前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python开发环境
-
python 3.6
-
pycharm
import requests
pip install requests
12
目标网页分析
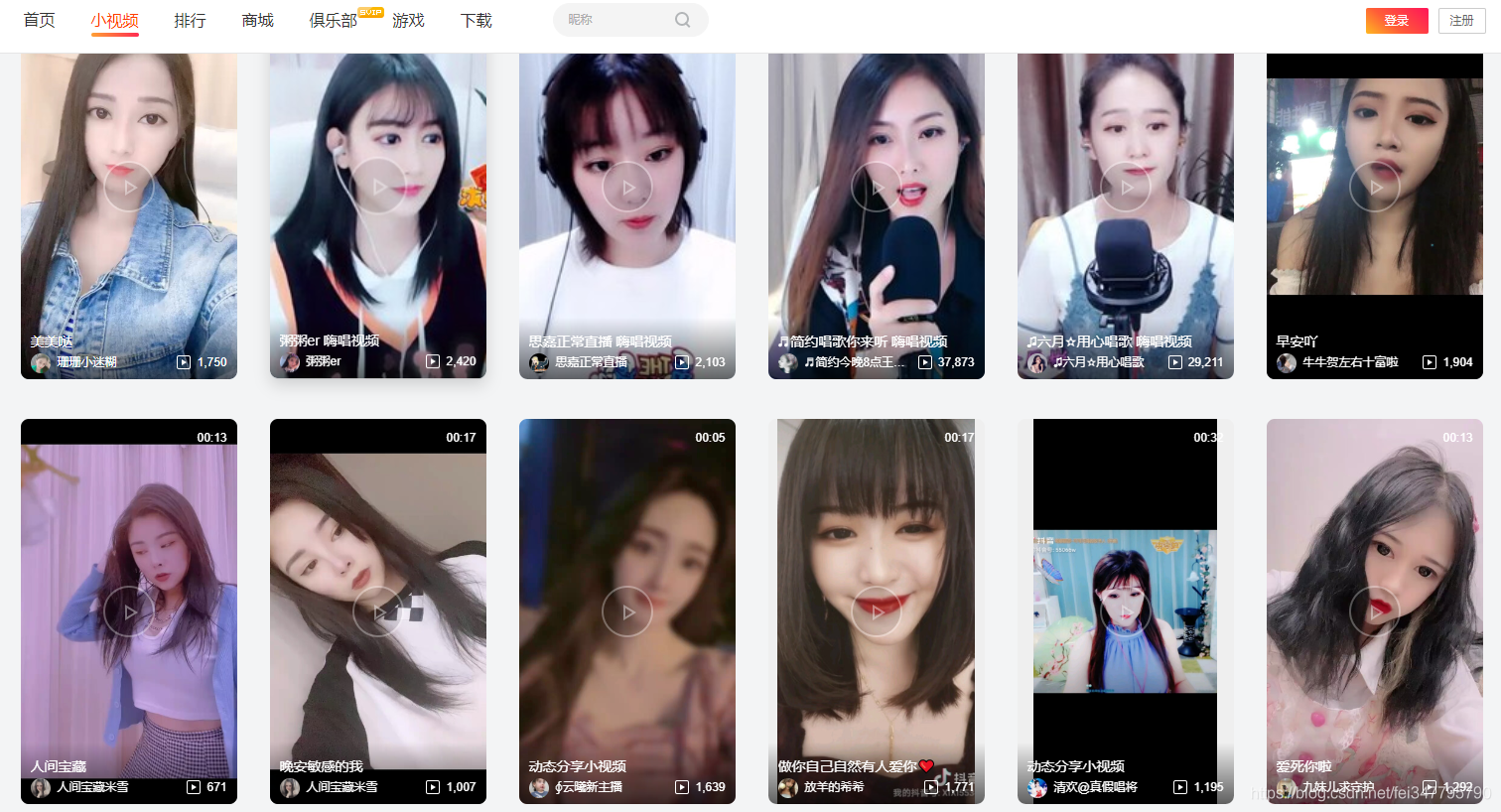
全部都是漂亮的小姐姐,爱了,爱了~

想把这些小姐姐的自拍视频全部打包带回家~
网站是动态数据加载的,再开发者工具里面可以找到相关的数据包
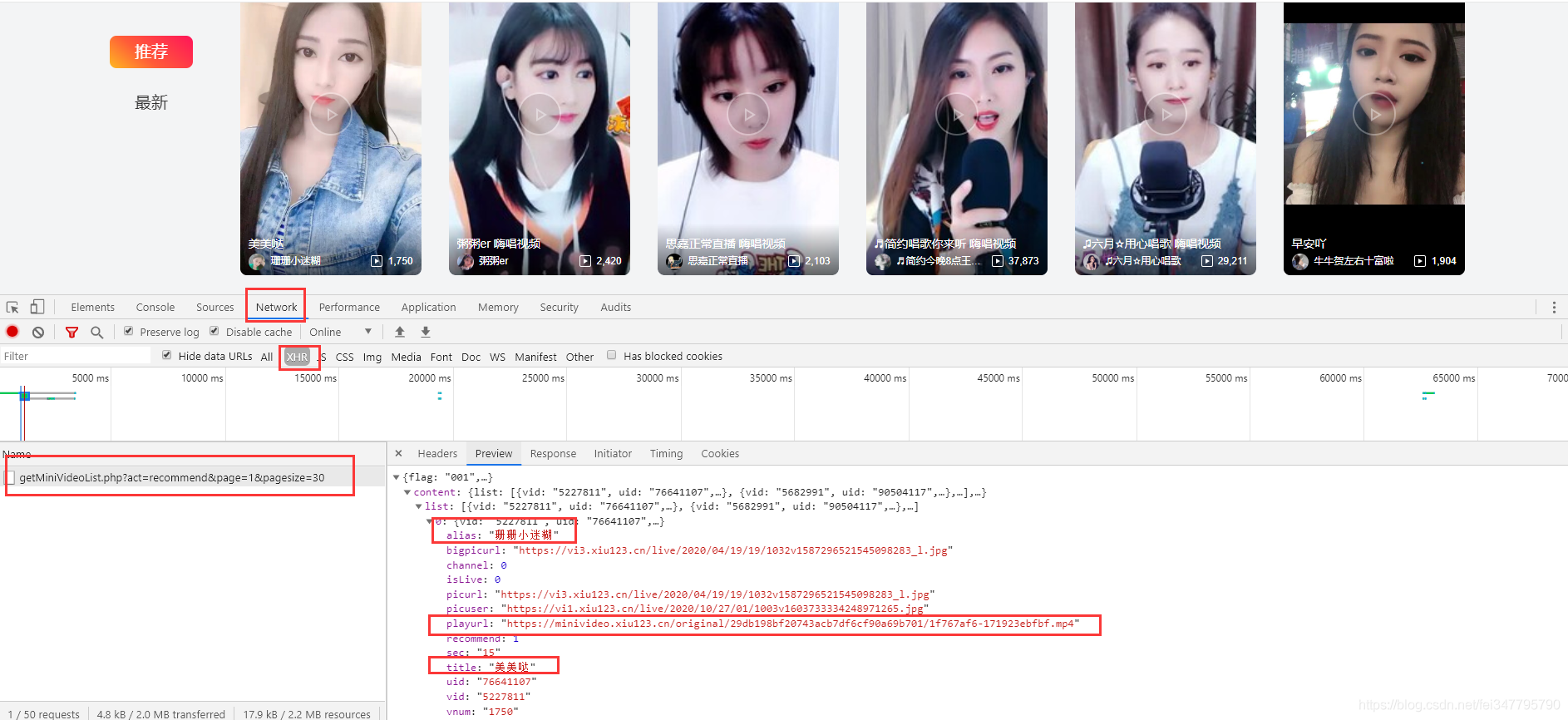
有昵称、标题、封面以及视频地址,复制视频地址会自动下载,所以只需要模拟请求这个也就可以获取相对应的数据了
import requests
import pprint
url = 'https://v.6.cn/minivideo/getMiniVideoList.php?act=recommend&page=1&pagesize=30'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'}
