

自动化构建就是把我们开发时候产生的源代码自动化的构建成生产环境可以运行的代码或者程序,一般我们会把这个自动化构建的过程叫做自动化工作流,作用就是尽可能脱离运行环境的种种问题,在开发阶段去使用提高效率的语法、规范和标准
NPM Scripts 是实现自动化构建工作流的最简单的方式
"scripts": {
"build": "sass scss/main/scss css/style.css --watch", // watch 监听文件变化
"preserve": "npm run build"
"serve": "browser-sync . --files \"css/*.css\"", // browser-sync启动一个web服务器
"start": "run-p build serve" // 需要npm-run-all
},
常用的自动化构建工具
Grunt
构建过程是基于临时文件构建的,所以构建过程相对较慢,构建过程中,每一步都有磁盘读写操作,每次操作完之后都会生成一个临时文件,下一步操作也会读取这个临时文件
grunt的基本使用
1.新建一个空文件夹,npm init -y 初始化目录,npm i grunt,添加grunt模块,然后在根目录下添加一个gruntfile.js的文件,使用npm的同学还需要安装一个npm install -g grunt-cli, 使用的是yarn的话,就不需要了
gruntfile.js是一个Grunt入口文件,用于定义一些需要Grunt自动执行的任务,这个文件需要导出一个函数,此函数接收一个grunt形参,内部提供一些创建任务时,可以用到的API
2.默认使用grunt.registerTask注册一个任务,两个参数,第一个为任务名,第二个是相对应的回调函数
如果是三个参数的话,那么第二个参数就是关于这个任务的描述
如果任务名称是'default'的话,这个任务就会成为grunt的默认任务,执行的时候命令行直接grunt就好了
我们也可以用default映射其他任务,这时候第二个参数传入一个数组,数组中指定任务名字,grunt会依次执行这些任务
3.grunt中的代码默认支持同步模式,如果想要使用异步操作的话,必须要使用this.async()得到一个回调函数,异步操作之后,去调用这个回调函数,不使用this.async()的话,异步函数内部的代码不执行
Grunt标记任务失败
当构建任务的逻辑代码时,发生错误,这时可以将任务标记为失败,具体的方法就是在函数体内return false
- 如果这个任务在任务列表中,那么这个任务失败的话,后续的任务也不会执行,不过如果使用
grunt default --force,即使中间某个任务失败,后续的任务也会继续执行 - 如果这个失败的任务失败异步任务的时候,这个时候我们不能通过
return false来标记这个异步任务的失败了,这个时候 我们需要在下面的done函数的参数中,加入false就可以了,具体代码如下
grunt.registerTask('bad-async', function () {
const done = this.async()
setTimeout(() => {
console.log('async task working');
done(false) // 异步任务失败,在done后面添加参数 fasle 就可以了
}, 1000);
})
Grunt的配置方法
Grunt还提供了用于配置选项的api叫做initConfig
module.exports = grunt => {
grunt.initConfig({
foo: 'bar'
})
grunt.registerTask('foo',() => {
console.log(grunt.config('foo'));
})
}
执行结果
更多的时候,我们直接通过grunt.config()拿到整个config对象,然后去拿到具体的值
grunt多目标任务
除了普通任务的模式之外,grunt中还支持一种多目标任务的模式,我们可以理解为子任务的概念
多目标模式,可以让任务根据配置形成多个子任务
module.exports = grunt => {
grunt.initConfig({
'build':{
options:{ // option中指定的信息会作为任务的配置选项
foo:'bar' // 除了option之外,每一个属性的键都会成为一个目标,也就是一个子任务
},
css:'2',
js:'2'
}
})
grunt.registerMultiTask("build", function(){ // 这里需要使用普通函数,因为下面需要使用this
console.log(`build task`);
console.log(`target: ${this.target},data:${this.data}`);
console.log(this.options());
})
}
执行结果
Grunt插件的使用
如何使用插件的构建任务
首先尝试使用npm i --dev grunt-contrib-clean,grunt的插件基本都是以grunt-contrib-XXXX命名的
module.exports = grunt => {
grunt.initConfig({
clean: {
temp :'temp/app.js' // 'temp/*.txt'
}
})
grunt.loadNpmTasks(`grunt-contrib-clean`) // 加载这个插件提供的任务
}
// 运行 grunt clean ,app.js就被删除了
1.找到相关插件,安装到项目中
2.在gruntfile.js中通过grunt.loadNpmTasks('插件名')把插件中提供的任务加载进来
