


谢传纪,微医云服务团队 iOS 工程师。一个思想和行为都比较古怪的中年杠精
看 YYCache 源码的原因
关于 YYCache,突然想起来看这个五年前的 OC 库是因为之前在掘金上看到过一篇文章,上面提到了 YYCache 使用了 LRU 算法,心中不免起了一些涟漪。自己刷过一些算法题,LRU 也实现过,但是从来没用到工程过,所以对自己来说算法好像只是面试使用的八股文。
还有一个原因是 @ibireme 大神五年前写的代码直到今天还被很多开发者分析源码,也经常出现在面试题中,想看看它到底有什么魔力。
缓存设计
源码阅读完后,相关的文章也看了一些。现在结合 YYCache 分析一个优秀的缓存系统应该包括哪些内容。
多级缓存,合理的入口
多级缓存指包括存取速度快的内存缓存和持久化存储的磁盘缓存
内存缓存:存取速度快,和 CPU 直接通信。与程序生命周期绑定,程序杀死后清空
磁盘缓存:存取速度慢。持久化存储在磁盘中,和程序生命周期无关。
由于开发者使用的功能只是存取数据,所以对外直接暴露的接口应该做到以下几点
- 存取 API 足够简单
- 支持 非系统数据类型/自定义模型 的存取
- 支持同步、异步
- 其他功能类开放少而足够的 API 供开发者自定义存储路径等
YYCache 中的 API 如下,通过 NSCoding 协议支持自定义模型的存取
- (void)setObject:(nullable id<NSCoding>)object forKey:(NSString *)key;
- (void)setObject:(nullable id<NSCoding>)object forKey:(NSString *)key withBlock:(nullable void(^)(void))block;
- (nullable id<NSCoding>)objectForKey:(NSString *)key;
- (void)objectForKey:(NSString *)key withBlock:(nullable void(^)(NSString *key, id<NSCoding> object))block;
在 Swift 中可以通过 subscript 函数实现更简单的下标访问。
subscript(key: String) -> NSCoding? {
get {
if let returnValue = object(forKey: key) as? NSCoding {
return returnValue
}
return nil
}
set {
if let newValue = newValue {
set(object: newValue, forKey: key)
}
else {
removeObject(forKey: key)
}
}
}
安全准确的数据存取
影响数据读取的安全和准确性一般和多线程访问有关系,能直接想到的处理方式有下面几种:
- 数据存取操作放入一个并行队列,通过
dispatch_barrier_async等函数控制队列执行任务 - 数据存取操作切到一个同步队列去按顺序执行
- 所有数据操作加锁处理
正常情况下第一种和第二种方式的效率会比较低,因为涉及到线程调度相关的开销。而第三种要分析下各种锁的性能和使用场景。下面会说到关于锁的选择
合理的缓存淘汰策略
通常情况下,我们要限制缓存的容量大小,不会让其无限存储,所以就涉及到了淘汰策略。常见的淘汰策略有:
- LFU:Least Frequency Used,访问次数最低的数据会被淘汰
- LRU:Least Recently Used,最长时间没被访问的数据会被淘汰
- ARC:综合 LFU 和 LRU,即访问次数和时间,来淘汰数据
- FIFO:First in First out,最先进入的数据会被淘汰
- MRU:最近被使用的数据会被淘汰(乍听有点奇怪,举个例子,我刚看完电视剧第 37 集,你觉得我最近还会想看它吗)
- LRU-K:LRU 的升级版,原来是访问一次,现在是 k 次
- 2Q:一个 FIFO 队列,一个 LRU 队列,访问数据时会先缓存在 FIFO 队列,再次访问时会放入 LRU 的的头部。
移动端中缓存量并不会太大,多数情况下可能 LRU 会更适合一些。YYCache 用的也是 LRU
优秀的性能
数据存取库的外在性能指标其实有很多个,比如 QPS、内存峰值等,下面在对比 Cache 库的时候也会说到。
而在设计时能直接想到的就是时空复杂度。大多数情况在时间会比空间优先级更高点,空间复杂度可以暂时不做考虑。所以设计的时间复杂度最好是 O(1) 或者 O(logN),如果是 O(N) 或者更高,可能就不太合适了。
还有一点必须考虑的就是最耗时的磁盘数据读取。这方面可以参考 YYCache 根据数据大小改变存储方式,或者使用 mmap + 临时文件 进行内存映射。
除此之外就是一些细节处理,下面列举了一些 YYCache 作者为了性能做的一些事:
- 多级缓存 + 数据同步
- 经典 LRU 淘汰策略实现 O(1) 的存取
- 使用
pthread_mutex锁代替线程切换和同步所带来的的开销 - 针对磁盘存储中数据大小的不同采取不同形式的缓存:小数据 sqlite,大数据文件存储
- 设置一个低优先级队列来释放对象
- 使用
__unsafe_unretained、直接访问变量等方式节省开销 - 使用
_dbStmtCache缓存二进制 sql 语句 - 直接访问变量内存地址代替 get/set 方法调用
YYCache 中的设计思路和实现
O(1) 和 LRU 的实现
首先了解下 LRU 算法,上面有简单提到,该算法的思想是把最长时间没有访问的数据淘汰。所以为了减少时间复杂度,通常情况下由一个双向链表 + 散列表来实现。然后在存取时作如下操作:
- 存数据时,将新节点插入到链表头部,同时更新散列表 [key: 新节点 ]
- 取数据时,根据散列表取出节点,然后将节点取出放入链表头部,同时更新原有位置的相邻节点的链接
- 数据满时,将最后一个节点删除,更新散列表
在 YYMemoryCache 中节点设计如下:
@interface _YYLinkedMapNode : NSObject {
@package
__unsafe_unretained _YYLinkedMapNode *_prev; // retained by dic
__unsafe_unretained _YYLinkedMapNode *_next; // retained by dic
id _key;
id _value;
NSUInteger _cost;
NSTimeInterval _time;
}
@interface _YYLinkedMap : NSObject {
@package
CFMutableDictionaryRef _dic; // do not set object directly
_YYLinkedMapNode *_head; // MRU, do not change it directly
_YYLinkedMapNode *_tail; // LRU, do not change it directly
}
_YYLinkedMapNode 是每个存储节点,_YYLinkedMap 相当于链表的管理类。而 _YYLinkedMap 中的 _dic 则是上文中提到的散列表,负责减少获取节点时的时间复杂度(空间换时间)
现在分析下时间复杂度(因为是双向链表,所以不需要遍历):
- 取数据:直接从散列表中取,O(1)
- 存数据:先取数据 O(1),更新原有节点位置 O(1),添加节点到头部 O(1),整体 O(1)
- 改数据:取出数据并更改 Value 指针 O(1)。
- 手动删除数据:取出数据 O(1),更新节点 O(1),整体 O(1)
- 淘汰数据:更新
_tail,然后删除原有的_tail,O(1)
上面可以看出,基本的增删改查都是 O(1),这是标准的 LRU 算法中以空间换时间的做法。当然也有可能遇到的问题,比如偶发性的、周期性的批量操作会导致 LRU 命中率急剧下降,这种情况可以考虑上面说的 LRU-K、2Q 算法。
锁的选择
YYCache 中针对内存缓存和磁盘缓存使用了两种不同的锁,作者是这么说明的:
OSSpinLock 自旋锁,性能最高的锁。原理很简单,就是一直 do while 忙等。它的缺点是当等待时会消耗大量 CPU 资源,所以它不适用于较长时间的任务。对于内存缓存的存取来说,它非常合适。 dispatch_semaphore 是信号量,但当信号总量设为 1 时也可以当作锁来。在没有等待情况出现时,它的性能比 pthread_mutex 还要高,但一旦有等待情况出现时,性能就会下降许多。相对于 OSSpinLock 来说,它的优势在于等待时不会消耗 CPU 资源。对磁盘缓存来说,它比较合适。
上图是作者在 不再安全的 OSSpinLock 中对锁性能做出的对比图。文中有提到,YYKit 中一开始用的是 OSSpinLock ,但是由于低优先级线程使用该锁占有资源后导致优先级反转问题。后来苹果也没提出比较好的解决方法,于是 YYKit 中都改成了 pthread_mutex 锁。在 iOS 10/macOS 10.12 发布时,苹果提供了新的 os_unfair_lock 作为 OSSpinLock 的替代,并且将 OSSpinLock 标记为了 Deprecated。google/protobuf 内部的 spinlock 被全部替换为 dispatch_semaphore。
我用 iPhoneX ,iOS 14 把 OSSpinLock 换成 os_unfair_lock 用作者的测试用例对比了一下目前这些锁的性能。发现新的 os_unfair_lock 并不比 dispatch_semaphore 性能高。当然这也有可能和 YYCache 作者提供的 测试代码 有关系,代码中测试是单一线程重复加锁解锁,并没有涉及到资源抢占的问题。如果有后续,我应该会完善下用例测试在等待资源的情况下各种锁的性能。
OSSpinLock: 109.16 ms
os_unfair_lock: 162.40 ms
dispatch_semaphore: 140.14 ms
pthread_mutex: 222.66 ms
NSCondition: 221.56 ms
NSLock: 244.92 ms
pthread_mutex(recursive): 365.52 ms
NSRecursiveLock: 437.68 ms
NSConditionLock: 784.76 ms
@synchronized: 1087.38 ms
---- fin (10000000) ----
这里思维稍微延伸了一下,想到为什么加锁实现的 atomic 不能保证存取的线程安全。
我们线程安全问题导致的数据错误大致是两种情况:
- 同一块数据内存,被同时写,这样的表现是数据会完全乱套了,根据 CPU 读写内存的 bit 不同,有可能一块内存就被分两次写掉,一次写 1,一次写 100,结果各写了一半进去类似的
- 逻辑顺序上出现问题,每次读写的顺序和预期不同,比如同一线程中读到的 i 是 1,自增之后却变成了 5。
atomic 的原子性是表示读写的事务操作不会被中断,不会出现同时操作同一段内存空间的情况,也就是避免 1 这种情况,它本质是做了 setter 和 getter 的加锁。但对于不同线程来说,读写操作虽然是准确的,却是无序的,也就是 2 这种情况,从而影响我们的逻辑判断。比如下面这段代码
@property (atomic) int temp;
- (void)atuomicPropertyTest {
dispatch_queue_t quque = dispatch_get_global_queue(0, 0);
for (int i = 0; i < 20; i ++) {
dispatch_async(quque, ^{
printf("some add befor index: %d, value: %d \n", i, self.temp);
self.temp = self.temp + 1;
printf("some add after index: %d, value: %d \n", i, self.temp);
});
}
// log:
some add befor index: 0, value: 0
some add after index: 0, value: 1
some add befor index: 2, value: 0
some add after index: 2, value: 2
some add befor index: 3, value: 1
some add befor index: 1, value: 0
some add befor index: 4, value: 1
some add after index: 3, value: 3
some add after index: 4, value: 5
some add after index: 1, value: 4
temp 在多个线程中被调用,当 i = 4 时,拿到 temp 的值是 1,但是加完后,却是 5,如果加上一些逻辑判断,就会导致代码错误。所以如果要保证数据的准确性,可以通过对 self.temp = self.temp + 1; 这行代码加锁,这样就会保证逻辑的正确性。
磁盘缓存时的设计
作者在选择磁盘缓存方案前有做过一些调研:
NSURLCache、FBDiskCache 都是基于 SQLite 数据库的。基于数据库的缓存可以很好的支持元数据、扩展方便、数据统计速度快,也很容易实现 LRU 或其他淘汰算法,唯一不确定的就是数据库读写的性能,为此我评测了一下 SQLite 在真机上的表现。iPhone 6 64G 下,SQLite 写入性能比直接写文件要高,但读取性能取决于数据大小:当单条数据小于 20K 时,数据越小 SQLite 读取性能越高;单条数据大于 20K 时,直接写为文件速度会更快一些。这和 SQLite 官网的描述基本一致。另外,直接从官网下载最新的 SQLite 源码编译,会比 iOS 系统自带的 sqlite3.dylib 性能要高很多。基于 SQLite 的这种表现,磁盘缓存最好是把 SQLite 和文件存储结合起来:key-value 元数据保存在 SQLite 中,而 value 数据则根据大小不同选择 SQLite 或文件存储。NSURLCache 选定的数据大小的阈值是 16K;FBDiskCache 则把所有 value 数据都保存成了文件。
在源码中,作者根据每次写入磁盘缓存的数据大小采取不同的存储方式,默认阈值是 20K。当数据较小时,会直接存入 sqlite 数据库。数据大于 20k 时,会把数据存入文件,同时为了更方便的实现 LRU 策略以及数据统计等,会在存文件的同时维护一个 sqlite 表存储文件索引等信息。
表结构如下(这里 notion 和 markdown 的表格式不一致,就直接写 sql 语句了):
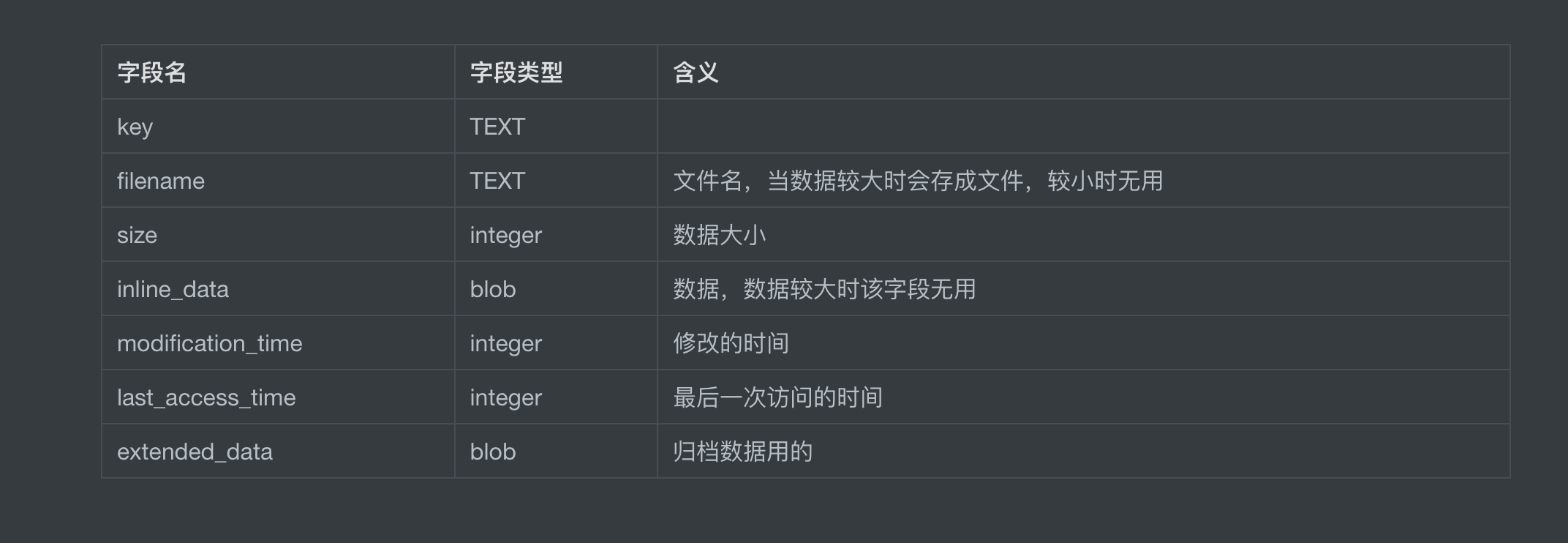
在磁盘存储时还有个小细节是 sqlite3 会根据 sql 语句生成一个 sqlite3_stmt 对象,作者使用了一个字典缓存起来,加快多次查找时的速度。
YYCache 代码中的细节
磁盘读数据后回写到内存
在 YYCache.m 的读取数据时,会先从内存中,读不到再从磁盘中读。这里有个操作是在磁盘中读到了之后会回写到内存中
- (id<NSCoding>)objectForKey:(NSString *)key {
id<NSCoding> object = [_memoryCache objectForKey:key];
if (!object) {
object = [_diskCache objectForKey:key];
if (object) {
[_memoryCache setObject:object forKey:key];
}
}
return object;
}
采用 dispatch_after 实现定时器
代码中有做定时缓存清理,但是并没有用定时器,而是用了一种类似递归的方法:
- (void)_trimRecursively {
__weak typeof(self) _self = self;
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(_autoTrimInterval * NSEC_PER_SEC)), dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_LOW, 0), ^{
__strong typeof(_self) self = _self;
if (!self) return;
[self _trimInBackground];
[self _trimRecursively];
});
}
这种写法的好处是可以不用维护定时器的生命周期,因为在每次执行到 block 的时候,如果 self 释放也就不会递归执行函数。
GCD block 捕获变量的 issues 讨论
讨论链接,相关代码:
- (void)_trimInBackground {
__weak typeof(self) _self = self;
dispatch_async(_queue, ^{
__strong typeof(_self) self = _self;
if (!self) return;
Lock();
[self _trimToCost:self.costLimit];
[self _trimToCount:self.countLimit];
[self _trimToAge:self.ageLimit];
[self _trimToFreeDiskSpace:self.freeDiskSpaceLimit];
Unlock();
});
}
通常情况下 GCD block 不需要用 weak + strong ,即使 GCD 函数的参数里有 self.queue。因为 block 执行完毕后会调用 Block_release 销毁 block,所以不会造成循环引用。
这个示例里是不需要写 if (!self) return;,如果下面的代码中有操作其他非 self 的变量和函数或者直接访问变量地址的话,这个判断还是必须要加的。
@package 关键字
这个关键字等同于 Swift 中的默认关键字: internal ,只给内部 framework 使用。
本来应该是个很简单的知识点,这里还是记下来是之前想用到这个特性,却想不起来关键字。工程中应该也会经常用到,但是也没看见相关使用。
static inline 关键字
static
- 修饰局部变量时作用是改变了变量的生命周期(作用域并未改变)。
- 修饰全局变量时作用是限定作用域为当前文件。
- 修饰函数时限定该函数仅作用于当前文件,防止函数同名冲突。
inline : 内联函数(这个标记符仅是向编译器推荐,并不会强制内联,在代码量过多的情况下不会内联成功)。如果内联成功,则类似宏定义一样,会把代码段嵌入调用位置,不同的是内联函数会做编译检查,并且只在运行时才会嵌入代码。对比普通函数调用,代码替换少了入栈、出栈的消耗。
这两个关键词在第三方库中很常见了,特别是 static 。而关于 inline 很早就了解过也用过,只是从当时到现在一直不明白的是,用不用 inline 的界限在哪,如何判断频繁使用和代码量过高?AFNetworking 中很多函数代码也不多使用频率也挺高啊,为什么也都没用呢?而且判断内联成不成功除了看汇编代码也没有找到其他合适的方法。
将对象放到指定 queue 释放
代码如下:
- (void)testSome {
_YYLinkedMapNode *node = CFDictionaryGetValue(_lru->_dic, (__bridge const void *)(key));
[_lru removeNode:node];
dispatch_queue_t queue = _lru->_releaseOnMainThread ? dispatch_get_main_queue() : YYMemoryCacheGetReleaseQueue();
dispatch_async(queue, ^{
[node class]; //hold and release in queue
});
}
上述代码中 node 在被 remove 之后,引用计数变为 0,正常情况下在函数执行完毕就会进入释放池等待释放。这里作者设置了一个 ReleaseQueue 通过 block 捕获 node 来使其引用计数加一, block 里面什么代码无所谓,只是为了增加其引用计数,这样就会把变量释放转移到指定的 queue 中了 。在 iOS 保持界面流畅的技巧 这里有写到这么做的目的:
对象的销毁虽然消耗资源不多,但累积起来也是不容忽视的。通常当容器类持有大量对象时,其销毁时的资源消耗就非常明显。同样的,如果对象可以放到后台线程去释放,那就挪到后台线程去。这里有个小 Tip:把对象捕获到 block 中,然后扔到后台队列去随便发送个消息以避免编译器警告,就可以让对象在后台线程销毁了
经过提示和测试,iOS 11+ 之后,对于 UIKit 的类系统会强制将对象释放过程放在主线程,而其他 NSObject 的类还是在设定的线程中释放。
使用 __unsafe_unretained 节省开销
YYCache 中相关代码如下:
@interface _YYLinkedMapNode : NSObject {
@package
__unsafe_unretained _YYLinkedMapNode *_prev; // retained by dic
__unsafe_unretained _YYLinkedMapNode *_next; // retained by dic
}
之前有提到过,这个类表示每个存储节点。这些节点存储在 _YYLinkedMap 的字典里,所以节点里的 _prev 和 _next 表示相邻节点的指针需要使用弱引用。而用 __unsafe_unretained 不选择 weak 是因为每次释放节点时都会更新该节点的前后节点指针,不存在释放之后访问野指针的情况,所以就使用 __unsafe_unretained 来代替 weak 节省一部分开销。
这里还有作者在 iOS JSON 转模型评测 里的一段话:
在 ARC 条件下,默认声明的对象是 __strong 类型的,赋值时有可能会产生 retain/release 调用,如果一个变量在其生命周期内不会被释放,则使用 __unsafe_unretained 会节省很大的开销。 访问具有 __weak 属性的变量时,实际上会调用 objc_loadWeak() 和 objc_storeWeak() 来完成,这也会带来很大的开销,所以要避免使用 __weak 属性。 创建和使用对象时,要尽量避免对象进入 autoreleasepool,以避免额外的资源开销。
判断是否在主线程
代码中作者用了 pthread_main_np() 方法判断是否在主线程,我们比较常用有两种:
NSThread.isMainThreadstrcmp(dispatch_queue_get_label(DISPATCH_CURRENT_QUEUE_LABEL), dispatch_queue_get_label(dispatch_get_main_queue())) == 0
第一个 API 和作者用的函数基本相同(没找到什么区别),用来判断是否在主线程,但是不能判断在主队列。
第二个 GCD 的比较方法可以判读是否在主队列,主队列一定是在主线程上的。
然后就在想平常有哪些代码是必须在主线程的主队列,又有哪些代码是可以在主线程但不在主队列的呢?
关于这个问题查了一些资料,除了 MapKit 中 addOverlay 方法必须在主队列中,其它没找到必须在主队列的情况。至于在主线程的非主队列的情况,可以自己在主线程开个队列,但是没想出到这样做会有什么好处对上面三个加上 YYCache 库 ,我编写了一些 测试用例 来做了下性能对比,由于这四个库的 API 对我的测试用例支持的并不是很好,我改了一些私有方法为 public。。 😔
Cache In Swift
YYCache 已经很久不更新,作者不知人在何方。至于 Swift 版本,作者也不太可能编写了。关于缓存库网上有开发者对照 YYCache 的思路写了 Swift 版本,也有一些国外开发者开源的库。在 GitHub 简单搜索了一下,列举了一些 Swift Cache 库(还有其他的因为功能和 star 的问题就没列举了):
- Track ,借鉴 YYCache 实现的库 🌟245
- Cache,支持 Codable 协议对象,🌟2.1 K
- Haneke/HanekeSwift,内存缓存用的 NSCache,支持数据从磁盘/网络读取,功能较多。🌟5 K
上面三个加上 YYCache 库 ,编写了一些 测试用例 来做了下性能对比,由于这四个库的 API 对我的测试用例支持的并不是很好,我改了一些私有方法为 public
测试用例:
- 单线程内存写字符串
- 单线程内存读字符串
- 单线程磁盘写字符串
- 单线程磁盘读字符串
- 单线程磁盘写大数据(50k)
- 单线程磁盘读大数据(50k)
测试对象:
- 内存缓存: Dictionary + Lock 、YYMemoryCache、Track.Memory、Cache.Memory、NSCache
- 磁盘缓存:YYDiskCache、Track.Disk、Cache.Disk、Haneke.Disk
测试指标: QPS (吞吐量,越高越好)
测试环境:iPhone X iOS 14, release 模式
内存读写测试结果(纵坐标是 QPS,越高越好):
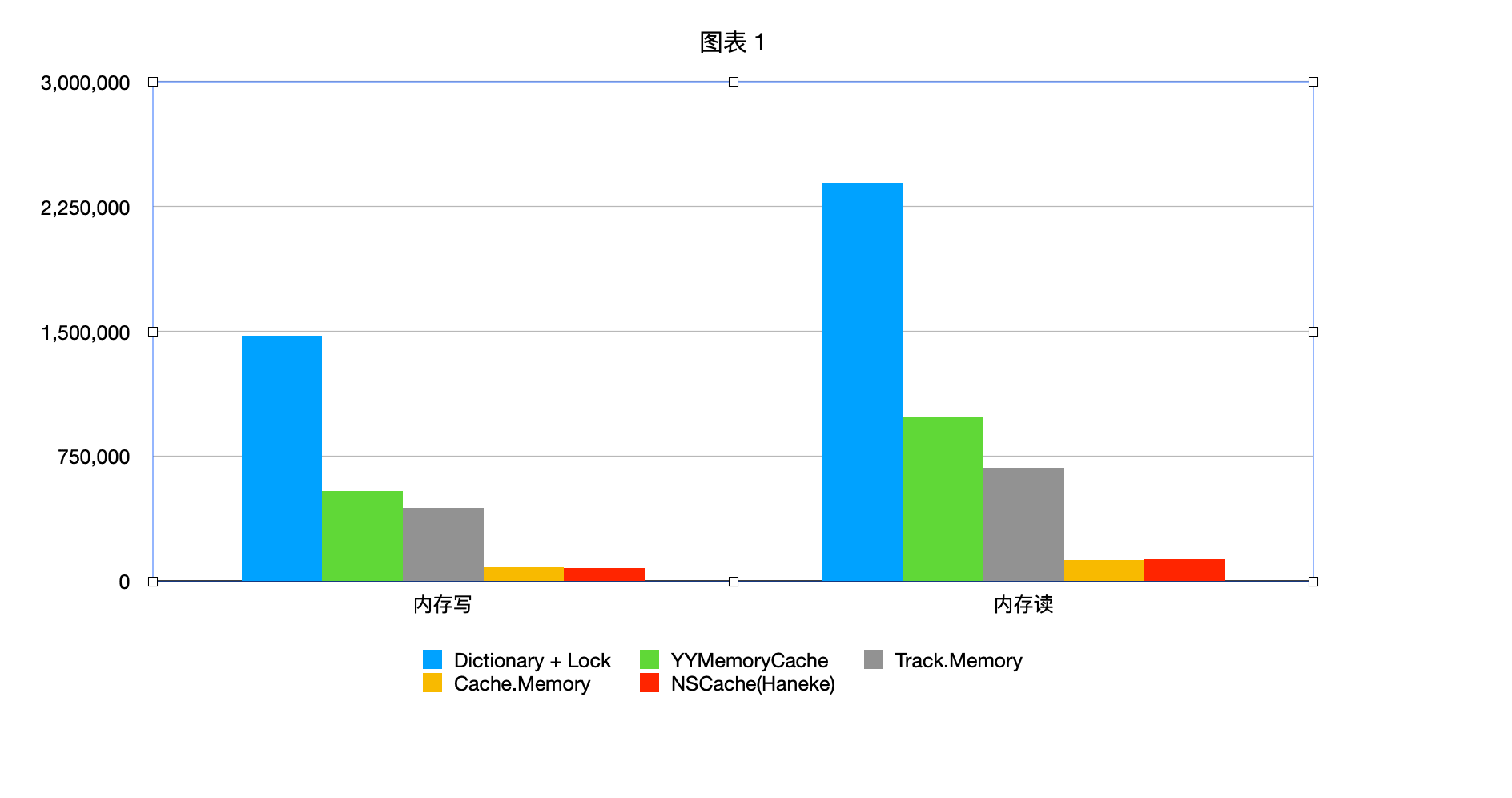
上图中 Dictionary + Lock 性能最高是因为没有加淘汰策略,可以算是天花板了,其他几个对比还是 YYCache 比较高点。NSCache 性能比较低的原因 YY 作者在它的博客有说过(我没查过,不知道对不对):
NSCache 是苹果提供的一个简单的内存缓存,它有着和 NSDictionary 类似的 API,不同点是它是线程安全的,并且不会 retain key。我在测试时发现了它的几个特点:NSCache 底层并没有用 NSDictionary 等已有的类,而是直接调用了 libcache.dylib,其中线程安全是由 pthread_mutex 完成的。另外,它的性能和 key 的相似度有关,如果有大量相似的 key (比如 “1”, “2”, “3”, …),NSCache 的存取性能会下降得非常厉害,大量的时间被消耗在 CFStringEqual() 上,不知这是不是 NSCache 本身设计的缺陷。
磁盘读写测试结果(纵坐标是 QPS,越高越好):
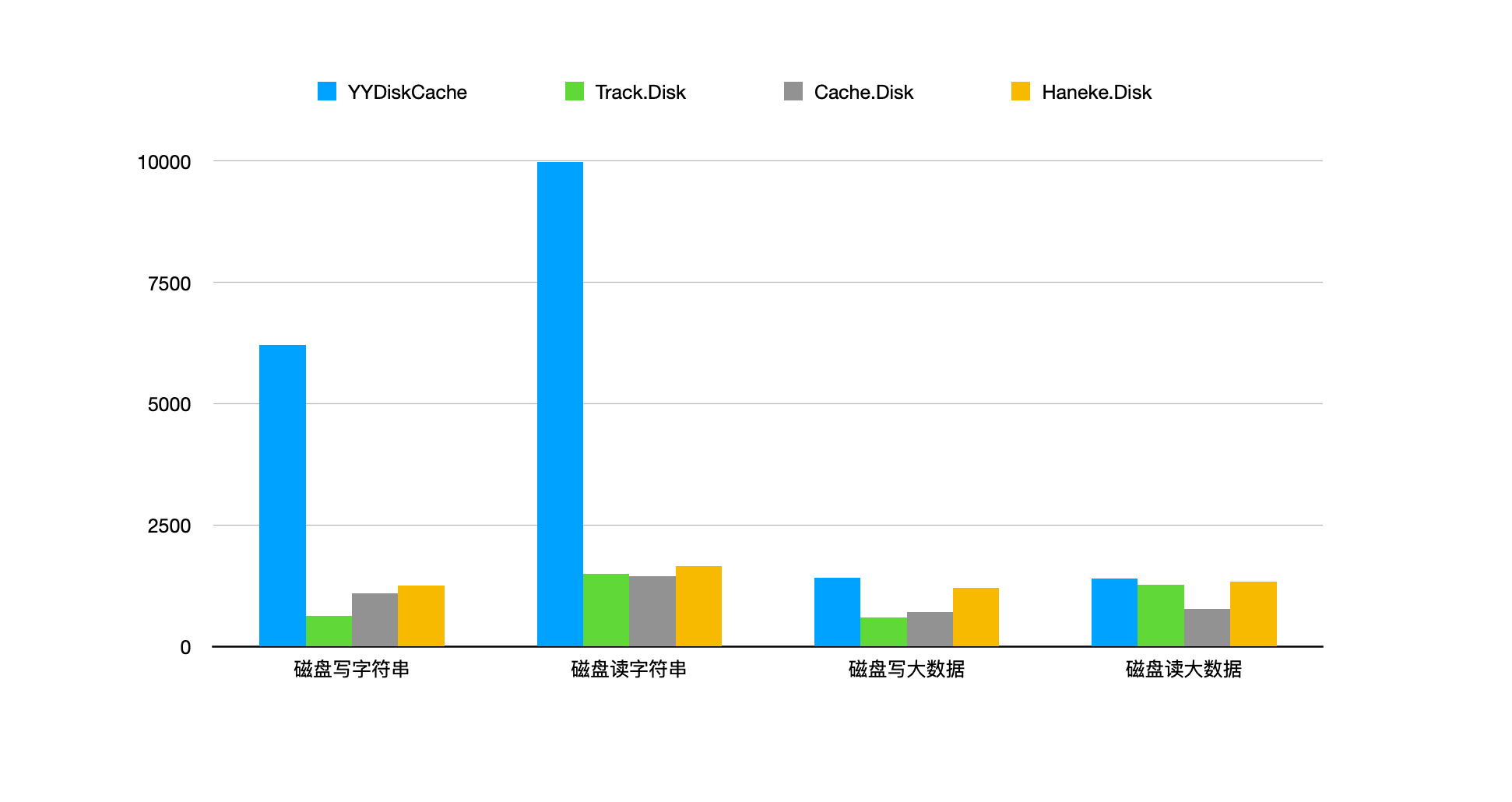
上图中在读写字符串时 YYDiskCache 性能高出很多是因为在数据小的时候 YYDiskCache 采用的是 sqlite 存储,在数据量小的时候数据库在内核中的缓存比文件内核缓存读取速度要快些。当存取大数据时,性能其实已经差不多了。
以上图 QPS 指标以及自己的上手过程来说,在这几个当中还是推荐用最后一个 Haneke/HanekeSwift。首先 YYCache 是五年前的 OC 库了,语法不改的话不能直接调用。Cache 库的 API 个人感觉挺难用的,性能也不佳。至于不选 Track 是觉得直接使用还需 as NSCoding 就很不舒服,没有后者的 API 舒服。
上面的性能对比其实算是很不专业的了,对于这种数据存储的工具库,单一 QPS 指标太过片面,测试用例也太简单。正常情况下还需要测试多线程下存取数据,并考察内存峰值、CPU 峰值、实际磁盘占用空间等指标。但是太麻烦,就没有进行更详细的对比。
一些想法
从分析代码到测试性能等,陆陆续续也花了一段时间,到这里还遗留下一些不解和想法。或者说简单分析了这些缓存库后,我觉得缓存库有些值得思考的点:
- 库最好功能简单,只有数据存取。支持同步、异步,支持自定义模型,尽可能的利用泛型和协议简化 API
- 有没有可能利用值类型和引用类型的特性在性能上做一些细节优化
- 使用锁之前,完善下测试用例,就像之前说的,测试各种锁在多线程资源抢占下的性能
- 设计磁盘存储时,要对比下两个方案:一个是 YYCache 根据数据大小分别使用数据库和文件存储,第二种则是通过 mmap + 临时文件的方式实现。这两种暂时不知道哪个性能会更好
- 写完做测试时,性能指标应该加上 内存峰值、CPU 峰值和实际存储大小这几个项,还有多线程存取等,确保性能指标的可信度。
这里先说下我查到 mmap 相关的资料。通常文件读取过程会将磁盘数据先读取到一个内核缓存中,然后程序内存缓存再从内核缓存中读数据。而 mmap 会直接将磁盘数据映射到程序的内存地址,少了一步内核缓存的交换,所以性能会高点。不过 mmap 有个问题是它是定时将存在程序内存的数据刷回到磁盘,当然也可以强制调用方法写到磁盘。如果每次写到内存时都强制写到磁盘肯定是不合适的,但是等待自动刷回磁盘的话有个问题是如果没到时间或者大小的阈值,进程就被杀死了,内存中的数据就会丢失。
所以有种方法是添加个小容量文件做备份用,当数据写到内存时,同步写到这个备份,当 mmap 自动将数据同步到磁盘时,就删除备份。每次启动时查找备份是否有数据,如果有数据,就将其带入磁盘。
当然这只是了解到的一个做法,我没实现过,看起来思路很清晰,只是不知道性能时候会不会更高。
最后,对 YYCache 感触最深的一点是作者为了性能查阅了很多资料然后去设计和实现一些细节,而不是得过且过,真的很佩服。
