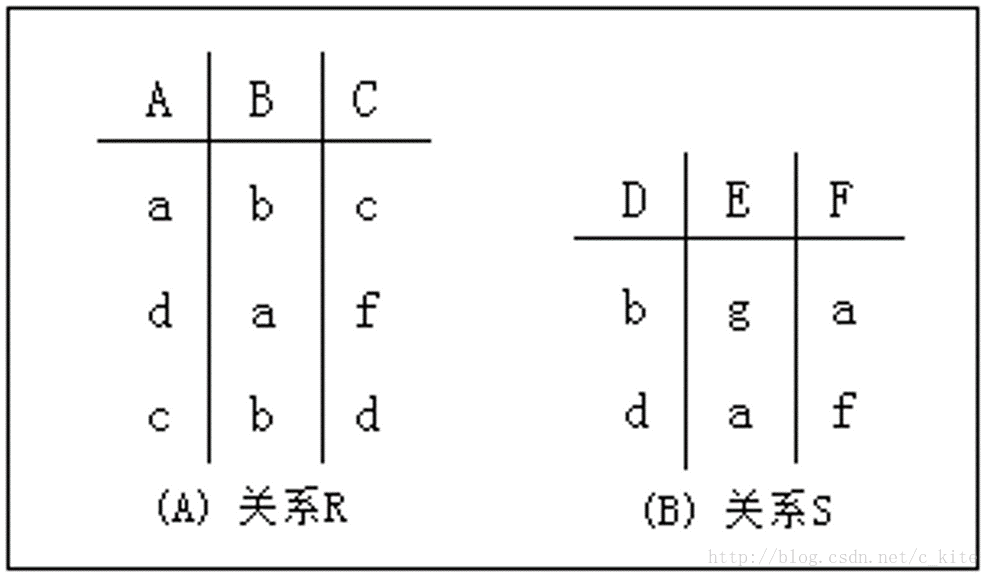
并运算
(R和S关系合一起, 相同的不写)
设R和S是n元关系,而且两者各对应属性的数据类型也相同。R和S的并操作定义为 R∪S = { t | t∈R∨t∈S }。
对应到 SQL 中就是 UNION 操作,比如说获取 User 和 Profile 中的所有 ID:
SELECT id FROM user UNION SELECT id FROM profile;
差操作
(因为是R-S, 找R在S关系中没有的)
设R和S是n元关系,而且两者各对应属性的数据类型也相同。R和S的差定义为 R-S ={ t | t∈R∧t∈S}。
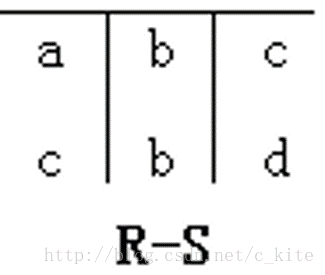
对于到 SQL 中就是 EXCEPT 操作,比如获取 User 不在 Profile 中的所有 ID1:
SELECT id FROM user EXCEPT SELECT id FROM profile;
投影
表示 选择 R 中的 A C
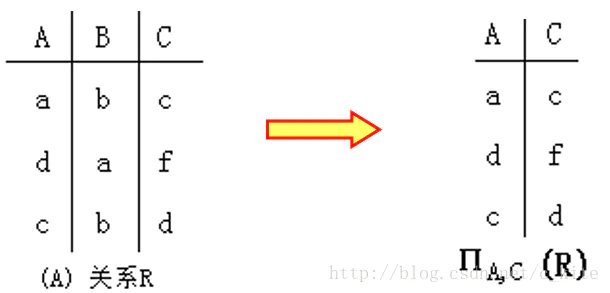
它的作用和 SQL 中的 SELECT 基本相同。
比如说我们要选择 R 中的 A 、 C, 用 SQL 编写的话就是:
SELECT A , C FROM R;
选择
(把符合条件的拿出来)
表示可以选择关系 R 中 B 等于 b 的用户,其等价的 SQL 语句如下:
SELECT * FROM user WHERE id = 1;
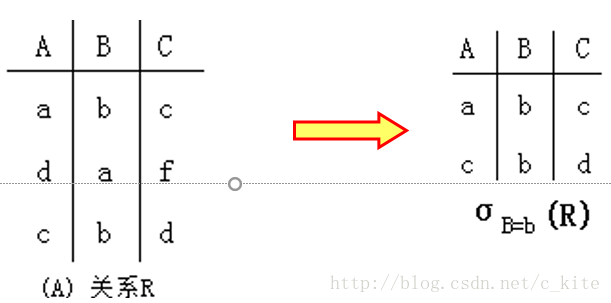
选择运算中可以使用的谓词包括:. 同时还可以使用连词 and(∧),or(∨),not(¬)将多个谓词合并为一个较大的连词。
比如说 选择 id 范围在 [1, 3) 之间的用户,等价于:
SELECT * FROM user WHERE id >= 1 AND id < 3;
交操作
(相同的拿出来)
集合交运算计算两个关系中都存在的部分,可以通过基本运算表示: r∩s=r−(r−s)r∩s=r−(r−s).
