mysql底层原理及优化实战-2
为什么加了索引查询就会变快?
- 都知道innodb的索引大部分会选用b+树,那什么是B+树呢?上一章说过,在磁盘中,有数据页的概念,其实里面就是一堆数据行,也就是你在表里看到的一行一行的数据。不过我们可以想象,如果没有索引,想要查询一个符合条件的数据会怎么办?无非就是先把第一个数据页读出来,读完没有找到合适的数据,就接着读下一个数据页,直到把所有数据页都读完。每次从磁盘加载数据页的过程就是一次磁盘IO,这种速度真是想都不敢想,说到存储查找数据,你可能第一时间想到了hash表,这玩意查的快啊,那确实,不过它不支持排序啊,数据库中经常会有排序等需求。所以我们需要一种方法,既能减少磁盘IO的随机读,又能在有限内存空间内找到想要的数据。而B+树就很符合这种操作。假设我们能设置一个主键索引,我们插入的每一条数据在数据页中都是有序的,又能保证下一个数据页永远比前一个数据页大,就可以记录一下当前数据页的最小主键id,当然,一般当数据超过两个数据页的时候,就会有一个索引页的概念,里面就记录了一下每个数据页对应的最小主键id是多少,想象一下,这时候如果要根据主键查询一条数据,我们就可以直接到索引页,看一下我的主键id是不是比你索引页记录的最小id小,如果碰到一个小的,就说明要查的数据肯定在前一个数据页中,由于数据页里也是有序排列的,就可以用二分法找到对应的数据了。
- 索引有聚簇索引(也就是主键构成的索引,数据页在叶子节点上),和二级索引,二级索引只记录了索引字段,和对应主键id的值,其他结构和聚簇索引基本一致。所以一般查询二级索引,实质上就是先查出主键id的值,再去聚簇索引来一次回表查询,不过如果查询的字段正好就是二级字段的内容,那就不用回表了,直接返回需要的数据就行,也叫覆盖索引。
- 所谓索引,其实就是按照某种规则排序,就像你查字典,你想查300页的内容,如果你的书页码是乱的,想找到300页,只能一页一页翻,但是如果是有序的,你就可以随便翻一页,假如你翻到200页,是不是就可以直接往后使劲翻一下,一不小心翻到了400页,再往前翻点,这样下来,不用几次就能翻到300页。我们姑且把这个叫聚簇索引,页数就把他当做主键id吧。这本书前面有一个顺序的目录,字典页数的顺序是按照笔画从少到多排好的。但是有个人他就偏偏想查一下z开头拼音的有几个字,那如果我们不想让他一页一页翻,是不是要先做一个步骤,在不动原有字典的情况下,再找一个本子,按照拼音开头,把字典重新整理一下,我们这个本子也不去抄什么字义解释,只抄拼音对应的字,如果全部抄完,这个本子绝对要比字典要薄的多,如果要往字典里加新字,顺便我读一下他的拼音,把这个字插入到他同类的位置,一定保证他是有序的。也就是说,每加一个索引,相当于多抄一个本子,这也回答了一个经典面试题,索引是不是越多越好?你想象一下字典场景,你加一个字,你会愿意抄几个本子?正常情况下,如果你需要查一个Z字开头字怎么写,什么意思,就要先去你抄的本子上,找那个字对应的字典的页数,然后到那个页数上查到你需要的一切知识。(回表)不过如果你只想知道字怎么写,是不是就不用去查字典了?你抄的本子就有这个字啊(覆盖索引)。不过大多数都建议多建立联合索引,联合索引也并不复杂,假设有abc三个字段,先按照a排好序,在保证a有序的情况下,保证b有序,然后在b有序的情况下保证c有序。
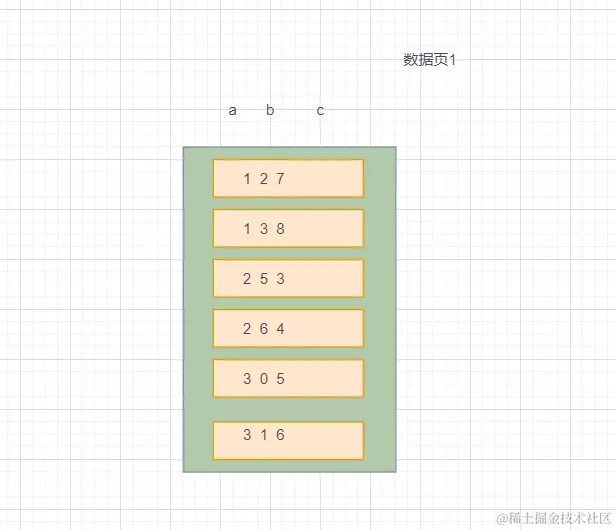 上面你可以理解为数据页的内容,记住一句话,索引是在保证有序才有资格谈的,如果我们直接select * from t where b>5 这个会命中索引吗?看图也知道了,压根保证不了这些数据是有序的,连范围都没法确定,所以有个最左前缀规则,你的联合索引如果第一个都无法命中,下面的肯定不会走索引的。那如果我写select * from t where a>1 and b>5呢?不用看,a肯定是能命中个范围索引的,但是b,还是没戏。如果我写select * from t where a=1 and b>0,那就能命中了,你保证前一个索引是等值命中,那后一个索引肯定是有序的啊。同理,select * from t where a>1 and b=6也是可以命中的。
上面你可以理解为数据页的内容,记住一句话,索引是在保证有序才有资格谈的,如果我们直接select * from t where b>5 这个会命中索引吗?看图也知道了,压根保证不了这些数据是有序的,连范围都没法确定,所以有个最左前缀规则,你的联合索引如果第一个都无法命中,下面的肯定不会走索引的。那如果我写select * from t where a>1 and b>5呢?不用看,a肯定是能命中个范围索引的,但是b,还是没戏。如果我写select * from t where a=1 and b>0,那就能命中了,你保证前一个索引是等值命中,那后一个索引肯定是有序的啊。同理,select * from t where a>1 and b=6也是可以命中的。


