

为什么需要哨兵模式(Sentinel)
- 只依靠持久化方案,在服务器下线后无法恢复服务
- 使用主从复制,在 master 节点下线后,可以手动将 slave 节点切换为
master,但是不能自动完成故障转移
哨兵模式(Sentinel)
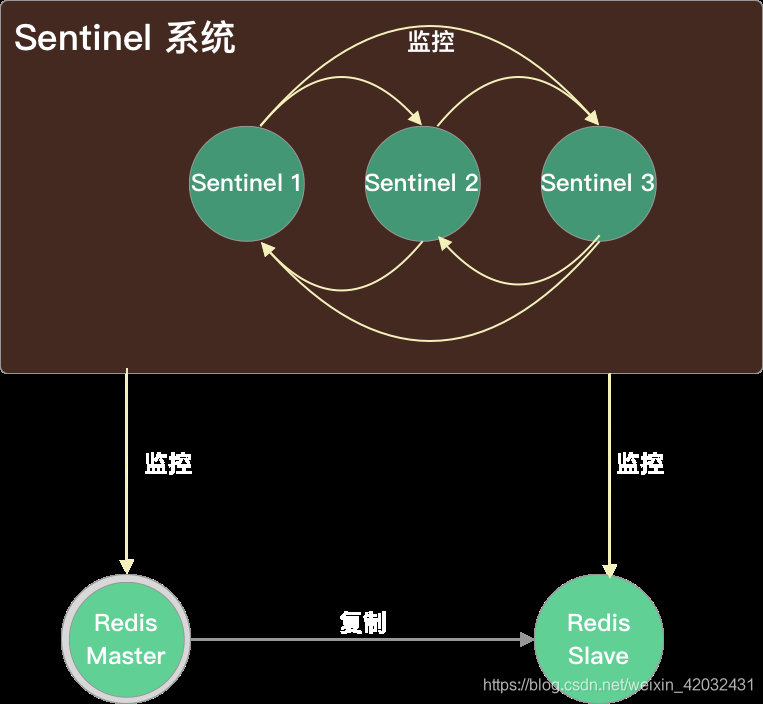
主要功能
- 监控(Monitoring):Sentinel会不断的检查你的主节点和从节点是否正常工作。
- 通知(Notification):被监控的Redis实例如果出现问题,Sentinel可以通过API(pub)通知系统管理员或者其他程序。
- 自动故障转移(Automatic failover):如果一个 master 离线,Sentinel 会开始进行故障转移,master下的一个slave 会被选为新的 master,其他的 slave 会开始复制新的 master。应用可以通过 Redis服务的通知机制更新新的master 地址。
- 配置提供(Configuration provider):客户端可以把 Sentinel 作为权威的配置发布者来获得最新的 master地址。如果发生了故障转移,Sentinel 集群会通知客户端新的 master 地址,并刷新 Redis 的配置。
主要配置
sentinel monitor : 监控的 redis 主节点
sentinel 是 redis 配置的提供者,而不是代理,客户端只是从 sentinel 获取数据节点的配置,因此这里的 ip 必须是 redis 客户端能够访问的。
redis 源码中提供了 sentinel 配置的模板:sentinel.conf
Sentinel 启动
$ redis-server sentinel.conf --sentinel
1
- 初始化一个普通的 redis 服务器
- 加载 Sentinel 专用配置,例如命令表、参数等,Sentinel 使用 sentinel.c 中的命令表、函数等配置,普通
