本系列是台湾大学资讯工程系林軒田(Hsuan-Tien Lin)教授开设的《机器学习基石》课程的梳理。重在梳理,而非详细的笔记,因此可能会略去一些细节。
该课程共16讲,分为4个部分:
- 机器什么时候能够学习?(When Can Machines Learn?)
- 机器为什么能够学习?(Why Can Machines Learn?)
- 机器怎样学习?(How Can Machines Learn?)
- 机器怎样可以学得更好?(How Can Machines Learn Better?)
本文是第3部分,对应原课程中的9-12讲。
本部分的主要内容:
- 线性回归算法详解,以及泛化能力的保证、能否用于二分类问题等;
- 逻辑回归算法详解,并引入梯度下降方法;
- 阐述PLA、线性回归、逻辑回归3种方法在分类问题上的联系与区别,并引入随机梯度下降方法;
- 多分类问题中的OVA、OVO方法;
- 特征的非线性变换,以及该如何控制变换后的复杂度。
1 线性回归
在第一部分中讲过机器学习的分类,当Y=R时,就是回归。
1.1 线性回归算法
线性回归的假设集十分简单,h(x)=wTx,其实就是感知机模型去除了符号函数。
它的逐点误差度量可设为err(y^,y)=(y^−y)2,那么样本内外的误差分别为
Ein(w)=N1n=1∑N(wTxn−yn)2
和
Eout(w)=(x,y)∼PE(wTx−y)2
要最小化Ein很简单,当它取到最小时必有梯度为0,因此可先计算出它的梯度:
∇Ein(w)=N2(XTXw−XTy)
令它为0即可。如图所示:
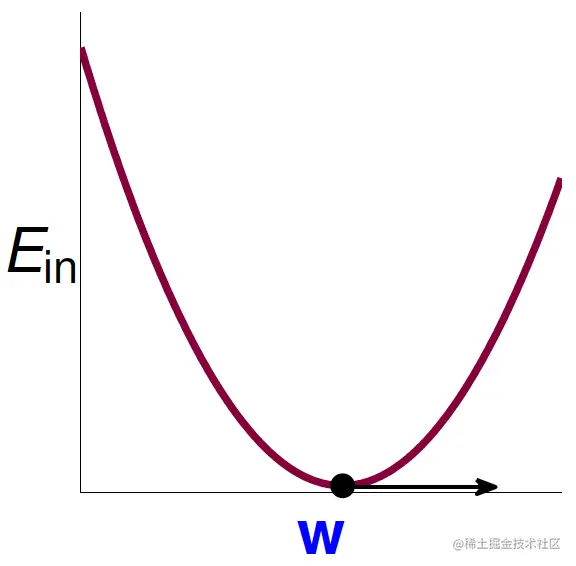
若XTX可逆(当N≫d+1时基本上会满足),则可直接得出
wLIN=(XTX)−1XTy
如果XTX是奇异的呢?可先定义“伪逆”(pseudo-inverse)X†,在定义完后有
wLIN=X†y
在实践中,建议直接使用X†,一方面可避免判断XTX是否可逆,另一方面就算在几乎不可逆的情况下,它也是在数值上稳定的。
1.2 线性回归的泛化
