

前言
操作系统我觉得是软件领域最难学的部分了,绝对没有之一,太多的概念和知识点,要理清楚期中脉络,相互关系,然后串起来形成一个技能树,这也一个及其困难的事。更令人绝望的是绝大部分学习资料都不合格,我找了很久,有半年吧,终于找到了O看的资料,看完这些能帮你把整个操作系统学明白,所以轻珍惜这次的资料推荐还
有一点,操作系统虽然学完了你感觉没什么大用,能直接帮助你的很少,但是请不要因此请示对于其的学习,操作系统的内容是贯穿我们整个职业生涯的,所有的代码,软件,都是运行在操作系统上的,职业生涯中肯定会是不是碰到涉及操作系统的时候,这个时候你不会,相关的点你就吸收不好,干脆看不懂,很耽误你事。你要是遇到一点学一点,你会崩溃的,扯出泥巴带着跟,跟还连着别的苗,那学习效果懒得1B
android 面试一般估计不会问到这些,但是不要忽视操作系统的内容,操作系统里的很多内容其实是我们精进技术必须了解的基础知识点,操作系统不熟后面你看好多深入C层的技术会根天书一样,尤其是腾讯的 MMKV 了,看得懂吗,能理解吗,即便对着你讲你也会懵逼的吧
学习资料
主力资料:
- B站:Y4NGY 老师的 Linux 课程,这位老师是南京那边学校的
《Linux内核设计与实现》,容易上手
辅助资料:
- 辅助资料[1]:【os浅尝】话说进程和线程~
- 辅助资料[2]:【os浅尝】话说虚拟内存~
- 辅助资料[3]:Linux进阶之进程、线程及调度算法
资料食用教程:
- 小白们直接看
Y4NGY的课程,最好的方式了,没有其它 - 辅助资料[1][2] 适合对 linux 有基础像快速过一遍的,时间加起来也就15分钟左右
- Y4NGY 老师的课程在内核调度这里要是打架看不懂没明白的,请食用 辅助资料[3],2者印证下来就没问题了
简单介绍下 linux
操作系统简单可以分成3部分:封装、抽象硬件的内核,给用户程序提供服务的外层,UI层
Linux 不是一个完整的操作系统,Linux 仅仅是一个开源的内核罢了,有好多基于 Linux 内核开发的操作系统:ubuntu/centos/opensuse/redhat这些
怎么理解,这些所谓的系统都是在 Linux 内核的基础上,添加了自己的一层UI界面和一些服务,还有软件源(类似于应用市场)罢了,包括 android 都是这样
Linux 的学习是很困难的一件事
- 入门 -> 推荐看《鸟哥的私房菜》这本书,先明白 linux 的几个组成部分,linux 的安装,基本的 Linux 指令,要学习的东西很多的shell 命令
- 深入 -> 推荐看《unix高级环境编程》,熟悉 posxi api,能编写 Linux 系统代码
- 然后就是学习 mysql/redis 等等基于在 Linux 环境上跑的软件了
所以说学习 Linux 是一件耗时很长的事
操作系统是个什么东西
操作系统:封装一切对硬件的操作、交互,在软件开发层面屏蔽硬件操作,只需关心代码逻辑即可。按马老师的说法,操作系统这东西就是一种特殊的软件,对上服务我们的程序,对下管理硬件
操作系统是60年代开始出现的,进化到现在也是经历了许许多多的。在没有操作系统的时代,我们写程序可不会像现在一样简单,只要专注于业务就行了
所有的操作我们都要自己去做关联,我们要自己去和硬件打交道,我们要自己控制内存如何存储数据,控制内存地址的变迁,往显卡写入数据,需要知道显卡的端口号,往显示器输出图像,需要知道显示器什么制式的,用打印机打印需要知道打印机是什么牌子的,每一家不同牌子的打印机支持的机器指令都是不同的
这样写程序本身是一件及其费时费力的事,而且写出来的程序只能在这个型号上的机器跑,换个硬件这个程序就不能用了,程序没有一点移植性可言,放到现在这是不可想象的,但是当年就是这样
后来人们发现这样不行啊,硬件一更新程序就要重新写,这样太费事了,根本不是程序应该有的样子。于是聪明的人想到应该把那些和硬件有关的操作都统一起来,屏蔽掉这些繁琐的和硬件之间操作,使用统一协议规范硬件之间的交互、指令,在程序开发时不用再考虑和硬件之间的操作,把这些交给上面我们封装好的和硬件交互的代码,所以操作系统诞生了
我这个解释估计不是很好,但是操作系统虽然是个复杂的哦东西,但是本质上不复杂,就是把所有根硬件的操作都封装起来,最后就变成了操作系统这个庞然大物。最合适的理解其实应该是早期的 DOS 系统
可能第一次接触的朋友还是不怎么明白,简单的说从啊做系统分2层:一层是封装硬件操作的内核;一层是给应用进程提供功能的外层,大家这么理解就行了,下面就说到内核了。要是还不理解,那么就记住操作系统是硬件的一层抽象
按照我新找到的学习资料来说,操作系统扮演的是一个 interface 接口的角色,软硬件之间的接口分3层:
硬件 —> 硬件之间的接口:典型的 USB 接口就是,使用总线相联,硬件提供中断命令和驱动给操作系统实现硬件的响应、使用、调度硬件 -> 软件之间的接口:软件 -> 软件之间的接口:
操作系统向下提供硬件->软件的接口,以实现软件操作硬件的可能性;向上提供软件->软件的接口,已实现用户程序对硬件操作的可能性和安全、权限管理
操作系统内核
一般操作系统都有这么一个内核,内核里面管理硬件,在内核周边运行着一些服务,来管理应用程序
操作系统分2层:内核态、用户态,这个内核指的就是操作系统内核了,内核的东西就是上面说的封装的那些对硬件的操作。这些和硬件的操作很多,除了内核的核心之外,基于封装思想还有5大功能模块:
内存管理模块cpu调度模块其他硬件设备管理模块文件系统管理模块进程调度模块
操作系统内核就是一个程序,而这5大功能又可以看成5大程序,当然操作系统内核还是有自己的核心的,一些基础的、杂七杂八的内容还是放在核心中的,核心中是操作系统最为核心的东西,核心和5大功能程序共同组成和操作系统内核,5个功能模块可以看成单独分离出来的核心的小弟,受核心管理,核心是老大,带着5个小弟,这个社团叫操作系统内核
严格抠字眼的话我这里应该不怎么对,但是大家要是不熟悉,之前没研究过的话,这么理解是最好的,对于做 Android 的来说,我么拿过来学习操作系统的部分不是为了开发操作系统的,就是为了夯实下基础的知识点,能理解就行了
宏内核、微内核
什么是宏内核,看字面意思,宏是大的意思,5大功能模块和核心必须安装在一起共同组成系统内核,这个就是宏内核,当然这样的内核会很大,会占用很多系统资源。PC,手机都是宏内核,win 启动后大家看看吃多少内存走就知道这种宏内核设计非常耗费系统资源了
什么是微内核,微就是微小,可以把系统内核做的很小,目的是减少资源消耗,微内核只有核心和进程管理2个组件。其他功能组件可以安装在系统内核之外的地方,这样系统内核运行时还是会去寻找相应的功能组件,有点像分布式系统
形象理解下:
宏内核 -内核这团大哥和小弟必须坐在一起办公微内核 -社团本部有大哥和进程调度这个管钱的小弟就行了,其他人可以外派出去,也可以在本部呆着
2者的优缺点:
- 微内核占用资源非常少,内核体积也很小,有的只有不到10M大小,非常适合物联网设备,物联网设备硬件有好有坏,有的需要Z合格功能,有的不需要,做成微内核这种分布式系统,需要的功能组件就填进来,不需要就不放进
- 宏内核的优点是性能好,因为所有功能组件都安装在系统中,调用相关功能的时候可以直接运行。而微内核必须去寻找这个相关的功能程序,然后再把结果交换给内核,内核再通知用户,性能上没有优势
对于微内核来说,除了进程调度这个模块必须在打在内核中,其他的模块你想用就挂到内核中,甚至可以做成分布式的,挂在别的设备、芯片上
华为退出的鸿蒙就是微内核的,智能家居可以看成微内核应用,一屋子的设备,冰箱、电视、空调、扫地机器人、洗碗机,这些有一个总的控制器,这个总得控制器可以看成内核核心,其他设备可以看成不同的功能组件,用到哪个去找哪个就行,整体系统可以随时扩容或者瘦身
你说一张 SIM 卡能有多大性能,宏内核系统跑得起来吗,也只能是微内核这种系统啦,这种小微设备还有很多,恰恰这些小微设备就是物联网的基础
微内核的特性必然在物联网时代中大红大紫,微内核系统本身又和硬件尤其是芯片紧密相关,说不定物联网的时代华为麒麟+鸿蒙会占半壁江山也不说不定,现在头部公司都在大力推进、后进公司也在布局这方面
PC时代:inter + window移动时代:ARM + Android/IOS
我很期待物联网 IOT 时代是:麒麟+鸿蒙的,很期待
外核
外核也是一种核心,只不过是应用在科研领域,市面上的商业项目是没有的。起特点是可以根据具体场景,生成最适合这个场景运行的系统内核
像阿里正在研发的 JVM,内存分配不再是根据对象为基础分区,分代来了,针对高并发这种场景,每一个 request 进来,JVM 都会给这个 request 分配一块内存,request 结束时回收这块内存。不用再去遍历对象树,不用再去判断对象是不是死了,是不是要升级,最简单的就是性能最好的
还有阿里研发的多租户,这个不详说了
这个了解就行,顶尖大学里可能能看见这东西
VMM 虚拟化
VMM可以看成是一个虚拟层,VMM 又专用的应用场景:资源极端富裕。像有的公司只是泡泡一般的简单程序,但是服务器配置贼高,128个CPU,每个CPU8个核,内存几T,你说这样资源浪费不浪费。所以就又了 VMM 这个东西,可以在同一套硬件资源上运行多个操作系统,VMM 就是介于硬件核操作系统之间的虚拟核心
这个了解即可
从安全层面理解系统内核
这个是重点