Redis 则使用 redis.c 中的配置 - 除了保存服务器一般状态之外,Sentinel 还会保存 Sentinel 相关状态
准备
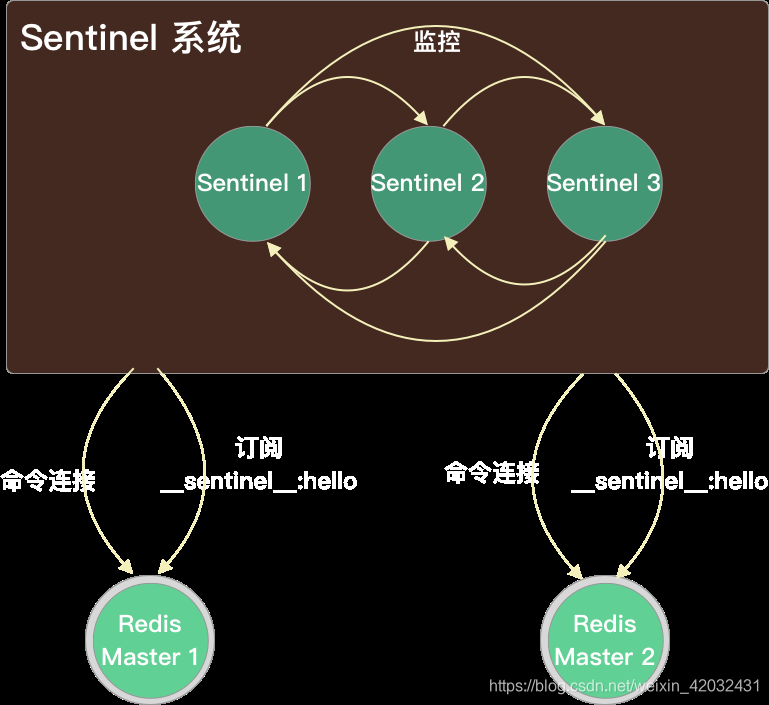
Sentinel 与 master: Sentinel 监控 master,并通过 master 发现其他 Sentinel 和 slaves
建立两个异步网络连接:
命令连接:用于向 Redis master 数据节点发送命令,例如通过 INFO 命令了解:
-
master 本身运行信息,用于更新本地的 master 字典(Redis Hash 的实现中用到字典使用的的也是这个数据结构)
-
slaves 信息(角色、IP、Port、连接状态、优先级、复制偏移量),用于更新本地的 slave 字典
订阅连接:订阅 sentinel:hello 频道,用于发现其他 Sentinel,频道中信息包括:
- Sentinel 自身信息(IP、Port、RunID、Epoch)
- 监视的 Master 节点的信息(Name、IP、Port、Epoch)
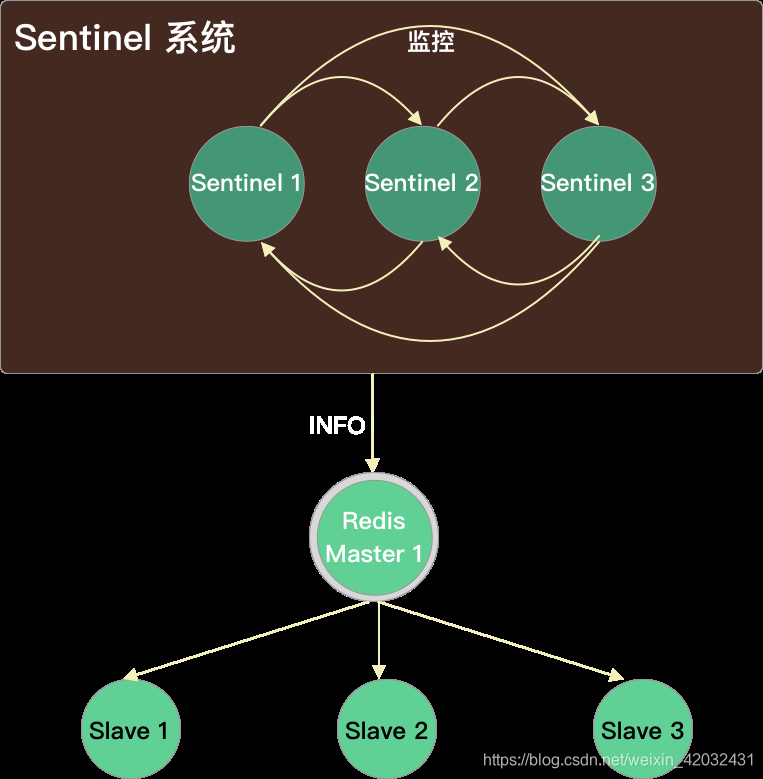
Sentinel 与 slave:Sentinel 自动发现 Slave
- Sentinel 向 master 节点发送 INFO 命令后获取到所有 slave 的信息
- Sentinel 与 slave 建立命令连接和订阅连接
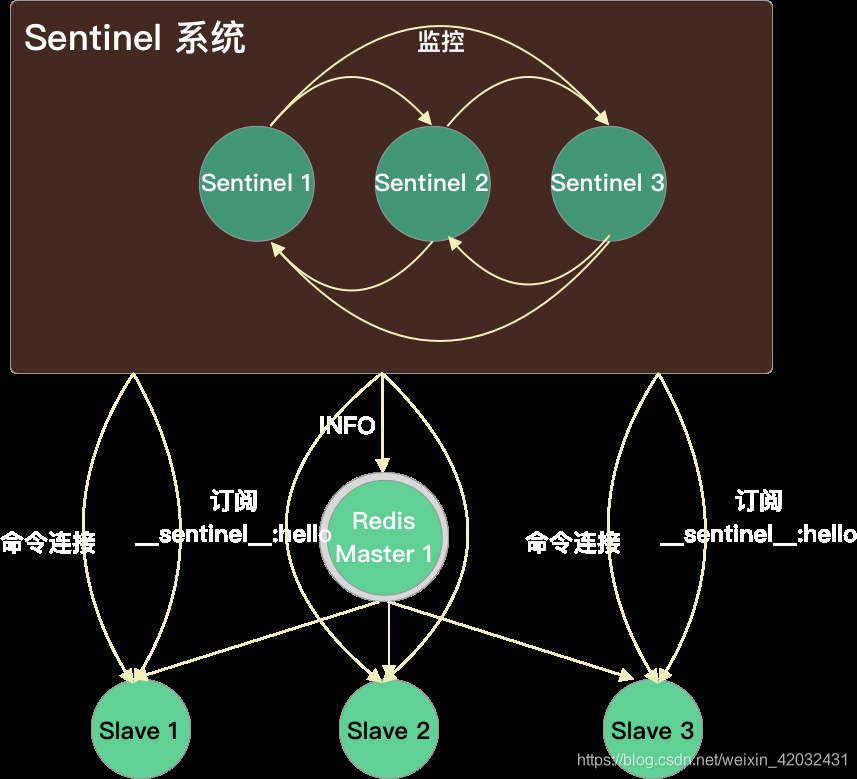
Sentinel 之间:自动发现机制
- Sentinel 利用 pub/sub(发布/订阅)机制,订阅了每个 master 和 slave 数据节点的
