

麻烦路过的小伙伴点赞、关注,共同学习成长!
本人csdn博客:blog.csdn.net/Sun_ltyy
提升内存池的分配效率,和cpu缓存一样都是比较底层的性能优化方法。在现在分布式集群应用的情况下,如果能从底层出发,很小粒度的性能提升,在分布式环境多集群的规模放大下,都将带来成倍的性能优化提升
下面带大家一步步了解内存池相关的知识。
一、应用请求分配内存的流程
-
应用代码申请内存时,先在应用内存池内申请,如果有足够可用空间直接返回,否则从C库内存池中申请内存资源,当C库内存池没有足够的内存空间时,才会从OS申请内存资源。
-
当应用向C库内存池申请1kb的内存空间时,C库内存池并不只申请1kb大小的内存空间,而是预先分配几百k的内存资源,当应用在申请内存时,直接从内存池中返回即可,提升内存分配的效率。
二、常用的C库内存池
目前有两种C库内存池分配器
ptMalloc(这也是linux系统默认的c库内存池分配策略)和tcMalloc(thread cache内存分配策略)
不同的设计思想
ptMaclloc是内存池共享的方式,他认为一个线程分申请了一部分内存空间,其他线程也可能会申请同样的内存空间,因此他采用的策略是多线程内存共享的方式,为了解决多线程共享数据安全问题,因此必须要枷锁,在多线程的并发争用的情况下,枷锁带来的成本比较高,但是内存的利用率就比较高;相反tcMalloc是每个线程单独维护、释放自己线程的内存资源,避免了读线程征用的情况,但是内存的利用率不高。
三、如何结合业务选型选择适用的C库内存池