早在 DOS 系统时代,一个程序想干什么就干什么,想控制哪个硬件就控制哪个硬件,想访问哪块内存就访问哪块内存,这个时代也是病毒天堂的时代,计算机是极度不安全的
为了系统安全,为了系统稳定运行
- 硬件操作权限上,操作系统分成2层:
内核态,用户态 - 内存地址上,操作系统分成2块:
内核空间,用户空间
用户程序是不能访问内核空间的,但是内核可以访问用户程序内存空间
目前,在硬件层面就可以实现对指令分级,inter CPU 上吧机器指令分成4个级别:ring0,ring1,ring2,ring3,Linux 系统只使用了 ring0,ring3 这2个权限级别,具体解释就是:
用户程序程序只能使用 ring3 级别的指令,而内核态程序就能使用 ring0 级别的指令
用户程序想用网卡读取数据,那么首先向系统内核申请 ring0 指令使用授权,操作系统内核使用 ring0 指令读到数据后,再使用 ring3 指令把数据交给用户程序。对于硬件来说是指令在 ring0/ring3 之间不断切换
再比如用户程序计算2+3,用户程序使用 ring3 指令生成2核3,然后向内核申请 add 计算这样的 ring0 指令的使用权限,系统内核使用 ring0 指定 add 之后把数据写回内存,用户程序用 ring3 指令就能读取到结果了
ring0 可以访问所有的内存,ring3 只能访问属于自己程序的那块内存
系统内核的功能都是通过内核函数对外暴露出来的,Linux 系统内核指令不多,就200多个,像 java 中 socket 操作,实际上是调系统内核的操作。创建线程,用户程序是干不了的,只能去找内核做操作,内核操作完了再通知你。JVM 什么级别,站在操作系统的角度,你JVM就是一个普通程序
操作系统层级结构
我们继续深化理解操作系统的层级结构,上面说了操作系统简单的就分2层:内核和外层服务,不直观,不好理解,虽然上面我们看了系统内核,但是这里我们还是要结合图示进一步看看
- 蓝色是整个操作系统的范围
- 上部分是操作系统外层,包括GUI用户界面,batch批处理,这个就是命令行界面了,command line 这个是命令行,这些都是针对平通用户而言的,这个就是 linux 里面的 shell 命令了
- 中间的是用户接口了,这一层就针对的是广大程序员开发工程师了,这一层级提供了大量 API 可以用来调用系统调用、绘制界面、操作硬件设备,这些 API 的综合使用可以构建出优秀的用户程序,注意这些系统 API 还是C/C++ 的,很多语言 JDK 会对这一层做一层本语言的包装方便开发者使用,比如 java JDK 中的 GUI 开发 API,里面就是调用操作系统的系统 API,这一层级也是也就是我们常说的 native API
- 再下一层是 system calls,这个是系统调用,系统 API 内部使用的就是系统调用。操作系统对硬件操作封装出来的方法就是系统调用,但是这些调用不能简简单单的全部对外开放直接使用,而是以系统 API 的方式提供对外使用
- 最下面一层就是就是系统内核了,这里大家再感觉一下
系统API、系统call关系
有必要再强调一下系统 API 和系统调用的关系,这2个概念必须理解清晰才行:
系统调用提供了访问和使用操作系统提供的服务的接口,这一层级的实现是操作系统级别的系统API是指名了参数和返回值的一组函数,应用app开发人员通过API间接访问系统调用
系统调用也是函数,只不过是操作系统级别的函数,可以理解为系统内核中的函数,这些方法因为安全和权限考虑不直接对外提供访问服务,而是通过经过考虑的、再次封装过的、可以对外提供访问服务的系统API来间接调用。系统API这一层的方法就不在内核中了,而是在内核外部
比如标准函数库里提供的 API:printf,可以显示器输出字符串,这个函数内部就是使用了系统调用 wirte,是一个从用户态到内核态,再从内核态切换回用户态的过程
还有几张有意思的图来说这个问题:
系统调用
理解到图中的这些内容就行了,更深入的有需求再去看,一般 app 层开发是用不到了
80中断
早期不是每一个系统东段都有对应的中断编号的,而是用统一用一个中断编号:0x80,80中断就是这么来的,用 0x80 代表系统调用,软中断
0x80 这个中断在中断向量表里保存了系统调用派发程序的入口,去系统调用表里根据调用编号找到处理函数入口
后来为了优化系统调用的性能,改为通过特殊指令触发系统调用,X86的 sysenter、AMD64的 syscall,有个专用寄存器保存派发入口,不用再去中断向量表里查了
理解虚拟地址空间
常常被2个概念搞的头大~
虚拟地址:这是说内存寻址的虚拟内存:这来源于 WIN 系统,说的是用硬盘来扩展内存的大小,把一部分硬盘当内存使
这2个概念不要乱,我们经常说的其实是虚拟地址这个东西,这个概念很多人都说,但是能讲清除的甚少啊,推荐大家看看B站佩雨小姐姐的这2个视频:
简单易懂,我算是看这个视频真正理解了虚拟地址
首先大家必须明确地址是干啥的,物理内存中每一个内存位都有在矩阵中,有自己的坐标,我们通过这个坐标来找到数据,坐标就是地址
物理地址就是内存位真实的物理存储位置
虚拟内存是操作系统内核为了对进程地址空间进行管理(process address space management)而精心设计的一个逻辑意义上的内存空间概念。我们程序中的指针其实都是这个虚拟内存空间中的地址。
早期我们直接使用物理内存地址
早期,那时程序都很小,我们都是直接把程序本身全部加载在内存中的。比如1个程序在硬盘中是2M大小,我们运行这个程序会把2M的代码全局一次性加载进内存,此时我们适用物理内存地址来访问内存
就行这样->
后面我们发现了其中严重的问题:
进程不隔离带来的安全问题:典型的 DOS 系统,病毒可以随意干什么,病毒进程可以随意修改其他进程的数据。因为进程间内存是不隔离的,为什么不隔离呢,因为大家用的都是真实的物理内存地址,我们可以访问其他进程的地址上的数据使用效率低:要是运行的程序需要的内存大小超过了物理内存大小呢,系统会把部分内存数据写入硬盘,把硬盘当做内存的次级缓存,把节省出来的内存分配给需要的进程,这样会造成内存隔离,进程用的都是内存碎片,内存碎片会带来性能问题
后来产诞生了虚拟内存
正是因为上面直接使用真实物理内存地址带来的种种问题,我们不得不给真实内存地址上套一层,使用一个相互之间不通用的别名来代替真实内存地址,这个虚假的内存地址别名就是虚拟地址了
我就不画图了,大家脑补下,就好像我们给电报加密,进程A使用自己加密方式去使用内存地址,病毒进程即便拿到进程A的内存地址也无法定位到真实的内存地址
虚拟内存使用:分段、分页 技术进一步优化内存使用,具体由操作系统和CPU硬件中的MMU单元来管理
在计算机系统中,映射的工作是由硬件和软件共同来完成的。承担这个任务的硬件部分叫做存储管理单元MMU,软件部分就是操作系统的内存管理模块了
1. 分段技术
为了避免内存碎片的诞生,我们直接给进程分配一段连续的真实内存,然后使用虚拟内存映射到真实物理内存上
通过分段技术,实现了进程间内存隔离,进程之间不能访问其他进程的内存了,因为每个进程虚拟地址都是独一份,单独维护的,单独和物理内存映射的,其他进程拿到也没用,没有虚拟内存映射关系你是找不到真实物理地址的
2. 分页技术
分段技术远远不够,内存对于电脑来说永远是不够的,我们不能说进程你要多少内存就给你多少物理内存,一个电脑上同时运行的进程数有好几十,这点内存怎么够分,即便几T都不一定够分,所以我们使用了分页这个技术,实现按需分配
进程A你要60M内存,OK 虚拟内存层面给你,但是物理内存先不给你,等你运行时,需要一点内存我就给你分配一点内存,做到按需分配,这样就能实现内存的高效应用了
分页中的页指的是内存管理单元把内存安页这个基本的单位分配,一页是4K大小,虚拟内存中的页叫页,物理内存中的页叫页框,记录页于页框之间映射关系的叫页表
页的分配原则是按需分配,进程A告诉操作系统我需要60M内存,那么操作系统就先给了进程A60M虚拟内存,但是没给物理内存。在进程运行时计算真的需要1M内存,此时才分配1M物理内存给进程A,实现进程A虚拟内存于这1M物理内存的映射,等不够用了再分配物理内存,但是总量不能超过进程A启动时申请的60M虚拟内存这个阀值
3. 页于页框的映射关系
页的地址由:页码+偏移量组成
页码- 虚拟内存中页的位置,其实就是排序数,虚拟内存划分的最小单位就是页,假如说虚拟内存分10000个页,那么0x23这个页码数就是说第0x23个页偏移量- 数据位于该页中的位置,一页是4K的大小,可以装好多对象了,内存又是顺序分配,所以这个偏移量就是数据在这个页中内存位置的首地址,页和页框中的偏移量其实都是一样的,大家想啊都是4K大小,在这4K中的位置能有区别嘛
4. 页表
每个进程都有自己独立的虚拟地址空间,这些地址空间需要通过页表映射到不同的物理地址
页表记录页于页框的映射关系,页和页框地址的偏移量,页表核心的就是记录页码和页框码了,看下图就是这个意思
最终CPU处理虚拟内存到物理内存就是下图:
5. 数据共享
大家想想要是能在2个进程中,要是都是指向相同的物理内存上,是不是就能实现跨进程内存共享啦,内存共享是进程间通信的一种方式
6. SWAP
swap 这个概念一直都不好理解,简单来说就是实现虚拟内存->硬盘的映射,下面是我找到的比较明白的解释
虚拟内存通过缺页中断为进程分配物理内存,内存总是有限的,如果所有的物理内存都被占用了怎么办呢?