sentinel:hello 频道,去自动发现其它也监控了统一 master 的 sentinel 节点 - Sentinel 向每 1s 向 sentinel:hello 中发送一条消息,包含了其当前维护的最新的 master
配置。如果某个sentinel发现自己的配置版本低于接收到的配置版本,则会用新的配置更新自己的 master 配置 - 与发现的 Sentinel 之间相互建立命令连接,之后会通过这个命令连接来交换对于 master 数据节点的看法
监控
- 定时监控 Redis 数据节点
1、每 10 秒每个 sentinel 向 master、slaves 节点发送 INFO 命令
2、每 2秒每个 sentinel 通过 master 节点的 channel(名称为 sentinel:hello)交换信息(pub/sub),信息包括:
3、每 1 秒每个 sentinel 对其他 sentinel 和 redis master,slave 发送 PING 命令,用于心跳检测,作为节点存活的判断依据 - 主观下线和客观下线(发现故障)
1、主观下线(subjectively down,SDOWN):当前 Sentinel 实例认为某个 redis服务为”不可用”状态。Sentinel 向 redis master 数据节点发送消息后30s(down-after-milliseconds) 内没有收到有效回复(+PONG、-LOADING 或者-MASTERDOWN),Sentinel 会将 master 标记为下线(打开 master 结构中 flags 的 SRI_S_DOWN 标记)
2、客观下线(objectively down,ODOWN):多个 Sentinel 实例都认为 master 处于 SDOWN 状态,那么此时 master 将处于 ODOWN, ODOWN可以简单理解为master已经被集群确定为”不可用”,将会开启故障转移机制。向其他 sentinel 节点发送
