1/openpyxl包介绍
penpyxl是一个直接可用于读写 .xlsx .xlsm .xltx .xltm文件的python内置库。
借助它可以利用Python语法对.xlsx文件进行自动化批量操作。
先说一下安装部分,如果小伙伴们用Anaconda作为Python环境的话,openpyxl无需安装可直接使用
如果需要安装的话方法也非常简单 pip install openpyxl
2/.xlsx文件属性
在对Excel表格处理之前,首先需要了解一下.xlsx文件的几个名词解释及构造
<1>Workbook 指的是什么?
Workbook 名叫工作薄,其实你可以立即为就是一个.xlsx文件。
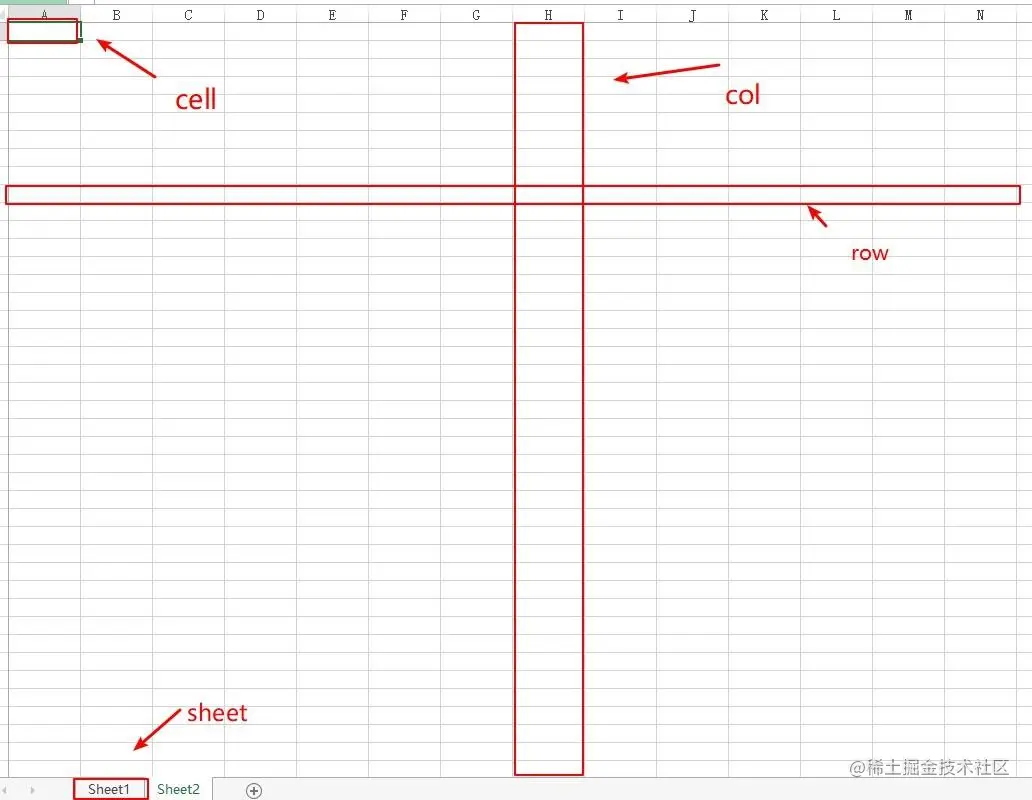
<2>sheet、cell、row 、col 分别指的是什么?
sheet是工作簿中的一张表,也就是说工作簿最少有一张表,可以有多张表.
cell是单元格
row是行数据
col是列数据
3/openpyxl基本命令操作
<1>创建一个空的workbook
from openpyxl import Workbook
from openpyxl.utils import get_column_letter
workbook = Workbook()
sheet1 = workbook.active
<2>创建新的 worksheet
sheet1 = workbook.create_sheet("Mysheet")
sheet2 = workbook.create_sheet("Mysheet", 0)
sheet3 = workbook.create_sheet("Mysheet", -1)
<3>更改sheet的名字
一行代码即可
sheet1.title = "New Title"
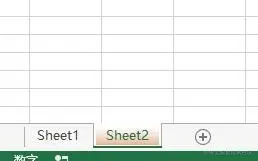
<4>更改sheet上tab背景颜色
sheet1.sheet_properties.tabColor = "1072BA"
通过修改 Wroksheet.sheet_properties.tabColor 参数即可,需要注意的是这里只接收 RRGGBB 颜色代码;
关于不清楚 sheet tab 背景颜色不清楚是什么的小伙伴,可参考下图:
<5>返回Workbook中所有sheet的名字
通过 Workbook.sheetname 命令即可查看
>>> print(workbook.sheetnames)
['Sheet2', 'New Title', 'Sheet1']
>>> for sheet in wb:
... print(sheet.title)
<6>将现有的sheet复制新创建的workbook中
可通过 Workbook.copy_worksheet()函数方法
source = workbook.active
target = workbook.copy_worksheet(source)
<7>获取某个cell的数据一级修改某个cell的值
我们在创建完 Workbook、sheet 之后,接下来就可以修改cell。
#获取第4行列名为A单元格中的值
c = sheet1['A4']
#通过赋值命令对其修改
sheet1['A4'] = 4
openpyxl 中有一个函数 Worksheet.cell() 可修改单元格中的数据,可定位到具体行、具体列进行更改,
d = sheet1.cell(row=4,columns=2,value=10)
row 表示指定行
columns 表示指定列
value 表示该单元格中需替代的数据值;当此参数不设置时表示只对该 cell 创建内存空间,不赋值
例如
for x in range(1,101):
for y in range(1,101):
ws.cell(row=x, column=y)
4/读写文件操作
from openpyxl import load_workbook
wb1= load_workbook('../data/test.xlsx')
print(wb1.sheetnames)
wb1 = Workbook()
wb1.save('balances.xlsx')
5/openpyxl和dataframe结合
from loguru import logger
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
import pandas as pd
data_df = pd.DataFrame(data=[ [11,22,33],[44,55,66],[77,88,99] ],
columns=list('abc'))
print(data_df)
my_wb = Workbook()
sheet1 = my_wb.active
for r in dataframe_to_rows(data_df,index=False,header=True):
sheet1.append(r)
my_wb.save("../data/text22.xlsx")
logger.info("数据文件保存完成!!!")