Linux 提出 SWAP 的概念,Linux 中可以使用 SWAP 分区,在分配物理内存,但可用内存不足时,将暂时不用的内存数据先放到磁盘上,让有需要的进程先使用,等进程再需要使用这些数据时,再将这些数据加载到内存中,通过这种”交换”技术,Linux 可以让进程使用更多的内存
另一个物理内存管理要处理的事情就是页面的换出。每个进程都有自己的虚拟地址空间,虚拟地址空间都非常大,而不可能有这么多的物理内存。所以对于一些长时间不使用的页面,将其换出到磁盘,等到要使用的时候,将其换入到内存中,以此提高物理内存的使用率
当然,也存在这样的情况:在请页成功之后,内存中已没有空闲物理页框了。这是,系统必须启动所谓地“交换”机制,即调用相应的内核操作函数,在物理页框中寻找一个当前不再使用或者近期可能不会用到的页面所占据的页框。找到后,就把其中的页移出,以装载新的页面。对移出页面根据两种情况来处理:如果该页未被修改过,则删除它;如果该页曾经被修改过,则系统必须将该页写回辅存
为了公平地选择将要从系统中抛弃的页面,Linux系统使用最近最少使用(LRU)页面的衰老算法。这种策略根据系统中每个页面被访问的频率,为物理页框中的页面设置了一个叫做年龄的属性。页面被访问的次数越多,则页面的年龄最小;相反,则越大。而年龄较大的页面就是待换出页面的最佳候选者
最后要注意 Swap 和 mmap 的区别:Swap 是操作系统自动的内存到文件的映射,mmap 是用户主动的内存到文件的映射,后面会详说 mmap
Swap:表示非mmap内存(也叫anonymous memory,比如malloc动态分配出来的内存)由于物理内存不足被swap到交换空间的大小
7. PTBR、TLB
大家想啊,页表本身也是存储在内存中的,为了访问一个内存中的数据,要经历2次内存访问:1-> MMU 访问内存中进程的页表,获取对一个的物理内存地址,2-> 通过物理地址访问变量
减少 CPU 访问内存的次数是系统优化的重点,这里自然就有优化的点,要是 MMU 能直接计算出进程虚拟内存对用的物理地址,那就能减少一次访问内存的操作了,所以 CPU 结构中专门有一个寄存器会存储处于运行状态的进程、进程的物理内存首地址,这个寄存器就是:PTBR
后来物理内存分块分配,光有 PTBR 寄存器也不好使了,物理内存都是按块分配,不再是连续分配了,这时候就要在 CPU 中缓存进程页表了,于是又诞生了一个寄存器:TLB,该寄存器会保存进程部分页表,为了提高 TLB 的命中还有其他一些算法,这里就不说了,知道这个东西就行了,线程切换,进程切换,TLB 缓存也会跟着失效
进程
进程大家熟悉这个东西,很多人觉得知道是什么个东西就行了, 我知道它的特性啊,这些就够了呀,但是我还是要说请大家仔仔细细的把进程的所有学习一遍,这回解释很多模糊的地方,及其有学习意义
进程的概念
程序、进程、线程,这2个概念,面试的时候总是爱问,除了应付面试之外,我们其实也是应该能把这3个概念说清楚的
程序:程序就是一个可执行文件,是存储再硬盘上的一列列指令,就像 win 系统里的.exe文件,这是一个可执行的安装文件,解压缩我们可以看到好多好多的代码,只是这些代码现在都是静态的,都还没有运行起来进程:当一个可执行文件被加载进内存,程序就变成了进程。进程就是已经被加载进内存的一系列相互关联的可执行指令。进程把第一条指令加载进内存,然后按顺序一条条的执行指令。进程本质就是程序计数器+运行时数据程序线程:CPU 执行的任务就是一个个线程,线程中有栈帧,栈帧就是一个个将要运行的方法和临时数据
面试时这样回答:进程是资源分配、保护和调度的基本单位,线程是CPU调度的基本单位
并发并行
在继续深入进程之前,先把并发并行这俩概念搞清楚,很有必要
并行:多个进程在多个CPU核心中一起执行,执行时机是固定的,是一起执行的,相互之间没有资源的抢占和冲突。同一个时间点,多个进程在同时运行。并发:多个进程在多个CPU核心中执行,可以是同时执行,也可以是你前我后,我后你前,执行时机是随机的,相互之间有资源的抢占和冲突,比如对于CPU时间片的抢夺。一个时间段内,多个进程在运行。同一时刻只能一个程序在运行,因为只有一个cpu。
进程的内存结构
得益于上面我们已经说多了虚拟内存的部分,大家知道了用户态和内核态,所有操作硬件的指令都必须要在内核态中执行,这里我们就好说多了
1. 虚拟地址空间结构
不管物理内存有多少,linux 系统都会给每一个进程分配4G的虚拟内存也叫逻辑内存
0-3G的低位内存分配给用户态3-4G的高位内存分配给内核态
用户态的3G内存就是进程自己的,别的进程访问不了,但是这1G的内核态内存都会同一映射到物理内存中的内核内存部分
物理内存中,一般有1/4,最少1G的起始内存是分配给操作系统内核专门使用的,用户进程是没法映射到内核所属的物理内存的,但是操作系统内核却可以访问全部的物理内存地址,进程间通信就是通过内核映射的物理内存做中转的
从3G-4G空间为内核空间,存放内核代码和数据,只有内核态进程能够直接访问,用户态进程不能直接访问,只能通过系统调用和中断进入内核空间,而这时就要进行的指令权限切换
操作系统中的所有进程中的这1G内核内存映射到的都是同一段物理内存,也就是所有进程共享内核所属的物理内存,这点必须明确
最后我们总体的看一下这4G逻辑内存的结构:
2. 用户态内存结构
内核态内存先不说,我们来详细看看属于进程自己的这3G用户态内存,结构如图:
text:这是代码段内存,保存就是每个程序指令的首地址data、bss:统称数据段,保存已初始化、未初始化的全局和静态变量,所以全局变量和静态变量都是在程序结束后才销毁,因为有专门存放的区域。局部静态变量也是存放在这里。heap:堆内存,存放的是运行时动态分配的内存,比如用 malloc 函数申请的内存块就是保存在堆中stack:C函数运行使用的内存,用于放局部变量、函数的返回地址。shared libs这是共享内存部分,共享函数库,mmap 内存到文件的映射用的就是这块,位于堆和栈内存的中间
注意:
heap 堆分配内存是从下往上分配,从低地址开始stack 方向是反过来的
结合代码来看看:
int a = 100;
void f(int b,int c){
int* p = malloc(100);
}
void g(int d){
f(d,d+1);
}
int main(){
static int e = 10;
}
复制代码
a是全局变量,保存在 data 里p是malloc函数分配的内存块,保存在 heap 里main(), d, g(), b, c, p, f()是函数运行时产生的,依次放入stack,当执行完之后,倒序从stack中退出。stack中存放的都是地址,包括局部变量,函数的地址。e是静态变量,保存在 data 里
大家可以对比 java 的内存模型看看,其实很像的,java 就是用自己的方式跑的C
3. PCB 进程控制块
每个进程都有自己的状态,这部分也是有专门的内存块来保存的,这块内存就叫做:PCB,结构如下:
也就是每个进程都有一个相对应的PCB. PCB不包含任何可执行的代码,全都是和control相关的信息
PCB 进程控制块很重要的,要理解的,后面马上就用到,PCB+运行实体组成进程的上下文 ,PCB下面的部分称为运行实体
其实进程上下文在物理内存中离散的放着,目的是避免连续存放对空间管理带来的问题。离散存放带来的问题是需要一个table帮你把所有内容找回来。
再加一点,PCB 在 Linux 系统用是 task_struct 这个属性,看代码的时候要能反应过来,task_struct 描述的是进程的数据结构
mm:描述进程的内存资源fs:描述文件系统资源,就是本进程的代码在磁盘哪里filel:进程运行过程中打开了哪些文件signal:信号处理函数
PID 的数量,进程的个数不是无限支持的,32位系统中最多支持 32768个进程,文件在:cat/proc/sys/kernel/pif_max里
进程的状态
进程状态有2种说法:5状态、7状态,这里先说5的,理解了之后再说7的,7的就是在5上细分出来的
1. 进程5状态:
大家千万别和线程的装唉搞混了,虽然看着很像啊
- 一个新的进程刚刚创建时,就是 new 的状态,此时需要等待系统分配资源
- 系统分配完资源,此时进程就进入了 ready 就绪状态,此时进程等待分配 CPU 资源。
- 进程运行后就是 running
- 进程自然结束就是 terminated 结束状态
- 需要细说的自然就是 waiting 等待状态了,此时进程在等待某些事件(中断)的结束。一个 running 状态的进程在没有抢到新的 CPU 时间片之后就会进入 ready 就绪状态,等待系统重新调度。running 状态的进程在发出中断信号之后会进入 waiting 的等待状态,等该中断执行完成后会回到 ready 就读状态等待系统重新调度。waiting状态不具备运行条件。
2. 进程7状态
- 图中内有 new 和 ternimated 状态
- Linux 中 running 和 ready 统称 running,但是我们还是要知道其实是2个的,在代码上看成一个罢了
暂停状态:就是字面意思,该进程被暂停了,而不是 waiting 去了,暂停状态下只有我们再次唤醒进程才能继续运行僵尸状态:进程死了,但是还留有一具尸体,只有父进程主动使用 wait方法回收尸体,进程尸体才会消失,否则进程尸体一直就在,kill 9 也杀不没。僵尸状态的进程所有资源都释放了,只有进程的PCB task_struct 还留存,其目的是告诉父进程子进程死亡的原因。创建进程时传进去的 state,父进程可以通过这个参数拿到子进程死亡的原因。再说一次僵尸状态资源都已经释放了,是系统主动释放的,绝对不会存在内存泄露的问题哈深度随眠:一般系统调用都是深度睡眠,只有进程在 waiting 的那个中断信号完事了,进程才能重回 ready 去排队执行浅度睡眠:任何信号都能唤醒 waiting 的进程,一般驱动程序都用的是浅睡眠
睡眠可以看成一种阻塞,结合后面进程调度的内容,不同状态,睡眠的进程都有自己的 warting 队列
看图,说的就是僵尸状态 state 的使用 ->
3. 进程状态码
R:TASK_RUNNING,可执行状态S:TASK_INTERRUPTIBLE,浅睡眠状态D:TASK_UNINTERRUPTIBLE,深度睡眠状态T:TASK_STOPPED or TASK_TRACED,暂停状态Z:TASK_DEAD - EXIT_ZOMBIE,僵尸状态X:TASK_DEAD - EXIT_DEAD,退出状态,即将被销毁
4. 子进程被杀死后,我们说进程会变成僵尸进程,但后等待父进程回收,怎么理解呢?
进程被杀死后其实4G用户空间中,高位的内核态部分并没有被回收,依然残留有一些关键信息,比如 PCB 依然还存在没有被回收
父进程可以拿到进程的残留的 PCB,可以知道子进程的死因等一系列信息,父进程回收子进程是指父进程把子进程高位内核态地址全部回收,此时 PCB 会被销毁
进程切换的概念
并发进程的切换:并发过程中一个进程在执行过程中可能被另一个进程替换占有cpu,这个过程乘坐进程切换。
什么叫进程切换,就是进程是去了 CPU。这里大家先不考虑同一个进程内多线程的状况,这个后面到线程时再说。造成线程切换的唯一原因就是中断了
中断就是一个信号,每个中断源都有编号,内核在接受到中断后,会看看中断号,就能找到对应需要执行的任务,根据不同的中断源来选择handle处理。内核中有一个中断向量表,存的就是中断的对应任务,外部硬件的中断都是依赖驱动程序注册到系统内核中的,要不系统怎么知道你这个硬件要干啥啊
中断是用户态向内核态转换的唯一途径。系统调用就是中断的一个例子,中断更加广泛。
OS提供Load PSW指令装载用户进程返回用户状态
中断是用户态和内核态之间切换的唯一原因
中断是指程序执行过程中,当发生一个事件时,会立即终止在CPU上执行的进程,然后马上执行这个事件对应的任务,该任务结束后再恢复这个进程继续执行程序
中断类型
内部中断:来自 CPU 内部的中断,指令执行过程中发生的中断,属于同步中断。注意使用的单词时:Exception,系统异常其实都是一个个事件,这和 error 是不同的,是系统在运行过程中自己发出的事件,中断来源:- 键盘,IO 设备等外部硬件,这些硬件在操作时都会产生一个硬件中断信号
- 硬件异常:掉电,奇偶校验错误等
- 程序异常:非法操作,地址越界,断点,除数为0
- 系统调用
外部中断:来自 CPU 外部的中断信号。这个又叫:硬件中断,注意单次是:interrupt,中断来源:- 如时钟中断,键盘中断,外围设备中断
- 外部中断都是异步中断(所谓异步,就是随机),因为这些中断谁也不知道会执行多久,我也需要等待结果,所以没需要等着
软件中断:由软件程序发出来的中断,前面2个都是硬件设备发出的中断信号,但是软件同样也有这样的需求- 软件中断只有一个中断号:
0x80,这就是常说的80中断,具体解释后面有
- 软件中断只有一个中断号:
内部中断也叫等待资源,外部中断也叫等待信号,有的地方说进程队列中等资源、等信号啥的大家要能反应过来,也许这样说不怎么正确,但是请这么理解。大家想啊,CPU 以外的硬件不就是系统的硬件资源嘛,这样想具理解了
进程离开CPU
内部事件:进程主动放弃(yield)CPU,进入等待/终止状态-
使用键盘,IO 设备等外部硬件,这些硬件在操作时都会产生一个硬件中断信号
-
(非)正常结束
-
外部事件:进程被动放弃,进程被剥夺CPU使用权,进入就绪状态,这个动作叫做抢占(preempt)- CPU 时间片到期
- 更高优先级的进程操作
进程调度
大家回忆上上面说的系统内核,内核中的一个功能模块就是进程管理,所以对进程的任何变化都必须在内核态中执行,也就是说操作进程的指令都是 ring0 级别的
内核进程管理模块使用队列来管理进程,也就是操作系统管理进程,用的是队列。不同状态的进程分别在不同的队列中排队,每个中断源都有自己专属的进程排队队列,比如进程A和进程B都因为要操作IO设备而触发了IO中断信号,在IO处理完之前,A和B都淂在IO中断队列里排队,看下图,比较形象了
在链表中,没有把进程所有的内容连在一起,仅仅链接了PCB,因为如果把所有东西链接在一起,开销很大。PCB体量很小,而且读PCB是可以从内存中找到进程的实体的。
具体A和B用户态到内核态的切换过程大家再去上面系统调用哪里看看,每个系统调用都会发出对应的中断信号的 Ψ( ̄∀ ̄)Ψ
大家不好奇队列里存的时什么吗,不卖关子,队列里存的是进程的 PCB,通过 PCB 就能代表一个进程了,就能找到一个进程的位置,内存数据,所以没必要把进程所有数据都装进来
进程在排队结束后不一定会按照进入的顺序再获取 CPU 资源执行自己的任务,具体的要看操作系统采用哪种进程调度策略,抢占式大家都熟悉吧,完事了有资格的进程去抢CPU时间片
PCB内存的作用再看下图:
进程切换
再次重申一遍,中断是用户态和内核态之间切换的唯一原因。先不考虑多线程的问题,这个之后说
进程的切换是进程丢失 CPU 再获取 CPU 的过程,也是从用户态切换到内核态,再从内核态切换回用户态的过程,这个过程值得仔细看看
还记得上面说的进程上下文吗,回忆一下,还有 PCB 这里就用到了
切换时机:-
进程需要进入等待状态(主动放弃,例如启用IO)
-
进程被抢占CPU而进入就绪状态(被动放弃,例如时间片到期,来了一个优先级更高的线程)
-
切换过程:-
将cpu从用户态切换到内核态
-
保存被中断进程的上下文信息(context)
-
修改被中断进程的控制信息(状态等)
-
将被中断的进程加入相应的状态队列
-
调度一个新的进程并恢复他的上下文信息
-
啊,又是上下文切换,线程切换有上下文切换,进程切换也有上下文切换,进程的上下文就是 PCB+用户态内存。进程保存在主内存中,获得CPU执行任务要把相应的方法和数据写入CPU缓存中的,当中断信号来了,不管是主动的还是被动的,都淂让出CPU给别的进程使用,这时候我们要保存进程当前执行的位置、数据、线程,以实现之后抢到CPU再回到现在的点继续执行任务
注意这5个过程都是在内核态中执行的,进程上下文的保存和切换都是在内核态由内核代码执行的。操作系统由一个 load PSW 指令就是专门恢复进程现场的,重新加载进程上下文
这个过程不是一瞬间就完成的,也是耗时的,进程要是老是切来切去的,一样会浪费大量性能,所以减少进程的切换也是一个优化性能的重点
fork() 函数
fork 函数是创建子进程的,这里强调这个函数是因为对于后面学习非常有意思
PCB 里有2个参数 ->
PID:进程IDPPID:父进程ID
PID = fork(); fork 函数是有返回值的,返回的是子进程的PID ->
-1:子进程创建失败0:创建出来的子进程还没有子进程,所以这个数是0非0:这个就是子进程的PID了
通过这个方法我们一般可以确定进程的父子关系
fork 函数的特点:新创建一个子进程,把父进程的所有数据完完全全的拷贝一份放到子进程内存中,父进程 fork() 之后的代码,父进程和子进程都会执行一边,也就是执行两边。父进程的内存和子进程的内存相互独立,互不关联,也就是父进程对变量的修改不影响子进程的变量。
看到 fork 这里大家惊讶不惊讶,会把进程的内存打包复制一份给子进程,做 android 的朋友们注意来,android 是大量用到 fork 了的,明白 fork 对于理解 android 很重要的
main{
int* a = 1;
fork();
printf("AA")
}
复制代码
就这段代码,fork 之后生成的子进程会继续执行 fork() 之后的代码,结合到这里就是 AA 打印了2次