线性回归看起来没有“学习”过程,是一步到位的,那么它算机器学习吗?
事实上,只要可以保证Eout(wLIN)足够小,那么就可以说“发生了”学习。
在这里,我们不从VC维理论出发,而从另一个角度说明为什么Eout(wLIN)会足够小。
我们先来看平均的Ein有多大:
Ein=D∼PNE{Ein(wLIN w.r.t D)}
其中
Ein(wLIN)=N1∥y−y^∥2=N1∥(I−XX†)y∥2
可将H=XX†称为hat matrix,因为它可将y映射到y^。由下图可知,若y由理想的f(X)∈span加上噪声noise生成,那么I−H也可将noise映射为y−y^:
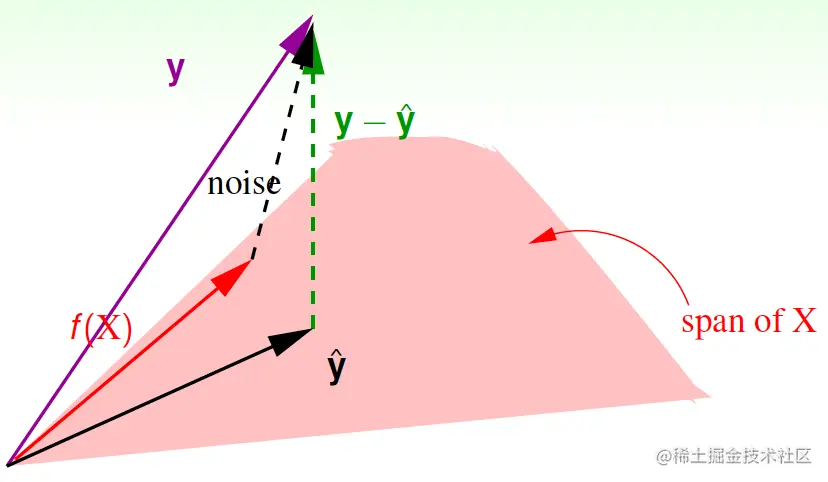
而trace(I−H)=N−(d+1),迹可以理解为“能量”,因此有
Ein(wLIN)=N1∥y−y^∥2=N1∥(I−H)noise∥2=N1(N−(d+1))∥noise∥2
如果对Ein取平均,大概可以理解为
Ein=noise level⋅(1−Nd+1)
类似地有
Eout=noise level⋅(1+Nd+1)
(证明过程略)。
因此Ein和Eout的关系如图:
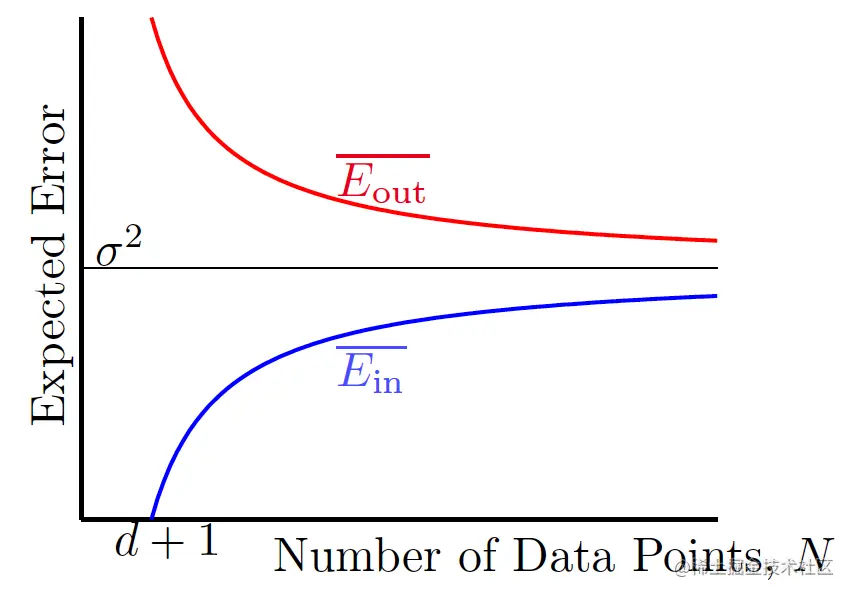
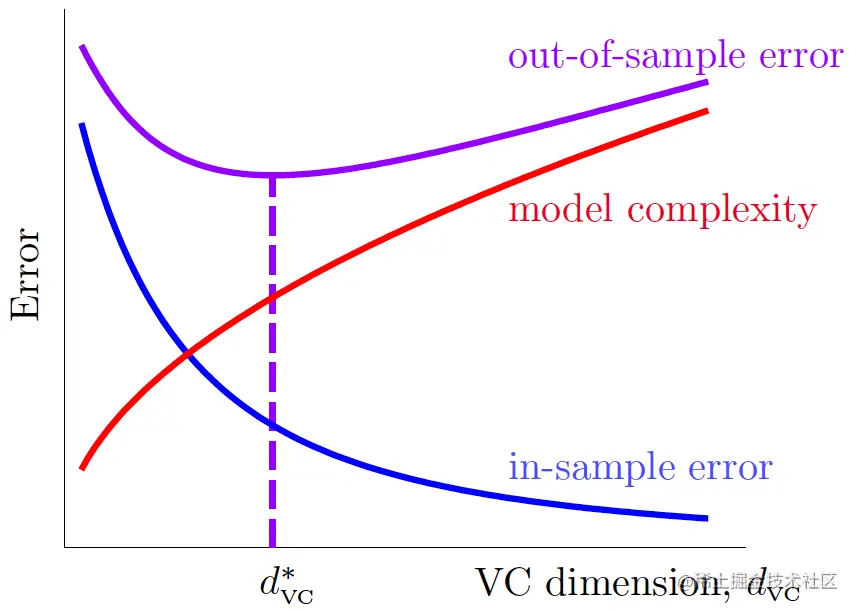
若N→∞,则二者都收敛于σ2(noise level),泛化误差的期望为N2(d+1)。因此,学习是会“发生”的!
VC维理论说明的是Ein和Eout相差较远的概率有上限,而这里说明的是它们的平均差距会收敛。角度不同,但两种方式都说明了泛化的能力。
1.3 用线性回归进行二分类
在线性分类中,Y={+1,−1},h(x)=sign(wTx),err(y^,y)=1[y^=y],找它的最优解是个NP-hard问题。
由于{+1,−1}⊂R,即样本的正负类别也能用实数表示,而在线性回归中Y=R,那么,直接来一发线性回归,得到wLIN,然后让g(x)=sign(wLINTx),这是否可行呢?