sentinel is-master-down-by-addr 消息询问数据节点情况,得知达到 quorum 数量的 sentinel节点认为数据节点已经下线
处理
Sentinel 选举(基于 Raft 算法),选出一个 Leader
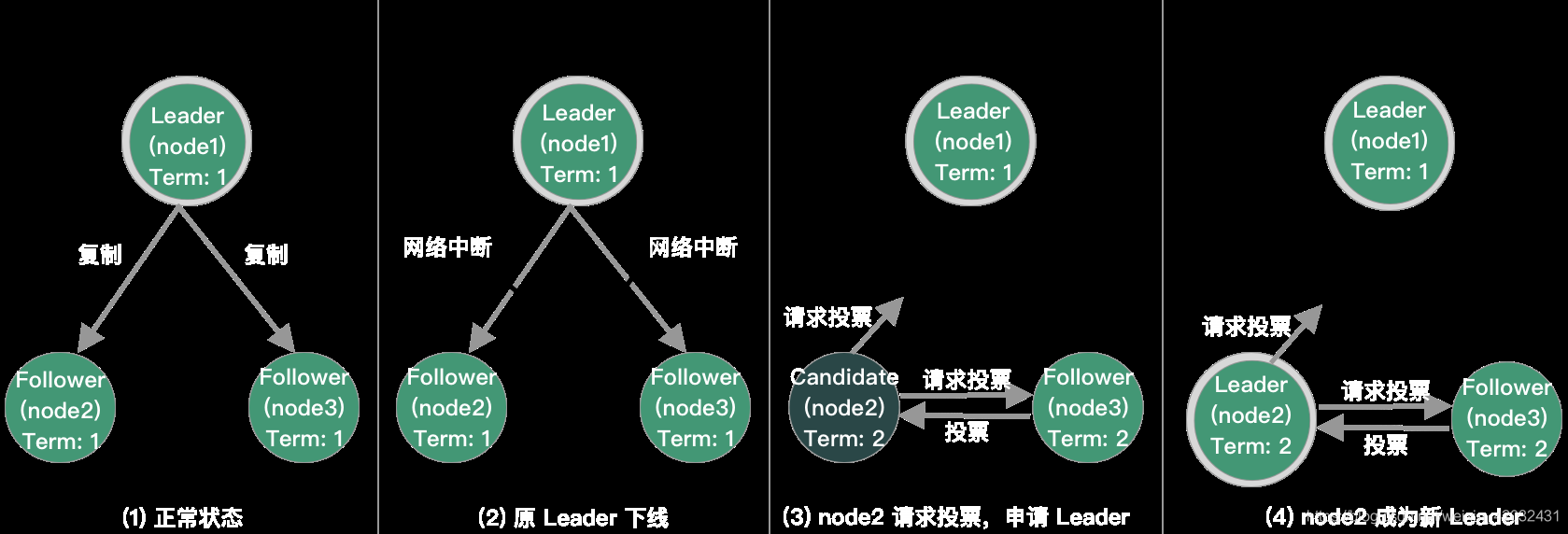
投票:修改本地 leader 和 leader_epoch
- 对于已经投过票,身份变为 Follower,在 2 倍故障转移时间内不再进行选举(故障转移的超时时间默认是3分钟);没投过票的变为Candidate,执行第 2 步
- 更新故障转移状态为start,epoch + 1,更新超时时间为 1s 内随机时间
- 向其他节点发送 is-master-down-by-addr 命令请求投票。命令会带上自己的epoch
- 2 倍故障转移时间内选举
Sentinel 选举算法与 Raft 的区别:
- 每次需要进行故障转移前才进行选举
- 增加了 quorum 参数,Candidate 需要的票数不仅要超过一半,还要达到 quorum 参数配置的值
- Leader 不会将自己成为 Leader 的消息发给其他 Sentinel,其他 Sentinel 等待Leader 从 slave
选出 master后,检测到新的 master 正常工作后,就会去掉旧的 master 客观下线的标识,从而不需要进入故障转移流程
注意:
1.在只有少数 Sentinel 进程正常运作的情况下, Sentinel 是不能执行自动故障迁移的。
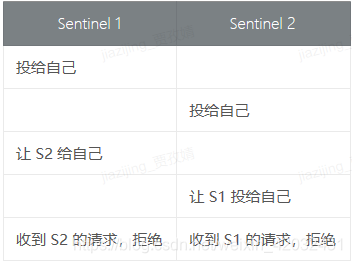
2.正常情况下要配置奇数哨兵,避免切换时候票数相同,出现竞争
两个节点出现竞争的投票过程
故障转移(切换 Redis master 数据节点)
sentinel master 选择合适的 redis slave 成为 master
slave 选择标准:
1.健康的节点:
- 在线的
- 最近成功通信过的(5s 内回复过 PING 命令)
