

- 原文地址:Making Neural Networks Smaller for Better Deployment
- 原文作者:Vincent Houdebine
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:PingHGao
- 校对者:samyu2000, lsvih
让神经网络变得更小巧以方便部署
数据科学和机器学习领域存在一种明显趋势,训练的模型越来越大。这些模型的性能接近人类,但通常太大,以至于无法部署在手机或无人机之类的资源有限的设备上。这是导致我们无法在日常生活中广泛使用 AI 的主要障碍之一。
我如何在 15Mb 的移动应用程序中安装 98Mb 的 ResNet 模型?
在安卓上,一个应用程序平均大小为 15 Mb。而由 Google 发布的最先进的图像分类模型 NASNet(在著名的图像分类竞赛数据集 ImageNet 上可达到 80% 的精度),其大型版本大小为 355 Mb,针对移动操作系统的优化版本也有 21.4 Mb。
如果您是一位数据科学家,试图将高性能的模型安装到资源有限的设备中,本文可以为您提供一些实用技巧,指导您在不损失性能的情况下,使用 Keras 和 NumPy 将模型大小压缩到 70%。
在过去的几年中,人们非常关注如何压缩模型,使其适合在资源有限的设备上进行训练和推理的问题。主要存在两种方法:
第一种常见方法是从设计入手,训练轻量级的神经网络。Google 的 MobileNet 就是一个很好的例子。MobileNet 的架构仅具有 420 万个参数,而 ImageNet 的准确率达到了 70%。这种压缩可保持合理的性能,是通过引入有助于减小模型的大小和复杂性的深度卷积层来实现的。
另一种方法是利用预先训练的大型神经网络,对其进行压缩以减小大小,同时最大程度地降低性能损失。本文将重点对卷积神经网络(CNN)压缩技术进行回顾和实现。
特别地,我们将专注于剪枝技术,一种较为容易实现的神经网络压缩技术。网络剪枝旨在消除神经网络中的特定权重及其各自的联系,以压缩网络大小。尽管剪枝技术不如其他方法流行,但它取得了很好的效果,并且很容易实现,正如接下来我们将在文章看到的那样。
“简化意味着去掉不必要的元素,让必要元素凸显。” Hans Hoffman
消除神经网络中的权重却并不会影响其性能,这似乎令人难以理解。不过,Y.LeCun 等人于 1991 年在一篇名为 Optimal Brain Damage 的论文中已经证明,可以通过选择性删除神经网络权重来减小神经网络的大小。他们发现有可能通过删除一半的神经网络权重,最终得到一个轻量级、性能更好的网络。
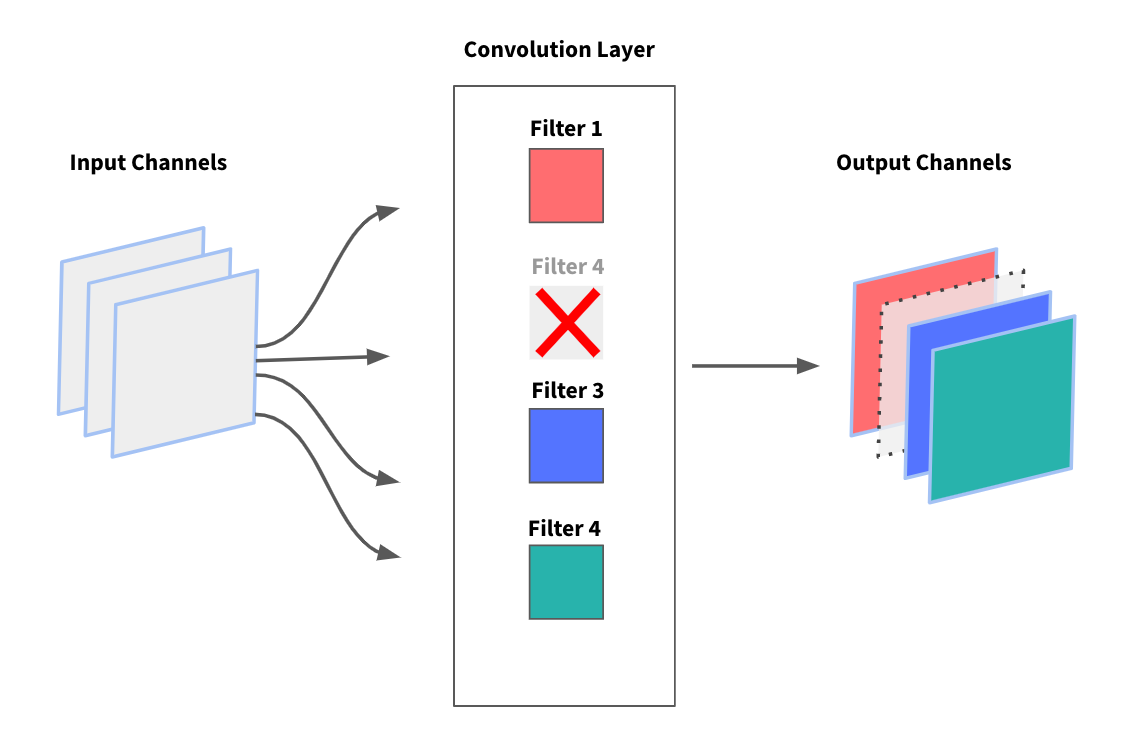
在 CNN 这一特定情况下,大多数方法不是除去单个权重,而是专注于从卷积层中除去整个滤波器及其对应的特征图。这种方法的主要优点是它不会在网络的权重矩阵中引入任何稀疏性。这一点很重要,因为包括 Keras 在内的大多数深度学习框架都不支持稀疏权重的层。
尽管卷积层仅占网络权重的一小部分 —— 网络权重的大部分位于全连接的层中 —— 修剪滤波器最终还是间接减少了全连接层的权重数。
网络修剪背后的直觉是什么?
让我们退后一步,看看网络修剪背后的直觉。关于神经网络的两个假设会催生剪枝技术:
第一个是“权重冗余”。这意味着多个神经元(或在 CNN 的情况下为过滤器)会被非常相似的输入值激活。因此,大多数网络实际上都是参数冗余的,我们可以放心地假设删除冗余权重不会对性能造成太大影响。
第二个是并非所有权重均对输出预测做出了同等贡献。本能地,我们可以假设较低幅值的权重对网络的重要性较低,Y.LeCun 称它们为“低显著性权重”。实际上,在所有条件都相同的情况下,较低幅值的权重将对网络的训练错误产生更小的影响。
如下图所示,网络中的大量卷积滤波器的 L1 范数较低,而很少数量的滤波器的范数则相对较大。

尽管使用 L1 范数来对滤波器的重要性进行排序是一种简单的启发式方法,但我们可以假设将低重要性的卷积滤波器从网络中删除会比删除其他滤波器的影响更小。
现在,我们对剪枝及其如何在不损害网络性能的情况下帮助压缩网络有了更好的了解,让我们看看如何在 Keras 网络上实现它。
如何对使用 Keras 训练的模型进行剪枝?