集合交运算对于的 SQL 语句是 INTERSECT, 比如:
SELECT id FROM user INTERSECT SELECT id FROM profile;
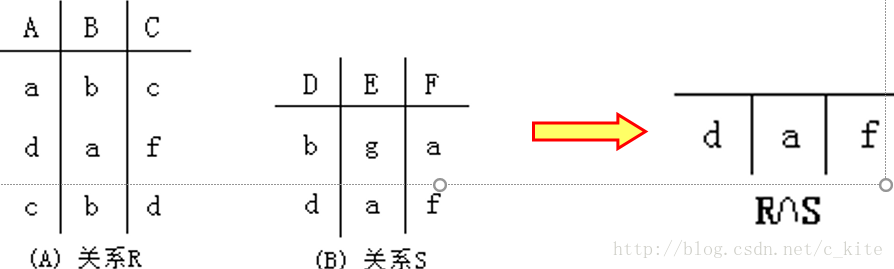
笛卡尔积
笛卡尔积是一个很重要的运算,通过笛卡尔积我们可以将 任意 两个关系的信息结合在一起,笛卡尔积的运算结果会将两个关系的所有列作为新的关系的列,将两个关系的所有行的组合作为新的关系的行。

对应到 SQL 中便是 CROSS JOIN, 比如说如下 SQL 语句便可以表示为 user×profile:
SELECT * FROM user CROSS JOIN profile;
连接运算
运算存在很多分类,比如:自然连接、内连接、外连接等。
自然连接
这里给出接下来会用到的两个关系(表):
-
User:
+------+---------+--------+ | id | account | passwd | +------+---------+--------+ | 1 | 123 | ****** | | 2 | 456 | ****** | +------+---------+--------+ -
Profile
+------+------+------+ | id | name | age | +------+------+------+ | 1 | tony | 16 | | 3 | john | 2 | +------+------+------+
首先是自然连接,自然连接将两个关系的 属性集 的 并集 作为新的关系的属性,同时会对两个关系中的相同属性进行比较筛选。
假如两个关系不存在相同的属性,那么自然连接的结果便和 笛卡尔积 相同:
+------+---------+--------+------+------+
| id | account | passwd | name | age |
+------+---------+--------+------+------+
| 1 | 123 | ****** | tony | 16 |
+------+---------+--------+------+------+
如上便是 自然连接 的运算结果,它将关系 User 和 Profile 的属性的并集作为新关系的属性,同时筛选具有相同 ID 值的行。
连接运算的关系代数形式都很复杂,这里就简单列出对应的 SQL 语句好了2:
SELECT * FROM user NATURAL JOIN profile;