- 数据比较新的(与 master 失联时间不超过 10*down-after-milliseconds)
- lave-priority(slave节点优先级)最高的slave节点
- 制偏移量最大的 slave 节点(复制的最完整)
- 择 runId 最小的 slave 节点(启动最早的节点)
2.执行 SLAVEOF no one(不会删除已有数据,只是不再接受主节点新的数据变化) 命令让其成为新的 master 节点。每秒 Sentinel 向其发送一次 INFO 命令,直到成功变为 master
3.向剩余的 slave 节点发送 SLAVEOF 新master 命令,让他们成为新 master 节点的 slave 节点
4.让剩余的 slave 复制新 master 的数据,通过配置 sentinel parallel-syncs(sentinel.conf) 规定了每次向新的主节点发起复制操作的从节点个数,parallel-syncs 取值越大,slave 完成复制的时间越快,但是对主节点的网络负载、硬盘负载造成的压力也越大,slave 加载 master 发来的 rdb 的过程中不可用
5.更新原来master 节点配置为 slave 节点,并保持对其进行关注,一旦这个节点重新恢复正常后,会命令它去复制新的master节点信息
6.全部故障转移工作完成后,Leader Sentinel 就会推送 +switch-master 消息,同时重置 master,重置操作会释放掉原来 master 全部的 slave 对象和监听该 master 的其他 Sentinel 对象,然后创建出新的 slave 对象
故障迁移过程中 slave 能否返回数据给客户端取决于 slave-serve-stale-data(redis.conf)
7.持续关注旧的 master,并在他重新上线后将它设置为新 master 的 slave
