写在前面:RFM模型分析在当下已经是非常常见的了,广泛运用与电商或传统商业提高自己的利润总量。什么是RFM模型?即通过分析一个客户的近期购买行为、购买的总体频率以及花费多少钱等3项指标来描述该客户的价值状况。该算法是其中之一参考度是频率,即从最简单也是最容易想到的角度出发,研究如何从客户角度来推销更多产品,而之前学习的挖掘算法都是基于产品的角度。
Discovering valuable frequent patterns based on RFM analysis without customer identification information
样例
定义
- 交易项集 T={ti,(x1,qx1),…,(xm,qxm},其中 t 表示该交易项集发生的时间,x 表示项(商品),qxj 表示内部效用(商品购买量)
- 频繁度分值(Frequency score):相当于以前的支持度 sup(X),该文中使用 FScoreDB(X) 表示。不同的是,该支持度必须符合 FScore(X)≥∣DB∣×α 才能把该项集 X 当作是 F-pattern(其中 α 是阈值,∣DB∣ 表示数据集中包含的总交易项数量)
- 利润分值(Monetary score):相当于以前的效用值 u(X),该文中使用 MScore(X,Tj) 表示在交易项 Tj 中该项集 X 的利润分值,定义式为 MScore(X,Tj)=∑xi∈X∧X⊆Tjp(xi)×qxi。更进一步,项集 X 在整个数据集中的利润分值定义为 MScore(X)=∑Tj∈DB。当 MScore(X)≥β 时,我们认定该项集是 M-pattern(其中 β 是设置的阈值)
- 近期分值(Recency score):在交易项集 Tj 内,项集 X 存在,定义为 RScore(X,Tj)=(1−δ)timecurrent−timeTj(其中 δ∈(0,1) 是设定的衰减速度),更进一步,项集 X 在整个数据集中的近期分值定义为 RScore(X)=∑Tj∈DBRScore(X,Tj)。当 RScore(X)≥γ 时,我们认定该项集是 R-pattern (其中 γ 是设定的阈值)
Ps. 当某个项集 X 满足以上三个度量分值都不小于各自设定的阈值时候,我们认定该项集是 RFM-pattern
- 项集的交易项效用值(Transaction utility)类似于以前的 tu(X,Tj),该文中定义为 ta(X,Tj)=∑xi∈Tj∧X⊆Tjp(xi)×qxi,更进一步,项集 X 在整个数据集中的总交易项效用值定义为 ttaDB(X)=∑Tjta(A,Tj)
Ps. 当某个项集 X 满足 FScore(X)≥∣DB∣×α,ttaDB(X)≥β,RScoreDB(X)≥γ,那么我们认定该项集是 RFT-pattern (类似于使用 TWU 筛选出候选项集,即需要进一步确认的项集)
性质
-
设 SRFM 和 SRFT 分别代表 RFM-pattern 集和 RFT-pattern 集,那么有 SRFM⊆SRFT
证明:
根据 MScore(X,Tj),ta(X,Tj) 的定义,我们很容易得出 ∑xi∈Tjp(xi)×qxi≥∑xi∈Xp(xi)×qxi(因为 X⊆Tj)进而 ttaDB(X)≥MScoreDB(X)。可知当项集 X 是 RFM-pattern 时,必然是 RFT-pattern
-
当一个项集是 RFT-pattern,那么它的任何子集依然会是 RFT-pattern(向下封闭性)
证明:
设项集 X,X′ 是 R-pattern 和 F-pattern,且 X′⊂X。自然有 TX⊂TX′(反过来看 X 是 X′ 的扩展集,那么包含 X′ 的交易项集不一定包含 X)即 ttaDB(X′)≥ttaDB(X),得证
-
略
算法
构造 RFM-pattern-tree:

构造 RFM-header-tree 伪代码:计算方式和之间计算 1-utility-list 是一样的,一层层遍历交易项 Ti,一层层把本轮遍历计算出来的结果添加到表中,伪代码如下:

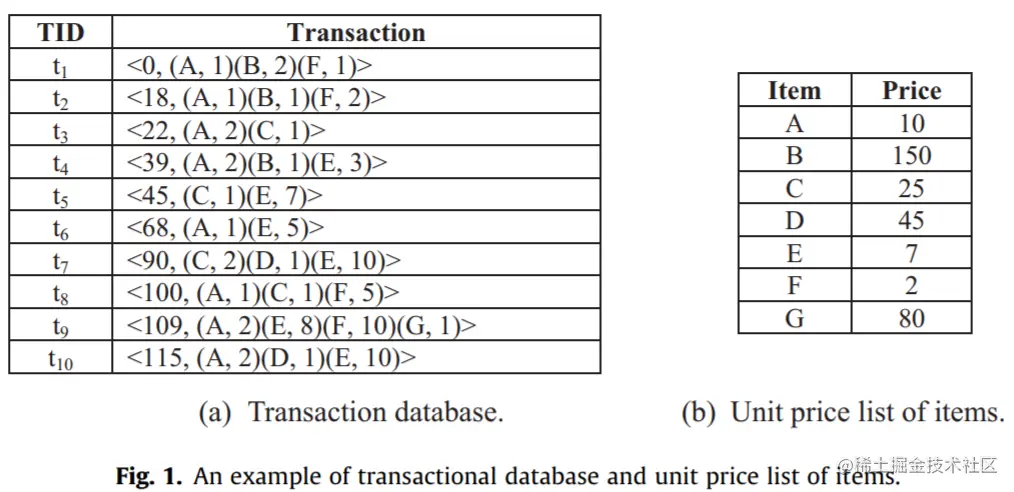
以下演示根据样例数据集计算,我们假设 α=10%,β=100%,γ=0.95%,δ=0.01%,tcurrent=115,遍历 T1 可以得到 RScoreDB(T1)≈0.315,FScoreDB(T1)=1,ttaDB(T1)=312,即下表:
| item-name | RScore | FScore | tta | link |
|---|
| A | 0.315 | 1 | 312 | |
| B | 0.315 | 1 | 312 | |
| F | 0.315 | 1 | 312 | |
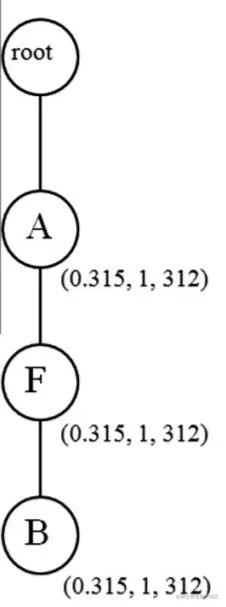
遍历交易项 T2 可以得到 RScoreDB(T2)≈0.377,FScoreDB(T2)=1,ttaDB(T2)=164,即下表:
| irem-name | RScore | FScore | tta | link |
|---|
| A | 0.692 | 2 | 476 | |
| B | 0.692 | 2 | 476 | |
| F | 0.692 | 2 | 476 | |
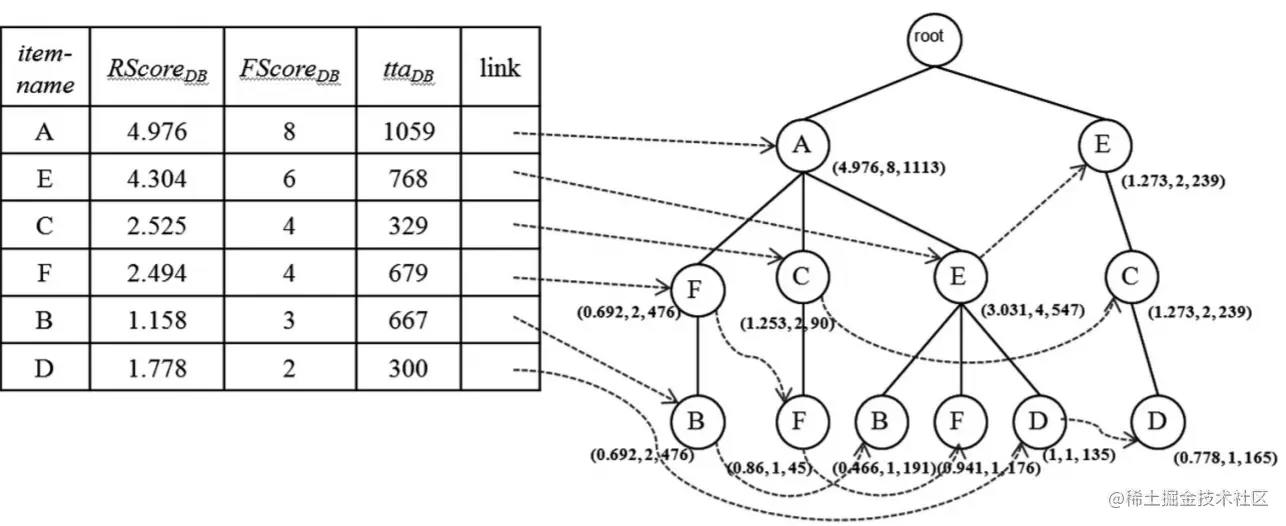
...依次计算各交易项,最终得到下表(已进行过滤且按照 FScore 降序排列):
| item-name | RScore | FScore | tta | link |
|---|
| A | 4.976 | 8 | 1059 | |
| E | 4.304 | 6 | 768 | |
| C | 2.525 | 4 | 329 | |
| F | 2.494 | 4 | 679 | |
| B | 1.158 | 3 | 667 | |
| D | 1.778 | 2 | 300 | |
构造 RFM-pattern-tree 伪代码:

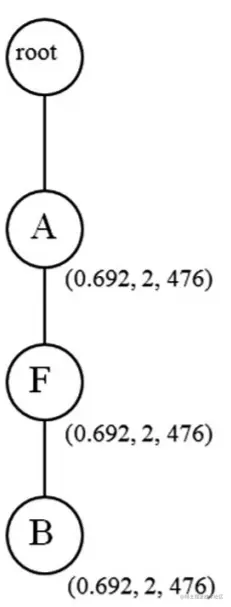
以下演示继续计算,遍历交易项 T1 时,可以得到 RScoreDB(T1)≈0.315,FScoreDB(T1)=1,ttaDB(T1)=312,分别创建三个子节点:insert_node([A|FB], root, 0.315, 312),insert_node([F|B], A, 0.315, 312),和 insert_node([B|- null], B, 0.315, 312) 排序后如下图(左)所示(Ps. 文中特别强调了在创建节点后需要立即建立相应的索引);遍历交易项 T2 时,可以得到 RScoreDB(T2)≈0.377,FScoreDB(T2)=1,ttaDB(T2)=164,由于节点已经存在,所以直接相加重新赋值,下图(中)所示;遍历交易项 T3 时,可以得到 RScoreDB(T3)≈0.393,FScoreDB(T3)=1,ttaDB(T3)=45,因为节点 C 在 A 后面,所以新开一条分支,如下图(右)所示:
...经过多次计算,可以得到最终结果如下图(构造流程也可以参考FP-Tree):
RFMP-growth 算法伪代码:

tree-growth 算法伪代码:

总结
该算法基于之前的FP-Growth算法改进而成,需要注意的是由于衡量标准的增多,算法在一定程度上需要多次扫描数据集,如何设计一个好的数据结构是比较重要的,再者Up-Growth是对FP-Growth的改进,那么是否能对RFMP-Growth进行改进呢?