在本文的其余部分,我们将使用在 imagenette(一个包含 10,000 张图片共 10 个类别的 ImageNet 的子集) 上训练的普通 CNN。在训练和评估了完整的基准网络之后,我们将实现并比较不同的剪枝策略。
Rank-Prune-Retrain
我们将采用的有效修剪 CNN 的方法非常简单:排序-修剪-重新训练。首先,我们需要对滤波器的重要性进行排序,以筛选出幅值低,重要性低的滤波器。然后,我们会根据估计的重要性修剪掉其中一定比例的滤波器。最后,我们将使用与初始训练相同的学习率来对网络重新训练几个 epoch,以将权重微调到修剪后的新架构上。就是这样,它非常简单,甚至可以放入一条 Tweet 中。

- 排序:筛选出待修剪的滤波器
关于如何根据权重对网络输出性能的贡献程度进行排名,尚无共识。理想的策略是分别修剪每个权重并计算没有该权重的模型的性能。这种方法被称为 oracle 剪枝,但是由于网络一般具有数百万(有时数十亿)的权重,可以说这种策略至少非常昂贵。
其他对权重进行排序的方法包括计算其范数(L1 或 L2)或计算一批输入数据上的均值,标准差或 0 激活值的百分比。
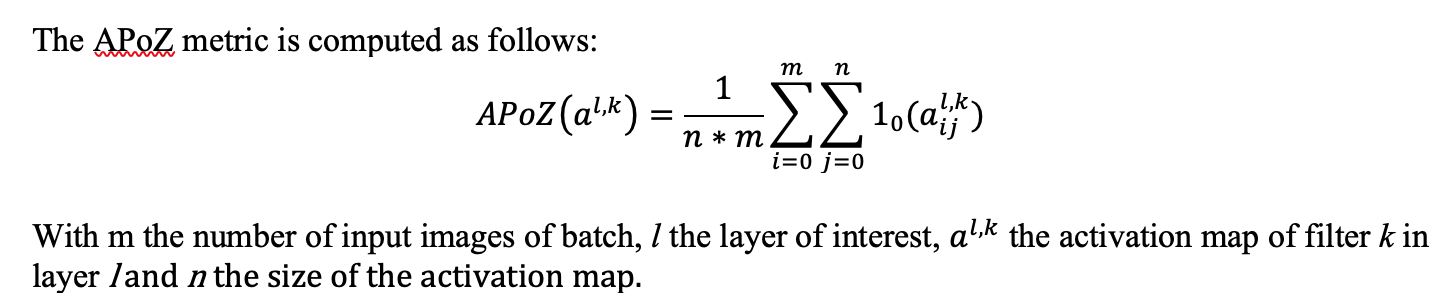
在本实验中,我们将同时使用卷积过滤器的 L1 范数和**平均零激活百分比(APoZ)**来对重要性进行排名。
由于我们将使用 L1 范数来比较大小不同的过滤器,因此我们必须使用归一化的 L1 范数:
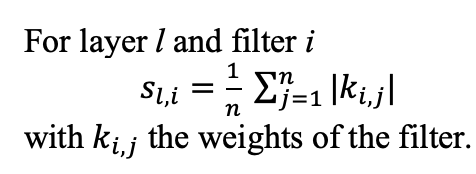
下面的代码计算 Keras 模型中卷积滤波器的 L1 范数,并输出尺寸为 Nb_of_layers x Nb_of_filters 的矩阵。
import tensorflow as tf
import keras.backend as K
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Model
from kerassurgeon import Surgeon, identify
from kerassurgeon.operations import delete_channels, delete_layer
import os
import numpy as np
import math
def get_filter_weights(model, layer=None):
"""用于返回 Keras 模型中一个或者所有卷积层的权重的函数"""
if layer or layer==0:
weight_array = model.layers[layer].get_weights()[0]
else:
weights = [model.layers[layer_ix].get_weights()[0] for layer_ix in range(len(model.layers))\
if 'conv' in model.layers[layer_ix].name]
weight_array = [np.array(i) for i in weights]
return weight_array
def get_filters_l1(model, layer=None):
"""返回 Keras 模型中指定卷积层中滤波器的 L1 范数,如果 layer=None,返回 APoZ 矩阵"""
if layer or layer==0:
weights = get_filter_weights(model, layer)
num_filter = len(weights[0,0,0,:])
norms_dict = {}
norms = []
for i in range(num_filter):
l1_norm = np.sum(abs(weights[:,:,:,i]))
norms.append(l1_norm)
else:
weights = get_filter_weights(model)
max_kernels = max([layr.shape[3] for layr in weights])
norms = np.empty((len(weights), max_kernels))
norms[:] = np.NaN
for layer_ix in range(len(weights)):