内连接
可以把内连接看做添加了选择语句的笛卡尔积,也就是说,计算内连接时需要先行计算出笛卡尔积,然后在根据选择条件进行选择。
比如这样的内连接操作:
SELECT * FROM user INNER JOIN profile ON user.id >= profile.id;
其结果为:
+------+---------+--------+------+------+------+
| id | account | passwd | id | name | age |
+------+---------+--------+------+------+------+
| 1 | 123 | ****** | 1 | tony | 16 |
| 2 | 456 | ****** | 1 | tony | 16 |
+------+---------+--------+------+------+------+
这里可以对照笛卡尔积的计算结果进行理解:
+------+---------+--------+------+------+------+
| id | account | passwd | id | name | age |
+------+---------+--------+------+------+------+
| 1 | 123 | ****** | 1 | tony | 16 |
| 2 | 456 | ****** | 1 | tony | 16 |
| 1 | 123 | ****** | 3 | john | 2 |
| 2 | 456 | ****** | 3 | john | 2 |
+------+---------+--------+------+------+------+
外连接
我们可以把外连接看做是 内连接 的扩展,首先计算出两个关系内连接的结果,然后根据外连接的类型补充数据到内连接的结果上。
比如说左外连接,首先可以计算出 User 和 Profile 的内连接,然后用空值来填充在左侧关系中存在而右侧关系中不存在的项就可以了。
SELECT * FROM user LEFT JOIN profile on user.id = profile.id;
这条 SQL 语句的执行结果为:
+------+---------+--------+------+------+------+
| id | account | passwd | id | name | age |
