0.HTML
- 1.lable 标签的用法
- label扩大可点击的范围

demo1:实现点击“密码”光标也能锁定输入框
方法1:推荐!!!
<label>密码: <input type="password" /></label>
方法2:
<lable for ="mima">密码:</lable>
<input type="password" id="mima" />
1.css
blog.csdn.net/sinat_36422…
2.js
一、垃圾回收的必要性
要回收不用的内存,就有了垃圾回收机制
var a = "before"
var b = "override a"
var a = b
这段代码运行之后,“before”这个字符串失去了引用(之前是被a引用)
系统检测到这个事实之后,就会释放该字符串的存储空间以便这些空间可以被再利用。
二、垃圾回收原理浅析
现在各大浏览器通常用采用的垃圾回收有两种方法:标记清除、引用计数。
1、标记清除 (目前主流的方式)
当变量进入执行环境就给标记,之后用到的时候就清除标记,不用的时候再次标记
最后。垃圾收集器完成内存清除工作,销毁那些带标记的值,并回收他们所占用的内存空间。
2、引用计数
引用就+1 不用就-1 但是循环引用的话就无法回收了 内存泄漏了
三、减少JavaScript中的垃圾回收(实现变量的复用)
1、对象object优化
// 删除obj对象的所有属性,高效的将obj转化为一个崭新的对象!
cr.wipe = function (obj) {
for (var p in obj) {
if (obj.hasOwnProperty(p))
delete obj[p]
}
}
有些时候,你可以使用cr.wipe(obj)方法清理对象,再为obj添加新的属性,就可以达到重复利用对象的目的。
虽然通过清空一个对象来获取“新对象”的做法,比简单的通过{}来创建对象要耗时一些,但是在实时性要求很高的代码中,这一点短暂的时间消耗,这是非常值得的!
2、数组array优化
清空数组 arr = [] 这种方式又创建了一个新的空对象,并且将原来的数组对象变成了一小片内存垃圾!
推荐 arr.length = 0 也能达到清空数组的目的,并且同时能实现数组重用,减少内存垃圾的产生。
function add(num1,num2){
var num = num1+num2
if(num2+1>100){
return num
}else{
return add(num,num2+1)
}
}
var sum =add(1,2)
--------------------------------------------
add0(num1,num2){
let sum = 0
for (var i = num1
sum += i
}
return sum
},
--------------------------------------------
偶数和
function sum (){
var he = 0
for( var k = 1
if( k % 2 ==0 ){
he += k
}
}
console.log("熟悉的偶数和"+ he)
}
sum()
捕获阶段:当事件发生的时候,将事件从window依次往子元素传递
目标阶段:确定事件目标
冒泡阶段:事件目标开始处理事件,处理完以后会将事件依次传递给父元素,一直到window
document.addEventListener('lala',()=>{
})
let qyEvent = {
event:{
},
addEvent(eventName,fn){
if(this.event[eventName] == undefined){
this.event[eventName] = []
}
this.event[eventName].push(fn)
},
removeEvent(eventName,fn){
this.event[eventName].forEach((item,i)=>{
if(fn == item){
this.event[eventName].splice(i,1)
}
})
},
emit(eventName){
this.event[eventName].forEach((item)=>{
item()
})
}
}
let abc = ()=>{
console.log('事件1')
}
qyEvent.addEvent('shijian1',abc)
qyEvent.addEvent('shijian1',()=>{
console.log('事件2')
})
qyEvent.removeEvent('shijian1',abc)
qyEvent.emit('shijian1')
1.深拷贝 浅拷贝
- 浅拷贝的意思就是只复制引用,而未复制真正的值。
- 深拷贝就是对目标的完全拷贝。它们老死不相往来,谁也不会影响谁。
- 实现深拷贝主要是两种:
- 1.利用 JSON 对象中的 parse 和 stringify
- 2.利用递归来实现每一层都重新创建对象并赋值
const originArray = [1,2,3,4,5];
const originObj = {a:'a',b:'b',c:[1,2,3],d:{dd:'dd'}};
const cloneArray = originArray;
const cloneObj = originObj;
cloneArray.push(6);
cloneObj.a = {aa:'aa'};
console.log(cloneArray); // [1,2,3,4,5,6]
console.log(originArray); // [1,2,3,4,5,6]
console.log(cloneObj); // {a:{aa:'aa'},b:'b',c:Array[3],d:{dd:'dd'}}
console.log(originArray); // {a:{aa:'aa'},b:'b',c:Array[3],d:{dd:'dd'}}
上面的代码是最简单的利用 = 赋值操作符实现了一个浅拷贝,
随着 cloneArray 和 cloneObj 改变,originArray 和 originObj 也随着发生了变化。
JSON.parse(JSON.stringify(originArray))
- JSON.stringify 对象 => 字符串。
- JSON.parse 字符串 => 对象。
const originArray = [1,2,3,4,5]
const cloneArray = JSON.parse(JSON.stringify(originArray))
console.log(cloneArray === originArray)
const originObj = {a:'a',b:'b',c:[1,2,3],d:{dd:'dd'}}
const cloneObj = JSON.parse(JSON.stringify(originObj))
console.log(cloneObj === originObj)
改变副本 不会 影响母本
确实是深拷贝,也很方便。但是,这个方法只能适用于一些简单的情况
(如果对象中有函数 就不行了)
const originObj = {
name:'axuebin',
sayHello:function(){
console.log('Hello World')
}
}
console.log(originObj)
const cloneObj = JSON.parse(JSON.stringify(originObj))
console.log(cloneObj)
发现在 cloneObj 中,有属性丢失了。。。那是为什么呢?
函数 会在转换过程中被忽略。。。
递归的方法
function deepClone(source){
const targetObj = source.constructor === Array ? [] : {};
for(let keys in source){
if(source.hasOwnProperty(keys)){
if(source[keys] && typeof source[keys] === 'object'){
targetObj[keys] = source[keys].constructor === Array ? [] : {};
targetObj[keys] = deepClone(source[keys]);
}else{
targetObj[keys] = source[keys];
}
}
}
return targetObj;
}
2.原型 原型链
- 原型对象(prototype)
- 所有的函数都有 prototype 而且是函数特有的
- 上面的所有方法和属性都能被函数new出来的实例对象访问
- 因为对象身上有 proto 指向 原型(prototype)
function Star(uname, age) {
this.uname = uname
this.age = age
}
Star.prototype.sing = function() {
console.log('我会唱歌')
}
var ldh = new Star('刘德华', 18)
// 1. 只要是对象就有__proto__ 原型, 指向原型对象 prototype
console.log(ldh.__proto__ === Star.prototype)
prototype 也是一个对象 里面有属性和方法 还有 __proto__ 而且有一个构造器指向构造函数本身
- 构造器 (constructor)
- 构造器存在于 函数的 prototype 中,保存了指向函数的引用(指针)
- 通俗理解就是 constructor 指向函数本身
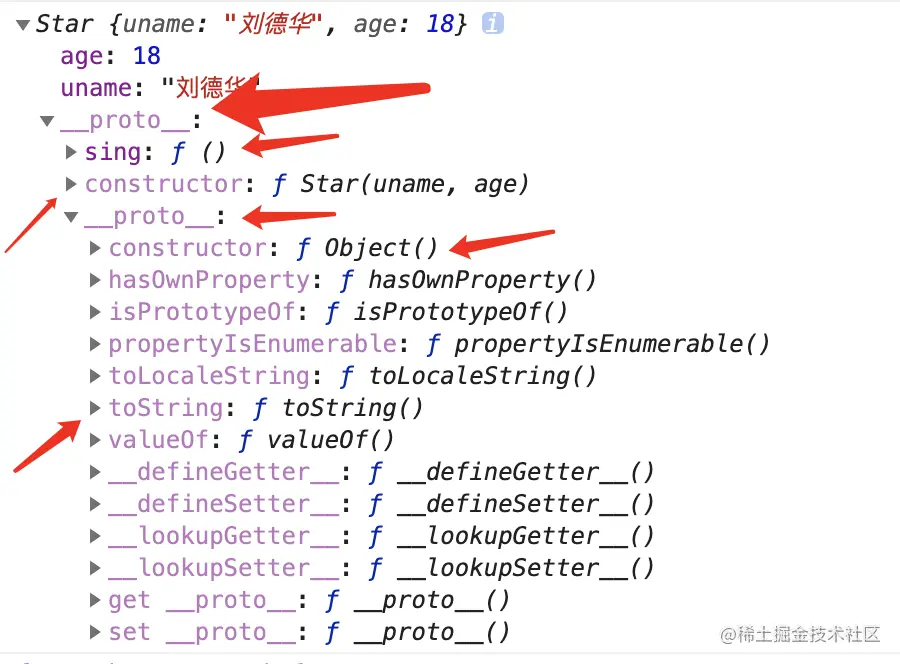 上图的分析 打印ldh 这个实例对象
上图的分析 打印ldh 这个实例对象
- 1.对象身上本身有uname age属性
- 2.ldh.sing() 本质是去Star.prototype 上面去查找 因为 ldh.__proto__ === Star.prototype
- 3.ldh.toString() 本质是去Star.prototype.__proto__ 上面去查找
ldh.__proto__.__proto__ (原型链查找)
- 4.Star.prototype 中有一个构造器 constructor 指向了构造函数本身 Star
总结:prototype 只有函数或者构造函数才有的属性
__proto__ 是任何对象都有的属性
2.1 常规面试题 如何准确判断一个数据是数组?
- 下面三种方法 返回都是 bool 判断[ ] 是都是数组
- 1.[ ] instanceof Array
- 2.Object.prototype.toString.call([ ]) === '[object Array]'
- 3.Array.isArray([ ])
3.js异步
- 解释:JS是单线程 出现请求 定时器等耗时操作时候回扔到任务队列中,主线程任务执行完毕去任务队列中轮询,有任务就执行。
3.1 模拟
<script>
function loadImage(src, resolve, reject) {
let image = new Image()
image.src = src
image.onload = () => {
resolve(image)
}
image.onerror = reject
}
console.log('111');
loadImage('./images/2.jpg', (image) => {
document.body.appendChild(image)
console.log('success');
}, () => {
console.log('fail');
})
console.log('222');
</script>
分析:虽然 loadImage 方法先调用 但是会扔到任务队列中,优先执行主线程
先输出 console.log('111'); 之后是 console.log('222');
之后再去任务队列中拿回调结果
2.如何优化SPA首页加载速度慢?
分析方法:
1.大文件定位
我们可以使用webpack可视化插件Webpack Bundle Analyzer 查看工程js文件大小,然后有目的的解决过大的js文件。
npm install --save-dev webpack-bundle-analyzer
在webpack中设置如下,然后npm run dev的时候会默认在浏览器上打开
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin
module.exports = {
plugins: [
new BundleAnalyzerPlugin()
]
}
- 公用的JS用标签外部引入,减少app.bundel的体积,让浏览器并行下载资源文件,提高下载速度
- 路由懒加载 图片懒加载
component: () => import('./components/ShowBlogs.vue')
vuecli 3中,我们还需要多做一步工作
因为 vuecli 3默认开启 prefetch(预先加载模块),提前获取用户未来可能会访问的内容
在首屏会把这十几个路由文件,都一口气下载了
所以我们要关闭这个功能,在 vue.config.js中设置
- 首页加一个loading
- 移除console
- 长列表分页加载
3.Vue生命周期
此时实例初始化了,但是数据观察和时间机制没完成,不能获取DOM节点
Vue实例已经创建 但是还是不能获取DOM节点
在挂载开始之前被调用:相关的render函数首次被调用。
数据更新时调用
组件DOM已经更新,所以你现在可以执行依赖于DOM的操作。
keep-alive组件激活时调用。
keep-alive组件停用时调用。
实例销毁之间调用。
Vue实例销毁后调用。调用后,Vue实例指示的所有东西都会解绑定,所有的事件监听器会被移除,所有的子实例也会被销毁。
3.nexttick
- Vue 实现响应式并不是数据发生变化之后 DOM 立即变化,而是按一定的策略进行 DOM 的更新
- 简单来说,Vue 在修改数据后,视图不会立刻更新,而是等同一事件循环中的所有数据变化完成之后,再统一进行视图更新。