在 sentinel 中执行 sentinel failover master 可以强制该 sentinel 节点执行故障转移,不与其他节点进行选举
Sentinel 缺陷
- Sentinel 模式下,写操作仍然只能在 Sentinel 提供的 master 数据节点上执行,无法负载均衡
- 持久化时 master节点刷盘阻塞,服务请求成功率下降
- slave 节点存储能力受到单机的限制
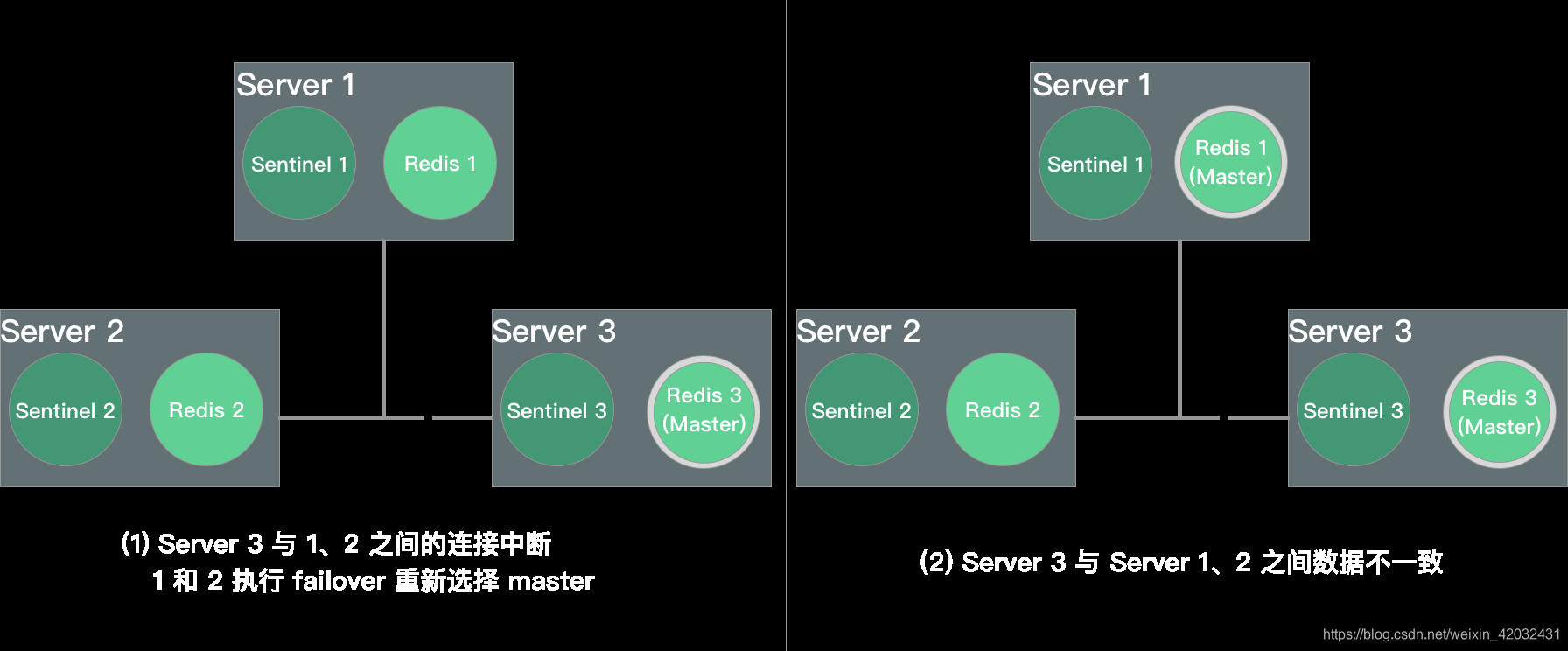
- 分区问题:原 master redis 3 断开与 redis 1 和 redis 2 的连接,此时 redis 1 和 redis 2 执行故障转移,达到大多数,选择 redis 1 为 master。这样,redis 1 和 redis 3 都能接受写请求,但数据无法同步,数据不一致
为什么不用集群模式(Cluster)
- 需要客户端实现 Smart Client,完成重定向等工作
- 批量操作限制,不支持跨 slot 查询,所以批量操作支持不友好
- Key 事务操作支持有限,只支持多 key 在同一节点上的事务操作,当多个 Key 分布于不同的节点上时无法使用事务功能
- Key 作为数据分区的最小粒度,不能将一个很大的键值对象如hash、list 等映射到不同的节点
- 不支持多数据库空间,单机下的 redis 可以支持到 16 个数据库,集群模式下只能使用 1个数据库空间,即 db 0
参考
- Redis Sentinel Documentation
- 深入学习Redis(4):哨兵
- Redis 设计与实现
- Redis深度历险:核心原理与应用实践
源自:刘聪
看到这里的小伙伴,如果你喜欢这篇文章的话,别忘了转发、收藏、留言互动!
如果对文章有任何问题,欢迎在留言区和我交流~
最近我新整理了一些Java资料,包含面经分享、模拟试题、和视频干货,如果你需要的话,欢迎私信我!
给你们康康都有哪些:
