一、what?why?
限流是保护高并发系统三种最有效的方式之一,另外两个是缓存和服务降级。
通过控制发送到网络的流量的数量和速率,调节数据传输速率并减少拥塞,在高并发的流量下,保护自己和下游系统。
二、限流的策略
限流的目的是通过对并发访问进行限速,相关的策略一般是,一旦达到限制(速率、或失败率、或者排队时间等等),那么就会触发相应的限流行为。一般来说,触发的限流行为如下:
拒绝服务
把多出来的请求拒绝掉。一般来说,好的限流系统在受到流量暴增时,会统计当前哪个客户端来的请求最多,直接拒掉这个客户端,这种行为可以把一些不正常的或者是带有恶意的高并发访问挡在门外。
服务降级
关闭或是把后端服务做降级处理。这样可以让服务有足够的资源来处理更多的请求。降级有很多方式,一种是把一些不重要的服务给停掉,把 CPU、内存或是数据的资源让给更重要的功能;一种是不再返回全量数据,只返回部分数据。因为全量数据需要做 SQL Join 操作,部分的数据则不需要,所以可以让 SQL 执行更快,还有最快的一种是直接返回预设的缓存,以牺牲一致性的方式来获得更大的性能吞吐。
特权请求
所谓特权请求的意思是,资源不够了,我只能把有限的资源分给重要的用户,比如:分给权利更高的 VIP 用户。在多租户系统下,限流的时候应该保大客户的,所以大客户有特权可以优先处理,而其它的非特权用户就得让路了。
延时处理
在这种情况下,一般会有一个队列来缓冲大量的请求,这个队列如果满了,那么就只能拒绝用户了,如果这个队列中的任务超时了,也要返回系统繁忙的错误了。使用缓冲队列只是为了减缓压力,一般用于应对短暂的峰刺请求。
弹性伸缩
动用自动化运维的方式对相应的服务做自动化的伸缩。这个需要一个应用性能的监控系统,能够感知到目前最繁忙的 TOP 5 的服务是哪几个。然后去伸缩它们,还需要一个自动化的发布、部署和服务注册的运维系统,而且还要快,越快越好。否则,系统会被压死掉了。当然,如果是数据库的压力过大,弹性伸缩应用是没什么用的,这个时候还是应该限流。
三、限流的实现方式
3.1 限速器
3.1.1 静态限速器
3.1.1.1 Leaky Bucket
这是一个漏桶算法的示意图,详情可以查看wiki词条[Leaky Bucket](https://en.wikipedia.org/wiki/Leaky_bucket)

假设我们有一个桶,我们以变化的速度向里面倒水(bursty flow),但必须以固定的速度取水(fixed flow),为此,我们将在桶的底部开一个孔。 这将确保桶中的水以一定的速度流出,如果桶装满了水,我们将停止倒水(拒绝服务或者降级处理)。
输入速率可以变化,但是输出速率保持恒定。 在网络中,“漏桶”的技术可以消除突发流量,在流量过载的情况下保护后端,防止发生雪崩。
一般可以用FIFO的队列去实现,流程如下图:

3.1.1.2 Token Bucket
关于令牌桶算法的示意图如下,详情可以查看wiki词条[Token Bucket](https://en.wikipedia.org/wiki/Token_bucket)

在一个桶内按照一定的速率放入一些 token,然后,处理程序要处理请求时,需要拿到 token,才能处理;如果拿不到,则不处理(拒绝服务或者降级处理)。
3.1.1.3 两种经典算法比较
| LEAKY BUCKET | TOKEN BUCKET |
| When the host has to send a packet , packet is thrown in bucket. | In this leaky bucket holds tokens generated at regular intervals of time. |
| Bucket leaks at constant rate | Bucket has maximum capacity. |
| Bursty traffic is converted into uniform traffic by leaky bucket. | If there is a ready packet , a token is removed from Bucket and packet is send. |
| In practice bucket is a finite queue outputs at finite rate | If there is a no token in bucket, packet can not be send. |
Token bucket在某种程度上允许突发流量,而Leaky bucket主要用于确保平滑流量。
更多请查看《[Detailed Explanation of Guava RateLimiter's Throttling Mechanism](https://www.alibabacloud.com/blog/detailed-explanation-of-guava-ratelimiters-throttling-mechanism_594820)》
3.1.1.4 开源限速器
《[Google Guava RateLimiter](https://guava.dev/releases/19.0/api/docs/index.html?com/google/common/util/concurrent/RateLimiter.html)》基于Token bucket算法的java限流器
《[Uber go/ratelimit](https://github.com/uber-go/ratelimit)》基于Leaky bucket算法的golang限流器
《[golang.org/x/time/rate](http://golang.org/x/time/rate) [Limiter](https://godoc.org/golang.org/x/time/rate#Limiter)》golang官方提供的Token bucket算法的限流器
3.1.2 动态限速器
产生的背景
静态限速算法简单易用,成本很低的同时效果也比较明显。
这里静态的含义是,限流器里面的参数,比如说Leaky bucket里面的放水速率,Token bucket里面的token放入速率,bucket容量等,这些参数在使用的时候是写死的,不能动态感知或者调节。
那么这些参数我们在具体使用的时候需要设置为多少呢?
这确实是一个比较头痛的问题,一般我们通过对指定的硬件配置(CPU、内存、网络带宽等)做性能测试,找到最大的TPS/QPS,作为参数设置的基准。即使是这样,分布式系统下环境复杂多变,比如说依赖的redis或者db出了问题,比如说集群实例扩容、缩容了等等,我们压测出来的QPS就不再可靠,限流的策略也会发生很大的问题。
来看一下gitbug上对应的问题《[Possible to create a dynamic rate limiter?](https://github.com/resilience4j/resilience4j/issues/174)》

怎么解决这些问题呢?
1)人工修改动态配置--半自动化,参数放在动态配置中心,出现特定情况时,人工判断修改
2)动态限流器--全自动化的终极解决方案(但实现复杂)
基本介绍
核心思路:动态地感知系统的压力,自动化地限流。
基于系统动态运行的指标,比如说自身的CPU使用率和内存使用率、调用后端实时检测的超时率和异常率等,动态的估算自身或者后端实时能承受的QPS,在外界条件发生变化时,可以动态的调节,无需人工介入即可良好的运作。
算法实现
a.初始状态
定义流量控制窗口window,初始值为confidence(可以通过压测获取,或者选一个合适的随机数),如下所示:
window_(t) = confidence, where t = 0
再定义一个window的上限threshold(距离压测得到的QPS不要太远),比如2倍confidence:
threshold_(t) = 2 * confidence, where t = 0
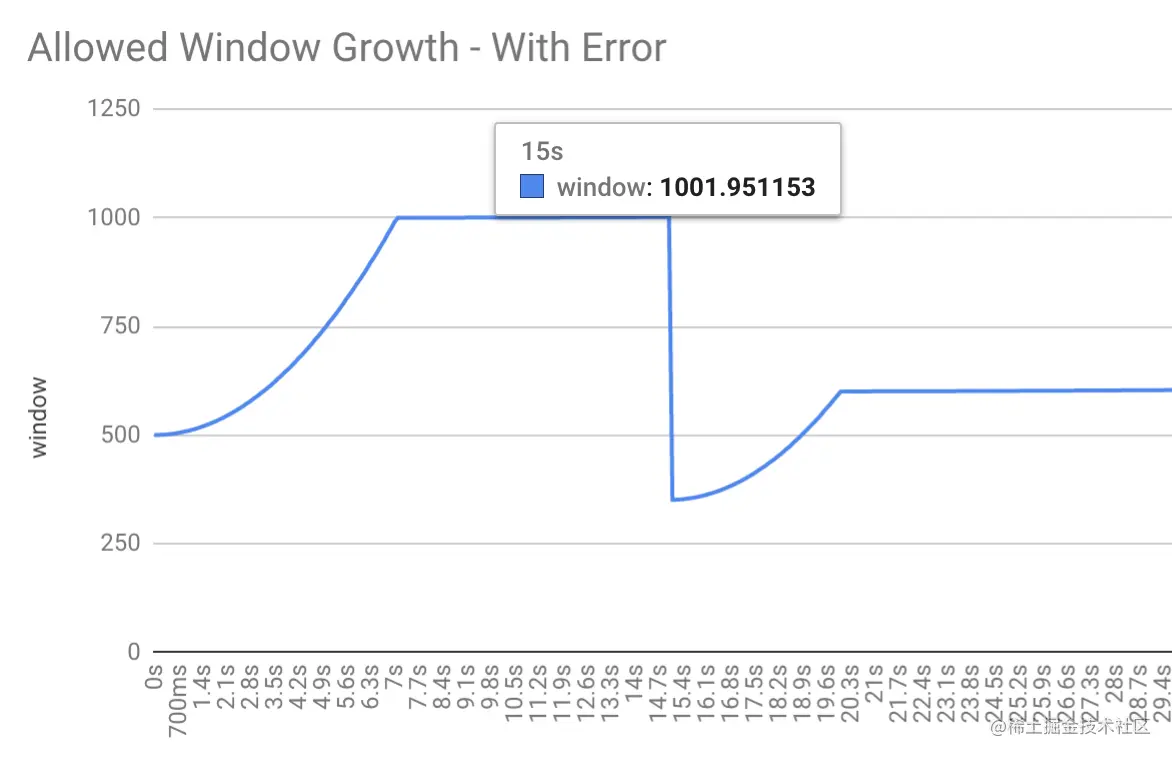
b.窗口增大Window growth:
快增长:window incremental: (on success, before reaching threshold)
window_(t) = window_(t-1) + (α * success_weight(t))
慢增长:
slow incremental: (on success, after reaching threshold)
window_(t) = window_(t-1) + (α * success_weight(t)) / window_(t-1)
这是window growth的一个案例图:

c.窗口减小Window drop:
w_drop = array(confidence * 2, .....)
w_drop = append(w_drop, rps_drop)threshold_(t) = sum(w_drop) / len(w_drop)
具体实现包括参数的含义可以参考《Designing Simple & Dynamic Rate Limiter In Golang》,这里主要阐述思想,不对细节做过多介绍。
上面的算法遗留了一个关键问题。怎么定义发生了拥塞以及拥塞恢复?
可以统计一个时间窗口(比如3s)的超时率,如果有超过0.01%的请求超时,则认为发生了拥塞,否则认为拥塞恢复(正常状态)。还有没有更好的办法?答案是通过超时时间的值提前判断,不必等到真正超时———提升灵敏度。
这里的统计通常是比较消耗cpu的。
小结:基于流控窗口的动态限流算法,借鉴了TCP协议的拥塞控制算法,窗口增大和增小的细节以及策略可以自行定义,简单的有直接在基准上增减百分比的,复杂的有上述描述的快增长、慢增长、乘法减小等分阶段定义的。
3.2 熔断器
3.2.1 熔断器简介
为了保护本服务,当下游出现问题的时候,比如调用下游服务错误率飙升,这个时候触发熔断,会随机丢弃,甚至停止对下游的请求,以防止被下游拖挂,完全雪崩无法启动。
它的灵感来源于我们电闸上的“保险丝”,当电压有问题时(比如短路),自动跳闸,此时电路就会断开,我们的电器就会受到保护。不然,会导致电器被烧坏,如果人没在家或是人在熟睡中,还会导致火灾。所以,在电路世界通常都会有这样的自我保护装置。
3.2.2 状态机实现熔断
熔断器可以看成是可能失败的操作的代理。代理应监视最近发生的故障数,然后使用此信息来决定是允许操作继续进行,还是直接返回异常。 可以将代理程序实现为具有以下状态的状态机,该状态机可以模拟断路器的功能:
闭合(Closed)状态:
我们需要一个调用失败的计数器,如果调用失败,则使失败次数加 1。如果最近失败次数超过了在给定时间内允许失败的阈值,则切换到断开 (Open) 状态。此时开启了一个超时时钟,当该时钟超过了该时间,则切换到半断开(Half-Open)状态。
断开 (Open) 状态:
在该状态下,对应用程序的请求会立即返回错误响应,而不调用后端的服务。
半开(Half-Open)状态:
允许应用程序一定数量的请求去调用服务。如果这些请求对服务的调用成功,那么可以认为之前导致调用失败的错误已经修正,此时熔断器切换到闭合状态,同时将错误计数器重置。如果这一定数量的请求有调用失败的情况,则认为导致之前调用失败的问题仍然存在,熔断器切回到断开状态,然后重置计时器来给系统一定的时间来修正错误。半断开状态能够有效防止正在恢复中的服务被突然而来的大量请求再次拖垮。