好处:得到了2个执行流(并发的)
坏处:资源浪费
wait() 函数
main{
int* a = 1;
int* PID = fork();
wait(PID);
printf("AA")
}
复制代码
上面代码加上一个 wait() 函数,wait 和 java 里的一样,其实应该说 java 的 wait 就是用的 C 的 wait,加上 wait 之后父进程会等待子进程执行完成后再执行自己,这个就是一个深度睡眠了,父进程在 wait 这个调度队列里一直等着,等着 wait 这个特定的中断完成再把自己调度回 ready 队列
孤儿进程问题
父进程里面启动了一个子进程,然后这2个进程并发执行,系统会倾向于先执行父进程,当然也可以设置倾向于执行子进程,这样就有一个问题,要是在子进程执行完之前,父进程先结束了,那么子进程的 PPID 就有问题了
Linux 里面进程都是父子关系的,进程不能没有爹,你爹要是挂了,系统回再给你动态的找个爹 ┗|`O′|┛ 嗷~~ ,这样 PPID 也会跟着变
- 当有 subreaper 进程时,系统把把离你最近的 subreaper 进程当成你新的爹
- 当没有 subreaper 进程时,系统会把你托管给系统最初的进程 SYSTEM,这个进程的 PID 是 1
copy on wirte
copy on wirte 说的就是 fork 子进程的事,我们说了 fork 出来的子线程把父进程的所有数据的都拷贝饿了一份,进程调度队列中存的是什么,是 PCB 啊,PCB 就可以表示一个进程,fork 的过程就是复制了 P1 的 PCB 给 P2,此时 P1 和 P2 的 PCB 是完全一样啊,看 PCB 图:
系统会复制 P1 DE PCB 给 P2,mm 段表示内存,那此时 P1 P2 的内存地址都是一样的,那么操作都是相同的数据了,copy on wirte 发挥作用的就在这里
子进程创建出来后,使用的还是父进程的页表,不过系统会把父进程页表改成 RD-ONLY (只读)的,当子进程修改数据时,系统看到 RD-ONLY 会触发缺页中断,把新的页分配给子进程,把父进程的数据 copy 一份给子进程。虽然父子进程之间的虚拟内存页表地址都一样,但是指向的却是不同的物理地址,新的内存页就有写权限了
fork 内部使用的是 clone(),clone 这个函数,这个函数非常灵活,可以选择把 PCB 的哪些数据段复制给 P2,哪些数据端共享
总结下:P1 把 task_struct 对拷一份给 P2,一开始是一样的,但是只要 P2 改了就变了,P2 是在自己的那份上改的,内存最难对拷,只要 P2 修改资源了,就重新分配内存页给 P2,那P2就是自己的一份了,谁先写谁得到新的物理内存地址,父进程先写,那父进程就获得新的物理内存地址
vfork() 函数
vfork() 函数使用 clone() 函数,PCB 其他的数据段都复制一份,mm 内存段则共享,这样一来子进程操作的就是父进程的数据了
fork 的点到这利就差不多了,知道怎么回事就行,又不是做 Linux 开发的,没必要深究~
还有一点,没有 MMU 单元的 CPU,没法使用 fork() 函数
进程中主次线程的问题
main{
......
}
复制代码
Linux 进程中默认都会有一个主线程,这个线程不用大家自己去new,系统在创建进程时一块iu创建出来了,这个线程就是主线程,看见main函数就代表主线程了。
再创建的其他线程都叫子线程,有个特点一定要知道:一旦进程中的主线程结束了,不管这个进程还有多少子线程,这些子线程是不是还在执行任务,这些子线程都会跟着你一块结束。也就是说进程中主线程的结束代表这进程的死亡,所以进程的主线程一般都是设计成循环遍历的,空闲时会阻塞
android MainThread 里的 main 函数熟悉不熟悉,Linux 这块你没学过,你能理解到精髓码,你能真的看得懂吗,多半都是猜吧,猜就不免会有疑惑、顾虑,这就不叫学明白,大家要清楚这点
线程
什么是线程
线程大家耳熟能详了吧,不过多说概念了,Linux 中线程是基本的调度单位,面试说这个就行了
每个进程都有自己的主线程,在进程创建时系统默认就会把主线程创建出来,再创建的线程都是子线程,对于进程来说,线程就是进程内的多个执行流
线程共享进程数据、资源,PCB 进程控制块可以找到进程所有的资源,PCB 就可以代表一个进程,对于线程来说既然我们要共享继承的资源,我们怎么做最简单,把 PCB 复制一份就行了,寄存器的值就存线程自己的就行了。复制出来的 PCB 可以作为线程的控制单元,改名叫:TCB
线程私有的资源也就是线程栈和寄存器临时数值了,线程栈在用户内存中,寄存器临时数值在内核空间中,PCB 也是在内存中,也就是说复制一份 PCB 出来,生成 TCB,TCB 的 registers 重置一下就行了,PCB 和 TCB 在 Linux 中都是 task_sturct 结构体
代码上复制 PCB 最方便的方式就是 clone() 函数了,clone() 函数必会复制一份 PCB 出来,Linux 创建进程的函数 pthread_create() 用的就是 clone() 函数
TCB 中的数据基本都是复制了一份 PCB,但是注意啊,mm 是和 PCB 共享的,也就是用的是同一份数据,而没有选择复制,TCB 之间 mm 也会是用的同一份,看图:
线程创建模式
其实我们所说的线程指的是 用户线程,也就是这个线程是运行在用户空间中的,但是我们要是需要访问硬件资源怎么办,必须要切换到系统内核也就是内核空间中啊,系统提供了对应的 内核线程 这个东西,下面我们说的线程创建模式就是用户线程和内核线程的相互关系
1. M:1 多对一模型
多个用户线程对应一个内核线程: 要是哪个用户线程耗时太长,那别的用户线程就别想执行了,这显然是不行的,所以也没有操作系统采用这种线程模式
优点:逻辑上的多个执行流
缺点:实际上并不是并行,是并发
2. M:M 多对多模型
多个用户线程对应一个内核线程,几个对几个就不固定了: 一对一和多对一的中合体,目前也没有操作系统用这个线程模型
优点:KLT数量不等于core的数量,节省了内核开销。
缺点:实现起来复杂
3. 1:1 一对一模型
有1个用户线程就有1个内核线程: 性能和复杂度的中和,目前基本用的都是这个线程模型
优点:真正的并行+并发
缺点:内核开销很大,时间和空间开销都很大
线程库
Thread Library 是为程序眼创建、管理用户线程服务的,不同操作系统有不同的线程库
POSIX Pthreads:这是 linux 的线程库 API,可以创建出用户线程和内核线程Windows Threads:win 平台的java Threads:java 因为要跨平台嘛,所以具体要看目标的操作系统了
PID/TID
PID:进程的ID,其实就是线程所属进程的 PCB 号TID:线程自己的 TCD ID 号
getpid() 函数获取 PID,gettid() 函数获取 TID
内核调度器
内核调度的是什么,就是CPU啊,内核调度器决定哪个任务执行,哪个任务排队,不管是单核心,还是多核心都是依靠内核调度器来调度计算任务的
内核调度的是什么
还记得面试时我们对于线程的回答吗:线程是系统调度的基本单元,这里展开一下
对于内核调度器来说,没有什么进程线程的概念,只有 task_sturct,也就是 PCB、TCB 这东西,内核调度器遇到 task_sturct 就可以去调度
TCB 我们知道它代表资源,那怎么理解 PCB,它可是代表的进程啊,最小调度单元不是线程嘛,干 PCB 什么事。大家还记得不,Linux 进程一创建,系统会马上创建给进程创建出一个默认的线程出来,这个线程就是主线程,主线程有 TCB 吗,没有,PCB 就是 Linux 进程主线程的 TCB,也许这么解释不是很正确,但是我觉得这么理解就行了
所以上面讲的进程切换的东西在这里都适用~
内核调度带来的性能损失
涉及到的几个方面:
cpu 指令切换上下文切换进程切换cache miss
CPU性能损失 -> Linux 采用了2种机器指令权限范围,ring0,内核态可以使用,ring3 用户态可以使用。CPU 有自己的指令缓存寄存器、高速缓存的,平时都会缓存你这个操作级别对应的及其指令的,任何用户态和内核态的切换都会造成指令寄存器和缓存的无效,要重新加载,这里有一点性能损失
上下文切换性能损失 -> 用户线程运行在用户空间,内核线程运行内核空间,线程的切换必要要在内核中进行,这样不光用户线程切换带来性能损失,内核线程切换一样会带来性能损失。线程有自己数据,在内核调度器中就是 PCB、TCB,这些数据是要加载到 CPU 缓存中的,CPU 一切换任务,这些数据都要离开 CPU 缓存,把新线程的数据加载进来
进程切换 -> 你 CPU 前后切换的线程要是分属不同进程,那会还会造成进程切换,上下文切换的范围更大,CPU 缓存内进程的页目录要切换,TLB 缓存会失效
cache miss性能损失 -> cache miss 是什么,是缓存命中无效啊。为了减少 CPU 等待内存读取数据的等待时间,有个缓存命中的技术,会有把相关的数据都加载进来,有时候一整页 4K 的数据都会加载进来,L3、L2、L1 都会有,你一切换线程,这些为了缓存命中加载家来的数据都无效了,这叫缓存命中无效或丢失,还得重新加载一次
你的线程要是没事切来切去,这些性能损失也不小了,一般会占 CPU 时间片的 1% 甚至更高
抢占调度
非抢占调度:一旦某个进程得到cpu,就会一直占用到终止或等待状态,除非主动放弃cpu抢占调度:不是非抢占调度就是抢占调度
内核调度准则
这里我先说一个参数和2种任务类型 ->
响应时间:从提交任务到第一次响应的时间CPU 密集型任务:像学科计算这种需要占用很多 CPU 时间的任务IO 密集型任务:像访问资源这种不怎么需要占用 CPU 时间,但是需要大量等待访问资源时间的任务
这3个东西是放在一起说的,比如像鼠标操作,他是不占 CPU 时间的,需要的就是操作系统及时反应我们按键盘就行了,要是响应时间太长了,那就是卡顿了,像有大量用户交互的系统,响应时间是最重要的指标
那磁盘操作这种 IO 任务,也需要及时响应,及时去放访问资源就行了,然后我等着呗,这个过程中可以释放对 CPU 资源的占用
要是大家都排队执行的话,一个 IO 型任务长时间占用 CPU 但是不用,这对 cpu 型任何是没法接收的。要是按照谁快谁来这样排队的话,那 IO 任务永远没有执行的机会了
所以 ARM 平台针对这2种类型的任务,专门推出了 big.LITTLE 型 CPU 架构,说白了就是大小核设计,大核计算能强,小核功耗小。系统会把 CPU 型任务度放到大核中执行,系统会把 IO 型任务放到小核中执行
这种针对任务类型设计的 CPU 架构需要系统架构同步的去这样设计,效果就是实现用 4个核心的功耗实现7个核心的计算能力,这样带来的成本压缩、功耗下降对于移动平台来说至关重要
android RXjava,kotlin 的线程都设计有 cpu密集型任务线程池和 IO密集型线程池,也是为了响应硬件上的设计思路,所以大家看看国外程序眼的眼界多高,代码都可以迎合硬件架构思路做优化,这个点太 NB 了,我太佩服了
内核调度策略
cpu利用率:cpu的忙碌程度响应时间:从提交任务到第一次响应的时间(针对交互式系统)等待时间:进程积累在就绪队列中等待的时间周转时间:从提交到完成的时间吞吐率:每个时钟单位处理的任务数(越高越好,但是不能无限高,但是对响应时间和等待时间造成影响)公平性:以合理的方式让各个进程共享cpu
调度算法
1. FCFS/FIFO 先来先服务
说白了就是排队,排在前面的先执行,排在后面的后执行,只有前面的执行完了,后面的才能执行,不能插队 。非抢占式,调整次序可能带来更好的效果
优点:简单易行,公平算法
缺点:问题也很明显,前面的执行太慢,后面的任务响应时间就没法预测了,对于鼠标键盘来说, 这种策略是不能接受的。当你只买一瓶矿泉水却在付款队伍最后的时候,你作何感想?
2. RR 时间片轮转
这个大家就熟悉了,限定每次 CPU 执行的时间,大家还是按照顺序排队,CPU 时间用完了就换下一个,然后自己到队尾接着排队
抢占式调度算法
RR并不是一定比FCFS优秀
时间片选取
- 取值太小:进程切换开销显著增大(不能小于进程切换的时间)
- 取值较大:响应速度下降(取值无穷大将退化成FCFS)
- 一般时间片的取值范围为10ms-100ms 之间
- 上下文切换的时间大概为0.1ms-1ms(1%的CPU时间开销)
RR算法优缺点
-
公平算法
-
对长作业带来额外的切换开销
-
对于键盘鼠标还是不能接受,键盘鼠标要是长时间连着操作,不能一会一卡。
3. SJF 最短作业优先
这个就是预判谁的任务执行时间最短,谁就执行,然后比较下一个
思路优化了响应时间,难以预测job占用cpu时间,不公平算法,长进程可能长时间无法获得cpu。
现在也没有成熟的算法,无法实现。所以这个目前也是没人用,但这是目前研究的一个方向,现在的成果是:记录线程之前平均运行时长来作为参考
4. PRIORITY 优先级调度
- 优先级高的先执行,优先级相同的时候,可以采用FCFS。Linux为例,0为最高优先级
- SJF是优先级调度的一个特例,越短优先级越高
- 优先级调度算法可以是抢占式,也可以是非抢占式的
- 动态优先级:进程占用CPU时间越长,优先级越低。进程等待cpu时间,等待时间越长,优先级越高
- 静态优先级:优先级保持不变,但会出现不公平现象
5. SCS/PCS
SCS/PCS 是简写,是2种线程调度模式
SCS:PTHREAD_SCOPE_SYSTEM,所有的可以公平的去竞争所有 CPU
PCS:PTHREAD_SCOPE_PROCESS,进程先去竞争 CPU,然后该进程内部的线程再去竞争
linux 使用的 SCS 模式,Thread.scope 参数表示的就是这个,原因很简单,Linux 采用 1:1 线程模型,每个用户线程都有自己对应的内核线程,内核线程可以去抢 CPU
Linux 调度策略
Linux 中 把优先级值(priority_value)分成 [1-99],数字越大,优先级越高。Nice值在[-20, 19]中变化,数值越大,优先级越低。我们说数值越低,优先级越高,说的其实是PR值。下面说的任务和线程是一回事
Thread 里有个 Scheduling prlicy 参数,这个就是线程策略,Linux 系统根据线程要求响应的不同分成2大的调度策略(都是抢占式的):
-
Real-time Schduling:实时调度策略,一般内核线程都是这种调度策略,内部使用 FIFO+静态优先级的思路,每个优先级都有一个队列,优先级高的队列先执行,相同优先级的按照顺序排队运行。若是有个高优先级的来了,就得让给这个后来的优先级高的线程。所有的Nice值都是0. PR=-1 - priority_value,PR的范围是[-100,-2]。上述说的优先级指PR值。SCHED_FIFO默认是这个SCHED_RR
-
Normal Schduling一般任务,用户线程都是这个级别的,所有一般任务的priority value都是0,所有线程优先级值低于Real-time schduling的线程。使用 RR+动态优先级的思路,不过就不是优先级高的运行完了才能等到优先级低的,而是可以同时抢,区别是优先级高的运行时间长了,就把你优先级调低,优先级低的一定时间轮不到你,就把你的优先级往上调,这个幅度一般是 +-5。这样做的目的就是为了大家都能轮到执行,不会优先级低就等到最后。用到了Nice(友好值)和PR值。Nice在[-20, 19]中变化。在Norma Schduling中PR = 20+Nice,PR在[0, 39]。PR值越高,优先级越低。PR值和优先级成反比。我们说数值越低,优先级越高,说的其实是PR值。SCHED_OTHER默认是这个 其实就是分时调度(time-sharing policy)+动态优先级(RR)SCHED_IDLESCHED_BATCH
新版本的值范围是从[0,139], 数值越小,优先级越高。0-99 对应是 Real-time Schduling 实时线程,100-139 对应的 Normal Schduling 普通线程,Linux 早期,100是-20,139是19,0是-139,具体看你的 Linux 版本
对于100-139的普通线程来说,优先级高的线程对优先级低的线程不具有绝对的优势,100的线程比110的线程,就是执行时间更长,在从 wrating 到 ready 的时候,100的线程能抢到时间片
普通线程的优先级还有 Nice 这个参数,用来动态调节优先级的,nice 的取值范围:[-20,19],nice 越大优先级越小,nice 算是一个惩罚机制,你运行的时间太长了,把你 nice 值调大,你优先级就降低了,留出机会给其他线程
普通线程也是有 IO型任务的,IO型任务响应一定要快,Linux 系统本身就会照顾 IO 型的任务,所以就诞生了 nice 这个值,没有 nice,怎么实现照顾 IO型任务,尽量让 IO 型任务得到及时响应呀
RT 补丁包
后来 Linux 出了一个 RT 补丁包,可以设置实时线程一段时间内占用 CPU 时间的最大值,比如 1000 个时间片,通过 RT 可以设置实时任务最多占900个,剩下的留给普通任务。大家想啊,这个设计也是合理的,内核任务你要是跑起来没完没了,后面的普通任务,用户程序的任务怎么执行,不能一直都卡在那里吧,要不用户体验就糟糕死了
CFS
RT 补丁包了对于普通线程还添加了一个调度算法:CFS 完全公平调度策略,CFS 会计算出一个虚拟时间,谁的虚拟时间小,谁执行,采用红黑树的数据结构
计算公式:
累计运行时间/权重
权重和优先级转换:
在最求虚拟时间相等的前提下,权重越小,虚拟时间最大,想要虚拟时间小,就得累计运行时间长,也就是得到 CPU 时间片的机会更多
cgroup
cgroup 可以让我们给线程划分群组,可以让该群组运行在某个核心上,或者某几个核心上,或者该群组的线程优先级更高,获得 CPU 的机会更大
android 系统上分了2个群组:
apps:前台 appbg_non_interactive:背景非交互的,app 不再前台了都是这个apps:cpu.share = 1024bg_non_interactive:cpu.share = 52
数越大权重越高,获取 cpu 的机会越大,在前前台运行的 app 能够更大的抢到 CPU
查询步奏:
root@XXXX:/proc/6566 # ps | grep -i "video"adb shell进入已经root的Android设备终端,获得进程的pidadb shell cat proc/6566/cgroup
结果:
cpu:/(前台进程)cpu:/bg_non_interactive(后台非交互进程)
Synchronization
并发
在内存中同时存在的若干个进程/线程,有操作系统的调度程序采用适当的策略将他们调度至CPU上运行,同时维护他们的状态队列
-
多个并发进程/线程宏观上是同时运行
-
从微观上看,他们的运行过程是
走走停停 -
并发的进程/线程之间是
交替执行 -
注:不需要刻意区分并发进程和并发线程,他们都可以理解为运行的实体和调度的单位
并发进程之间的关系:独立关系和交互关系
独立关系:
- 并发进程分别在自己的变量集合上运行
- 例如Chrome进程和music进程
交互关系:
- 并发进程执行过程中需要交换数据
- 例如银行交易服务器上的receiver进程和handler进程
- 交互的并发进程之间有存在这
竞争和协作关系
异步产生的错误
异步:Asynchronous means RANDOM!!
会引发竞争条件(Race Condition):一种这样的情况:多个进程并发操作同一个数据导致执行结果依赖于特定的进程执行顺序。
同步
Synchronization Tool Kits:
Mutex lock 互斥锁(解决竞争关系)
Semaphore 信号量(解决协作关系) 信号量作用范围更广,可以完成互斥锁的功能
1. 临界区问题
Each concurrent process has a segment of code, called a critical section, in which the process may be changing common variables, updating a table, writing a file, and so on.
每个并发进程,都有一段可能修改公共数据,更新表格,写文件等等的代码,这段代码叫做临界区
The Important feature of the system is that, when one process is executing in its critical section, no other process is allowed to execute in its critical section. That is, No two processes are executing in their critical sections at the same time.
当一个进程在他的临界区正在执行的时候,其他进程都不能执行他的临界区。也就是不能有两个进程同时执行临界区的代码。
The critical-section problem is to design a protocol that the processes can use to cooperate.
进程进出临界区协议:1. 进入临界区在entry section要请求许可。 2. 离开临界区后在exit section要归还许可
临界区管理准则:有空让进 择一而入 无空等待 有限等待 让权等待
Mutual exclusion(Mutex):互斥Progress:前进Bounded waiting:有限等待
2. 喂养金鱼(软件方法解决临界区问题)
金鱼生存法则:每天喂一次,且仅一次。今天一个人喂了,另一个人就不能再喂。 今天一人没有喂过,另一人就必须喂。
Alice Tom
if(no feed){ if(no feed){
feed fish feed fish
} }临界区就是if这部分代码块
由于异步执行,所以线程是交替执行,所以可能鱼被撑死
Alice Tom
if(no node){ if(no node){
leave a node leave a node
if(no feed){ if(no feed){
feed fish feed fish
} }
remove node remove node
} }
临界区还是if(no feed)这部分
leave a node是entry section
remove a node是exit section
和上一个方案一样,鱼也有可能被撑死
Alice Tom
leave noteAlice leave noteTom
if(no nodeTom){ if(no nodeAlice){
if(no feed){ if(no feed){
feed fish feed fish
} }
remove nodeAlice remove nodeTom
} }
因为先贴纸条,所以两方可能都贴了纸条,两个人都没办法喂鱼,导致鱼被饿死。
这里的鱼就是计算机的资源,对于计算机来说,饿死的情况更安全,撑死会导致错误的结果。
Alice Tom
leave noteAlice leave noteTom
while(noteTom){
do nothing
}
if(no nodeTom){ if(no nodeAlice){
if(no feed){ if(no feed){
feed fish feed fish
} }
remove nodeAlice remove nodeTom
} }
这种情况下,鱼可以活下来
软件解决临界区的管理,需要较高的编程技巧,两个进程的实现代码是不对称的,当处理超过两个进程的时候,代码复杂度会变大。
两个著名的软件方案:peterson Dekker
3. 互斥锁 MUTEX LOCKS
基本操作:
- 上锁(分为等待锁至打开状态,获得锁并上锁。并且是不能被打断的,所以由操作系统提供)
- 解锁
- 原子操作(原语): 就是操作在运行过程中不可以被打断。上锁和解锁都是源自操作
test_and_set() 和 compare_and_swap()是原子操作
bool available = true;
lock(){
while(!ts(&available))
do nothing;
}
unlock(){
available = false;
}
bool ts(bool* target){
bool result = *target;
*target = true;
return result;
}
这种占用cpu执行空循环实现的等待成为忙式等待。
这种类型的互斥锁也被称为自旋锁(spin lock)
缺点:浪费cpu周期,可以将进程插入等待队列一让出cpu的使用权。
优点:进程在等待时没有上下文切换,对于使用锁的时间不长的进程(自旋的性能开销可能小于上下文切换所带来的开销),自旋锁还是可以接受的,在多处理系统中,自旋锁的又是更加明显。
4. 信号量
信号量(Sempaphore)是一种比互斥锁更强大的同步工具,他可以提供更高级的方法来同步并发操作。
信号量是一个整数,除了初始化的时候,只能通过两个标准的原子操作来访问。两种操作是p/v
p : wait() operation
v : signal() operation
P(s){
while(s<=0){
do nothing;
s--;
}
V(s){
s++;
}
5. 信号量的使用
Binary semaphore 二值信号量,而值信号量的值只能是0或1,通常将其初始化为1,用于实现互斥锁的功能。
semaphore mutex = 1
process pro{
P(mutex); = lock()
critical section
V(mutex); = unlock()
}
Counting Semaphore 一般信号量 一般信号量的取值可以是任意取值,用于控制并发进程对共享资源的访问
semaphore road = 2;
process Car{
P(road)
pass the fork
in the road.
V(road)
}
初始值是2,也就是说信号量后面的数量是2.两个线程可以pass the fork in the road.