+------+---------+--------+------+------+------+
| 1 | 123 | ****** | 1 | tony | 16 |
| 2 | 456 | ****** | NULL | NULL | NULL |
+------+---------+--------+------+------+------+
如果将其替换为内连接的话便是:
+------+---------+--------+------+------+------+
| id | account | passwd | id | name | age |
+------+---------+--------+------+------+------+
| 1 | 123 | ****** | 1 | tony | 16 |
+------+---------+--------+------+------+------+
可以看到,ID 为 2 的项只存在于 User 中而不存在与 Profile 中,因此,左外连接时使用了空值来填充 Profile 对应的部分,保证 User 的每项都存在。
依次类推,右外连接、全外连接也就好理解了:
-
右外连接的执行结果:
+------+---------+--------+------+------+------+ | id | account | passwd | id | name | age | +------+---------+--------+------+------+------+ | 1 | 123 | ****** | 1 | tony | 16 | | NULL | NULL | NULL | 3 | john | 2 | +------+---------+--------+------+------+------+ -
全外连接的执行结果:
+------+---------+--------+------+------+------+ | id | account | passwd | id | name | age | +------+---------+--------+------+------+------+ | 1 | 123 | ****** | 1 | tony | 16 | | 2 | 456 | ****** | NULL | NULL | NULL | | NULL | NULL | NULL | 3 | john | 2 | +------+---------+--------+------+------+------+