把线性分类和线性回归的误差度量分别记为err0/1=1[sign(wTx)=y]和errsqr=(wTx−y)2,它们的关系如下图:
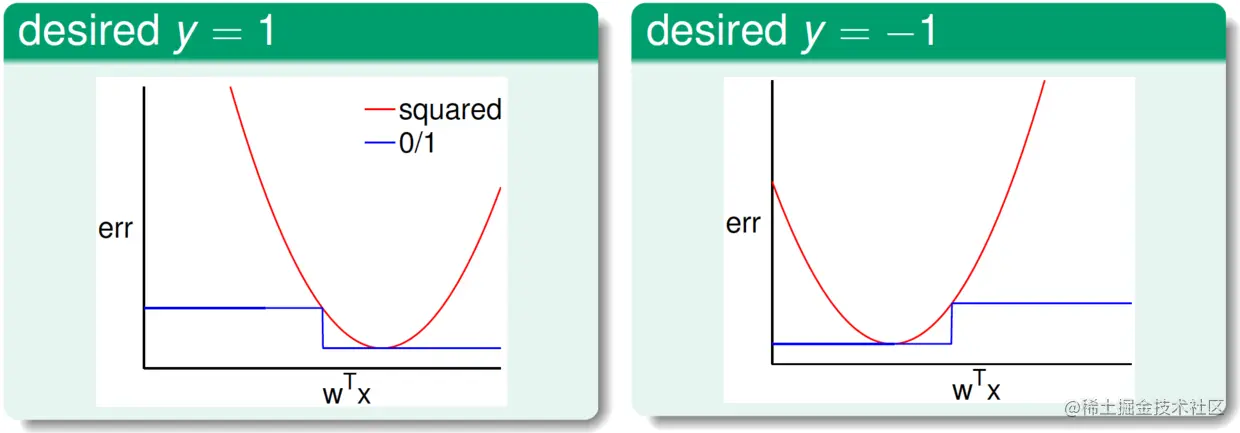
从中可直观地看出,err0/1≤errsqr一定成立。由此,有
≤VC≤classificationEout(w)classificationEin(w)+⋯regressionEin(w)+⋯
也就是说,让回归的Ein做得足够好,也可以使得分类的Eout足够小,只不过上限更宽松一些而已。这样做就是用边界的紧度(bound tightness)换取计算效率(efficiency)。
一般wLIN可用来作为PLA或pocket算法的初始向量。
2 逻辑回归
2.1 逻辑回归算法
二分类中,我们感兴趣的是
f(x)=sign(P(+1∣x)−21)∈+1,−1
但在很多场景下,我们想要做的是“软”(soft)分类,即得到某个分类的概率,此时感兴趣的是
f(x)=P(+1∣x)∈[0,1]
问题在于,我们得到的数据标签是样本的类别,而非样本被分到某个类的概率。
对于一个样本的所有特征x=(x0,x1,x2,⋯,xd),令s=i=0∑dwixi。我们可用逻辑函数(logistic function)θ(s)将它转换成估计的概率。也就是说,逻辑回归(logistic regression)的假设为h(x)=θ(wTx)。
最常用的逻辑函数是
θ(s)=1+eses=1+e−s1
函数图像如下:
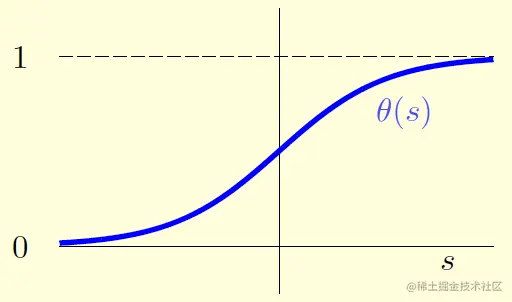
可见,它是个光滑的、单调的、“S”形的(sigmoid)函数。
接下来,要定义逻辑回归的Ein(w)。先将目标函数f(x)=P(+1∣x)反表示为
P(y∣x)={f(x)1−f(x)for y=+1for y=−1
假设手中的数据集为
D={(x1,∘),(x2,×),…,(xN,×)}
那么,由f生成D的概率为
×××P(x1)f(x1)P(x2)(1−f(x2))⋯P(xN)(1−f(xN)
由我们的假设h生成D的似然(likelihood)为
×××P(x1)h(x1)P(x2)(1−h(x2))⋯P(xN)(1−h(xN)