第三个线程来了之后因为road值<0导致等待,当前两个占用资源的线程结束,修改road之后,则第三个线程可以得到资源
s = 1代表竞争 s > 1代表后面的数量 s=0用于进程同步
int ticketAmount = 2; //Global Var
sem_t mutex;//定义一个信号量
void* ticketAgent(void* arg){
sem_wait(&mutex); //P(mutex)
int t = ticketAmount;
if (t>0){
printf("one ticket sold!\n");
t--;
}else{
printf("ticket sold out!!\n")
}
ticketAmount = t;
sem_post(&mutex); //V(mutex)
pthread_exit(0);
}
int main(int argc, char const *argv[]){
pthread_t ticketAgent_tid[2];
sem_init(&mutex, 0, 1)//mutex = 1 初始化为1
for(int i = 0; i<2; ++i){
pthread_create(ticketAgent_tid+i, NULL, ticketAgent, NULL);
}
for(int i = 0; i<2; ++i){
pthread_join(ticketAgent_tid[i], NULL);
}
printf("The left ticket is %d\n", ticketAmount);
return 0;
}
6. 信号量实现同步
司机与售票员
- 司机:启动车辆;正常行车;到站停车
- 售票员:关车门;售票;开车门
规则:
- 司机要等车门关闭才能开车
- 售票员要等车停下才能开车门
- 同步问题:同步问题的实质将异步的并发进程按照某种顺序执行
- 解决同步的本质就是要找到并发进程的交互点,利用p操作的等待特点来调节进程的执行速度
- 通常初始值之为0的信号量可以让进程直接进行等待状态,直到另一个进程唤醒他。
所以 s=0用于进程同步
7. 经典同步问题
生产消费者问题:生产者消费者共用一个缓冲区,生产者不能忘“满”的缓冲区放产品,消费者不能从空的消费区取产品。
初始状态:buffer是空的
设置信号量(初始值empty设置为1,full设置为0)
对于生产者:初始状态empty=1, full = 0。当一个生产者生产出来东西,生产者执行p(empty)操作,empty=1,将货物放进buffer,empty变为0,执行V(full)操作,full变成1。 当另一个线程生产出来东西执行p(empty)操作,由于empty = 0,所以一直等待。
对于消费者:初始状态empty=1, full = 0。消费者一直执行P(full)操作,由于buffer中没有东西,所以full一直是0。当生产者将东西放入buffer后,full变为1,消费者可以拿走东西。当消费者拿走东西,消费者执行V(empty)操作,empty重新变成1,等待的线程可以把他的东西放进buffer,empty重新变成0.
如果改变buffer的容量大于1,例如5,则把empty的数值设置为5。
The bounded-buffer problem 有界缓冲区
下面这种情况会产生死锁,产生的原因是因为将临界区扩大了。把不必要的代码放入临界区可能产生死锁。互斥的锁和解锁,一定要紧紧挨着临界区。临界区越小越好。
- 不要随意扩大临界区
- empty和full的P、V操作不在同一进程(同步信号量)
- mutex的P、V操作在同一进程(互斥信号量)
苹果橘子问题(单缓冲,多生产者,多消费者,产品多类的问题)
桌子上有一只盘子,每次只能放入一只水果
爸爸专门向盘子中放苹果,妈妈专向盘子中放橘子
儿子专吃橘子,女儿专吃苹果
司机售票员问题
读者写者同步问题:
读者和写者是竞争关系,也就是同一个文件,不能同时读写,不能同时写,可以同时读
由于reader_count是所有的读者,都可以看到的值,所以红框内的内容也成了临界区,就需要另一个信号量来控制。所以添加信号量r_mutex.
理发师问题:如果有没有顾客,理发师就睡觉。如果顾客来了,看到理发师在睡觉,就唤醒,开始剪发。下一位顾客来了看到理发师在剪头发就在waiting chair上等着。如果顾客看到waiting chair已经满了,就走了
如果理发师超过一个,则把barber数量修改就好。
对应的计算机问题:理发师就是server,顾客就是client。服务器要接受连接,如果服务器只能接受一个连接,意味着就只有一个理发师,如果可以通知接受三个连接,也就是有三个理发师。当多个client访问server,server对每个client建立连接,如果超过最多服务的数量,则进入等待队列。
哲学家吃饭问题:必须拿到两个筷子才能吃饭。
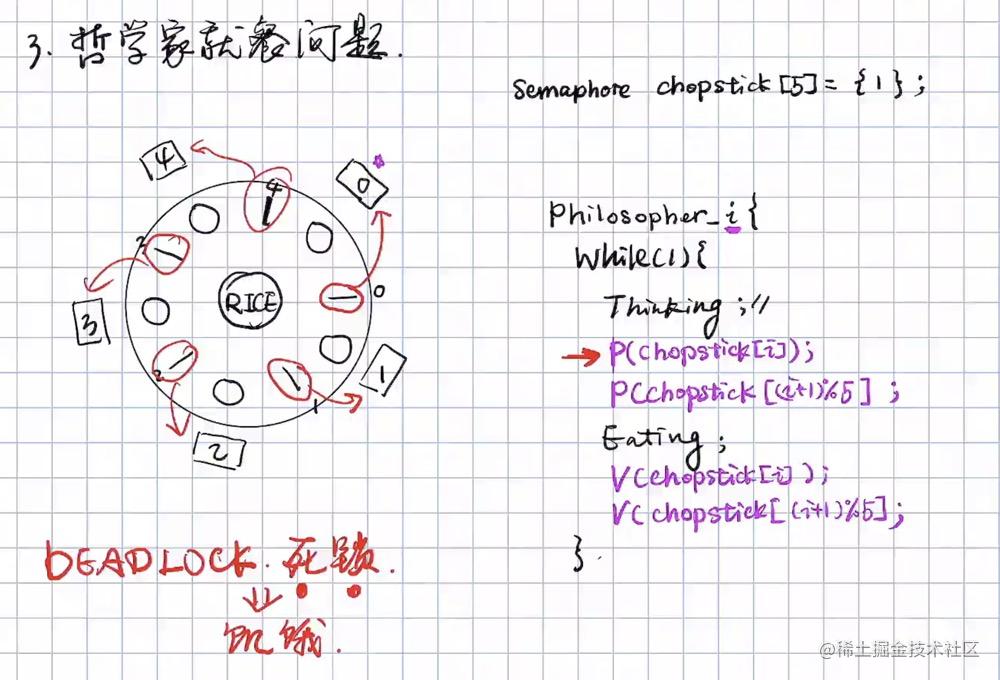
当所有哲学家拿到自己左手的筷子,都没办法进行吃饭,都不会放弃手中的筷子,所以就会发生死锁
死锁
1. 避免银行家问题发生死锁
- 最多允许四个哲学家同时吃
- 奇数号先取左手边的筷子,偶数边的先取右手边的筷子
- 每个哲学家取到手边的两根筷子才吃,否则一根也不取
饥饿:进程长时间等待。E.g 第优先级进程总是等待高优先级所占有的进程。
死锁:循环等待资源
死锁发生了一定会产生饥饿现象,反之不然
死锁产生的必要条件(死锁发生,四个条件都成立):
- 互斥使用:一个资源仅能被一个进程占有
- 不可剥夺:除了资源占有进程主动释放,其他进程都不可抢夺其资源
- 占有和等待:一个进程请求资源得不到满足等待时,不释放以占有资源
- 循环等待:每个进程分别等待他前一个进程所占的资源
死锁解决方案:
- 死锁的防止:破坏四个必要条件之一(可操作性太复杂)
- 死锁避免:允许四个必要条件同时存在,在并发进程中作出妥善安排避免死锁发生
- 死锁的检测和恢复:匀速死锁的发生,系统及时地检测死锁并解除它
破坏死锁任一必要条件:
-
互斥使用:允许资源共享使用。所以互斥条件不能被破坏
-
不可剥夺:资源可以被抢夺。所以不可剥夺不能被破坏
-
占有和等待:在进程运行启动的开始,把所有需要的资源都申请到。就可以破坏占有和等待,也就是资源,要不全有,要不全没有。会造成资源浪费。
-
循环等待:把所有资源编号,从R1 到 Rn。如果p申请Ri资源,那么p必须同时占有R1......Ri-1。就会破坏循环等待
所以破坏死锁任一必要条件,操作太复杂,可操作性太差。
安全状态:如果系统是安全的,系统就可以按照特定的顺序给每个进程安排资源,同时可以避免死锁。系统是安全状态如果存在安全序列。如果不存在安全序列,这个系统状态是不安全的
死锁的避免 系统对进程的每一次资源申请都进行详细的计算,根据结果决定是分配资源还是让其等待,如果确保系统始终处于安全状态,避免死锁的发生
2. 银行家算法
- 已知系统中所有资源的种类和数量
- 一直进程所需的各类最远最大需求量
- 该算法可以进行计算出当前系统状态是否安全(寻找安全序列)
优缺点:
- 优点:允许死锁必要条件同时存在
- 缺点:缺乏使用价值。进程运行前就要求知道其所需要的最大数量,要求进程是无关的,若考虑同步情况,可能会打乱安全序列。要求进入系统的进程个数和资源数固定。
3. 死锁的检测与恢复
允许死锁发生,操作系统不断监视系统进展情况,判断死锁是否发生
一旦死锁发生则采取专门的措施,解除死锁并以最小的代价恢复操作系统运行
死锁的检测的时机:
-
当进程等待是检测死锁(系统开销大)
-
定是检测
-
系统资源利用率家将是检测死锁