其实,这三个外连接是可以互相转换的,将两个关系的位置换一下就可以将左外连接转换为右外连接,而将左右外连接的结果并起来就可以得到全外连接了。
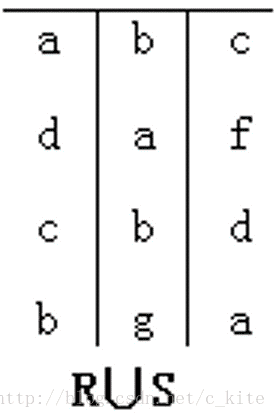
例子:
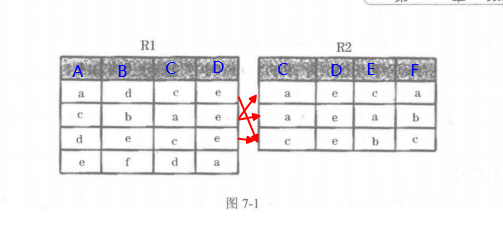
关系R1和R2如 所示∶
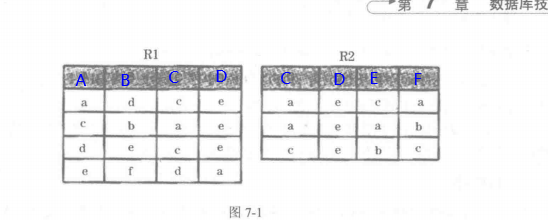
- 连接将两个关系的 属性集 的 并集 作为新的关系的属性, 结果集的属性列应为ABCDEF
- 对两个关系中的相同属性进行合并。如图


E-R模型和关系模型
| 表头 | 表头 |
|---|---|
 | 表示实体集 |
 或 或  | 表示弱实体集 |
 | 表示联系集 |
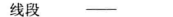 | 将属性与相关的实体集连接,或将实体集与联系集相连 同时在无向边旁标注上联系的类型(1∶1、1∶n或m∶n) |

关系数据库的规范化
依赖关系
函数依赖
可以这么理解(但并不是特别严格的定义):若在一张表中,在属性(或属性组)X的值确定的情况下,必定能确定属性Y的值,那么就可以说Y函数依赖于X,写作 X → Y。也就是说,在数据表中,不存在任意两条记录,它们在X属性(或属性组)上的值相同,而在Y属性上的值不同。这也就是“函数依赖”名字的由来,类似于函数关系 y = f(x),在x的值确定的情况下,y的值一定是确定的。
例如,对于表3中的数据,找不到任何一条记录,它们的学号相同而对应的姓名不同。所以我们可以说姓名函数依赖于学号,写作 学号 → 姓名。但是反过来,因为可能出现同名的学生,所以有可能不同的两条学生记录,它们在姓名上的值相同,但对应的学号不同,所以我们不能说学号函数依赖于姓名。表中其他的函数依赖关系还有如:
- 系名 → 系主任
- 学号 → 系主任
- (学号,课名) → 分数
但以下函数依赖关系则不成立:
- 学号 → 课名
- 学号 → 分数
- 课名 → 系主任
- (学号,课名) → 姓名
完全函数依赖
在一张表中,若 ,但对于 X 的任何一个真子集 , 不成立,那么我们称 Y 对于 X 完全函数依赖,记作 。
例如:
再举个例子,考试成绩:
(学号,课程,分数)
(学号,课程)→分数
但是单独知道学号或者课程两者中的一个,是无法知道具体分数的。说明分数完全依赖于学号+课程。
部分函数依赖
假如 Y 函数依赖于 X,但同时 Y 并不完全函数依赖于 X。 即 。记作