如果h≈f,那么h生成D的似然也应该接近于由f生成D的概率,并且由f生成D的概率应该是较大的(正好被我们抽样抽到)。所以,机器学习算法可以取
g=hargmaxlikelihood(h)
若h(x)=θ(wTx),由函数的性质可知,1−h(x)=h(−x),所以
=×××likelihood(h)P(x1)h(x1)P(x2)h(−x2)⋯P(xN)h(−xN)
而P(x1)、P(x2)、……、P(xN)都与h无关,因此有
likelihood(logistic h)∝n=1∏Nh(ynxn)
现在要将它最大化,以找出最终的h。可先把θ(s)代入,再取对数(对数函数单调,不改变最大化取值的点),变为
wmaxlnn=1∏Nθ(ynwTxn)
再取相反数(最大化变为最小化)、除N(不改变最值点)后,又可变为
wminN1n=1∑N−lnθ(ynwTxn)
将θ(s)展开得到
wminN1n=1∑Nln(1+exp(−ynwTxn))
令
err(w,x,y)=ln(1+exp(−ywx))
这就是交叉熵误差(cross-entropy error),而n=1∑Nerr(w,xn,yn)就是Ein(w)。
2.2 梯度下降
接下来就要最小化Ein(w),它是连续的、可微的、二次可微的、凸的,因此可以试着让它梯度为0。求出它的梯度
∇Ein(w)=N1n=1∑Nθ(−ynwTxn)(−ynxn)
它的梯度可以看成是以θ(⋅)为权重的−ynxn的加权平均。要让它为0,有两种方式:
- 让所有的θ(−ynwTxn)都为0,这意味着所有样本都满足ynwnxn≫0,也即D是线性可分的;
- 若D不是线性可分的,要让加权和为0,这是个非线性方程,没有闭式解(closed-form solution)。
可用与PLA中类似的方法进行迭代,即wt+1←wt+ηv,其中v确定了更新的方向,η确定了更新的步长,如图:
怎么迭代呢?可用贪心算法,一步步让Ein变小。假设已经给定某个η,要确定v的方向,每一步的更新问题就转换成了
∥v∥=1minEin(wt+ηv)
看起来仿佛更难解了。但如果η足够小,我们可以用局部线性近似展开它(泰勒展开,Taylor expansion):
Ein(wt+ηv)≈Ein(wt)+ηvT∇Ein(wt)