更多细节可以参考《熔断器模式设计》[https://docs.microsoft.com/en-us/previous-versions/msp-n-p/dn589784(v=pandp.10)](https://docs.microsoft.com/en-us/previous-versions/msp-n-p/dn589784(v=pandp.10))
3.2.3 开源实现
gobreaker:[https://github.com/sony/gobreaker](https://github.com/sony/gobreaker)
go-circuitbreaker :[https://github.com/mercari/go-circuitbreaker](https://github.com/mercari/go-circuitbreaker)
3.3 其他过载判断方式
限速器主要是基于QPS判断是否过载,熔断器主要是通过判断下游链路的失败数或者失败率判断是否过载,我们把基于其他方式判断是否过载的统称为-其他方式过载判断方式
过载控制是服务器发现自己的处理能力不足,为了防止情况恶化甚至雪崩,而随机/或按照某些规则丢弃一定数量请求的行为。这里的判断依据主要是针对自身处理能力,如下:
队列等待时间、吞吐量、请求处理时延、内存利用率、CPU利用率等等纬度;
队列等待时间 = 请求开始被处理的时刻 - 请求到达此服务的时刻。
四、业界限流介绍
4.1 微信过载控制
《[Overload Control for Scaling WeChat Microservices](https://arxiv.org/abs/1806.04075?from=timeline&isappinstalled=0)》
《[微信微服务过载控制论文总结](https://bytedance.feishu.cn/docs/5FyZC9Ee0c34roxDey2Ybc)》
介绍了DAGOR, 一种应用于面向账户的(account-oriented)微服务架构的过载控制系统设计。
DAGOR对服务内部是无感知的。它在微服务的粒度上管理过载,使得每个微服务的负载状态能够被实时监控,并在检测到过载时,以协作的方式触发负载丢弃。DAGOR已经用于微信五年之久。实验表明DAGOR在系统过载的情况下,可以提高服务的成功率,同时还能保证过载控制的公平性。
它的基本机制是:当一个client请求到达时,它会被分配一个业务优先级和一个用户优先级,根据这个优先级使得它下游所有的服务可以强制接受或者拒绝这个请求。每个微服务都有自己的一个优先级阈值,来决定是否接受请求,并且他们都通过检查系统层级的指标来监控自己的load状态,比如这个指标可以是请求的平均处理时延。如果某个微服务检测到了过载,这个微服务通过调整优先级阈值(阈值有一套调整算法)来试图减少负载。同时,微服务也会通知它的直接上游服务这个阈值改变的消息,使得客户端的请求可以被更早的层级就被拒绝掉。
--------------------------------------------------------------------------------协作型的过载控制体系
如何判断过载?
使用排队时间来检测过载。微信中平均queuing time的阈值是20ms,queuing time 超过20ms就意味着本服务过载了。
过载后的处理策略
优先级策略:
当一个服务过载时,它的服务拒绝机制将会丢弃低优先级的服务,省出资源给高优先级服务。一个用户请求的业务优先级(同时也是它后续调用链一系列service请求的业务优先级)由入口服务中要执行的动作类型决定。
业务优先级 + 用户优先级 (自动化算法)
工作流程

1、当用户请求到达微服务系统时,它被路由到相关的入口服务。 入口服务将业务和用户优先级分配给请求,并且对下游服务的所有后续请求继承了封装到请求头中的相同优先级。
2、每个服务根据业务逻辑调用一个或多个下游服务。 服务请求和响应通过消息传递提供。
3、当服务收到请求时,它会根据当前的准入级别执行基于优先级的准入控制。 该服务根据负载状态定期调整其准入级别。 当服务想要发送后续请求给下游服务时,它根据存储的下游服务的准入级别执行本地准入控制。 上游业务只发出本地准入控制允许的请求。
4、当下游服务向上游服务返回效应时,它将其当前的准入等级附加到响应消息。
5、当上游服务收到响应后,从消息中提取准入等级的信息,并相应地更新下游业务的相应本地记录。
五、总结
1、限流对于分布式系统的高可用至关重要,能够在突发流量或者系统异常时,保护系统,避免雪崩;常见的手段包括:限速器、熔断器和其他过载检测控制机制。
2、常见的限速器主要由静态算法实现,包括漏桶算法和令牌桶算法,简单、粗暴、有效,但在使用时参数写死,特定的情况下会出问题;动态算法能够动态地感知系统的压力,自动化地限流,典型的可以参考TCP的拥塞控制算法实现。虽然算法稍复杂,但具备效果好和自动化的优点,是一种综合评价比较高的限流方法。
3、熔断模式灵感来源于电路“保险丝”,通常由状态机实现,在下游链路出现问题的时候,可以自我保护;
4、除了限速器的QPS、熔断的失败率检测方式,还存在一些其他的方式,比如判断排队时间、CPU、内存、时延和吞吐量等,业界经验表面,排队时间是比较靠谱的。
5、发生流控后,常见的处理策略有拒绝服务或者服务降级,这里面可以区分KA用户和普通用户,提供不一样的处理策略;


