

欢迎访问我的GitHub
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
本文是《Flink的DataSource三部曲》系列的第一篇,该系列旨在通过实战学习和了解Flink的DataSource,为以后的深入学习打好基础,由以下三部分组成:
- 直接API:即本篇,除了准备环境和工程,还学习了StreamExecutionEnvironment提供的用来创建数据来的API;
- 内置connector:StreamExecutionEnvironment的addSource方法,入参可以是flink内置的connector,例如kafka、RabbitMQ等;
- 自定义:StreamExecutionEnvironment的addSource方法,入参可以是自定义的SourceFunction实现类;
Flink的DataSource三部曲文章链接
关于Flink的DataSource
官方对DataSource的解释:Sources are where your program reads its input from,即DataSource是应用的数据来源,如下图的两个红框所示:
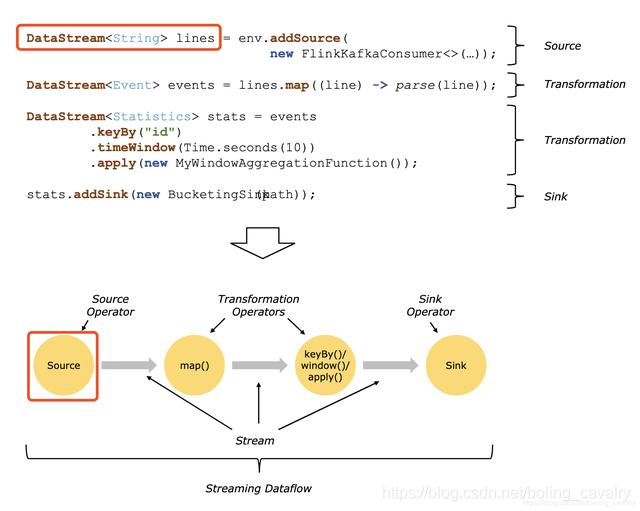
DataSource类型
对于常见的文本读入、kafka、RabbitMQ等数据来源,可以直接使用Flink提供的API或者connector,如果这些满足不了需求,还可以自己开发,下图是我按照自己的理解梳理的:
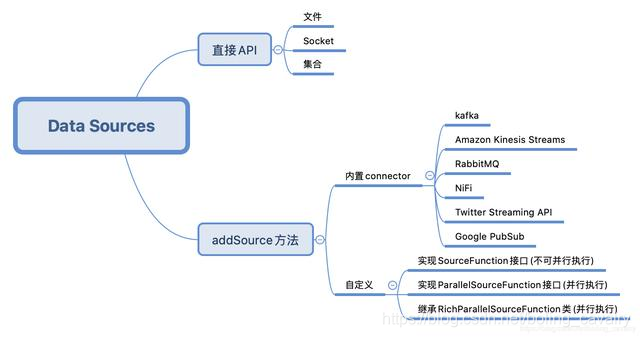
环境和版本
熟练掌握内置DataSource的最好办法就是实战,本次实战的环境和版本如下:
- JDK:1.8.0_211
- Flink:1.9.2
- Maven:3.6.0
- 操作系统:macOS Catalina 10.15.3 (MacBook Pro 13-inch, 2018)
- IDEA:2018.3.5 (Ultimate Edition)
源码下载
如果您不想写代码,整个系列的源码可在GitHub下载到,地址和链接信息如下表所示(github.com/zq2599/blog…
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | github.com/zq2599/blog… | 该项目在GitHub上的主页 |
| git仓库地址(https) | github.com/zq2599/blog… | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
这个git项目中有多个文件夹,本章的应用在flinkdatasourcedemo文件夹下,如下图红框所示:
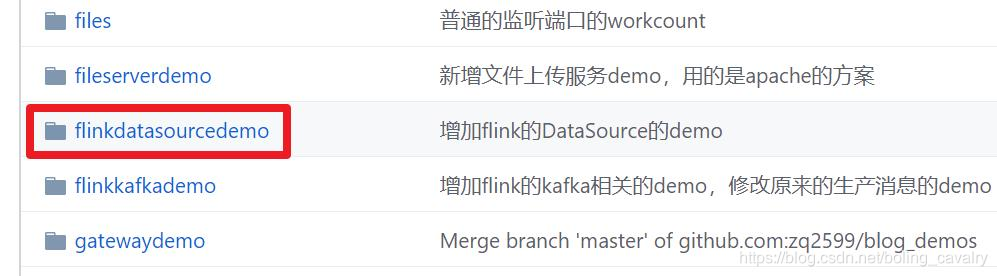
环境和版本
本次实战的环境和版本如下:
- JDK:1.8.0_211
- Flink:1.9.2
- Maven:3.6.0
- 操作系统:macOS Catalina 10.15.3 (MacBook Pro 13-inch, 2018)
- IDEA:2018.3.5 (Ultimate Edition)
创建工程
- 在控制台执行以下命令就会进入创建flink应用的交互模式,按提示输入gourpId和artifactId,就会创建一个flink应用(我输入的groupId是com.bolingcavalry,artifactId是flinkdatasourcedemo):
mvn \
archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.9.2