response = requests.get(url=url, headers=headers)
html_data = response.json()
pprint.pprint(html_data)
1234567
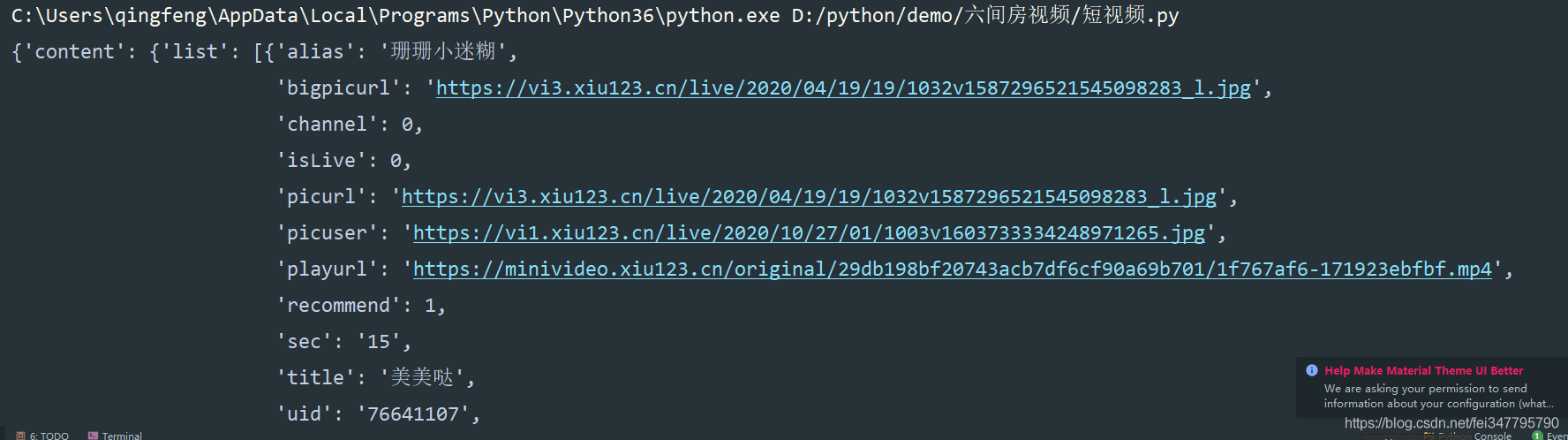
返回的是json数据,所以我们可以根据字典取值的方法获取视频地址~
pprint 格式化输入模块,这样的会让返回的数据看的清楚。
解析数据,获取视频地址以及标题
lis = html_data['content']['list']
for li in lis:
title = li['title']
play_url = li['playurl']
print(title, play_url)
12345
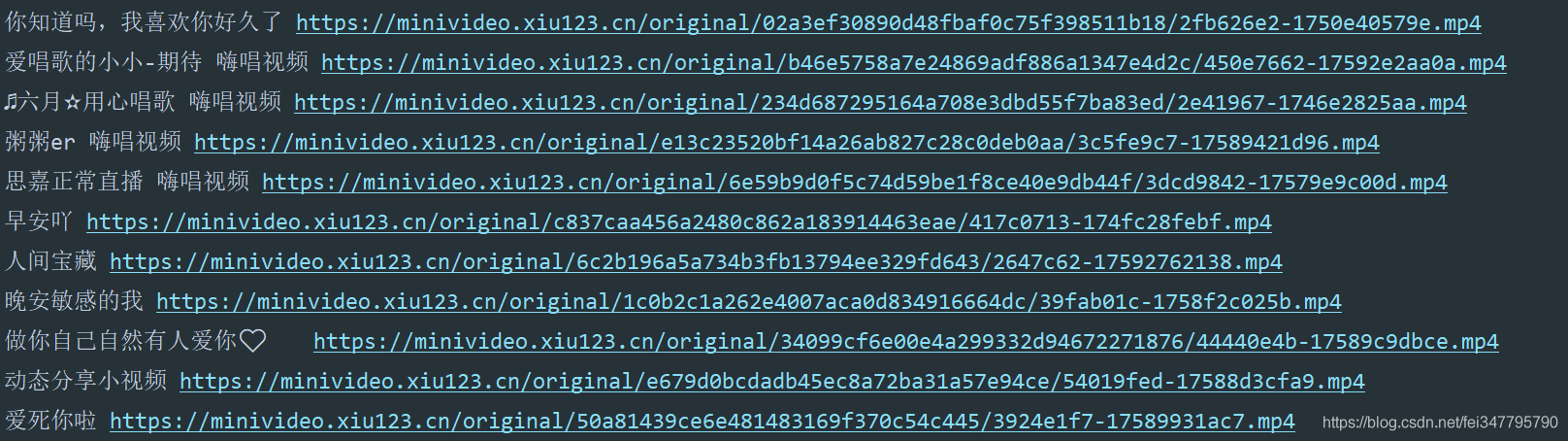
获取视频地址之后,可以请求视频地址,进行保存