# 计算滤波器的范数
kernel_size = weights[layer_ix][:,:,:,0].size
nb_filters = weights[layer_ix].shape[3]
kernels = weights[layer_ix]
l1 = [np.sum(abs(kernels[:,:,:,i])) for i in range(nb_filters)]
# 除以滤波器的形状
l1 = np.array(l1) / kernel_size
norms[layer_ix, :nb_filters] = l1
return norms
您可以尝试的第二个选项是计算 APoZ 激活。直觉是,如果一个滤波器几乎没有被一批随机输入图像激活,那么它对模型的输出的贡献就不会很大。请注意,如果卷积层中使用的激活函数将很多值归零,则此度量方法很有意义。对于 ReLU 就是这种情况,但是当使用 Leaky ReLU 之类的其他激活函数时,APoZ 标准可能不那么相关。
要计算每个滤波器的 APoZ,我们必须选择数据集的一个子集,用 CNN 对其评分,然后计算每个滤波器的值为零的激活值所占百分比的均值。我们要修剪的滤波器是零激活值平均百分比最大的。
以下的代码为对一个卷积层完成上述工作:
def compute_apoz(model, layer_ix, nb_filters, generator):
"""计算一层的激活值中零激活值得平均百分比"""
act_layer = model.get_layer(index=layer_ix)
node_index = 0
temp_model = Model(model.inputs,
act_layer.get_output_at(node_index)
)
# 计算每个激活值零值的百分比
a = temp_model.predict_generator(generator,944, workers=3, verbose=1)
activations = a.reshape(a.shape[0]*a.shape[1]*a.shape[2],nb_filters).T
apoz_layer = np.sum(activations == 0, axis=1) / activations.shape[1]
return apoz_layer
将其推广到所有层,我们再次输出一个 Nb_of_layers x Nb_of_filters 矩阵,其中包含网络中每个滤波器的 APoZ 值:
def get_filters_apoz(model, layer=None):
"""计算一个或者所有卷积层激活值中零值得平均百分比,如果 layer=None,返回一个 APoZ 矩阵"""
test_generator = ImageDataGenerator(rescale=1./255, validation_split=0.1)
apoz_dir = "/home/ec2-user/experiments/data/imagenette2-320/train"
apoz_generator = test_generator.flow_from_directory(
apoz_dir,
target_size=(160, 160),
batch_size=1,
class_mode='categorical',
subset='validation',
shuffle= False)
if layer or layer ==0:
assert 'conv' in model.layers[layer].name, "The layer provided is not a convolution layer"
weights_array = get_filter_weights(model, layer)
act_ix = layer + 1
nb_filters = weights_array.shape[3]
apoz = compute_apoz(model, act_ix, nb_filters, apoz_generator)
else :
weights_array = get_filter_weights(model)
max_kernels = max([layr.shape[3] for layr in weights_array])