3.在grunt.initConfig()中为这个任务添加配置选项,插件就可以正常工作了
Grunt常用插件
grunt sass可以通过安装npm i grunt-sass sass --devgrunt-babel@babel/core@babel/preset-env可以在gruntfile中使用babel提供的任务了- 随着
gruntfile越来越复杂,里面的loadNpmTasks操作越来越多,有一个模块load-grunt-tasks,可以减少loadNpmTasks的使用
使用方法
const loadGruntTasks =require('load-grunt-tasks') loadGruntTasks(grunt)会自动加载所有的
grunt插件中的任务,这就是load-grunt-tasks的作用 4.runt-contrib-watch,文件修改,自动编译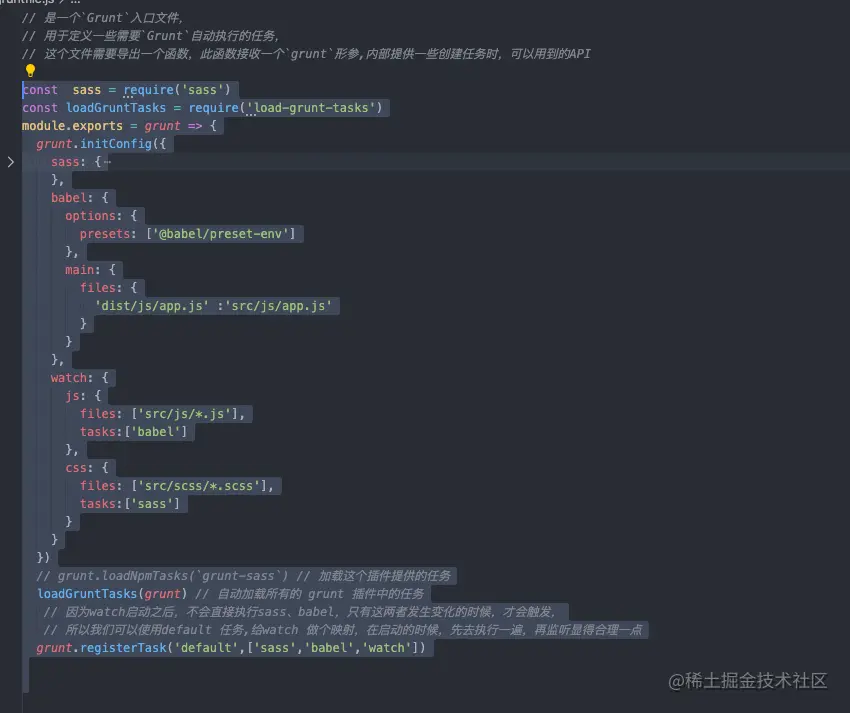
grunt就说到这里,因为现在用的已经不多了,所以简单介绍一下,想要更多内容可以去官网查api。
Gulp
The streaming build system 基于流的构建系统
基于内存实现的,对于文件的处理都是在内存中完成的,相对于磁盘读写自然快了很多,而且默认支持同时执行多个任务,使用方式相对于Grunt更加直观易懂
Gulp的基本使用
npm init -ynpm i gulp --dev先在项目中安装gulp的开发依赖- 根目录添加一个
gulpfile.js的文件,用于去编写需要gulp去执行的构建任务,是gulp的入口文件- 命令行中使用gulp提供的命令去运行这些任务
// 第一种 gulp 4.0以前一般都是按照以下的形式来建立一个gulp任务
const gulp = require('gulp')
gulp.task('bar', done => {
console.log('bar working');
done()
})
// 第二种 目前更推荐是的导出函数的形式
exports.foo = done => {
console.log('foo working');
done() // 标识任务完成
}
exports.default = done => {
console.log('default working');
done()
}
gulp 创建组合任务
组合任务就是多任务执行的时候,串并行的问题是我们时刻需要解决的,gulp给我们提供了两个函数series parallel负责对于串行和并行任务的处理
const {series, parallel } = require('gulp')
const task1 = done => {
setTimeout(() => {
console.log('task1 working');
done()
}, 1000);
}
const task2 = done => {
setTimeout(() => {
console.log('task2 working');
done()
}, 1000);
}
const task3 = done => {
setTimeout(() => {
console.log('task3 working');
done()
}, 1000);
}
exports.foo = series(task1,task2,task3)
exports.bar = parallel(task1,task2,task3)
Gulp 异步任务的三种方式
- 回调函数,promise, async , 错误优先,当前一个任务抛错的时候,后续的任务就不会再去执行了
- stream
// 异步任务
exports.callback = done => {
console.log('callback');
done()
}
exports.callback_error = done => { // 错误优先,当前一个任务抛错的时候,后续的任务就不会再去执行了
console.log('callback');
done(new Error('task failed'))
}
exports.promise = () => {
console.log('promise');
return Promise.resolve() // resolve 抛出的值会被gulp忽略
}
exports.promise_error = () => {
console.log('promise_error');
return Promise.reject(new Error('task failed'))
}
const timeout = time => {
return new Promise(resolve => {
setTimeout(resolve,time)
})
}
exports.async = async () =>{
await timeout(1000)
console.log('async task');
}
// stream
exports.stream = () => {
const readStream = fs.createReadStream('package.json')
const writeStream = fs.createWriteStream('temp.txt')
// pipe类似于把水从一个水池倒到另一个水池,类似于复制的作用,这个时候就是把package.json的内容复制到temp.txt里面了
readStream.pipe(writeStream)
