

2. 文件关键行数
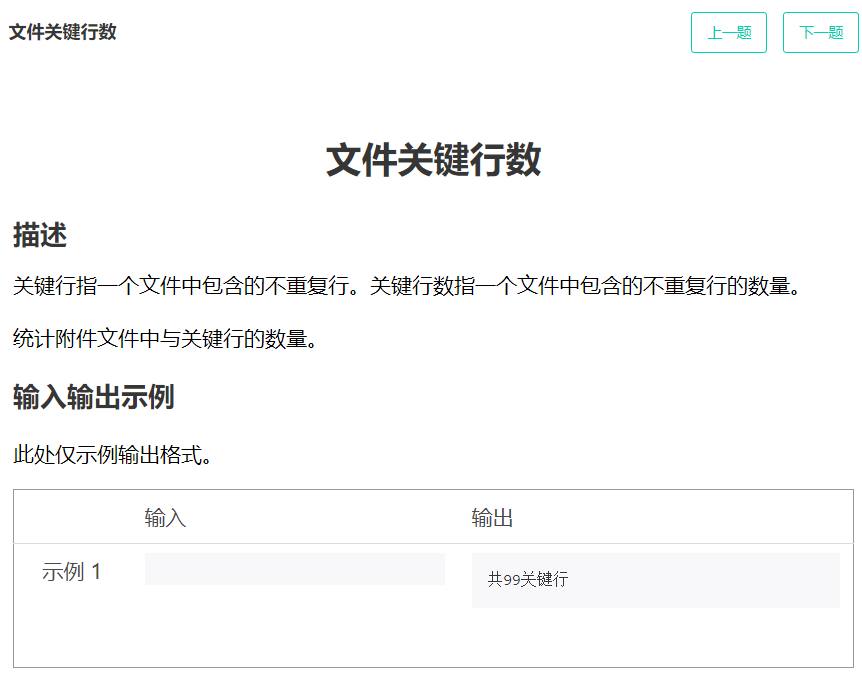
# 我
f = open('latex.log', 'r')
s = set()
count = 0
for line in f:
if line not in s:
s.add(line)
count += 1
print('共{}关键行'.format(count))
傻了,可以直接转换成set的
# 参考代码
f = open("latex.log")
ls = f.readlines()
s = set(ls)
print("共{}关键行".format(len(s)))
3. 字典翻转输出
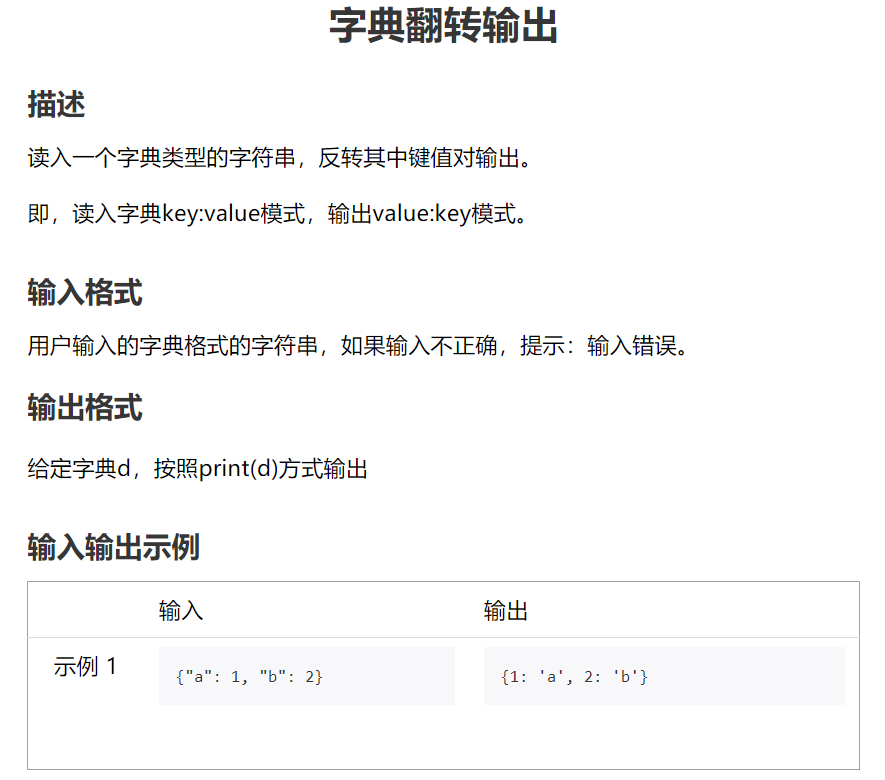
# 我
d = eval(input())
if type(d) == dict:
d1 = {value:key for (key, value) in d.items()}
print(d1)
else:
print('输入错误')
不足:
- 没有正确使用异常处理
- 是参考别人的代码翻转的,而且不太懂原理
# 参考代码
s = input()
try:
d = eval(s)
e = {}
for k in d: # 原来如此,是这样读取字典dict的数据的
e[d[k]] = k
print(e)
except: # 原来如此,异常处理
print("输入错误")
原来如此,学到了
4.《沉默的羔羊》之最多单词
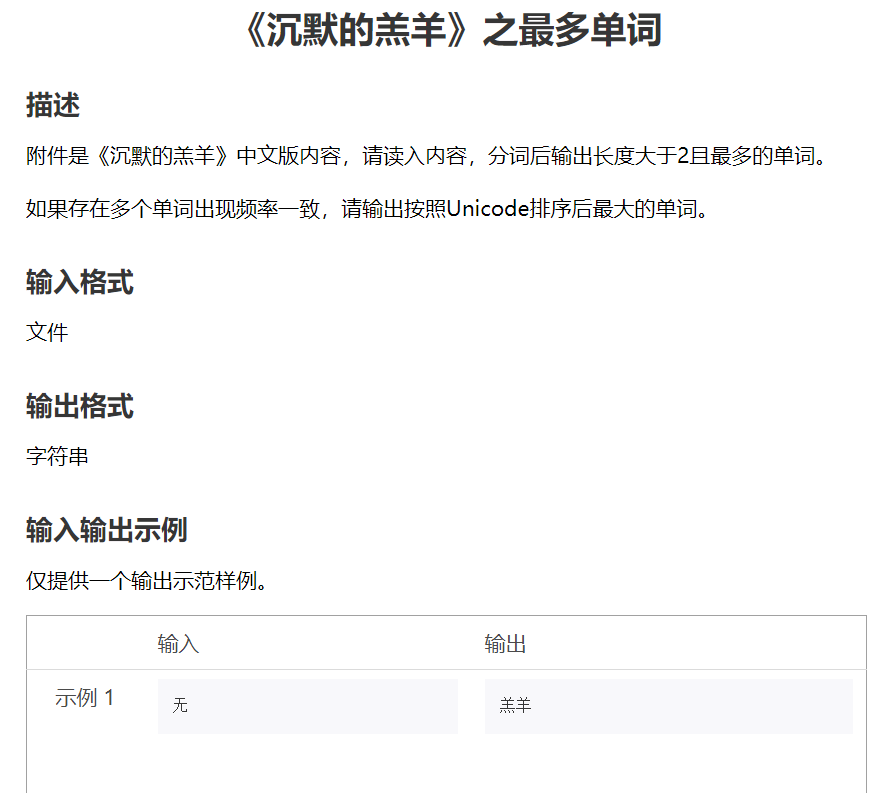
# 我
import jieba
txt = open('沉默的羔羊.txt', 'r', encoding ='utf-8').read()
words = jieba.lcut(txt)
# ls = []
counts = {}
for word in words:
if len(word) >= 2:
# ls.apppend(word)
counts[word] = counts.get(word, 0) + 1
items = list(counts.items()) # 转化为list方便处理和排序
items.sort(key = lambda x:x[1], reverse = True) # 按照items的第二个元素排序,逆序
print(items[0][0])
不足:没有完全完成任务(进行unicode比较)
# 参考代码
import jieba
f = open("沉默的羔羊.txt")
ls = jieba.lcut(f.read())
#ls = f.read().split()
d = {}
for w in ls:
d[w] = d.get(w, 0) + 1
maxc = 0
maxw = ""
for k in d: # 原来如此,遍历一遍,逐次更新
if d[k] > maxc and len(k) > 2:
maxc = d[k]
maxw = k
if d[k] == maxc and len(k) > 2 and k > maxw:
maxw = k
print(maxw)
f.close()
不过也挺奇怪的