conv_indexes = [i for i, v in enumerate(model.layers) if 'conv' in v.name]
activations_indexes = [i for i,v in enumerate(model.layers) if 'activation' \
in v.name and 'conv' in model.layers[i-1].name]
# 创建一个 n 维的 array 来存储数据
apoz = np.zeros((len(weights_array), max_kernels))
for i, act_ix in enumerate(activations_indexes):
# 用我们的模型对该样本评分(修剪到感兴趣的图层)
nb_filters = weights_array[i].shape[3]
apoz_layer = compute_apoz(model, act_ix, nb_filters, apoz_generator)
apoz[i, :nb_filters] = apoz_layer
return apoz
根据这两个矩阵,我们可以轻松地确定要修剪的滤波器。一些论文设定了严格的门槛,并修剪掉所有没有切掉的滤波器,而另一些论文则对滤波器进行排序,并设定一定的百分比来修剪滤波器。
在下面的代码中,我们通过简单地计算与 10% 的滤波器相对应的数量 n_pruned,然后计算 n_pruned 个值最低(对于 L1)或最大(对于 APoZ)的滤波器的坐标,来删除网络中 10% 的滤波器:
def compute_pruned_count(model, perc=0.1, layer=None):
if layer or layer ==0:
# 计算滤波器的数量
nb_filters = model.layers[layer].output_shape[3]
else:
nb_filters = np.sum([model.layers[i].output_shape[3] for i, layer in enumerate(model.layers)
if 'conv' in model.layers[i].name])
n_pruned = int(np.floor(perc*nb_filters))
return n_pruned
def smallest_indices(array, N):
idx = array.ravel().argsort()[:N]
return np.stack(np.unravel_index(idx, array.shape)).T
def biggest_indices(array, N):
idx = array.ravel().argsort()[::-1][:N]
return np.stack(np.unravel_index(idx, array.shape)).T
除了这两种方法,我们还尝试了从网络中随机删除滤波器,结果证明了你并不能无痛地从网络中随机删除滤波器。
2. 剪枝:修剪掉滤波器
现在,既然我们已经确定了要删除的卷积滤波器,我们就得戴上脑外科医生的帽子并去实施相关操作。我们仍需谨慎,并在网络的更深层中删除相应的输出通道。
值得庆幸的是,keras-surgeon 库提供了非常简单的方法来有效地修改经过训练的 Keras 模型。基于 Keras 的简易性,keras-surgeon 使您可以使用简单的 delete_channels_method() 从层中轻松删除神经元或通道。该库还具有一个识别模块,可让您计算特定层中神经元的 APoZ 指标。Keras-surgeon 库很棒,几乎可以在任何 Keras 模型上工作(不仅限于 CNN),让我们向 Keras-surgeon 库的作者 Ben Whetton 致敬。这是该[项目](github.com/BenWhetton/…
让我们实现 keras-surgeon 来修剪掉上一节中确定的通道。在对模型进行修剪后,我们还必须使用 Keras 中标准的 .compile() 模块对模型重新编译。
from kerassurgeon.operations import delete_channels, delete_layer
from kerassurgeon import Surgeon
def prune_one_layer(model, pruned_indexes, layer_ix, opt):