// return 出去readStream,gulp中接收到这个stream之后,为这个readstream注册了一个end事件,去监听这个任务的结束
return readStream
}
exports.stream = () => {
const readStream = fs.createReadStream('package.json')
const writeStream = fs.createWriteStream('temp.txt')
readStream.pipe(writeStream)
readStream.on('end', () => {
done()
})
}
return 出去readStream,gulp中接收到这个stream之后,为这个readstream注册了一个end事件,去监听这个任务的结束,这样的话,这里就不需要调用done,来使任务结束了
gulp 构建过程核心工作原理
构建过程多数情况下就是将文件读出来,进行一些转换,最后写入到另一个位置,其中有三个核心的概念
我们通过读取流把我们需要的文件读出来,然后经过转换流的转换逻辑转换成我们需要的结果,再通过写入流写入到指定的文件位置
const fs = require('fs')
const { Transform } = require('stream')
exports.default = () => {
// 创建一个文件读取流
const read = fs.createReadStream('normalize.css')
// 创建文件的写入流
const write = fs.createWriteStream('normalize.min.css')
// 文件转换流
const transform = new Transform({
// 核心转换过程
transform: (chunk, encodeing, callback) => {
// 核心转换过程实现
// chunk => 通过chunk可以拿到读取流中读取到的内容(Buffer)
const input = chunk.toString()
const output = input.replace(/\s+/g, "").replace(/\/\*.+?\*\//g, "") // 空格替换掉、注释替换掉
callback(null, output) //第一个参数需要传入的是一个错误对象,没有的话就传入null
}
})
// 把读取出来的文件流导入到文件写入流
read
.pipe(transform) // 转换
.pipe(write) // 写入
return read
}
文件操作api和插件的使用
gulp给我们提供了创建文件读取流和写入流的api---src,dest,相对于低层的node的api,gulp的api更强大,也更容易使用
至于负责文件加工的转换流,绝大多数情况下我们都是通过独立的插件来提供
实际通过gulp创建构建任务的流程: 通过src方法创建一个读取流,然后通过插件提供的转换流,处理文件,最后通过dest方法创建一个写入流,从而写入到目标文件
// gulp给我们提供了创建文件读取流和写入流的api`src`,`dest`,相对于底层的node的api,gulp的api更强大,也更容易使用
const { src , dest } = require('gulp')
const cleanCss = require('gulp-clean-css') // 提供了压缩css代码的转换流 `npm i gulp-clean-css --dev`
const rename = require("gulp-rename") // npm i gulp-rename --dev
exports.default = () => {
return src('src/*.css') // 通过src方法创建文件的读取流
.pipe(cleanCss()) // 先转换,再写入到写入流中,多个转换继续在中间间接爱多个pipe操作
.pipe(rename({ extname : ".min.css"})) // extname指定重命名的扩展名
.pipe(dest('dist')) // 导出到 dest创建的写入流当中,指定一个写入目标目录
}
gulp各类插件的使用
样式编译 gulp-sass
const style = () => {
return (
src("src/assets/styles/*.scss", { base: "src" })
//sass工作的时候,会把 _ 开头的文件默认为是主文件的依赖文件,不会去转换,自动忽略
.pipe(plugins.sass({ outputStyle: "expanded" })) // `outputStyle:'expanded'`默认展开
.pipe(dest("temp"))
.pipe(bs.reload({stream: true})) // reload内部把文件流的信息推到了浏览器,`stream`以流的方式往浏览器推
);
};
脚本编译gulp-babel
babel默认只是一个EcmaScript转换平台,不做任何操作的,做转换的操作的是babel里面的插件@babel/preset-env @babel/core
const script = () => {
return (
src("src/assets/scripts/*.js", { base: "src" })
// babel默认只是一个ecmascript转换平台,不做任何操作的,做转换的操作的是babel里面的插件
// 也可以单独添加babelrc文件,我们这里写在代码里,是一样的效果 都可以
.pipe(plugins.babel({ presets: ["@babel/preset-env"] }))