一个例子,给定一个tableux,存在以下关系: (假设姓名是唯一的)
(学号,姓名,学生宿舍)
(学号,姓名)→学生宿舍 (通过学号和姓名可以找到学生宿舍)
学号,姓名分别是(学号,姓名)的两个真子集。
(学号→学生宿舍)(通过学号可以得出学生宿舍)
(姓名→学生宿舍)(通过姓名也可以得出学生宿舍)
说明学生宿舍部分依赖于学号+姓名。

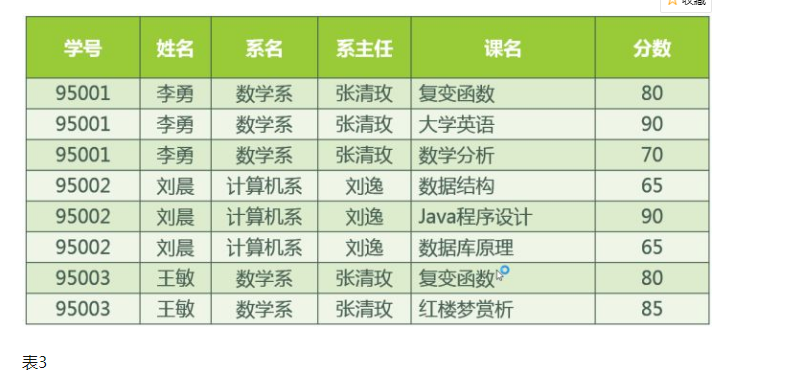
传递函数依赖
假如 Z 函数依赖于 Y,且 Y 函数依赖于 X (X 不包含于Y), 即: , 且
记作
比如通过学号,我们可以知道姓名、性别、班级,间接可以知道班主任是谁。
所以(学号→班级)(班级→班主任)
班主任传递依赖于学号。
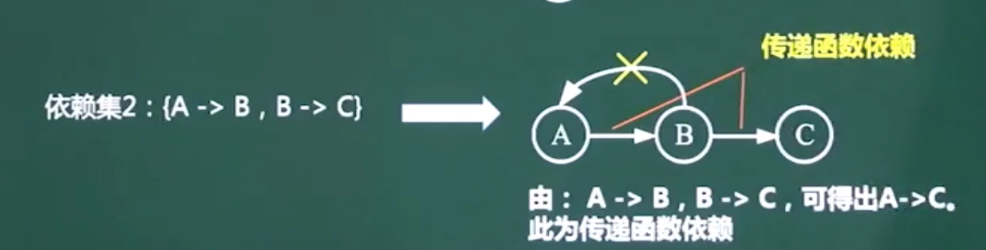
求候选码
图示法求候选键
-
将关系的函数依赖关系,用“有向图”的方式表示。
-
找出入度为0的属性,并以该属性集合起点,尝试遍历有向图,若能正常遍历图中所有结点,则该属性集即为关系模式的候选键。
-
若入度为0的属性集不能遍历图中所有点,则需要尝试性的将一些中间结点(既有入度,也有出度的结点)并入入度为0的属性集中,直至该集合能遍历,所有结点,集合为候选键。

答案 A

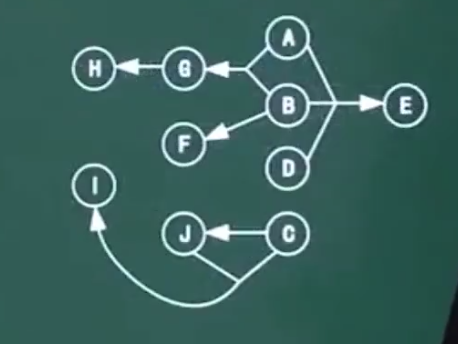
答案:[ ABDC ]

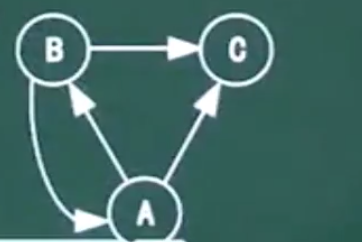
答案 B
范式说明
三种异常
| 学生学号 | 学生姓名 | 学生专业 | 系主任姓名 | 系主任电话 |
|---|---|---|---|---|
插入异常:如果 输入某条新学生信息的时候,系主任电话号码输错,无法确认该学生对应系主任的真正号码。
删除异常:某个系的学生全部退学了 , 该系对应的系主任名字和电话号码也随之丢失。
更新异常:系主任更换了手机号 , 我们需要把系里所有学生的行都给更新一遍,显然开销过大。
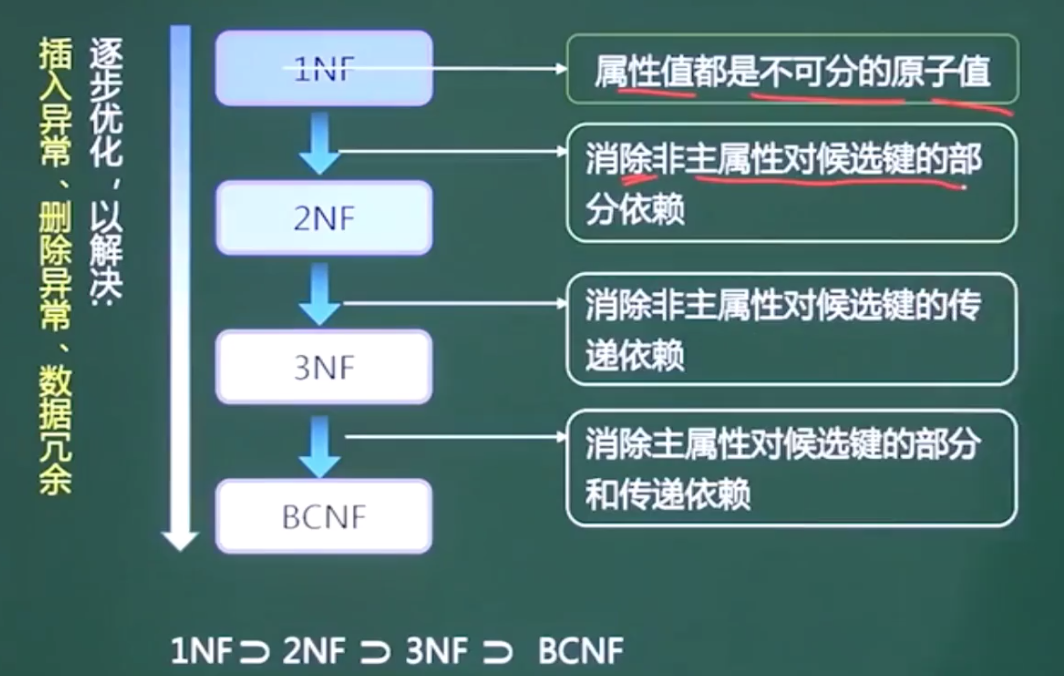
第一范式(1NF)
所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项。
下面的表格是不符合 1NF 的。

修改后下面的表格才符合 1NF 的。

第二范式(2NF)
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。当且仅当实体E是第一范式(1NF),且每一个非主属性完全依赖主键(不存在部分依赖)时,则称实体E是第二范式。