"""基于 Keras 模型修剪掉一层,层索引
和待修剪的滤波器索引"""
model_pruned = delete_channels(model, model.layers[layer_ix], pruned_indexes)
model_pruned.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
return model_pruned
def prune_multiple_layers(model, pruned_matrix, opt):
"""基于 Keras 模型修剪掉几层,层索引和带修剪滤波器的索引矩阵"""
conv_indexes = [i for i, v in enumerate(model.layers) if 'conv' in v.name]
layers_to_prune = np.unique(pruned_matrix[:,0])
surgeon = Surgeon(model, copy=True)
to_prune = pruned_matrix
to_prune[:,0] = np.array([conv_indexes[i] for i in to_prune[:,0]])
layers_to_prune = np.unique(to_prune[:,0])
for layer_ix in layers_to_prune :
pruned_filters = [x[1] for x in to_prune if x[0]==layer_ix]
pruned_layer = model.layers[layer_ix]
surgeon.add_job('delete_channels', pruned_layer, channels=pruned_filters)
model_pruned = surgeon.operate()
model_pruned.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
return model_pruned
我们可以写一个满意的 prune_model() 函数对其进行封装。
def prune_model(model, perc, opt, method='l1', layer=None):
"""使用不同的方法对 Keras 模型进行修剪
参数:
model: Keras 模型对象
perc: 一个 0 到 1 之间的小数
method: 剪枝方法,可以是 ['l1','apoz','random'] 中的一种
返回:
一个修剪后的 Keras 模型对象
"""
assert method in ['l1','apoz','random'], "Invalid pruning method"
assert perc >=0 and perc <1, "Invalid pruning percentage"
n_pruned = compute_pruned_count(model, perc, layer)
if method =='l1':
to_prune = prune_l1(model, n_pruned, layer)
if method =='apoz':
to_prune = prune_apoz(model, n_pruned, layer)
if method =='random':
to_prune = prune_random(model, n_pruned, layer)
if layer or layer ==0:
model_pruned = prune_one_layer(model, to_prune, layer, opt)
else:
model_pruned = prune_multiple_layers(model, to_prune, opt)
return model_pruned
在我们的实验中,我们尝试了不同的修剪百分比,最多修剪了网络中 50% 的卷积滤波器。实验结果表明,在修剪比例超过某个值后,我们从网络中删除了太多必要的滤波器,并且性能下降太大,无法通过进一步的微调来恢复。
最佳修剪 — 通过使用 APoZ 修剪掉 20% 的滤波器可实现性能比,这使我们可以将模型权重数量减少 69%!
