

每隔60秒一次的心跳检测或发送请求超时等待响应;即:等待xxx时间就执行yyy任务;可以开启定时任务timer,周期性检测是否要执行任务来处理此类需求
当存在有大量的心跳检测任务或超时控制任务, 如 每个超时任务都开启定时任务timer则会消耗大量资源; 只开启一个定时任务timer用来检测大量的任务则会遇到 遍历耗时长问题 (每次循环遍历所有任务检测时间)如:java.util.Timer
更好的解决思路,开启一个定时任务time,拆分大量的定时任务,每次只检测部分任务,没有被检测到的任务在理论上保证不需要执行;即可以节省资源,也很大程度缓解遍历耗时长的问题 如: HashedWheelTimer
HashedWheelTimer使用方式
Hash轮
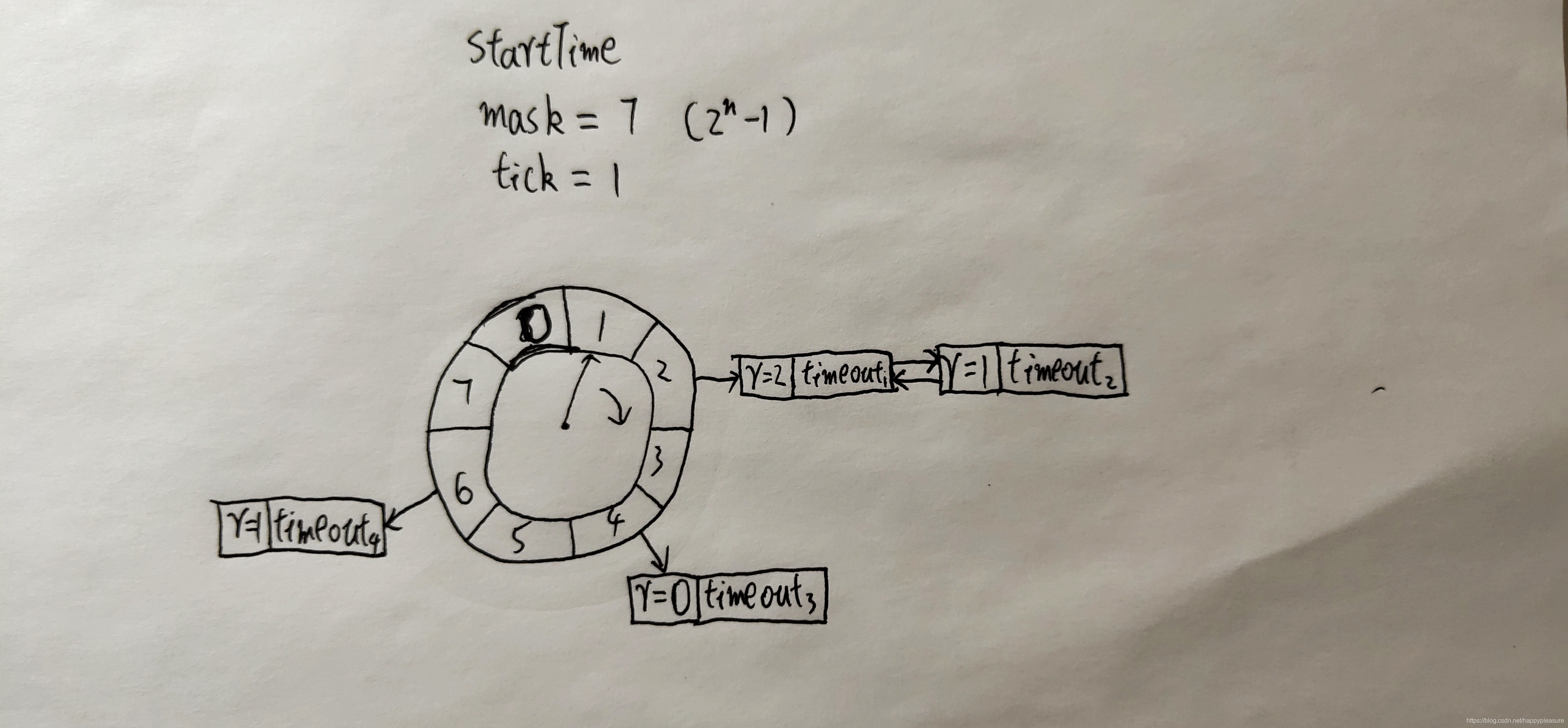
HashedWheelTimer创建的时候创建worker线程(用于循环检测),走一圈有多少个bucket, 走一个bucket 隔需要多久时间 tickDuration
第一个timeout 创建时,启动worker线程,开始循环检测;并记录HashWheelTimer中worker线程开始运行时间startTime,也是整个hash轮开始转动时间【不是timeout开始计时的时间】;新创建timeout时不会计算加入到具体bucket中
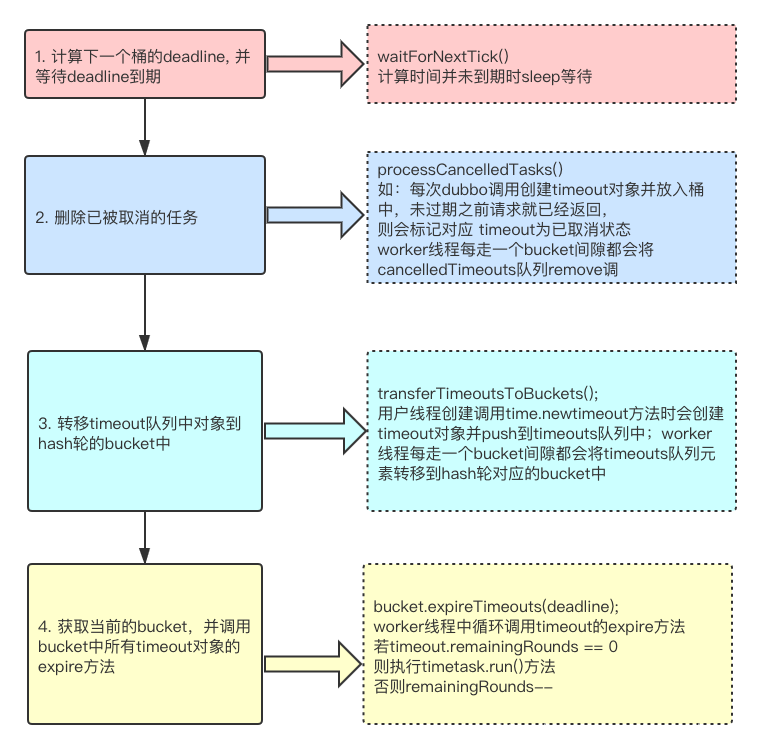
worker线程作为HashedWheelTimer循环检测调度器,启动开启do while循坏模式;一次循环分为4步
Worker 线程
waitForNextTick() 等待期间做什么呢?答案是sleep;那么在sleep期间如果有timeout到期了怎么办?答案是睡醒来在执行;那么tickDuration 就控制着时间的精准度,值越小精准度越高;如tickDuration=1秒,在1.1秒时添加了timeout,2秒时间点扫描发现没有超时,3s秒才扫描到timeout已超时;此时已经过了1.9秒;若tickDuration非常小worker线程则越繁忙
dubbo中发送请求超时检测time中tickDuration=30毫秒
未到期但被取消的任务会放到 cancelledTimeouts【HashWheelTime的队列属性】集合中, worker线程周期性的执行do while方法会调用processCancelledTasks() 会从bucket中删除调对应的timeout;如:rpc请求1s超时检测任务,正常请求20毫秒返回之后需要cancel调对应的timeout
worker线程执行 transferTimeoutsToBuckets() 将新创建的timeout根据deadline计算出remainingRounds几轮与idx 并加入到对应的bucket
bucket.expireTimeouts(deadline); 将到期的bucket中所有的timeout判断并进行超时处理,到期的timeout进行超时处理,即调用TimeTask的run方法;此处风险:TimeTask.run() 方法是阻塞同步执行的,**如果某task执行时间过久则会阻塞Worker线程 进一步拖慢超时检测流程 **
Dubbo中应用
rpc请求超时检测,发送请求时创建 timeout
定义timeTask
请求正常返回时cancel timeout
发送同步请求,将超时检测交给HashedWheelTimer中worker线程 ,那么发送请求的工作线程在做什么呢?答案是在阻塞等待response