式中Ein(wt)和∇Ein(wt)已知,η给定,只需确定v即可,注意到上式第二项本质上是两个向量内积,当两个向量方向相反时值最小,因此要最小化上式,可取
v=−∥∇Ein(wt)∥∇Ein(wt)
梯度下降的迭代更新就变成了:对于给定的较小η,
wt+1←wt−η∥∇Ein(wt)∥∇Ein(wt)
η太小会导致非常慢,太大会导致不稳定,最好用变化的η,如下图所示:
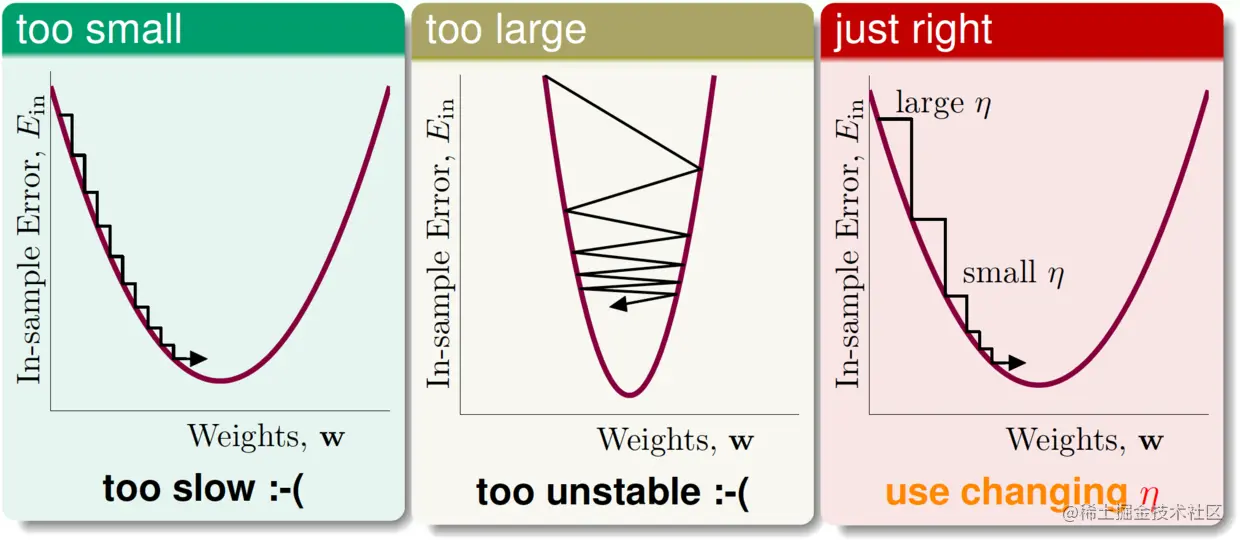
那么,η怎么变比较好?可让它与∥∇Ein(wt)∥正相关,将原来固定的η乘上∥∇Ein(wt)∥即可。这样,更新规则也就变成了
wt+1←wt−η∇Ein(wt)
这个新的η可叫作固定的学习率(learning rate)。
3 分类的线性模型
3.1 三种算法的比较
记s=wTx,以下是总结三种模型(线性分类、线性回归、逻辑回归):
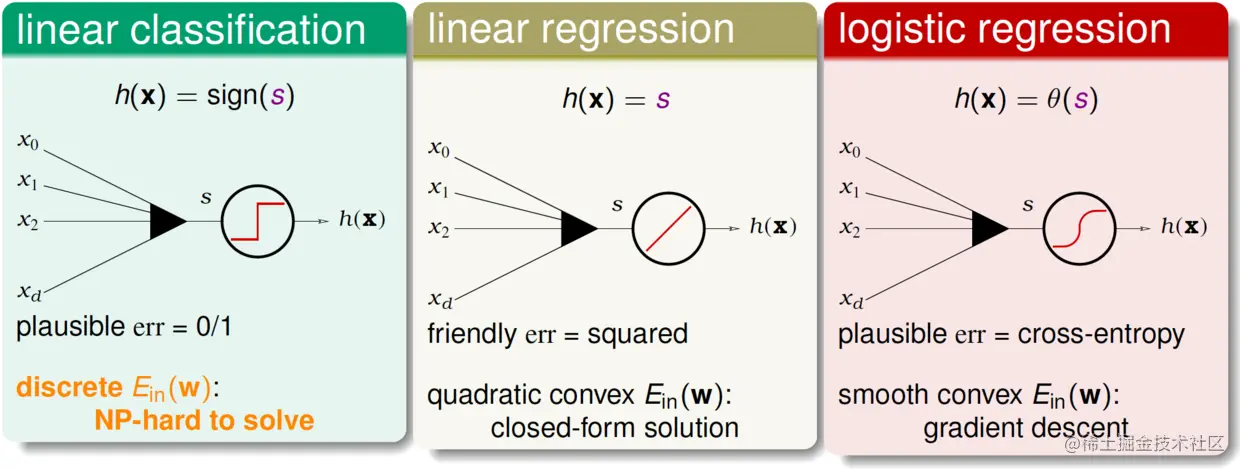

这里的ys可称为分类正确度分数(classification correctness score),即度量分类有多正确,该值越大,说明分类越“正确”。
若将交叉熵误差函数errCE(s,y)做scale(除ln2),得到
errSCE(s,y)=log2(1+exp(−ys))
把它们的误差函数都画出来,可得下图:
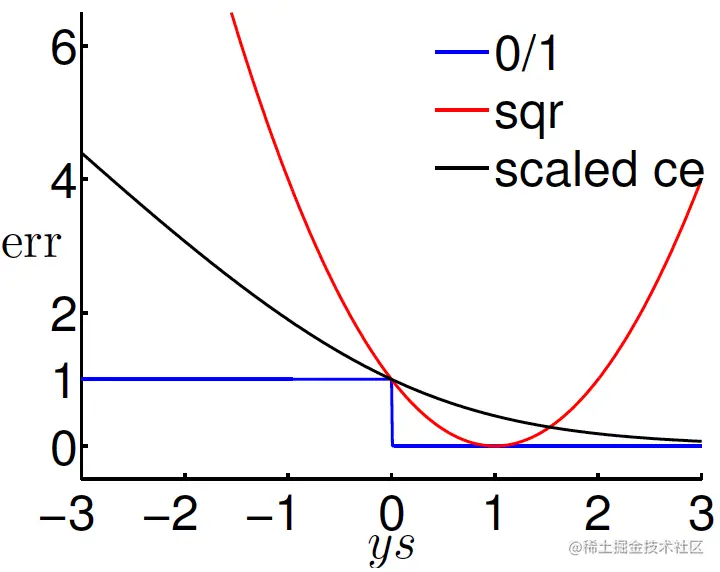
从图中可知,一定有
err0/1≤errSCE(s,y)=ln21errCE(s,y)
由此可以用VC维理论证明,使用errCE也可以做好分类任务,有两种思路:
Eout0/1(w)≤Ein0/1(w)+Ω0/1≤ln21EinCE(w)+Ω0/1
Eout0/1(w)≤ln21EoutCE(w)≤ln21EinCE(w)+ln21ΩCE
不管用哪种方式,只要保证EinCE足够小,都可以保证Eout0/1(w)也足够小,也就是说,使用逻辑回归或线性回归都可以做线性分类。
用PLA、线性回归、逻辑回归做分类,三种方法的优缺点如下:

3.2 随机梯度下降
PLA每次迭代的时间复杂度为O(1),但逻辑回归(或pocket算法)每次迭代都需要对D中的所有样本进行一次运算,时间复杂度为O(N),能不能让每次迭代的时间复杂度也变成O(1)?
我们在做更新wt+1←wt+ηv时,取了
v=−∇Ein(wt)=−N1n=1∑Nθ(−ynwtTxn)(−ynxn)
可以看到,计算梯度需要遍历所有样本,复杂度实在太高了。可将它里面的N1n=1∑N看作是期望E,相当于不断随机抽一个样本计算出来的结果的平均。若将随机抽一个样本n算出来的梯度称为随机梯度∇werr(w,xn,yn),那么真正的梯度可看作是它的期望:
∇wEin(w)=Erandom n∇werr(w,xn,yn)
这样,就可以用随机梯度下降(Stochastic Gradient Descent,SGD)进行迭代。它的好处是非常简单,计算的成本低,非常适用于大数据或在线学习的情况,缺点是不够稳定。
在逻辑回归中,用SGD更新的步骤就变成了
wt+1←wt+η⋅θ(−ynwtTxn)(ynxn)
这与PLA中的更新步骤十分相似,PLA中是这样的:
wt+1←wt+1⋅1[yN=sign(wtTxn)](ynxn)
因此用SGD的逻辑回归,可以看作是“软”的PLA。而反过来,若取η=1,则PLA在wtTxn很大的时候也可以看作是用SGD的逻辑回归。
在用SGD时,有两个经验法则:
- 什么时候停止?t足够大的时候就可以(不要判断梯度是否真的为0,否则又会带来梯度计算的复杂度);
- 当x在一般范围内时,就取η=0.1吧。
4 多分类问题
4.1 用逻辑回归做多分类
假设Y={□,♢,△,⋆},数据分布如下图:

可对每个类别分别做一次分类,如下图:
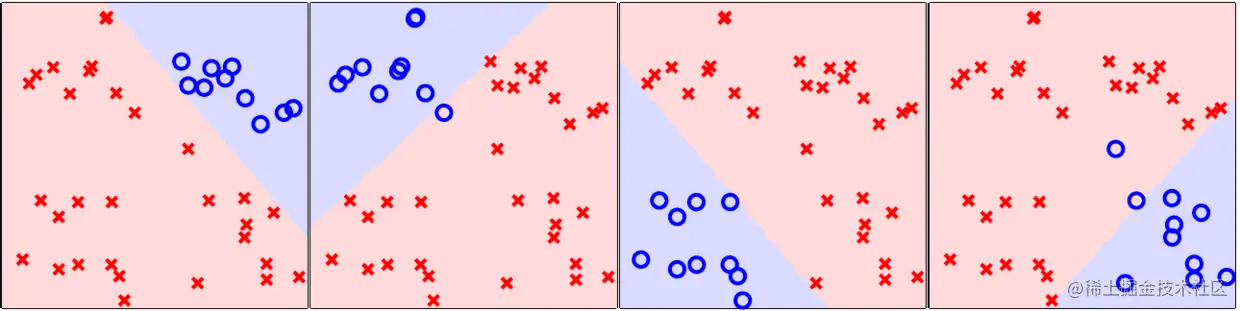
但这样做,在最后要把它们结合起来时,会出现问题,有些区域无法判定属于哪一类:

怎么解决呢?可以用逻辑回归做“软”分类器,依旧是对每个类别k,用数据集
D[k]={(xn,yn′=2⋅1[yn=k]−1)}n=1N
做一次逻辑回归,得到一个分类器w[k]:
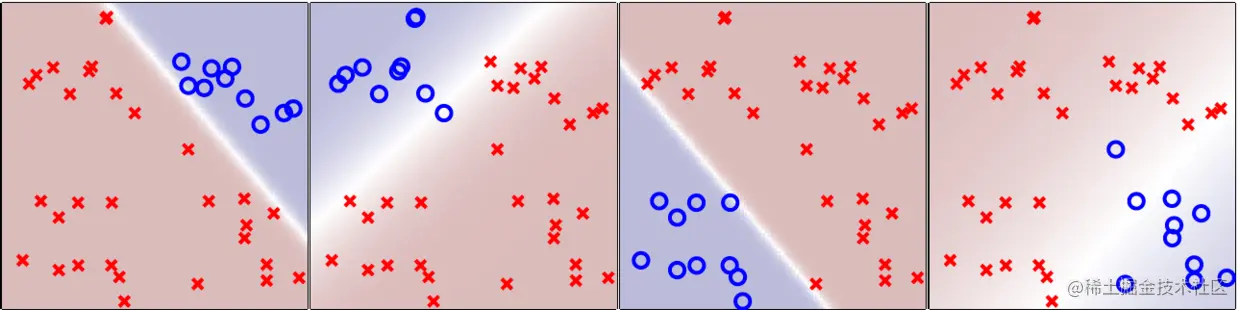