- 现在maven工程已生成,用IDEA导入这个工程,如下图:

- 以maven的类型导入:
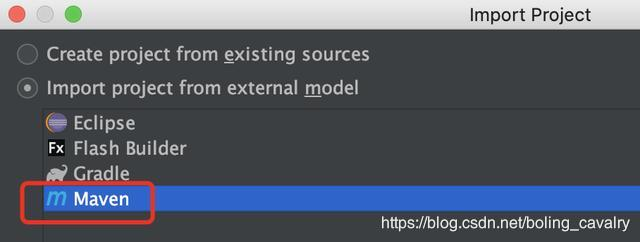
- 导入成功的样子:
- 项目创建成功,可以开始写代码实战了;
辅助类Splitter
实战中有个功能常用到:将字符串用空格分割,转成Tuple2类型的集合,这里将此算子做成一个公共类Splitter.java,代码如下:
package com.bolingcavalry;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
import org.apache.flink.util.StringUtils;
public class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
if(StringUtils.isNullOrWhitespaceOnly(s)) {
System.out.println("invalid line");
return;
}
for(String word : s.split(" ")) {
collector.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
准备完毕,可以开始实战了,先从最简单的Socket开始。
Socket DataSource
Socket DataSource的功能是监听指定IP的指定端口,读取网络数据;
- 在刚才新建的工程中创建一个类Socket.java:
package com.bolingcavalry.api;
import com.bolingcavalry.Splitter;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
public class Socket {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//监听本地9999端口,读取字符串
DataStream<String> socketDataStream = env.socketTextStream("localhost", 9999);
//每五秒钟一次,将当前五秒内所有字符串以空格分割,然后统计单词数量,打印出来
socketDataStream
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
.print();
env.execute("API DataSource demo : socket");
}
}
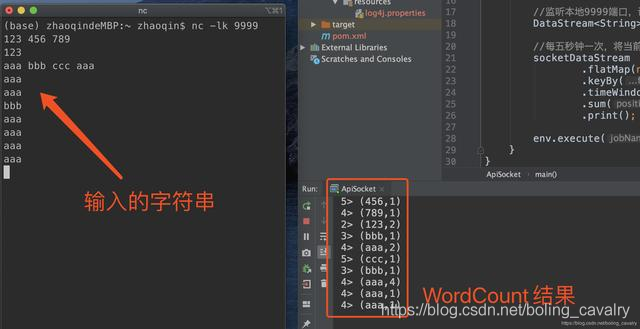
从上述代码可见,StreamExecutionEnvironment.socketTextStream就可以创建Socket类型的DataSource,在控制台执行命令nc -lk 9999,即可进入交互模式,此时输出任何字符串再回车,都会将字符串传输到本机9999端口;
- 在IDEA上运行Socket类,启动成功后再回到刚才执行nc -lk 9999的控制台,输入一些字符串再回车,可见Socket的功能已经生效:
集合DataSource(generateSequence)
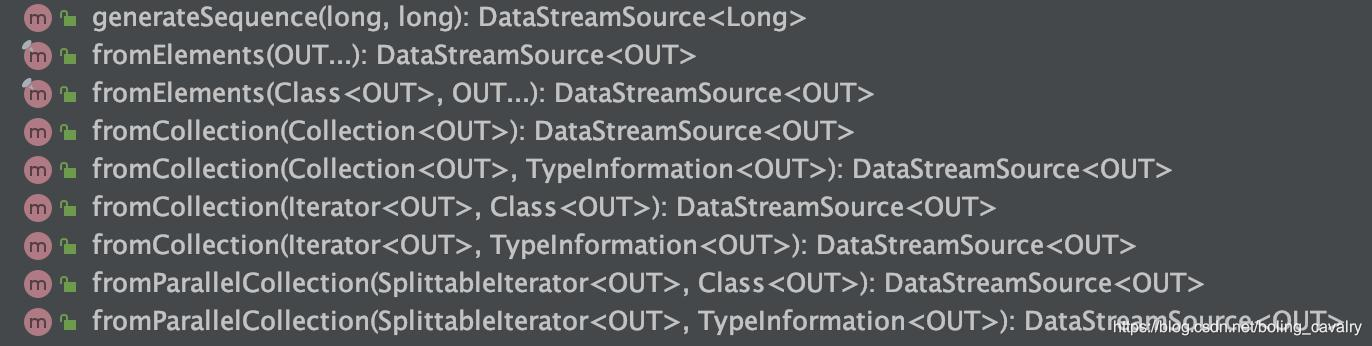
- 基于集合的DataSource,API如下图所示:
 2. 先试试最简单的generateSequence,创建指定范围内的数字型的DataSource:
2. 先试试最简单的generateSequence,创建指定范围内的数字型的DataSource:
package com.bolingcavalry.api;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class GenerateSequence {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//并行度为1
env.setParallelism(1);
//通过generateSequence得到Long类型的DataSource
DataStream<Long> dataStream = env.generateSequence(1, 10);
//做一次过滤,只保留偶数,然后打印
dataStream.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long aLong) throws Exception {
return 0L==aLong.longValue()%2L;
}
}).print();
env.execute("API DataSource demo : collection");
}
}
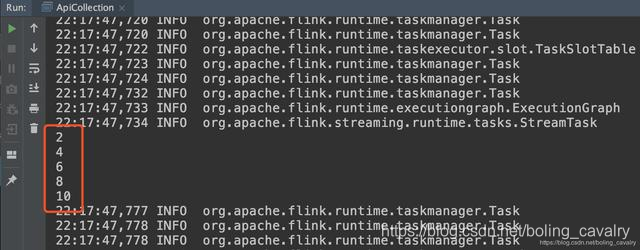
- 运行时会打印偶数:
集合DataSource(fromElements+fromCollection)
- fromElements和fromCollection就在一个类中试了吧,创建FromCollection类,里面是这两个API的用法:
package com.bolingcavalry.api;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.ArrayList;
import java.util.List;
public class FromCollection {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//并行度为1
env.setParallelism(1);
//创建一个List,里面有两个Tuple2元素
List<Tuple2<String, Integer>> list = new ArrayList<>();
list.add(new Tuple2("aaa", 1));
list.add(new Tuple2("bbb", 1));
//通过List创建DataStream
DataStream<Tuple2<String, Integer>> fromCollectionDataStream = env.fromCollection(list);
//通过多个Tuple2元素创建DataStream
DataStream<Tuple2<String, Integer>> fromElementDataStream = env.fromElements(
new Tuple2("ccc", 1),
new Tuple2("ddd", 1),
new Tuple2("aaa", 1)
);
//通过union将两个DataStream合成一个
DataStream<Tuple2<String, Integer>> unionDataStream = fromCollectionDataStream.union(fromElementDataStream);
//统计每个单词的数量
unionDataStream
.keyBy(0)
.sum(1)
.print();
env.execute("API DataSource demo : collection");
}
}
- 运行结果如下:
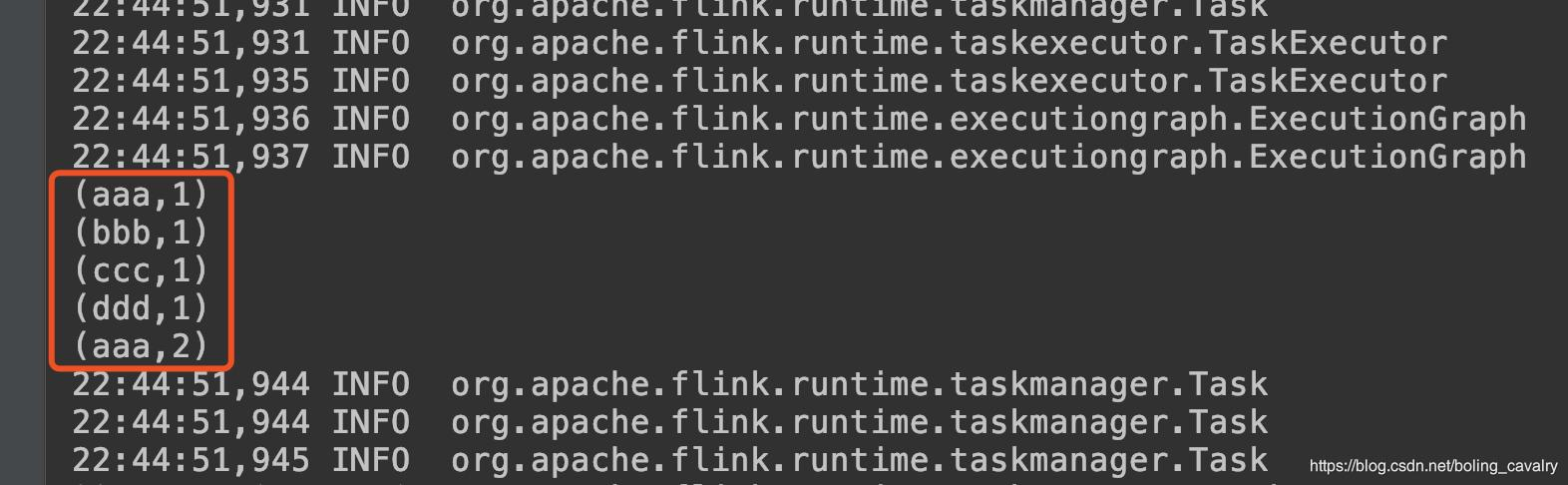
文件DataSource
- 下面的ReadTextFile类会读取绝对路径的文本文件,并对内容做单词统计:
package com.bolingcavalry.api;
import com.bolingcavalry.Splitter;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class ReadTextFile {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度为1
env.setParallelism(1);
//用txt文件作为数据源
DataStream<String> textDataStream = env.readTextFile("file:///Users/zhaoqin/temp/202003/14/README.txt", "UTF-8");
//统计单词数量并打印出来
textDataStream
.flatMap(new Splitter())
.keyBy(0)
.sum(1)
.print();
env.execute("API DataSource demo : readTextFile");
}
}
- 请确保代码中的绝对路径下存在名为README.txt文件,运行结果如下:
3. 打开StreamExecutionEnvironment.java源码,看一下刚才使用的readTextFile方法实现如下,原来是调用了另一个同名方法,该方法的第三个参数确定了文本文件是一次性读取完毕,还是周期性扫描内容变更,而第四个参数就是周期性扫描的间隔时间:
public DataStreamSource<String> readTextFile(String filePath, String charsetName) {
Preconditions.checkArgument(!StringUtils.isNullOrWhitespaceOnly(filePath), "The file path must not be null or blank.");
TextInputFormat format = new TextInputFormat(new Path(filePath));
format.setFilesFilter(FilePathFilter.createDefaultFilter());
TypeInformation<String> typeInfo = BasicTypeInfo.STRING_TYPE_INFO;
format.setCharsetName(charsetName);
return readFile(format, filePath, FileProcessingMode.PROCESS_ONCE, -1, typeInfo);
}
- 上面的FileProcessingMode是个枚举,源码如下:
@PublicEvolving
public enum FileProcessingMode {
/** Processes the current contents of the path and exits. */
PROCESS_ONCE,
/** Periodically scans the path for new data. */
PROCESS_CONTINUOUSLY
}
- 另外请关注readTextFile方法的filePath参数,这是个URI类型的字符串,除了本地文件路径,还可以是HDFS的地址:hdfs://host:port/file/path
至此,通过直接API创建DataSource的实战就完成了,后面的章节我们继续学习内置connector方式的DataSource;
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界... github.com/zq2599/blog…