response_2 = requests.get(url=play_url)
path = 'D:\\python\\demo\\六间房视频\\视频\\' + title + '.mp4'
with open(path, mode='wb') as f:
f.write(response_2.content)
print(title)
12345
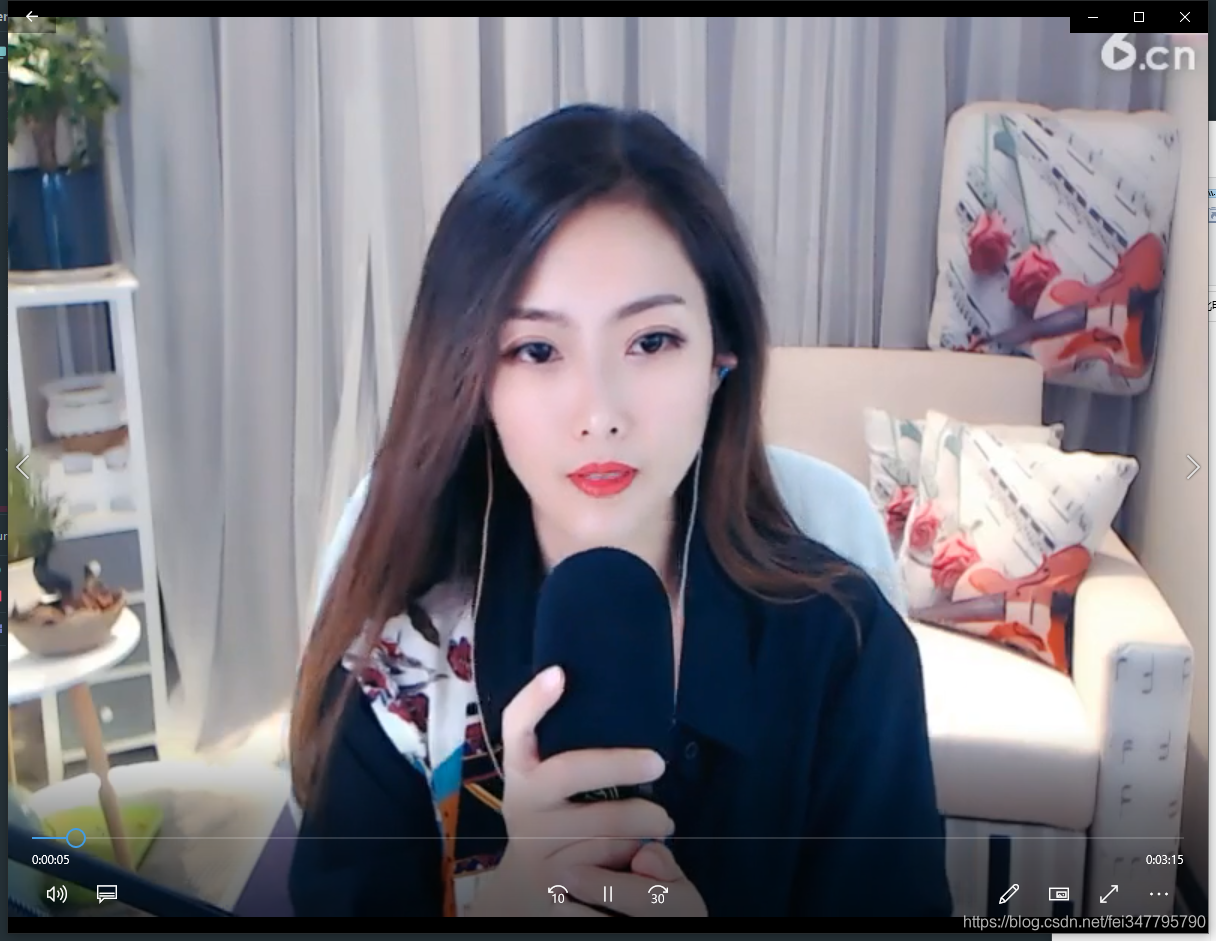
保存下来的视频是可以播放的,但是这个只是一页的数据,对于这丢丢视频,小编是肯定不满足的~
那怎么实现翻页爬取呢,这就要分析数据接口的url变化了
六间房这个网站的数据加载是瀑流的数据加载方式,和平常我们看到的那点击下一页就跳转的不一样,它是需要你往下滑,然后就会给你出现数据

可以清楚的看到page的变化是对应的是页码
所以我们只需要在url前面给他循环遍历一下就可以了,达到翻页的效果了
完整代码
import requests
import pprint
for page in range(1, 11):
url = 'https://v.6.cn/minivideo/getMiniVideoList.php?act=recommend&page={}&pagesize=30'.format(page)
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'}
response = requests.get(url=url, headers=headers)
html_data = response.json()
lis = html_data['content']['list']
for li in lis:
title = li['title']
play_url = li['playurl']
response_2 = requests.get(url=play_url)
path = 'D:\\python\\demo\\六间房视频\\视频\\' + title + '.mp4'
with open(path, mode='wb') as f:
f.write(response_2.content)
print(title)