做完后要将它们结合起来,可取g(x)=argmaxk∈Yθ(w[k]Tx),这样就得到某个点应该属于哪一类了:

这样做称为OVA(One-Versus-All) Decomposition,好处是有效率,可以和类似逻辑回归的方法结合起来,但缺点在于当K很大时,往往会使D[k]非常不平衡,比如有100类,并且分布比较均匀,OVA每次用于训练的样本的两类数据的个数就会非常悬殊。
可以再进行扩展,如multinomial ('coupled') logistic regression,加入一些如“属于不同类的概率加起来应该为1”之类的限制,让它更适合用于多分类。
4.2 用二分类做多分类
为了克服不平衡问题,可以对两两类别进行训练,即用数据集
D[k,ℓ]={(xn,yn′=2⋅1[yn=k]−1):yn=k or yn=ℓ}
进行线性二分类:

最后,取
g(x)=tournament champion{w[k,ℓ]Tx}
即可:

这样的方法叫作OVO(One-Versus-One)Decomposition,好处在于有效率(因为每次训练用的数据量较少),并且是稳定的,可以和任何二分类方法相结合,但缺点在于不断计算w[k,ℓ]的操作总共的复杂度是O(K2),需要更多运算空间。当K不是非常大时,OVO很常用。
5 非线性变换
对于某些数据集来说,不管怎么使用线性模型,Ein都很大:
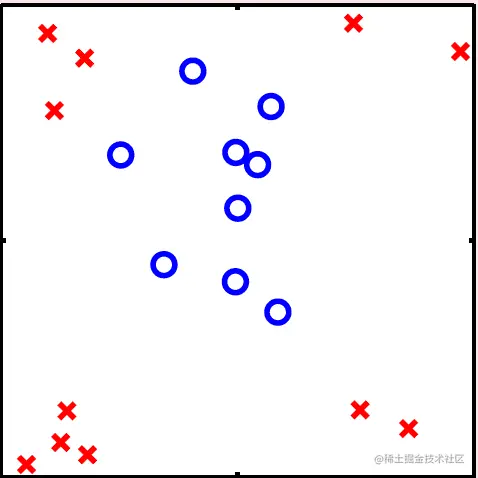
5.1 二次的假设集
我们发现,如果用一个圆来做它的分类界线,它其实是可分的:
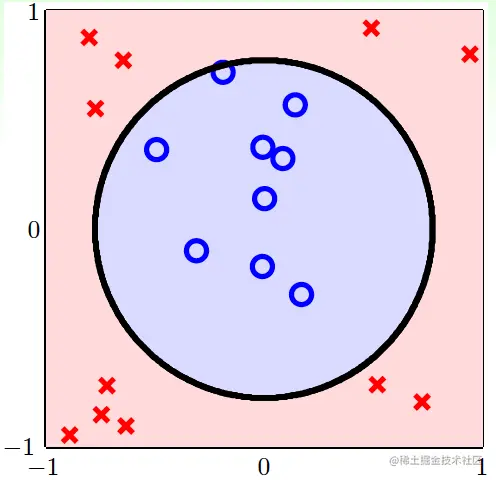
所以我们要重新设计圆形PLA、圆形回归、……吗?当然不是。我们可以将x∈X用变换Φ映射到z∈Z,使得在X中圆形可分的数据在Z中线性可分。
通过由Φ2(x)=(1,x1,x2,x12,x1x2,x22)映射而来的Z空间,可构成一般的二次假设集:
HΦ2={h(x):h(x)=h~(Φ2(x)) for some linear h~ on Z}