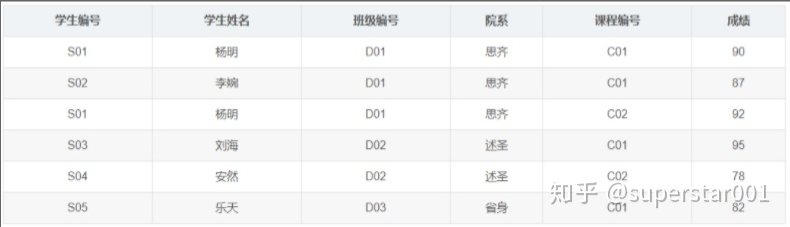
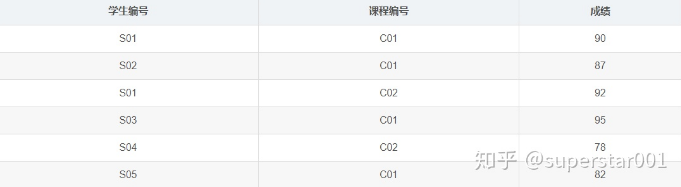
我们发现,对于学生姓名、学生所属的班级编号、院系,这三个属性可以直接通过学生编号来确定,在这里课程编号显得很多余。也就是,学生姓名、班级编号、院系对 学生编号、课程编号部分函数依赖。
它就不满足 2NF,我们需要把 Student 表进行拆分,可以消除部分依赖。
- 学生表:
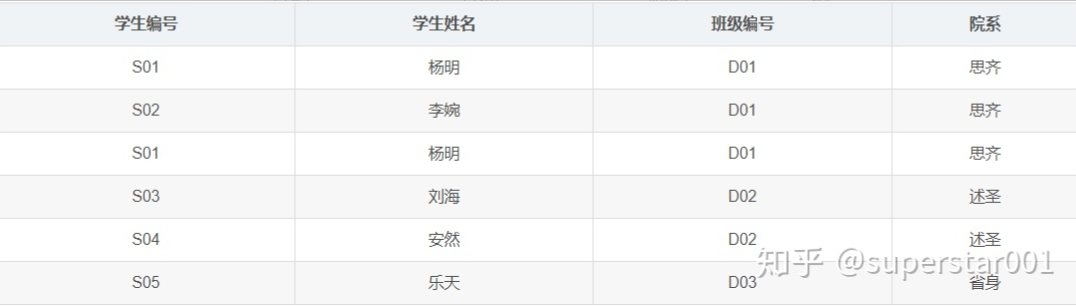
-
学生-课程表:
第三范式(3NF)
第三范式(3NF)属性不依赖于其它非主属性 ,即 消除了传递依赖 。
如果某一属性依赖于其他非主键属性,而其他非主键属性又依赖于主键,那么这个属性就是间接依赖于主键,这被称作传递依赖于主属性。
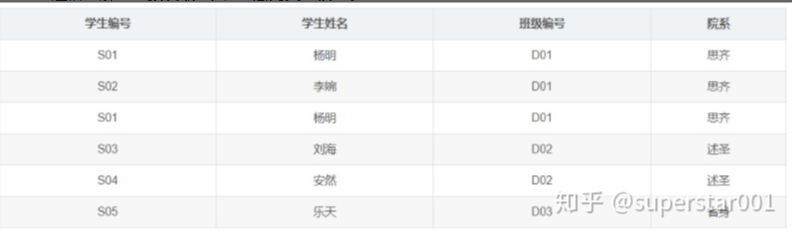
我们发现,对于 Student 表,学生编号可以唯一确定他所在的院系,但是注意到这中间存在传递过程,即学生编号唯一确定该学生所对应的班级编号,班级编号对应唯一的院系。我们称,院系对学生编号传递函数依赖。
它就不满足 3NF,我们需要把 Student 表继续进行拆分,可以消除传递依赖。
-
学生表:
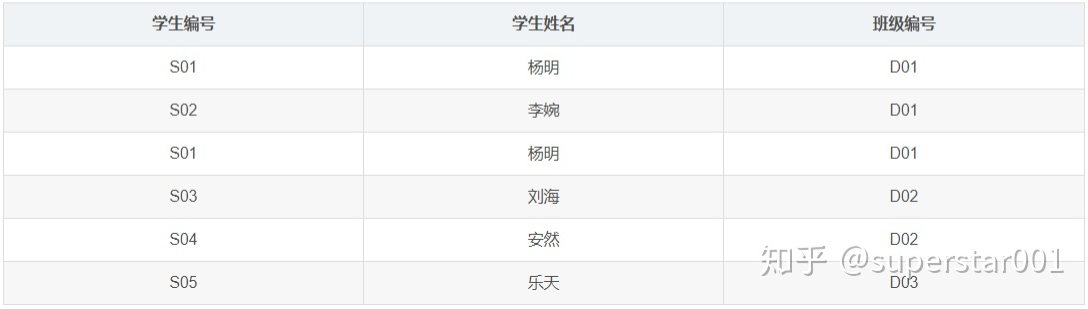
-
学生-课程表:
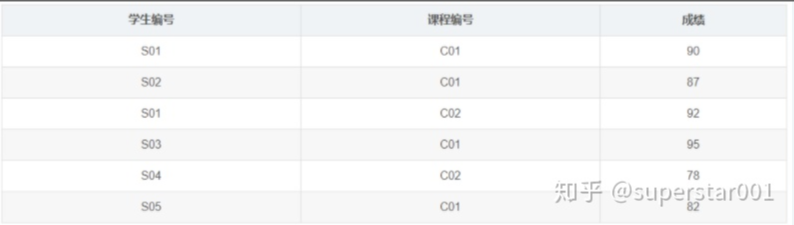
- 班级-学院表

BC范式(BCNF)
在第三范式基础上,消除主属性对主属性的部分函数依赖与传递函数依赖
假设仓库管理关系表为StorehouseManage(仓库ID, 存储物品ID, 管理员ID, 数量),且有一个管理员只在一个仓库工作;一个仓库可以存储多种物品。这个数据库表中存在如下决定关系:
(仓库ID, 存储物品ID) →(管理员ID, 数量)
(管理员ID, 存储物品ID) → (仓库ID, 数量)
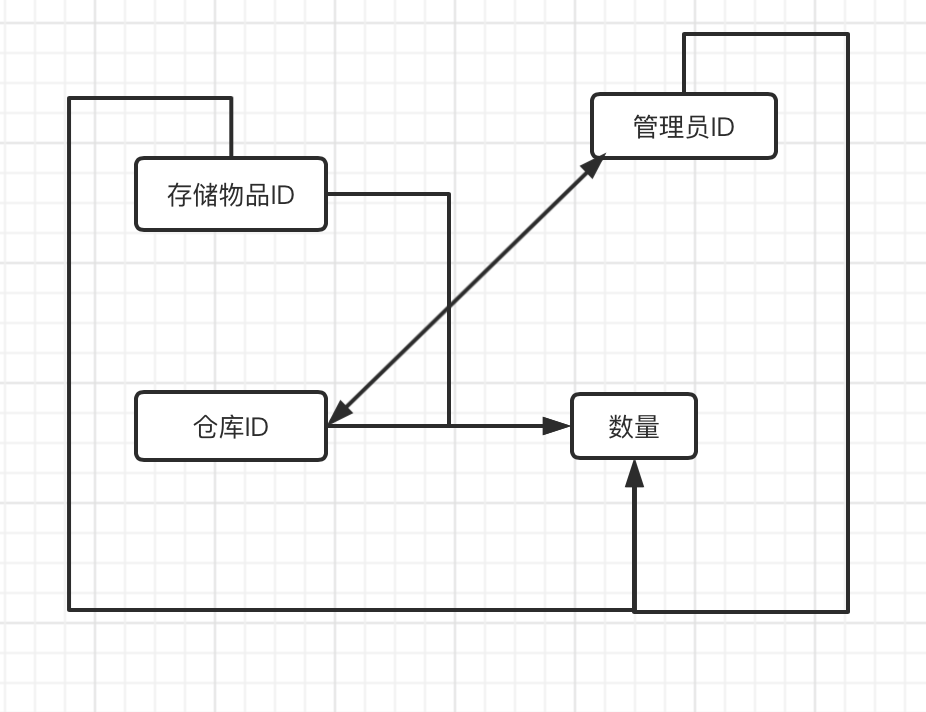
所以仓库ID, 存储物品ID,管理员ID都是StorehouseManage的候选关键字,表中的唯一非关键字段为数量,它是符合第三范式的。但是,由于存在如下决定关系:
(仓库ID) → (管理员ID)
(管理员ID) → (仓库ID)
即存在关键字段决定关键字段的情况,所以其不符合BCNF范式。