ptMalloc和tcMalloc的分配效率 可以参考链接:goog-perftools.sourceforge.net/doc/tcmallo…
同样并发线程情况下,不同内存大小空间申请时,每CPU时钟能处理的操作数(百万单位)
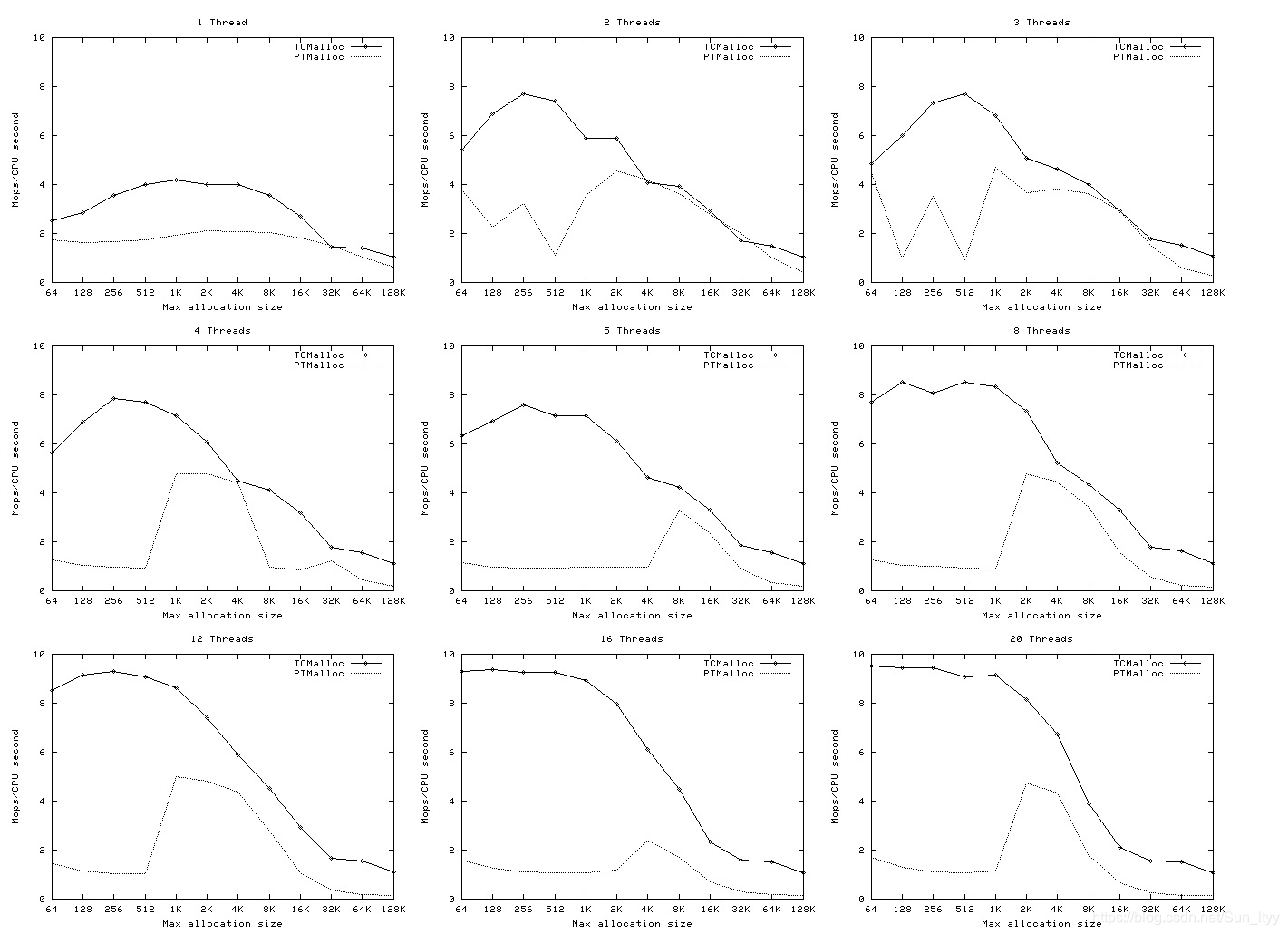
相同内存申请大小前提下,不同线程并发数,每CPU时钟执行操作数据(百万单位)
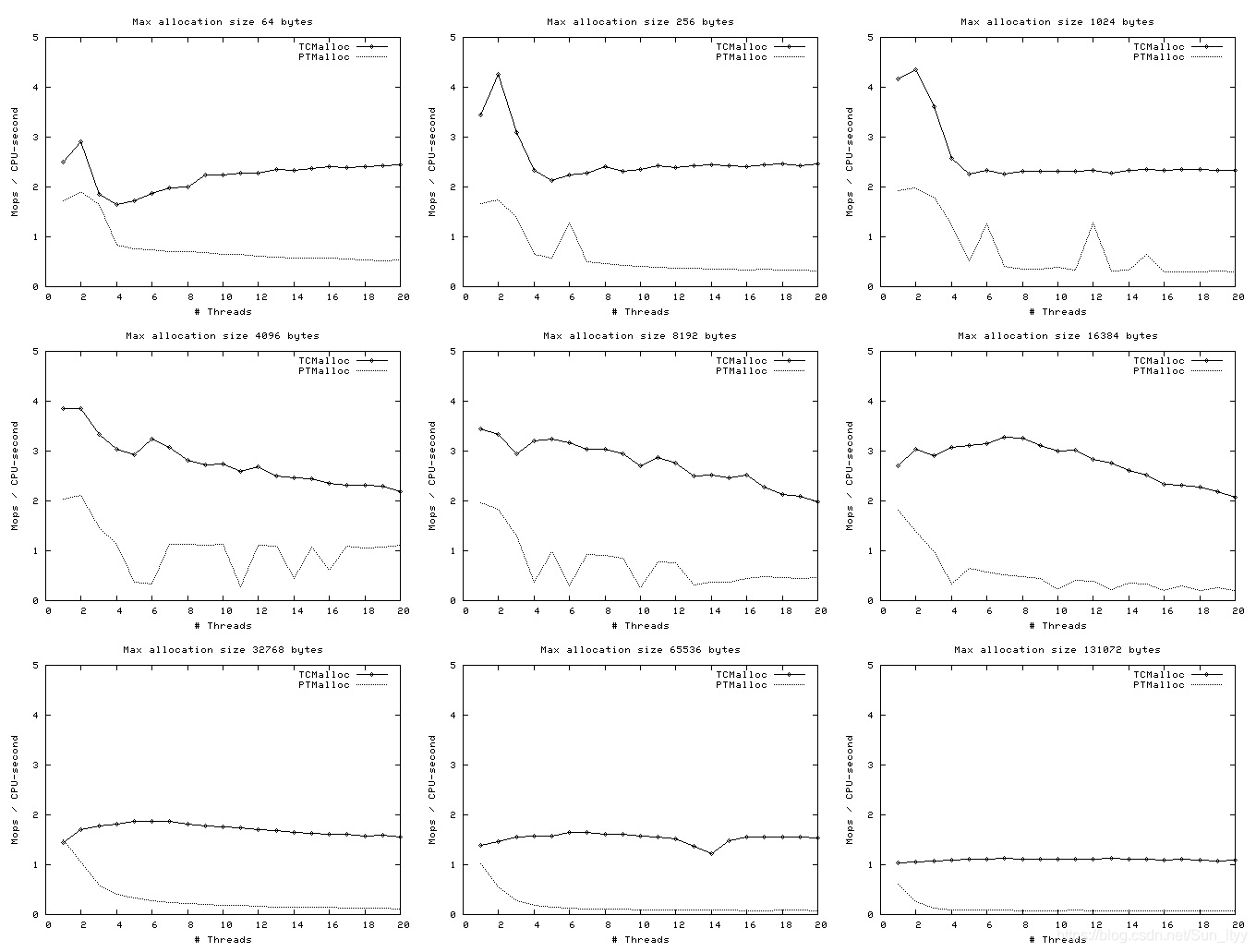
性能结论
-
首先把所需分配的内存大小做下三类分档
-
小内存:128k
-
中内存:介于128和1M之间
-
大内存:大于1M
-
-
在处理小内存分配时,在单线程还是多线程并发情况下,tcMalloc都是要优于ptMalloc的
-
图中分配的内存都是在128K为节点的,小于256K是同样的指标。当分配内存为中大内存时,ptMalloc是要优于tcMalloc的
选型/应用场景
设计理念的不同,也就决定了他们适合不同的场景。由以上的性能结论分析,如果我们的应用程序每次申请内存空间为小内存时,推荐适用tcMalloc内存池分配策略。相反推荐适用ptMalloc。
c库内存池在java中,使用堆外内存时,才会使用到,常见的jdk中directBuffer,一般使用的不多,往往使用在网络传输,IO文件读写时,堆外内存可以节省一次对象内存复制的过程。其他应用程序比如数据库、nginx等就可以根据内存使用情况,合理选择内存分配池。
