

目录
- 1、场景还原
- 2、名词解释
- 3、实践情况
- 4、个人观点
- 5、引申问题
1、场景还原
面试官:小伙子,听说你会SQL调优,那我这里有一条SQL,你来帮我调优一下。SQL如下: SELECT * FROM T LIMIT 899999, 10;
表结构如下:
id int(10) primary key,
其他字段……
我:¿¿¿(缓缓打出反问号),这条SQL要干嘛,随机找10条数据吗?
面试官:哦,不好意思,忘记加上排序了SELECT * FROM T ORDER BY id LIMIT 899999, 10;
我:如果id是连续不中断的话可以这样写。 SQL如下:SELECT * FROM T where id >= 899999 LIMIT 0, 10;
面试官:那假如id不是连续的呢?
我:(略加思考)单从SQL优化层面我优化不了了。
面试官:……那我们进行下一个话题……
我:……
面试官:那最后你有什么问题想问我的吗?
我:刚才那条SQL从SQL层面上该如何优化?
面试官:你可以这样写:SELECT * FROM T t where t.id >= (SELECT f.id FROM T f ORDER BY id DESC LIMIT 899999, 1) LIMIT 0, 10;
我:(假装略加思考)你确定这样写会比图一这条SQL:SELECT * FROM T ORDER BY id LIMIT 899999, 10;更快吗?在图一的SQL里已经是通过主键索引去查询数据了,你图二的SQL并没有改变原有的查找方式。如果你原有SQL是通过其他字段去排序的,用的是非主键索引,例如:SELECT * FROM T ORDER BY createdTime LIMIT 899999, 10;那么你第二条SQL的写法确实会比第一条SQL快得多,因为在MySQL里非主键索引与主键索引在查找上的区别是,非主键索引他存储的是索引列与主键列的值,查找具体的值还需要一次回表过程,而主键索引存储了是整行数据,不需要再次回表[^①]查找,减少了一次查找过程。
面试官:……
我:……
2、名词解释
回表
指查找时通过非主键索引(非聚簇索引)去查找对应的记录的主键后,仍需要根据主键进行再一次的查找,这是MySQL的索引结构引起的。在MySQL中,主键索引(聚簇索引)存储的是一整行的数据,而非主键索引(非聚簇索引)存储的是主键列的值。
假如有这样一张表
CREATE TABLE person (
id int(11) NOT NULL,
name varchar(32) NOT NULL,
age int(11) NOT NULL,
PRIMARY KEY (id),
KEY idx_person_age (age)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
那这张表的索引具体表现形式如下:
主键索引:
非主键索引:
所以当我们需要查找age=30的数据时,他的查找过程如下图: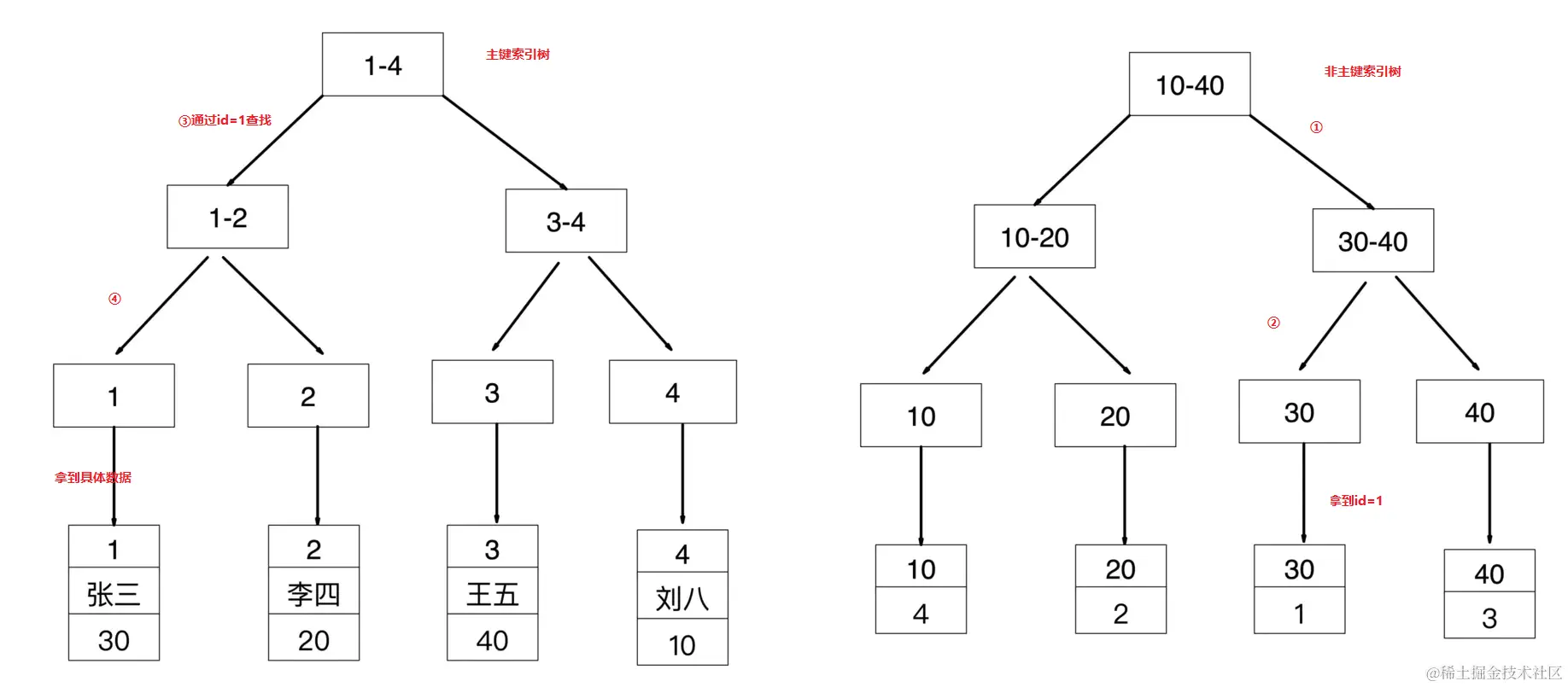
3、实践情况
如今我有这样一张表:
CREATE TABLE file (
id int(11) NOT NULL AUTO_INCREMENT,
name varchar(255) DEFAULT NULL,
created_time datetime NOT NULL,
updated_time datetime NOT NULL,
PRIMARY KEY (id),
KEY idx_file_created_time (created_time) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=954185 DEFAULT CHARSET=utf8mb4;