.pipe(dest("temp"))
.pipe(bs.reload({stream: true}))
);
};
页面模板编译gulp-swig
const page = () => {
return src("src/*.html", { base: "src" })
.pipe(plugins.swig({ data }))
.pipe(dest("temp"))
.pipe(bs.reload({stream: true}))
};
图片和字体文件转换gulp-imagemin
const image = () => { // 不需要放到临时目录,只有会被useref影响到的目录才需要放到临时目录
return src("src/assets/images/**", { base: "src" })
.pipe(plugins.imagemin())
.pipe(dest("dist"))
};
const font = () => {
return src("src/assets/fonts/**", { base: "src" })
.pipe(plugins.imagemin())
.pipe(dest("dist"));
};
文件清除del
const del = require("del");
const clean = () => {
return del(["dist", "temp"]);
};
自动加载插件的插件 引入的东西越来越多,我们不需要每一款插件都在文件开头都引入
const loadPlugins = require("gulp-load-plugins"); // loadPlugins是一个方法
const plugins = loadPlugins(); // plugins是一个对象,所有的插件都会成为这个对象上面的属性
browser-sync
支持代码修改后的热更新,browser-sync提供的web服务器来提供我们的web服务,有利于开发阶段所见即所得
watch任务,可以监事文件路径的通配符,根据文件监视到的结果,决定是否要执行一个任务
思考那些任务是要在开发阶段执行(style,script),那些任务不是要执行(image,font之类的)
const browserSync = require(`browser-sync`);
const bs = browserSync.create();
const serve = () => {
watch("src/assets/styles/*.scss", style)
watch("src/assets/scripts/*.js", script)
watch("src/*.html", page)
watch(["src/assets/images/**","src/assets/fonts/**", "public/**"], bs.reload)
// watch("src/assets/images/**", image)
// watch("src/assets/fonts/**", font)
// watch("public/**", extra)
bs.init({
notify: false,
port: 2080,
// open: false,
// files:'dist/**',
server: {
baseDir: ["temp","src", 'public'],
routes: {
"/node_modules": "node_modules", // 原路径: 指到的位置
},
},
});
};
useref文件引用处理
会自动处理html文件中的构建注释,做对应的转换
这里使用temp目录作为中间目录,本来我们src读取流是从dist目录读取文件,做一些处理,然后通过dest写入流写入dist文件,此时就产生了一个文件读写的冲突,一边读一边写,读写没有分离开,容易产生读写文件写不进的状况,这种时候,我们需要重新规划一个文件的生成放置过程
事实上,在useref之前,所有的生成的文件算是中间产物,所以我们应该把这些中间产物放到一个临时目录temp,然后在useref的时候,从临时目录把文件拿出来,做一些转换操作,最后放到dist目录中,是比较合适的
const useref = () => { // 打破了文件结构
return src('temp/*.html', { base:"temp" }) // useref找生成之后的文件,找src下面的模板没有意义
// useref可以把注释中间引入的资源,全部合并到一个文件当中,过程中自动修改了html,并且把html的依赖的文件创建了新的文件生成到了html文件当中
.pipe(plugins.useref({searchPath: ['temp','.']}))
// html js css
.pipe(plugins.if(/\.js$/, plugins.uglify()))
.pipe(plugins.if(/\.css$/, plugins.cleanCss()))
.pipe(plugins.if(/\.html$/, plugins.htmlmin({
collapseWhitespace: true,
minifyCSS: true, // 压缩html页面中的style标签内的样式
minifyJS: true // 压缩html文件中的script标签中的js
})))
.pipe(dest('dist'))
}
总的来说gulp和grunt都是任务的执行器,并不包括具体能实现的功能,功能都是需要开发者通过代码实现的
封装自动化构建工作流
代码段的方式,不利于整体维护 其他内容。。。。疯狂打码中。。。