当然也可以用更高次的非线性变换,用非线性变换的流程如下图:
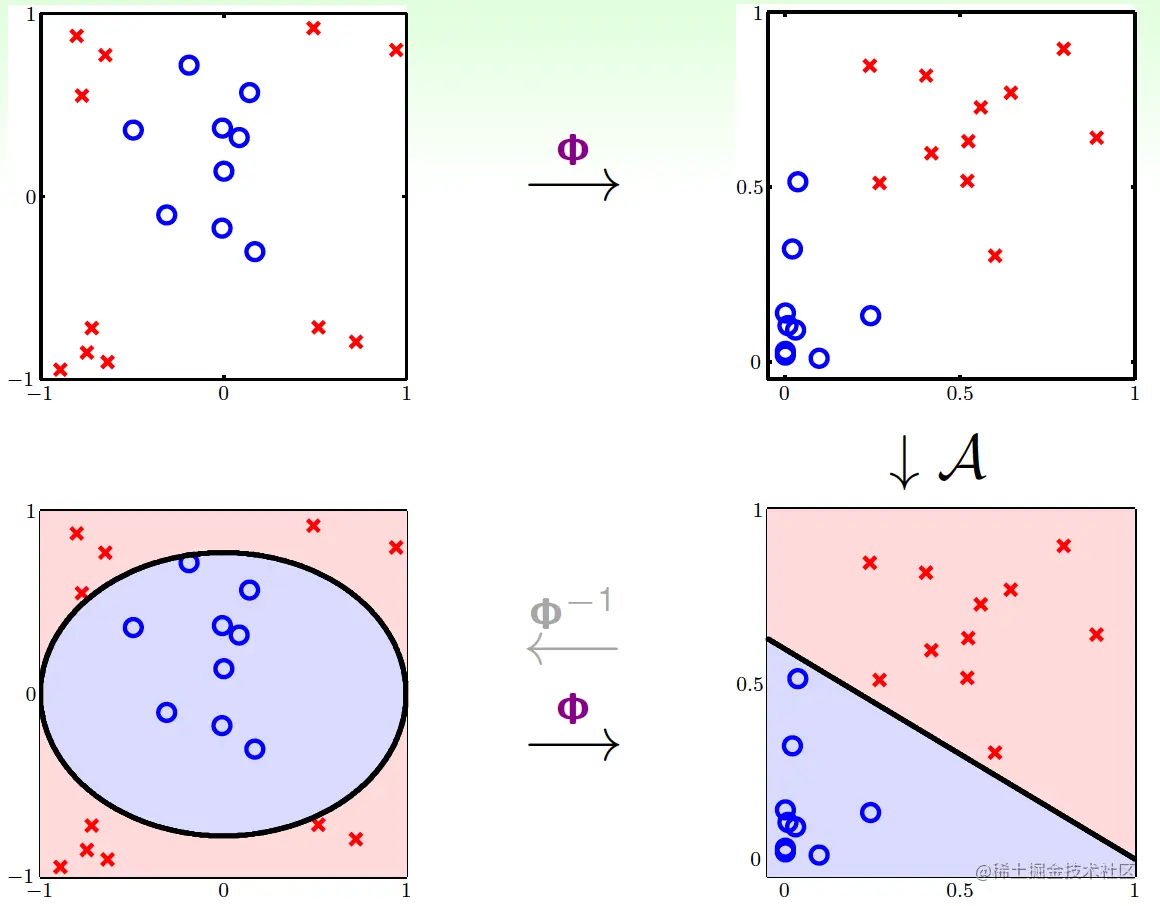
具体步骤如下:
- 先用Φ将{(xn,yn)}变换到{(zn=Φ(xn),yn)};
- 用{(zn,yn)}和线性分类算法A训练出模型w~;
- 返回g(x)=sign(w~TΦ(x))即可。
5.2 复杂度的代价
假设用Q次的非线性变换:
ΦQ(x)=(1,x1,x2,…,xd,x12,x1x2,…,xd2,⋯,x1Q,x1Q−1x2,…,xdQ)
式中的项数1+d~是多少呢?若有d个特征,可以在补上1后认为上面式子后边的每一项都是Q次的,也就是说要对d+1项每项都赋予一个次数,并且所有次数之和必须为Q。可以用隔板法:想象共有Q+d+1个小球,要在它们的空隙中放入d个隔板,隔成d+1段,每一段的小球个数减去1代表了对应位置的项的次数,由于要求每段中至少有1个小球,因此两端不能放隔板,共有Q+d个位置可放隔板,共有(dQ+d)种放法,也就是说,上式等号右边的项数
1+d~=(dQ+d)=O(Qd)
当Q较大时,一方面计算或存储的成本非常高,另一方面1+d~是dVC(HΦQ)的上界,Q太大会导致dVC过大,模型损失了泛化能力。
5.3 Q的选择
如何选择Q?假设Φ0(x)=(1),Φ1(x)=(Φ0(x),x1,x2,…,xd,),……,ΦQ(x)=(ΦQ−1(x),x1Q,x1Q−1x2,…,xdQ,),将它们的假设集分别记为H0,H1,……,HQ,它们存在嵌套关系
H0⊂H1⊂H2⊂⋯
如图所示:
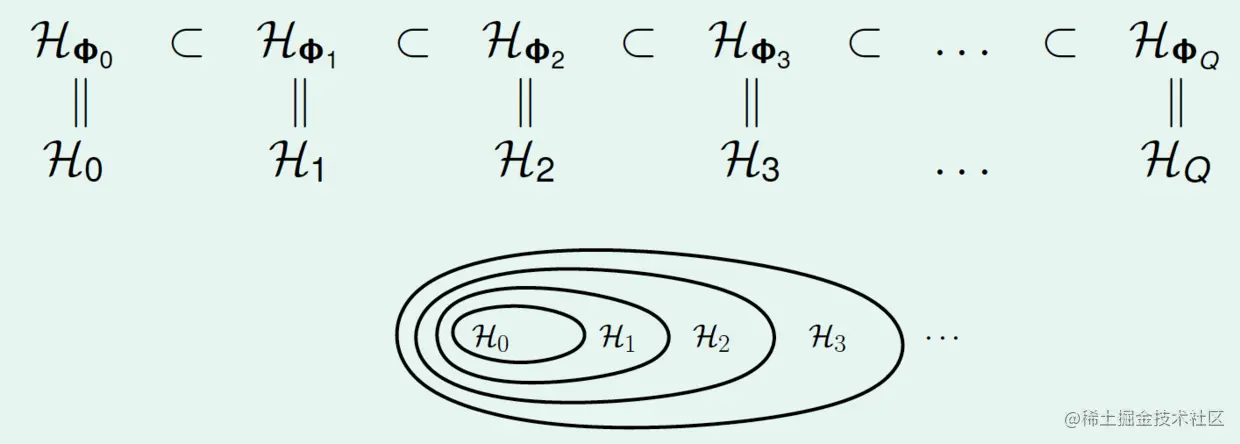
并且,它们的VC维满足
dVC(H0)≤dVC(H1)≤dVC(H2)≤⋯
若取gi=argminh∈HiEin(h),则它们的Ein满足
Ein(g0)≥Ein(g1)≥Ein(g2)≥⋯
如何选择Q?安全的做法是,先看Ein(g1)是否已经足够小,如果足够小,就可以了,否则,就用再稍微复杂一些的模型,也就是在下图中向右移动: