

1、用原生JS实现forEach
if(!Array.prototype.forEach) {
Array.prototype.forEach = function(fn, context) {
var context = arguments[1];
if(typeof fn !== "function") {
throw new TypeError(fn + "is not a function");
}
for(var i = 0; i < this.length; i++) {
fn.call(context, this[i], i, this);
}
};
}
让我们先来看forEach的语法
array.forEach(callBack(currentValue, index, arr), thisValue)
callback
为数组中每个元素执行的函数,该函数接收一至三个参数:
-
currentValue数组中正在处理的当前元素。
-
index可选数组中正在处理的当前元素的索引。
-
array可选forEach()方法正在操作的数组。
thisArg 可选
可选参数。当执行回调函数 callback 时,用作 this 的值。
手撕算法中context, this[i], i, this与currentValue, index, arr一一对应,而context则是call()函数的指向,可有可无
2、实现apply/bind/call方法
Function.prototype.call = function (context,...args) {
context = context?Object(context):window
let res
context.fn = this
res = context.fn(...args)
delete context.fn
return res
}
Function.prototype.apply = function (context, arr) {
context = context ? Object(context) : window
context.fn = this
let res
if (!arr) {
res = context.fn()
} else {
res = context.fn(...arr)
}
delete context.fn
return res
}
Function.prototype.bind = function(context,args) {
context = context?Object(context):window
context.fn = this
let res
if(args){
res = context.fn(args)
}else{
res = context
}
}
3、实现事件委托
事件委托的原理:
事件委托是利用事件的冒泡原理来实现的,何为事件冒泡呢?就是事件从最深的节点开始,然后逐步向上传播事件,举个例子:页面上有这么一个节点树,div>ul>li>a;比如给最里面的a加一个click点击事件,那么这个事件就会一层一层的往外执行,执行顺序a>li>ul>div,有这样一个机制,那么我们给最外面的div加点击事件,那么里面的ul,li,a做点击事件的时候,都会冒泡到最外层的div上,所以都会触发,这就是事件委托,委托它们父级代为执行事件。
实现
<ul id="ul1">
<li>111</li>
<li>222</li>
<li>333</li>
<li>444</li>
</ul>
window.onload = function(){
var oUl = document.getElementById("ul1");
oUl.onclick = function(){
alert(123);
}
}
这里用父级ul做事件处理,当li被点击时,由于冒泡原理,事件就会冒泡到ul上,因为ul上有点击事件,所以事件就会触发,当然,这里当点击ul的时候,也是会触发的,那么问题就来了,如果我想让事件代理的效果跟直接给节点的事件效果一样怎么办,比如说只有点击li才会触发,不怕,我们有绝招:
Event对象提供了一个属性叫target,可以返回事件的目标节点,我们成为事件源,也就是说,target就可以表示为当前的事件操作的dom,但是不是真正操作dom,当然,这个是有兼容性的,标准浏览器用ev.target,IE浏览器用event.srcElement,此时只是获取了当前节点的位置,并不知道是什么节点名称,这里我们用nodeName来获取具体是什么标签名,这个返回的是一个大写的,我们需要转成小写再做比较(习惯问题):
window.onload = function(){
var oUl = document.getElementById("ul1");
oUl.onclick = function(ev){
var ev = ev || window.event;
var target = ev.target || ev.srcElement;
if(target.nodeName.toLowerCase() == 'li'){
alert(123);
alert(target.innerHTML);
}
}
}
4、用setTimeOut实现setInterval
function myInterval(fn,time){
let interval=()=>{
fn()
setTimeout(interval,time)
}
setTimeout(interval,time)
}
5、用JS实现map
Array.prototype.map = function (fn) {
let arr = []
for (let i = 0; i < this.length; i++) {
arr. push(fn(this[i], i, this))
}
return arr
}
6、用JS实现reduce方法
Array.prototype.myReduce = function (fn, initVal) {
let res = initVal ? initVal : 0
for (let i = 0; i < this.length; i++) {
res = fn(res, this[i], i, this)
}
return res
}
7、用JS实现filter方法
Array.prototype.myFilter = function (fn) {
let arr = []
for (let i = 0; i < this.length; i++) {
if (fn(this[i], i, this)) {
arr.push(this[i])
}
}
return arr
}
8、JS实现push
Array.prototype.myPush = function () {
let args = arguments
for (let i = 0; i < args.length; i++) {
this[this.length] = args[i]
}
return this.length
}
9、实现pop
Array.prototype.pop = function () {
if(this.length === 0) return
let val = this[this.length - 1]
this.length -= 1
return val
}
10、实现unshift
Array.prototype.unshift = function () {
let args = [...arguments]
let len = args.length
for (let i = this.length - 1; i >= 0; i--) {
this[i + len] = this[i]
}
for (let i = 0; i < len; i++) {
this[i] = args[i]
}
return this.length
}
10、实现shift
Array.prototype.shift = function () {
let removeVal = this[0]
for (let i = 0; i < this.length; i++) {
if (i !== this.length - 1) {
this[i] = this[i + 1]
}
}
this.length -= 1
return removeVal
}
11、
var n=123
function f1(){
console.log(n)
}
function f2(){
var n=456
f1()
}
f2()
console.log(n)//运行结果是123 123
12、
var length=100
function f1(){
console.log(this.length)
}
var obj={
x:10,
f2:function(f1){
f1()
arguments[0]()
}
}
obj.f2(f1,1)
13、--proto--和prototype和constructor
①__proto__和constructor属性是对象所独有的;② prototype属性是函数所独有的。但是由于JS中函数也是一种对象,所以函数也拥有__proto__和constructor属性
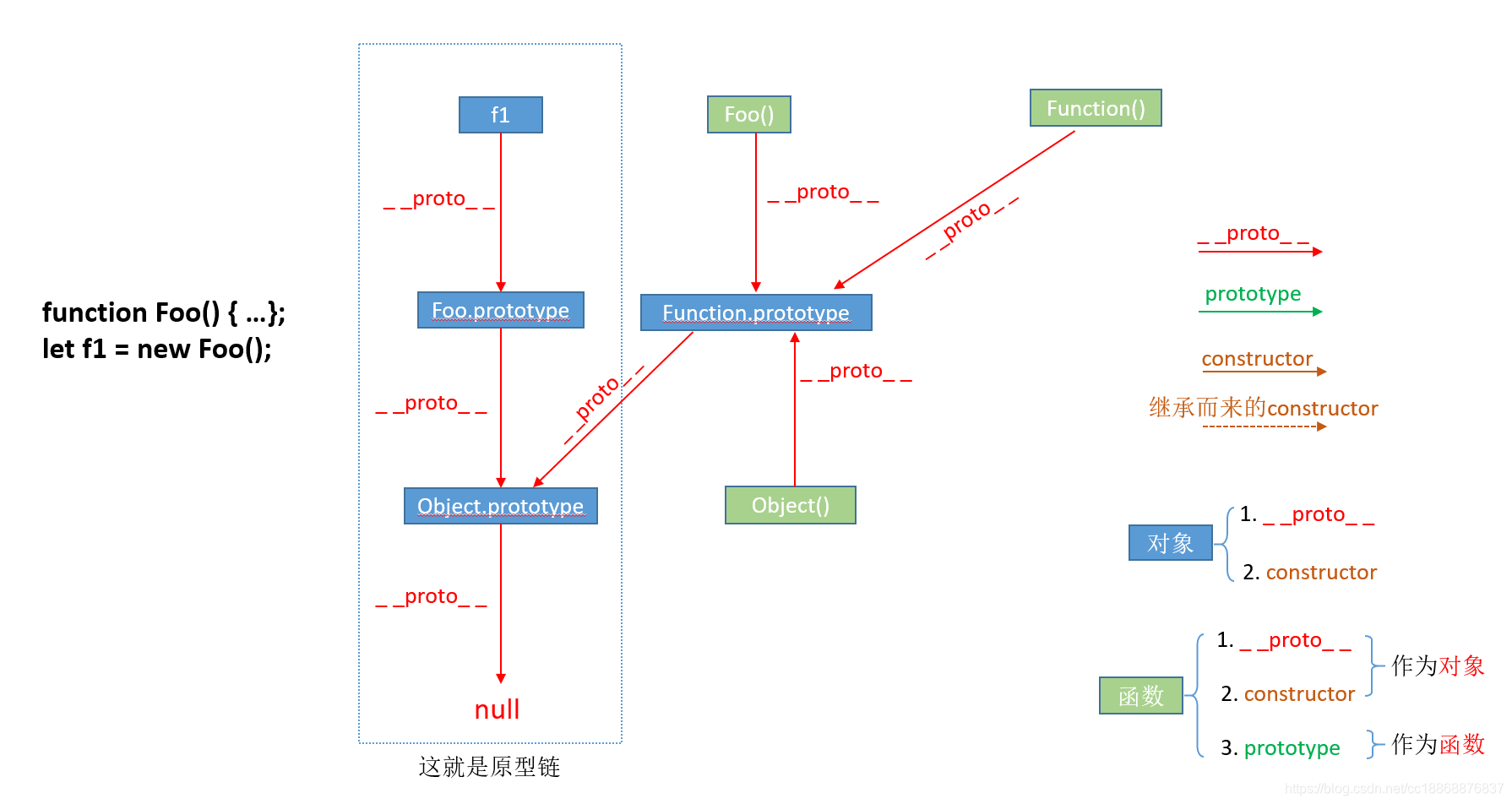
proto 属性,它是对象所独有的,可以看到__proto__属性都是由一个对象指向一个对象,即指向它们的原型对象(也可以理解为父对象),那么这个属性的作用是什么呢?它的作用就是当访问一个对象的属性时,如果该对象内部不存在这个属性,那么就会去它的__proto__属性所指向的那个对象(可以理解为父对象)里找,如果父对象也不存在这个属性,则继续往父对象的__proto__属性所指向的那个对象(可以理解为爷爷对象)里找,如果还没找到,则继续往上找…直到原型链顶端null
prototype属性,别忘了一点,就是我们前面提到要牢记的两点中的第二点,它是函数所独有的,它是从一个函数指向一个对象。它的含义是函数的原型对象,也就是这个函数(其实所有函数都可以作为构造函数)所创建的实例的原型对象,由此可知:f1.proto === Foo.prototype,它们两个完全一样。那prototype属性的作用又是什么呢?它的作用就是包含可以由特定类型的所有实例共享的属性和方法,也就是让该函数所实例化的对象们都可以找到公用的属性和方法。任何函数在创建的时候,其实会默认同时创建该函数的prototype对象。
constructor属性也是对象才拥有的,它是从一个对象指向一个函数,含义就是指向该对象的构造函数,每个对象都有构造函数(本身拥有或继承而来.
14、手动实现new
function myNew(constrc, ...args) {
const obj = {}; // 1. 创建一个空对象
obj.__proto__ = constrc.prototype; // 2. 将obj的[[prototype]]属性指向构造函数的原型对象
// 或者使用自带方法:Object.setPrototypeOf(obj, constrc.prototype)
const result = constrc.apply(obj, args); // 3.将constrc执行的上下文this绑定到obj上,并执行
return result instanceof Object ? result : obj; //4. 如果构造函数返回的是对象,则使用构造函数执行的结果。否则,返回新创建的对象
}
// 使用的例子:
function Person(name, age){
this.name = name;
this.age = age;
}
const person1 = myNew(Person, 'Tom', 20)
console.log(person1) // Person {name: "Tom", age: 20}
15、浏览器事件循环机制
任务队列
所有的任务可以分为同步任务和异步任务,同步任务,顾名思义,就是立即执行的任务,同步任务一般会直接进入到主线程中执行;而异步任务,就是异步执行的任务,比如ajax网络请求,setTimeout 定时函数等都属于异步任务,异步任务会通过任务队列( Event Queue )的机制来进行协调。
同步和异步任务分别进入不同的执行环境,同步的进入主线程,即主执行栈,异步的进入 Event Queue 。主线程内的任务执行完毕为空,会去 Event Queue 读取对应的任务,推入主线程执行。 上述过程的不断重复就是我们说的 Event Loop (事件循环)。
在事件循环中,每进行一次循环操作称为tick,通过阅读规范可知,每一次 tick 的任务处理模型是比较复杂的,其关键的步骤可以总结如下:
- 在此次 tick 中选择最先进入队列的任务( oldest task ),如果有则执行(一次)
- 检查是否存在 Microtasks ,如果存在则不停地执行,直至清空Microtask Queue
- 更新 render
- 主线程重复执行上述步骤
这里相信有人会想问,什么是 microtasks ?规范中规定,task分为两大类, 分别是 Macro Task (宏任务)和 Micro Task(微任务), 并且每个宏任务结束后, 都要清空所有的微任务,这里的 Macro Task也是我们常说的 task ,有些文章并没有对其做区分,后面文章中所提及的task皆看做宏任务( macro task)。
(macro)task 主要包含:script( 整体代码)、setTimeout、setInterval、I/O、UI 交互事件、setImmediate(Node.js 环境)
microtask主要包含:Promise、MutaionObserver、process.nextTick(Node.js 环境)(在调用任务队列前就已经调用)
setTimeout/Promise 等API便是任务源,而进入任务队列的是由他们指定的具体执行任务。来自不同任务源的任务会进入到不同的任务队列。其中 setTimeout 与 setInterval 是同源的。
console.log('script start');
setTimeout(function() {
console.log('timeout1');
}, 10);
new Promise(resolve => {
console.log('promise1');
resolve();
setTimeout(() => console.log('timeout2'), 10);
}).then(function() {
console.log('then1')
})
console.log('script end');
首先,事件循环从宏任务 (macrotask) 队列开始,最初始,宏任务队列中,只有一个 scrip t(整体代码)任务;当遇到任务源 (task source) 时,则会先分发任务到对应的任务队列中去。所以,就和上面例子类似,首先遇到了console.log,输出 script start; 接着往下走,遇到 setTimeout 任务源,将其分发到任务队列中去,记为 timeout1; 接着遇到 promise,new promise 中的代码立即执行,输出 promise1, 然后执行 resolve ,遇到 setTimeout ,将其分发到任务队列中去,记为 timemout2, 将其 then 分发到微任务队列中去,记为 then1; 接着遇到 console.log 代码,直接输出 script end 接着检查微任务队列,发现有个 then1 微任务,执行,输出then1 再检查微任务队列,发现已经清空,则开始检查宏任务队列,执行 timeout1,输出 timeout1; 接着执行 timeout2,输出 timeout2 至此,所有的都队列都已清空,执行完毕。其输出的顺序依次是:script start, promise1, script end, then1, timeout1, timeout2
16、强缓存与协商缓存
一、强缓存
到底什么是强缓存?强在哪?其实强是强制的意思。当浏览器去请求某个文件的时候,服务端就在respone header里面对该文件做了缓存配置。缓存的时间、缓存类型都由服务端控制,具体表现为: respone header 的cache-control,常见的设置是max-age public private no-cache no-store等。
在HTTP/1.0和HTTP/1.1当中,这个字段是不一样的。在早期,也就是HTTP/1.0时期,使用的是Expires,而HTTP/1.1使用的是Cache-Control。让我们首先来看看Expires。
Expires
Expires即过期时间,存在于服务端返回的响应头中,告诉浏览器在这个过期时间之前可以直接从缓存里面获取数据,无需再次请求。比如下面这样:
Expires: Wed, 22 Nov 2019 08:41:00 GMT
复制代码
表示资源在2019年11月22号8点41分过期,过期了就得向服务端发请求。
这个方式看上去没什么问题,合情合理,但其实潜藏了一个坑,那就是服务器的时间和浏览器的时间可能并不一致,那服务器返回的这个过期时间可能就是不准确的。因此这种方式很快在后来的HTTP1.1版本中被抛弃了。
Cache-Control
在HTTP1.1中,采用了一个非常关键的字段:Cache-Control。这个字段也是存在于
它和Expires本质的不同在于它并没有采用具体的过期时间点这个方式,而是采用过期时长来控制缓存,对应的字段是max-age。比如这个例子:
Cache-Control:max-age=3600
代表这个响应返回后在 3600 秒,也就是一个小时之内可以直接使用缓存。
max-age表示缓存的时间是315360000秒(10年),public表示可以被浏览器和代理服务器缓存,代理服务器一般可用nginx来做。immutable表示该资源永远不变,但是实际上该资源并不是永远不变,它这么设置的意思是为了让用户在刷新页面的时候不要去请求服务器!啥意思?就是说,如果你只设置了cahe-control:max-age=315360000,public 这属于强缓存,每次用户正常打开这个页面,浏览器会判断缓存是否过期,没有过期就从缓存中读取数据;但是有一些 "聪明" 的用户会点击浏览器左上角的刷新按钮去刷新页面,这时候就算资源没有过期(10年没这么快过),浏览器也会直接去请求服务器,这就是额外的请求消耗了,这时候就相当于是走协商缓存的流程了(下面会讲到)。如果cahe-control:max-age=315360000,public再加个immutable的话,就算用户刷新页面,浏览器也不会发起请求去服务,浏览器会直接从本地磁盘或者内存中读取缓存并返回200状态,看上图的红色框(from memory cache)。这是2015年facebook团队向制定 HTTP 标准的 IETF 工作组提到的建议:他们希望 HTTP 协议能给 Cache-Control 响应头增加一个属性字段表明该资源永不过期,浏览器就没必要再为这些资源发送条件请求了。
强缓存总结
-
cache-control: max-age=xxxx,public 客户端和代理服务器都可以缓存该资源; 客户端在xxx秒的有效期内,如果有请求该资源的需求的话就直接读取缓存,statu code:200 ,如果用户做了刷新操作,就向服务器发起http请求
-
cache-control: max-age=xxxx,private 只让客户端可以缓存该资源;代理服务器不缓存 客户端在xxx秒内直接读取缓存,statu code:200
-
cache-control: max-age=xxxx,immutable 客户端在xxx秒的有效期内,如果有请求该资源的需求的话就直接读取缓存,statu code:200 ,即使用户做了刷新操作,也不向服务器发起http请求
-
cache-control: no-cache 跳过设置强缓存,但是不妨碍设置协商缓存;一般如果你做了强缓存,只有在强缓存失效了才走协商缓存的,设置了no-cache就不会走强缓存了,每次请求都回询问服务端。
-
cache-control: no-store 不缓存,这个会让客户端、服务器都不缓存,也就没有所谓的强缓存、协商缓存了。
-
s-maxage:这和
max-age长得比较像,但是区别在于s-maxage是针对代理服务器的缓存时间。值得注意的是,当Expires和Cache-Control同时存在的时候,Cache-Control会优先考虑。
二、协商缓存
上面说到的强缓存就是给资源设置个过期时间,客户端每次请求资源时都会看是否过期;只有在过期才会去询问服务器。所以,强缓存就是为了给客户端自给自足用的。而当某天,客户端请求该资源时发现其过期了,这是就会去请求服务器了,而这时候去请求服务器的这过程就可以设置协商缓存。这时候,协商缓存就是需要客户端和服务器两端进行交互的。
etag:每个文件有一个,改动文件了就变了,就是个文件hash,每个文件唯一,就像用webpack打包的时候,每个资源都会有这个东西,如: app.js打包后变为 app.c20abbde.js,加个唯一hash,也是为了解决缓存问题。
last-modified:文件的修改时间,精确到秒
也就是说,每次请求返回来 response header 中的 etag和 last-modified,在下次请求时在 request header 就把这两个带上,服务端把你带过来的标识进行对比,然后判断资源是否更改了,如果更改就直接返回新的资源,和更新对应的response header的标识etag、last-modified。如果资源没有变,那就不变etag、last-modified,这时候对客户端来说,每次请求都是要进行协商缓存了,即:
发请求-->看资源是否过期-->过期-->请求服务器-->服务器对比资源是否真的过期-->没过期-->返回304状态码-->客户端用缓存的老资源。
这就是一条完整的协商缓存的过程。
当然,当服务端发现资源真的过期的时候,会走如下流程:
发请求-->看资源是否过期-->过期-->请求服务器-->服务器对比资源是否真的过期-->过期-->返回200状态码-->客户端如第一次接收该资源一样,记下它的cache-control中的max-age、etag、last-modified等。
所以协商缓存步骤总结:
请求资源时,把用户本地该资源的 etag 同时带到服务端,服务端和最新资源做对比。 如果资源没更改,返回304,浏览器读取本地缓存。 如果资源有更改,返回200,返回最新的资源。
为什么要有etag? 你可能会觉得使用last-modified已经足以让浏览器知道本地的缓存副本是否足够新,为什么还需要etag呢?HTTP1.1中etag的出现(也就是说,etag是新增的,为了解决之前只有If-Modified的缺点)主要是为了解决几个last-modified比较难解决的问题:
-
一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候我们并不希望客户端认为这个文件被修改了,而重新get;
-
某些文件修改非常频繁,比如在秒以下的时间内进行修改,(比方说1s内修改了N次),if-modified-since能检查到的粒度是秒级的,这种修改无法判断(或者说UNIX记录MTIME只能精确到秒);
-
某些服务器不能精确的得到文件的最后修改时间。
三、缓存的位置
前面我们已经提到,当强缓存命中或者协商缓存中服务器返回304的时候,我们直接从缓存中获取资源。那这些资源究竟缓存在什么位置呢?
浏览器中的缓存位置一共有四种,按优先级从高到低排列分别是:
- Service Worker
- Memory Cache
- Disk Cache
- Push Cache
Service Worker
Service Worker 借鉴了 Web Worker的 思路,即让 JS 运行在主线程之外,由于它脱离了浏览器的窗体,因此无法直接访问DOM。虽然如此,但它仍然能帮助我们完成很多有用的功能,比如离线缓存、消息推送和网络代理等功能。其中的离线缓存就是 Service Worker Cache。
Service Worker 同时也是 PWA 的重要实现机制,关于它的细节和特性,我们将会在后面的 PWA 的分享中详细介绍。
Memory Cache 和 Disk Cache
Memory Cache指的是内存缓存,从效率上讲它是最快的。但是从存活时间来讲又是最短的,当渲染进程结束后,内存缓存也就不存在了。
Disk Cache就是存储在磁盘中的缓存,从存取效率上讲是比内存缓存慢的,但是他的优势在于存储容量和存储时长。稍微有些计算机基础的应该很好理解,就不展开了。
好,现在问题来了,既然两者各有优劣,那浏览器如何决定将资源放进内存还是硬盘呢?主要策略如下:
- 比较大的JS、CSS文件会直接被丢进磁盘,反之丢进内存
- 内存使用率比较高的时候,文件优先进入磁盘
Push Cache
即推送缓存,这是浏览器缓存的最后一道防线。它是 HTTP/2 中的内容,虽然现在应用的并不广泛,但随着 HTTP/2 的推广,它的应用越来越广泛。
17、实现深拷贝
let deepCopy = (obj) => {
if (!obj instanceof Object) {
throw new Error('not a object')
}
let newObj = Array.isArray(obj)?[]:{}
for (let key in obj) {
newObj[key] = obj[key] instanceof Object?deepObj(obj[key]):obj[key]
}
return newObj
}
18、nodeValue、value和innerHTML的区别
DOM一共有12种节点,其中常见的有:
1.文档节点(document,一个文档只能有一个文档元素(在html文档中,它是))
2.元素节点(div、p之类)
3.属性节点(class、id、src之类)
4.文本节点(插入在div、p之类里面的内容)
5.注释节点
nodeValue,是节点的值,其中属性节点和文本节点是有值的,而元素节点没有值。
innerHTML以字符串形式返回该节点的所有子节点及其值
value是获取input标签value的值
19、箭头函数与普通函数的区别
1、箭头函数全都是匿名函数
2、箭头函数中this的指向不同,是在定义函数的this时就已经确定。
3、箭头函数不具有arguments对象
20、MVVM
MVVM是Model-View-ViewModel的简写。即模型-视图-视图模型。【模型】指的是后端传递的数据。【视图】指的是所看到的页面。【视图模型】mvvm模式的核心,它是连接view和model的桥梁。它有两个方向:一是将【模型】转化成【视图】,即将后端传递的数据转化成所看到的页面。实现的方式是:数据绑定。二是将【视图】转化成【模型】,即将所看到的页面转化成后端的数据。实现的方式是:DOM 事件监听。这两个方向都实现的,我们称之为数据的双向绑定。总结:在MVVM的框架下视图和模型是不能直接通信的。它们通过ViewModel来通信,ViewModel通常要实现一个observer观察者,当数据发生变化,ViewModel能够监听到数据的这种变化,然后通知到对应的视图做自动更新,而当用户操作视图,ViewModel也能监听到视图的变化,然后通知数据做改动,这实际上就实现了数据的双向绑定。并且MVVM中的View 和 ViewModel可以互相通信。