3. 再训练:再训练模型
现在,我们的模型中去除了很多所谓的不必要的滤波器。修剪模型会在模型中引入扰动,并且为了保持模型的性能,通常需要对模型进行几个 epoch 的微调。Keras 使微调预先训练过的模型变得非常容易,只需再次调用 .fit()函数即可使用与初始模型训练相同的优化器(相同的优化器类型,相同的学习率)。
进行微调的数量将取决于从模型中删除的滤波器比例和初始模型的复杂性。对于我们的实验,在传统的 CNN 上我们选择仅微调一轮,但是一些论文在更复杂的模型上最多进行了 10 轮再训练。
有意识的一点是,对于使用 L1 范数和 APoZ 修剪的模型,修剪和重新训练后的性能与基线相比实际上有所提高。我们的模型尽管体积小了 69%,但其准确度却达到了 77.8%,比我们的参数化的基准模型要好得多。这是很酷的一件事。
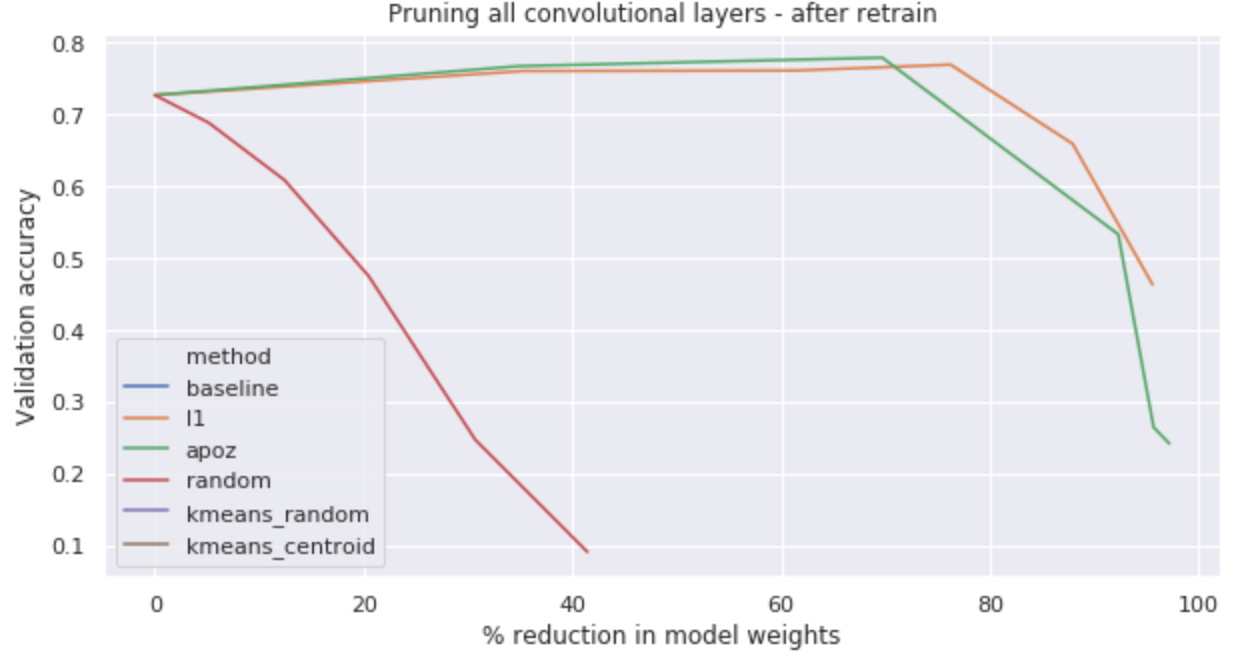

在几篇论文中已经观察到了这一点,并且可以将其解释为对神经网络训练后的再正则化(post-training network regularization)。即使您不想压缩模型,你也可以尝试把剪枝技术作为提高模型泛化能力的一种方法。
4. 再训练!
可以反复重复 排序 - 剪枝 - 再训练的循环,直到满足特定条件为止。例如,我们可以重复此循环,直到修剪后的模型的性能与原始模型的性能之间的差异大于某个阈值为止。
在实践中,我们发现此循环的单次迭代可以使得权重数量压缩高达近 70%,同时保持或改善基线 CNN 的性能。
结论
总结一下这些实验,我们发现了 APoZ 的压缩/性能比结果比 L1 好。但是,在实际中,我建议使用 L1 作为快速压缩的方法。与 APoZ 相比,L1 不需要任何数据即可识别要修剪的滤波器,因此计算量要少得多。
总体而言,我们对这种概念上如此简单的技术所获得的压缩效果印象深刻。与诸如量化之类的其他压缩技术相比,剪枝是一种更简单的实现方法,同时可以得到非常好的结果。
我们希望本文能说服您进行尝试剪枝技术,希望我们能看到更多修剪后的模型被部署到生产中!
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
